MySQL查询操作

系列文章目录
- 前言
- 一、简单查询
- 二、嵌套子查询
-
- 比较运算中使用子查询
- 带有IN的子查询
- SOME(子查询)
- ALL(子查询)
- EXISTS子查询
- 三、多表连接查询
-
- 内连接
- 外连接
-
- 左外连接
- 右外连接
- 全外连接
- 四、复杂查询
-
- 复杂查询UNION [ALL]
前言
一、简单查询
select 表示查询
from 后接表名,表示查询哪张表
where 是筛选条件,满足条件的会被查询出来
SELECT子句
SELECT后面之间跟列名
【例】:查询 Student 表中的学号、姓名、班级
SELECT 学号、姓名、班级
FROM Student
【例】:查询 Student 表中全部数据
SELECT 学号、年龄、姓名、性别、联系方式、班级
FROM Student
等价于:
SELECT * FROM Student
当想要选取一个表中全部列时,全部列可以用【*】表示
DISTINCT,ALL
如果在结果中重复的数据不想显示出来,可以使用distinct关键字
对比结果:
【例】
SELECT pubilsh FROM Book
对比:
SELECT DISTINCT pubilsh FROM Book
也可以指明不要去除重复元祖,使用ALL关键字
SELECT ALL sex FROM Student
列表达式
【例】查询每一本书九折后的价格
Book表
| book_ID | name | price | |
|---|---|---|---|
| 1 | A025B1 | 计算机文化基础 | 28.00 |
| 2 | A025B2 | C语言 | 58.00 |
| 3 | A025B3 | JAVA | 25.00 |
| 4 | A025B4 | Python | 27.00 |
SELECT book_ID,name,price*0.9 FROM Book
列更名
SQL 提供了为关系表和属性重新命名的机制。
经过计算的列、函数的列和常量列的显示结果都没有列名,也可以通过这样的方式指定列名。
语法格式:旧列名 | 表达式 [ AS ] 新列名 或:新列名 =旧列名 | 表达式
【例】:
SELECT sno AS 学号、name AS 姓名、bno AS 班级
FROM Student
WHERE子句
语法格式:
SELECT 列名列表 FROM 表名
WHERE 条件表达式
【例】查询成绩大于90分的学生的全部信息
SELECT * FROM Student
WHERE Score > 90
WHERE子句中可以使用的查询条件
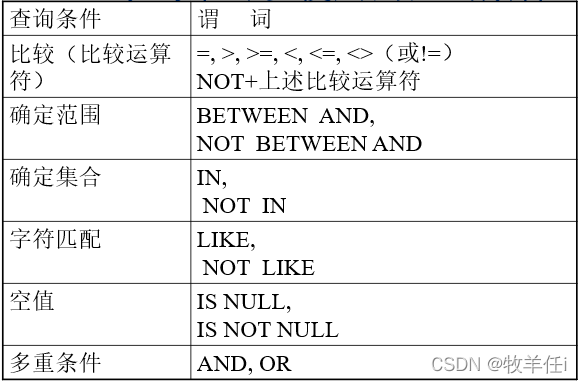
比较运算
【例】查询所有的女老师的信息
Select * from Teacher where sex='女'
【例】查询学生成绩在60到90分之间的学生
SELECT * FROM Student
WHERE Score >= 60 AND Score <= 90
【例】查询“高等教育出版社”或者“清华大学出版社”出版的图书
SELECT * FROM Book WHERE publish ='高等教育出版社' or publish = '清华大学出版社'
BETWEEN…AND…
用法:BETWEEN<下限值>AND<上限值>
【例】查询学生成绩在60到90分之间的学生
SELECT * FROM Student
WHERE Score BETWEEN 60 AND 90
等价于
SELECT * FROM Student
WHERE Score >= 60 AND Score <= 90
它可以查找上限值与下限值之间的元组,也可以查找不在上限值与下限值之间的元组
【例】查询学生成绩不在60到100分之间的学生
SELECT * FROM Student
WHERE Score NOT BETWEEN 60 AND 100
等价于
SELECT * FROM Student
WHERE Score < 60 OR price > 100
集合查询:IN
【例】查找“机械工业出版社”,“清华大学出版社”,“高等教育出版社”出版的全部图书
SELECT * FROM Book
WHERE publish IN('机械工业出版社','清华大学出版社','高等教育出版社')
【例】查找不是“机械工业出版社”,“清华大学出版社”,“高等教育出版社”出版的全部图书
SELECT * FROM Book
WHERE publish NOT IN ('机械工业出版社','清华大学出版社','高等教育出版社')
模糊查询LIKE
LIKE的用法
列名 LIKE <字符串>
在字符串中我们可以使用通配符
_代表任意一个字符
%代表任意多个字符
