《Advanced R》学习笔记 | Chapter3 Vectors

专注系列化、高质量的R语言教程
推文索引 | 联系小编 | 付费合集
本篇推文是学堂君学习第3章“Vectors”的笔记,原文链接是https://adv-r.hadley.nz/vectors-chap.html,可在文末“阅读原文”处直达。
通过本章的学习,我们可以更清晰地理解R语言中各种数据结构之间的关系。
-
3.1 Introduction
-
3.2 Atomic vectors
-
3.2.1 Scalars
-
3.2.2 Making longer vectors with c()
-
3.2.3 Missing values
-
3.2.4 Testing and coercion
-
-
3.3 Attributes
-
3.3.1 Getting and setting
-
3.3.2 Names
-
3.3.3 Dimensions
-
-
3.4 S3 atomic vectors
-
3.4.1 Factors
-
3.4.2 Dates
-
3.4.3 Date-times
-
3.4.4 Durations
-
-
3.5 Lists
-
3.5.1 Creating
-
3.5.3 Matrices and arrays
-
-
3.6 Data frames and tibbles
-
3.6.1 Creating
-
3.6.2 Row names
-
3.6.4 Subsetting
-
3.6.6 List columns
-
3.6.7 Matrix and data frame columns
-
-
3.7 NULL
3.1 Introduction
测试:如果读者能准确回答如下几个问题,就可以跳过本章的学习。
-
What are the four common types of atomic vectors? What are the two rare types?
-
What are attributes? How do you get them and set them?
-
How is a list different from an atomic vector? How is a matrix different from a data frame?
-
Can you have a list that is a matrix? Can a data frame have a column that is a matrix?
-
How do tibbles behave differently from data frames?
(答案见原文本章节末尾处。)
3.2 Atomic vectors
常见的4个原子向量类型是:逻辑类型、整型、双精度类型和文本类型(元素为字符串),整型和双精度合称数值型。
两种不常见的类型是复数型和原始型;复数在统计学中很少使用,原始型仅在处理二进制数据时使用,本章不会进一步讨论这两种类型。

学堂相关推文:R语言的原子类型和数据结构
3.2.1 Scalars
标度(scalar)可以用来指示元素的类型:
-
逻辑值只有两个:
TRUE和FALSE,分别简写为T和F; -
双精度值的形式可以小数点(
0.1234)、科学计数法(1.23e4)或十六进制(0xcafe);此外还有三个特殊值:Inf、-Inf、NaN; -
整型的值是整数,也可以是科学计数法和十六进制,为了区别双精度值,数字后面要加上字母
L(1234L、1e4L、0xcafeL);整型中不能包含分式; -
文本的标志是其两侧的双引号
"或单引号'。
3.2.2 Making longer vectors with c()
c()函数的名称是combine的缩写,通过合并单值或向量来创建更长的向量;多个原子向量使用c()函数合并后还是原子向量。
c(c(1, 2), c(3, 4))
## [1] 1 2 3 4typeof()函数用来查看向量类型,length()函数用来查看向量长度。
3.2.3 Missing values
NA(“not applicable”的缩写)表示缺失值或未知值。通常情况下,NA参与大小比较或计算,得到的结果也是NA:
NA > 5
## [1] NA
10 * NA
## [1] NA
!NA
## [1] NA也有例外:
NA ^ 0
## [1] 1
NA | TRUE
## [1] TRUE
NA & FALSE
## [1] FALSE无法通过x == NA的形式判断变量的元素是否为NA:
x <- c(NA, 5, NA, 10)
x == NA
## [1] NA NA NA NA正确方法是使用is.na()函数:
is.na(x)
## [1] TRUE FALSE TRUE FALSE在技术层面缺失值存在4种类型的:NA(逻辑型)、NA_integer_(整型)、NA_real_ (双精度型)、NA_character_(文本型)。R语言根据情况自动使用相应的类型。
3.2.4 Testing and coercion
