多项式特征应用案例

多项式特征应用案例
描述
对于线性模型而言,扩充数据的特征(即对原特征进行计算,增加新的特征列)通常是提升模型表现的可选方法,Scikit-learn提供了PolynomialFeatures类来增加多项式特征(polynomial features)和交互特征(interaction features),本任务我们通过两个案例理解并掌握增加多项式特征的应用过程。
本任务的实践内容包括:
1、在线性回归中使用多项式特征
2、房价预测案例中使用多项式特征(基于Ridge模型)
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
scikit-learn 0.24.2 matplotlib 3.3.4 numpy 1.19.5
分析
本任务涉及以下环节:
A)在线性回归中使用多项式特征
B)可视化对比预测曲线的拟合情况
C)在房价数据集中增加多项式特征
D)进行数据缩放,建立Ridge回归模型
E)对比增加多项式特征前后的模型表现
实施
1、在线性回归中使用多项式模型
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import numpy as npnp.random.seed(seed=0) # 固定随机数种子,便于结果重现
x = np.random.uniform(-3, 3, size=100) # 随机生成100个数
x.sort() # 排序
y = x 2 + 2 * x + 3 + np.random.normal(0, 1, 100) # 由数组x生成数组y,增加噪音
X = x.reshape(-1, 1) # 将x转换为(samples,features)格式lr = LinearRegression().fit(X, y) # 创建模型,拟合数据
y_predict = lr.predict(X) # 预测plt.scatter(x, y) # 画出数据点
plt.plot(x, y_predict, c='r', label='score=%0.2f'% lr.score(X, y)) # 生成预测曲线及成绩
plt.legend(fontsize=14) # 图例(显示成绩)
plt.show()
结果如下:
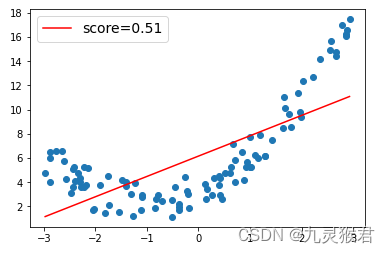
说明:数据点并不符合线性分布,所以使用线性回归模型生成的预测曲线(红线)很不理想,不能反映数据点的分布规律,成绩只有0.51。下面我们在原数据中增加多项式特征,然后查看效果。
2、增加多项式特征
from sklearn.preprocessing import PolynomialFeaturesX_poly = PolynomialFeatures(degree=2).fit_transform(X) # 增加多项式特征
lr.fit(X_poly, y) # 重新拟合数据
y_predict = lr.predict(X_poly) # 预测plt.scatter(x, y) # 画数据点
plt.plot(x, y_predict, c='r', label='score=%0.2f'% lr.score(X_poly, y)) # 生成预测曲线
plt.legend(fontsize=14) # 图例
plt.show()
输出结果:
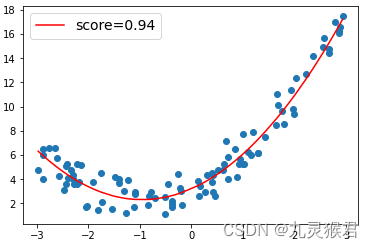
增加了多项式特征后,线性回归的预测曲线较好地拟合了数据点,成绩达到了0.94。因此,线性回归配合多项式特征,可以用来拟合非线性数据。
需要注意的是,如果多项式次数(degree)过大,容易出现过拟合(overfit)。即模型在训练时表现很好,但在陌生数据上表现很差,这是因为模型过于追求对训练数据点的拟合,导致泛化能力下降。(如下图)
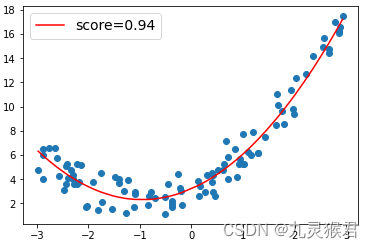
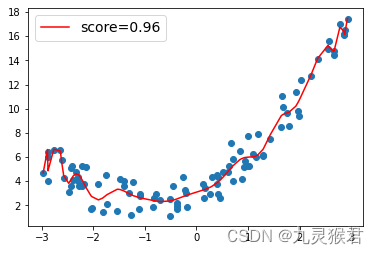
degree=2 degree=30
3、在房价预测案例中使用多项式特征
3.1 加载拆分数据集,进行缩放预处理
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge# 加载、拆分数据
boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=1)# 进行数据缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
3.2 增加多项式特征,建立Ridge回归模型,并对比模型前后成绩
# 增加多项式特征poly = PolynomialFeatures(degree=2)
X_train_poly = poly.fit_transform(X_train_scaled)
X_test_poly = poly.fit_transform(X_test_scaled)
print('X_train.shape:', X_train.shape) # 查看增加特征前后的数据尺寸
print('X_train_poly.shape:', X_train_poly.shape) # 创建Ridge回归模型,对比增加特征前后的模型成绩ridge = Ridge().fit(X_train_scaled, y_train)
print('Score without PolynomialFeatures: %0.2f'%ridge.score(X_test_scaled, y_test))
ridge = Ridge().fit(X_train_poly, y_train)
print('Score with PolynomialFeatures: %0.2f'%ridge.score(X_test_poly, y_test))
结果如下:
X_train.shape: (379, 13)
X_train_poly.shape: (379, 105)
Score without PolynomialFeatures: 0.78
Score with PolynomialFeatures: 0.90
可以看到,增加多项式特征后,特征个数由13个变成105个,同时Ridge回归模型的性能得到提升。需要注意的是,线性模型中使用多项式特征的效果,因具体的模型和具体任务要求不同而不同。