【例】查询姓全部 “张” 的读者的信息。
SELECT * FROM Reader
WHERE name LIKE '张%'
【例】查询1999年出生的学生的信息
SELECT * FROM Student
WHERE birthdate LIKE '%1999%'
空值比较:IS NULL
【例】查询性别为空的学生的信息
SELECT * FROM Student
WHERE sex IS NULL
【例】查询出生日期不为空的学生的姓名
SELECT name FROM Student
WHERE birthdate IS not NULL
多重条件查询
【例】查询1992年以后出生的女学生的姓名
SELECT name FROM Student
WHERE birthdate >= '1992-1-1' AND sex='女'
SELECT 的基本结构
SELECT子句:选择表中列
WHERE子句:筛选表中元组
ORDER BY子句:对查询结果排序
聚集函数:统计
GROUP BY子句:分组查询
HAVING子句:对分组结果筛选
ORDER BY子句排序
ORDER BY <列名> [ASC|DESC][,…n]
ASC表示升序排序;DESC表示降序排序
默认情况为升序排序
• 注:对于空值,若按照升序排序,含空值的元组将最后
显示。若按降序排序,空值的元组将最先显示
【例】查询学生的信息按出生日期的升序显示
SELECT * FROM Student
ORDER BY birthdate ASC
【例】查询老师的信息按出生日期的"降序"显示
SELECT * FROM Teacher
ORDER BY birthdate DESC
【例】查询图书的信息,查询结果按照出版社的名称升序排序,同一出版社的按照价格的降序排序。
SELECT * FROM Book
ORDER BY publish ASC,price DESC
聚集函数
聚集函数(也叫集合函数),方便用户统计一些数据。
COUNT(*): 统计表中元组个数;
COUNT(列名):统计本列列值个数;
SUM(列名):计算列值总和(必须是数值型列);
AVG(列名):计算列值平均值(必须是数值型列);
MAX(列名):求列值最大值;
MIN(列名):求列值最小值。
【例】统计全部学生的平均成绩
SELECT AVG(Score) FROM Student
【例】查询最高的学生成绩
SELECT MAX(Score) FROM Student
【例】统计老师的总人数
SELECT COUNT(*) FROM Teacher
聚合函数不能出现在 WHERE 子句中
分组查询【GROUP BY和HAVING 子句】
【例】统计每个出版社的出版图书的数目
分析:如果能够将所有的图书,按照出版社的名称进行分组,然后我们在统计每一组的元组的个数,我们就能能到得到期望的数据。如图:
| Book_ID | Name | Author | Public | Price | |
|---|---|---|---|---|---|
| 1 | 256B10001 | 数据库原理 | 张三 | 电子工业出版社 | 25.00 |
| 2 | 256B10001 | 离散数学 | NULL | 高等教育出版社 | 28.00 |
| 3 | 256B10001 | 线形数学 | 李四 | 高等教育出版社 | 51.00 |
| 4 | 256B10001 | 大学语文 | 张龙 | 机械工业出版社 | 31.00 |
| 5 | 256B10001 | C语言 | 赵虎 | 机械工业出版社 | 22.00 |
| 6 | 256B10001 | JAVA | 王朝 | 清华大学出版社 | 42.00 |
| 7 | 256B10001 | Python | 马汉 | 清华大学出版社 | 21.00 |
可以使用GROUP BY <列名>进行分组
在<列名>上值相同的元组被分在一组,该列称为分组依据列。然后可以使用聚集函数统计每一组的数据。
SELECT COUNT(*) , publish FROM Book
GROUP BY publish
【例】统计每个人所借图书的数目。
SELECT COUNT(book_ID), Reader_id
FROM Borrow
GROUP BY Reader_id
Having COUNT(book_ID)>2
【例】统计每个出版社出版图书的平均价格,并显示每个出版社的名称
SELECT publish, AVG(price) AS 平均价格
FROM Book
GROUP BY publish
【例】查询出版图书平均价格高于30元的出版社名称,并显示其图书平均价格。
HAVING 子句用于对分组统计后的结果进行筛选。满足HAVING 子句条件将会保留在结果中