is.*()系列的函数可以用来判断变量是否是给定类型的向量:is.logical()、is.integer()、is.double()和is.character()等函数可以分别来判断逻辑型、整型、双精度型和文本类型的向量。
但是,is.vector()、is.atomic()、is.numeric()等函数不能简单地认为是用来判断向量、原子向量和数值向量的,具体见相应函数文档。
原子向量的元素必须为同一类型。当合并不同类型的元素时,按文本——双精度——整型——逻辑的优先级顺序转换到同一类型。
类型转换有时会自动进行,例如大部分数学运算会将对象转为数值型。
用户可通过as.*()系列函数主动转换原子向量的类型。
3.3 Attributes
因子向量、时间和日期向量、矩阵和数组是在原子向量的基础上,添加属性而形成的更复杂的向量。
3.3.1 Getting and setting
attr()函数可以设置、查看和修改对象的单个属性:
x <- c(1:3)
attr(x, "attr1") <- "属性1"
attr(x, "attr2") <- "属性2" attr(x, "attr1")
attr(x, "attr2")attributes()函数可以一次性查看对象的所有属性:
attributes(x)structure()函数可以同时设置对象的多个属性:
x <- structure(c(1:3),attr1 = "属性1",attr2 = "属性2"
)attributes(x)3.3.2 Names
names属性是由对象元素的名称组成的文本向量。设置该属性有3种方式:
# When creating it:
x <- c(a = 1, b = 2, c = 3)# By assigning a character vector to names()
x <- 1:3
names(x) <- c("a", "b", "c")# Inline, with setNames():
x <- setNames(1:3, c("a", "b", "c"))移除names属性有两种方式:
x <- unname(x)
names(x) <- NULL3.3.3 Dimensions
虽然向量是一维结构的,但是由于它默认情况下没有dim属性,因此该属性为NULL。给向量添加dim属性后可以得到2维矩阵或多维数组。
通常情况下,我们一般使用使用matrix()和array()函数分别创建矩阵和数组:
x <- matrix(1:6, nrow = 2, ncol = 3)y <- array(1:12, c(2, 3, 2))也可以通过给原子向量添加dim属性来创建:
p <- 1:6
dim(p) <- c(3, 2)q <- 1:12
dim(q) <- c(2, 3, 2)3.4 S3 atomic vectors
class属性是向量最重要的属性之一,具有class属性的对象都是S3对象。以下4种S3向量都是在原子向量的基础上构建的:
-
因子向量(factor vector),记录分类数据;
-
日期向量(Date vector),记录日期数据(精确到天);
-
POSIXct向量,记录日期-时间(date-time)数据(精确到秒或亚秒);
-
difftime向量,记录时长(durations)数据。

3.4.1 Factors
因子向量是在整型原子向量的基础上构建的,它有两个属性:
-
class属性是factor,这是区别于一般整型原子向量的特征; -
levels属性,定义分类数据所有可能出现的类别。
x <- factor(c("a", "b", "b", "a"))
x
## [1] a b b a
## Levels: a btypeof(x)
## [1] "integer"attributes(x)
## $levels
## [1] "a" "b"
##
## $class
## [1] "factor"当数据所有可能出现的值是已知的时,比较适合用因子向量来储存,且允许类别在数据中不全部出现。因子向量和文本向量的元素都可以使用table()函数分类计数:前者会把未出现的类别也列举处理,后者仅列举出现的字符串:
sex_char <- c("m", "m", "m")
sex_factor <- factor(sex_char, levels = c("m", "f"))table(sex_char)
## sex_char
## m
## 3
table(sex_factor)
## sex_factor
## m f
## 3 0有序(ordered)因子向量又是特殊的因子向量,它的levels属性的元素顺序是有含义的。
基础包的一些函数,如read.csv()函数在加载数据时可能会默认将文本数据作为因子向量,设置参数stringsAsFactors = FALSE可以避免。
尽管因子向量与文本向量从外观上很相似,但它实际是整型向。一些文本分析的函数也可以用在因子向量上,如gsub()、grepl()函数会自动将其转为文本向量;而nchar()函数会报错。
3.4.2 Dates
日期向量是在双精度原子向量的基础上构建的。它有且仅有一个属性:class属性,值为Date。
today <- Sys.Date()typeof(today)
## [1] "double"
attributes(today)
## $class
## [1] "Date"日期向量元素对应的双精度值是该日期与1970年1月1日的间隔天数:
date <- as.Date("1970-01-02")
unclass(date)
## [1] 13.4.3 Date-times
base R储存时间数据有两种方式:POSIXct和POSIXlt。POSIX是“Portable Operating System Interface”(可移植操作系统接口)的缩写。“ct”表示日历时间(calendar time),“lt”表示地方时(local time)。
POSIXct向量是在双精度型向量的基础上构建的,对应的双精度值是该时间与1970年1月1日0时0分0秒的间隔秒数。
now_ct <- as.POSIXct("1970-01-01 01:00", tz = "Etc/GMT-8")
now_ct
## [1] "1970-01-01 01:00:00 +08"unclass(now_ct)
## [1] -25200tzone属性:
structure(now_ct, tzone = "Asia/Tokyo")
## [1] "2018-08-02 07:00:00 JST"
structure(now_ct, tzone = "America/New_York")
## [1] "2018-08-01 18:00:00 EDT"
structure(now_ct, tzone = "Australia/Lord_Howe")
## [1] "2018-08-02 08:30:00 +1030"
structure(now_ct, tzone = "Europe/Paris")
## [1] "2018-08-02 CEST"3.4.4 Durations
时长数据也是在双精度型向量的基础上构建的,具有属性units:
one_week_1 <- as.difftime(1, units = "weeks")
one_week_1
## Time difference of 1 weekstypeof(one_week_1)
## [1] "double"
attributes(one_week_1)
## $class
## [1] "difftime"
##
## $units
## [1] "weeks"one_week_2 <- as.difftime(7, units = "days")
one_week_2
## Time difference of 7 daystypeof(one_week_2)
## [1] "double"
attributes(one_week_2)
## $class
## [1] "difftime"
##
## $units
## [1] "days"3.5 Lists
列表是比原子向量更复杂的向量:它的每个元素可以是任意类型的。但从技术上将,列表元素实际上还是同一类型——“索引”。如2.3.3节介绍,列表元素只是其他对象的索引,而被引用的对象可以是任意类型的。
3.5.1 Creating
列表元素实际上只是索引,它不涉及将对象复制到列表的过程,因此很多情况下,它会比预想的要小:
lobstr::obj_size(mtcars)
## 7,208 Bl2 <- list(mtcars, mtcars, mtcars, mtcars)
lobstr::obj_size(l2)
## 7,288 B列表元素本身还可以是列表,因此列表也被称为递归向量(recursive vector):
l3 <- list(list(list(1)))
str(l3)
## List of 1
## $ :List of 1
## ..$ :List of 1
## .. ..$ : num 1使用c()和list()函数合并原子向量和列表的结果是不一样的:
l4 <- list(list(1, 2), c(3, 4))
l5 <- c(list(1, 2), c(3, 4))str(l4)
## List of 2
## $ :List of 2
## ..$ : num 1
## ..$ : num 2
## $ : num [1:2] 3 4str(l5)
## List of 4
## $ : num 1
## $ : num 2
## $ : num 3
## $ : num 43.5.3 Matrices and arrays
普通的列表没有dim属性。给列表定义dim属性后,可以得到list-matrices或list-arrays:
l <- list(1:3, "a", TRUE, 1.0)
dim(l) <- c(2, 2)l
## [,1] [,2]
## [1,] integer,3 TRUE
## [2,] "a" 1l[[1, 1]]
## [1] 1 2 3作者特别提到这种数据结构对时空类型的数据分析特别有用。
3.6 Data frames and tibbles
数据框和tibble是在列表的基础上构建的更复杂的异质向量。