SELECT publish,AVG(price) FROM Book
GROUP BY publish
HAVING AVG(price)>30
【例】查询出版图书多于2本的出版社名称和出版图书数目
SELECT publish, COUNT(*) FROM Book
GROUP BY publish
HAVING COUNT(*)>2
二、嵌套子查询
在SQL语言中,一个SELECT-FROM语句称为一个查询块。
如果一个SELECT语句嵌套在另一个SELECT、INSERT、UPDATE或DELETE语句中,则称之为子查询或内层查询;而包含子查询的语句则称为主查询或外层查询。
执行顺序:先内层后外层;先子查询后主查询
比较运算中使用子查询
【例】查询成绩最好的学生的姓名
SELECT name FROM Student WHERE Score =(SELECT MAX(Score) FROM Student)
带有IN的子查询
【例】查询与"C语言"在同一出版社的图书信息
SELECT * FROM Book WHERE publish IN (SELECT publish FROM Book WHERE name='C语言')
【例】查询王旭所借图书的图书编号
SELECT book_ID FROM Borrow WHERE reader_ID IN (SELECT reader_ID FROM Reader WHERE name='王旭')
【例】查询"王旭"所借的图书的名称
SELECT name FROM Book WHERE book_ID IN(SELECT book_ID FROM Borrow WHERE reader_ID IN (SELECT reader_ID FROM Reader WHERE name='王旭'))
查询过程:
第1步,查询"王旭"的reader_ID。
第2步,依据reader_ID在Borrow表中找王旭所借图书的book_ID
第3步,依据book_ID在Book表中找到图书名称。
【例】查询借书价格在20-40之间的读者的姓名
select name from reader where reader_id in(select reader_id from borrow where book_id in(select book_id from book where price between 20 and 40))
查询张三 ‘借阅’ 计算机文化基础’的日期
select borrowdate from borrow
where reader_id in(select reader_id from reader where name='张三')and book_id in(select book_id from book where name='计算机文化基础')
查询借书价格在20-40之间的读者的姓名
select name from reader where reader_id in(select reader_id from borrow where book_id in(select book_id from book where price between 20 and 40))
SOME(子查询)
表示子查询的结果集合中某一个元素
【例】查询除不是最低价格外的所有图书
SELECT * FROM Book WHERE price>SOME(SELECT price FROM Book)
【例】查询价格最低的图书信息
SELECT * FROM Book WHERE NOT(price>SOME(SELECT price FROM Book))
ALL(子查询)
表示子查询的全部结果
【例】查询书价最高的图书的信息
SELECT * FROM Book WHERE price >=ALL(SELECT price FROM Book)
【例】查询评价书价最高的出版社名称
SELECT * FROM Book
GROUP BY public
HAVING AVG(price)>=ALL(SELECT AVG(price) FROM BookGROUP BY public)
EXISTS子查询
判断子查询是否存在结果
当子查询存在结果时,EXISTS(子查询)返回值为true,否则返回值为false。
先外层查询,后内层查询;将外层的值代入内层进行查询,根据内层查询是否存在结果,判断外层的元组是否保留在结果集中。
【例】查询借阅了图书的读者的姓名
SELECT name FROM reader WHERE
EXISTS ( SELECT * FROM borrow WHERE
borrow.reader_id=reader.reader_id)
【例】查询被借出的图书的信息
SELECT * FROM Book WHERE EXISTS