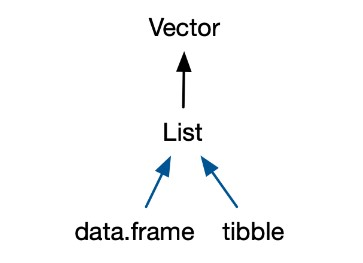
数据框是由向量组成的列表,并且每个向量的长度是一样的。这种矩形结构,使得它兼具列表和矩阵的特点。
tibble本身也是数据框,来自tibble工具包(本书作者是开发者之一),但在一些细节上的处理与普通数据框不同,下文会有所介绍。
3.6.1 Creating
data.frame()和tibble()函数可以分别定义数据框和tibble。下面列举两者的不同点。
如果变量名称为非法名称,数据框会自动转换为合法名称,tibble允许以反引号的形式:
names(data.frame(`1` = 1))
## [1] "X1"library(tibble)
names(tibble(`1` = 1))
## [1] "1"如果变量长度不一致,二者会在某种情况下循环利用较短变量的元素使之与较长向量等长:数据框要求较长向量的长度必须是较短向量的整数倍,否则报错;tibble要求较短向量的长度为1,否则报错:
data.frame(x = 1:4, y = 1:2)
## x y
## 1 1 1
## 2 2 2
## 3 3 1
## 4 4 2
data.frame(x = 1:4, y = 1:3)
## Error in data.frame(x = 1:4, y = 1:3) : 参数值意味着不同的行数: 4, 3tibble(x = 1:4, y = 1)
## # A tibble: 4 x 2
## x y
## <int> <dbl>
## 1 1 1
## 2 2 1
## 3 3 1
## 4 4 1
tibble(x = 1:4, y = 1:2)
## Error: Tibble columns must have compatible sizes.
## * Size 4: Existing data.
## * Size 2: Column `y`.
## ℹ Only values of size one are recycled.tibble的变量在创建时就可以引用,数据框无此功能:
tibble(x = 1:3,y = x * 2
)3.6.2 Row names
数据框可以设置行名,tibble不可以设置行名。当需要将前者转换为后者时,可以将行名作为变量:
as_tibble(df, rownames = "name")3.6.4 Subsetting
作者认为数据框的取子集操作时有两个麻烦的地方:
-
使用
df[, vars]提取的变量形式不是数据框,而是向量;df[, vars, drop = F]得到的变量形式才是数据框; -
使用
df$x的形式提取变量时,如果数据框中没有名称是x的变量,它会提取名称以x开头的列,如果还没有会返回NULL,这会让用户意识不到提取结果可能是错的或不存在的。
tibble对此做了改进:使用[可以直接提取到tibble形式的变量;只有当变量名称完全匹配时才能进行提取,否则报错。
3.6.6 List columns
数据框可以使用列表作为列,这样数据框一列内的元素也可以是不同类型的了。
类型为列表的列(下文简称“列表列”)在定义时需要使用I()函数:
data.frame(x = 1:3, y = I(list(1:2, 1:3, 1:4))
)
## x y
## 1 1 1, 2
## 2 2 1, 2, 3
## 3 3 1, 2, 3, 4或者是在数据框创建后,再添加列表列:
df <- data.frame(x = 1:3)
df$y <- list(1:2, 1:3, 1:4)
df
## x y
## 1 1 1, 2
## 2 2 1, 2, 3
## 3 3 1, 2, 3, 4tibble可以像创建普通列一样创建列表列:
tibble(x = 1:3, y = list(1:2, 1:3, 1:4)
)
## # A tibble: 3 × 2
## x y
## <int> <list>
## 1 1 <int [2]>
## 2 2 <int [3]>
## 3 3 <int [4]>3.6.7 Matrix and data frame columns
数据框也可以使用矩阵和数据框作为列,定义方式和上文类似:
dfm <- data.frame(x = 1:3 * 10,y = I(matrix(1:9, nrow = 3))
)
dfm$z <- data.frame(a = 3:1, b = letters[1:3])str(dfm)
## 'data.frame': 3 obs. of 3 variables:
## $ x: num 10 20 30
## $ y: 'AsIs' int [1:3, 1:3] 1 2 3 4 5 6 7 8 9
## $ z:'data.frame': 3 obs. of 2 variables:
## ..$ a: int 3 2 1
## ..$ b: chr "a" "b" "c"3.7 NULL
NULL的长度恒为0,且没有任何属性。它主要有两个用途:
-
表示任意类型的空向量;
-
在定义函数时,作为非必须参数的默认值。