(SELECT * FROM Borrow WHERE Borrow.book_ID=Book.book_ID)
三、多表连接查询
JOIN 表示连接,inner表示内连接,outer表示外连接,缺省情况就是内连接。
ON后面接<连接条件>
内连接
语句格式FROM 表1 [inner] JOIN 表2 ON <连接条件>
满足连接条件的元组保留到连接的结果中,其中存在不满足连接条件的元组会被舍弃。
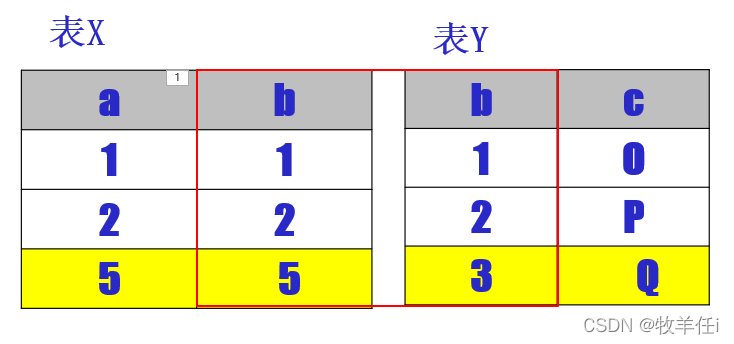
表X和Y内连接结果
SELECT a, X.b, Y.b, c
FROM X
JOIN Y
ON X.b=Y.b
一张表和自身连接。必须给表其别名
• 【例】查询与C语言在同一出版社的图书信息
分析:C语言一书在Book表中,与它在同一出版社的图书也在Book表中。二者通过publish相等进行连接
SELECT BookW.* FROM Book BookC JOIN
Book BookW on
BookC.publish=BookW.publish WHERE
BookC.name=‘C语言’ AND BookW.name<> 'C语言'
• 内连接的特点:满足连接条件的元组保留到连接的结果中,其中存在不满足连接条件的元组会被舍弃。
外连接
和内连接相对的就是外连接。
外连接的特点:满足连接条件的元组保留到连接的结果中,其中不满足连接条件的元组也会显示到连接结果中。
外连接分类:
左外连接
语法格式:FROM 表1 LEFT [OUTER] JOIN 表2 ON <连接条件>
LEFT OUTER JOIN表示左外连接, OUTER 可省略
【例】表 X 和 Y 进行左外连接语句及连接结果
SELECT a,X.b,Y.b,c from x left outer join y ON x.b=Y.b
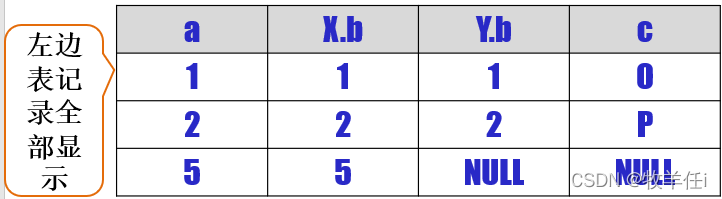
在连接过程中,左侧表一的元组r 如果不能满足连接条件,r 保留在连接的结果中
在连接结果中,和 r 对应的表二的例值用NULL来代替
右外连接
语法格式:FROM 表1 RIGHT [OUTER] JOIN 表2 ON <连接条件>
【例】表 X 和 Y 进行右外连接语句及连接结果
SELECT a, X.b, Y.b, c FROM X RIGHT JOIN Y ON X.b=Y.b
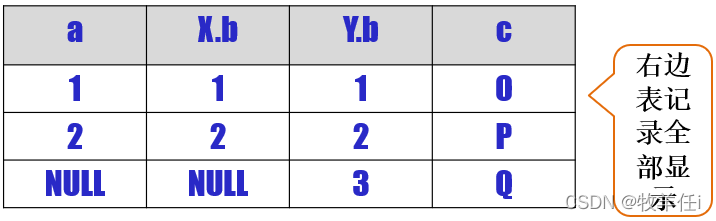
右侧表Y的元组(3,Q),虽未能在表X中找到相匹配的元组,单保留在结果当中
同时 a,X.b 的值用NULL填充
全外连接
语法格式:FROM 表1 FULL [OUTER] JOIN 表2 ON <连接条件>
【例】表 X 和 Y 进行右外连接语句
SELECT a, X.b, Y.b, c FROM X FULL OUTER JOIN Y ON X.b=Y.b
【例】查询所有读者借阅情况(包括没借阅图书的读者),显示读者编号,读者姓名,图书编号和书名。
SELECT R.reader_ID, R.name, B.book_ID, B.name
FROM Reader AS R LEFT JOIN Borrow
AS BW
ON R.reader_ID=BW.reader_ID LEFT
JOIN Book AS B ON B.book_ID=BW.book_ID
四、复杂查询
复杂查询UNION [ALL]
使用UNION语句可以合并两个或多个查询的结果。
UNION语句用第二个查询结果合并第一个查询结果。
它不显示两个查询中的重复的行。
如果想显示所有行(包括重复行)则可以在UNION后面添加ALL谓词
union的语法格式:
SELECT <目标列名序列> FROM <数据源> [WHERE <检索条件表达式>] [GROUP BY <分组依据列>] [HAVING <组提取条件>]
UNION [ALL]SELECT <目标列名序列> FROM <数据源> [WHERE <检索条件表达式>] [GROUP BY <分组依据列>] [HAVING <组提取条件>][ORDER BY <排序依据列> [ASC|DESC]]
注意:如果使用使用ORDER BY 字句进行排序,则该子句只出现最后一个查询的后面,如果不希望去除重复的元组,可以使用关键字ALL。
• 【例】
SELECT * FROM Book
WHERE publish='清华大学出版社'
UNION ALL
SELECT * FROM Book
WHERE price<25
ORDER BY name
因为使用了关键字ALL,结果中的重复元组被保留
在这个查询中的第二个查询后使用了ORDER BY 子句,使并集结果按书名name排序