【论文阅读】BiSeNet V2用于实时语义分割的双边网络

前言
BiSeNet V2延续了v1版本的双边结构,分别处理空间细节信息、高层语义信息。同时设计更简洁高效的结构,进行特征提取,实现高精度和高速度。在训练模型时,使用了增强训练策略 ,添加多个辅助训练分支来促进不同浅层网络的特征提取能力。
还设计了一个高效的特征融合模块,对空间细节信息、高级语义信息进行融合。
这个模型代码开源,亲自测试过(PyTorch版本),精度和速度都挺不错的;也适合部署到开发板,进行落地应用。
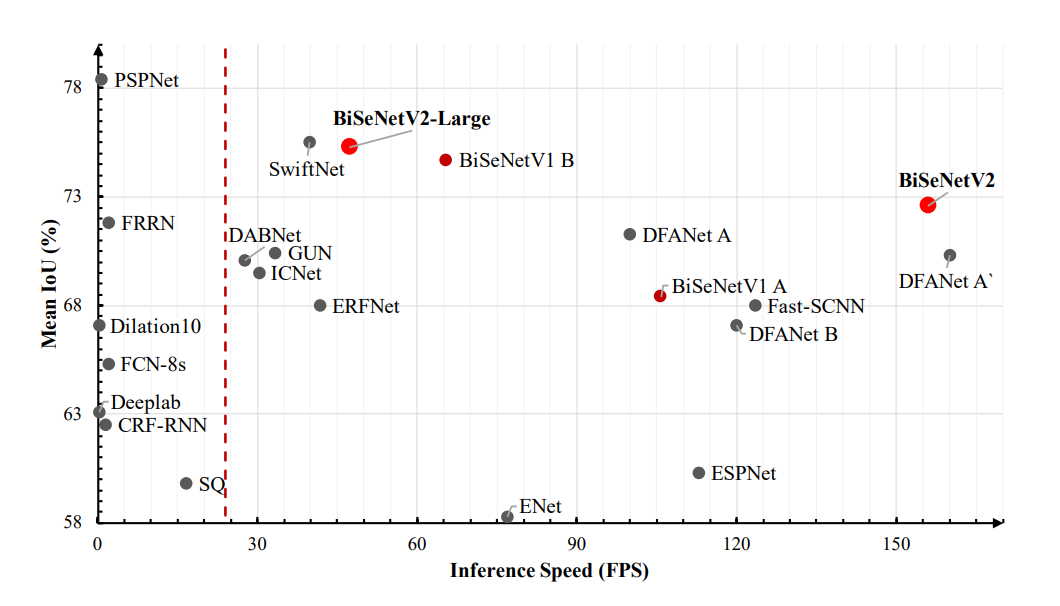
性能方面,BiSeNet V2,对于2048x1024的输入,在Cityscapes测试集中的平均IoU达到72.6%,在一张NVIDIA GeForce GTX 1080 Ti卡上的速度为156 FPS。
论文地址:https://arxiv.org/abs/2004.02147
代码地址(PyTorch):https://github.com/CoinCheung/BiSeNet
代码地址(Tensorflow):https://github.com/MaybeShewill-CV/bisenetv2-tensorflow
一、为什么要设计双边网络
在语义分割中,本质是对图像中每个像素进行分类,高层语义信息能让模型大概分清晰,这块区域像素是那个类别的,另一区域可能是其他类别的。毕竟高层语义信息,做了许多次下采样,输出的特征图相对于输入图片尺寸,可能相差(16、32、64...)倍数了;做上采样时让特征图恢复到原图大小,在不融入低层的空间细节信息,得到的分割效果会较差,很多边缘无法分割好。
丰富的空间细节信息,让模型对边缘也能分割得较好。但如果只有低层的空间细节信息,模型可能会无法进行分类,所以通常需要融合高层语义信息和层的空间细节信息。
那么不是有很多模型都能融合高层语义信息和层的空间细节信息吗?为什么都介绍这个BiSeNet V2呢?
1、它实时性好、精度高、轻量级、容易模型量化与部署;
2、BiSeNetv1中,创新的双边网络思想,设计空间细节分支和语义分支,达到实时语义分割;v2版本有模型结构的改进,引入新的训练策略,支持学习。
下面有三种语义分割的结构,
(a)是空洞卷积的主干网络,通过不同的空洞率设计卷积核,提取不同感受野的特征。 它具有沉重的计算复杂性和内存占用。
(b) 是编码器-解码器主干网络,它具有自上而下和横向的连接,以恢复高分辨率特征图。 网络中的这些连接对内存访问成本较高,虽然能达到高精度,但通常速度较慢。
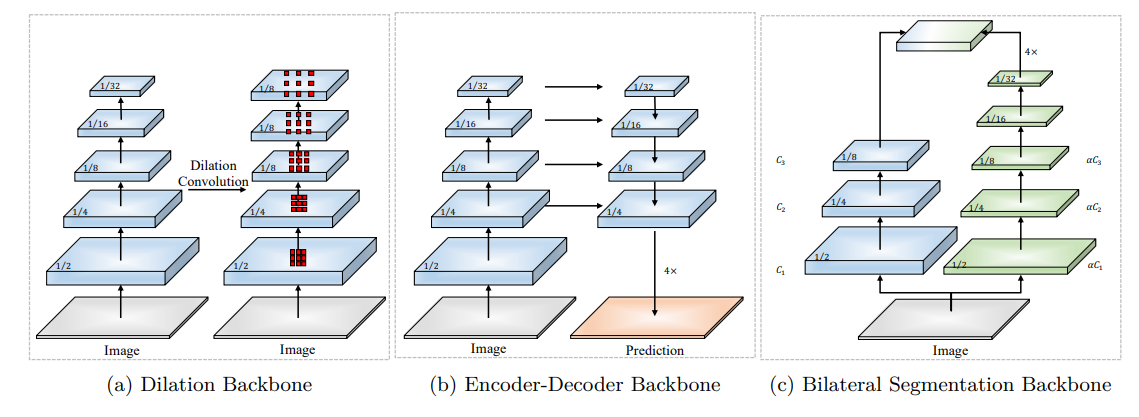
(c) 作者设计的双边分割主干网络, 它有2个分支,详细空间细节信息的分支和分类语义的语义分支。 细节分支通道宽,层数浅,而语义分支具有窄通道和深层;两个分支的通道数,可以通过因子(λ)调节,使其变得非常轻量级。
二、整体网络结构
模型主要由两个分支组成,一个是细节信息分支、另一个是语义分支,两个分是并行运行的;得到细节分支和语义分支,经过融合模型进行信息融合,最终输出与原图相同大小的图。
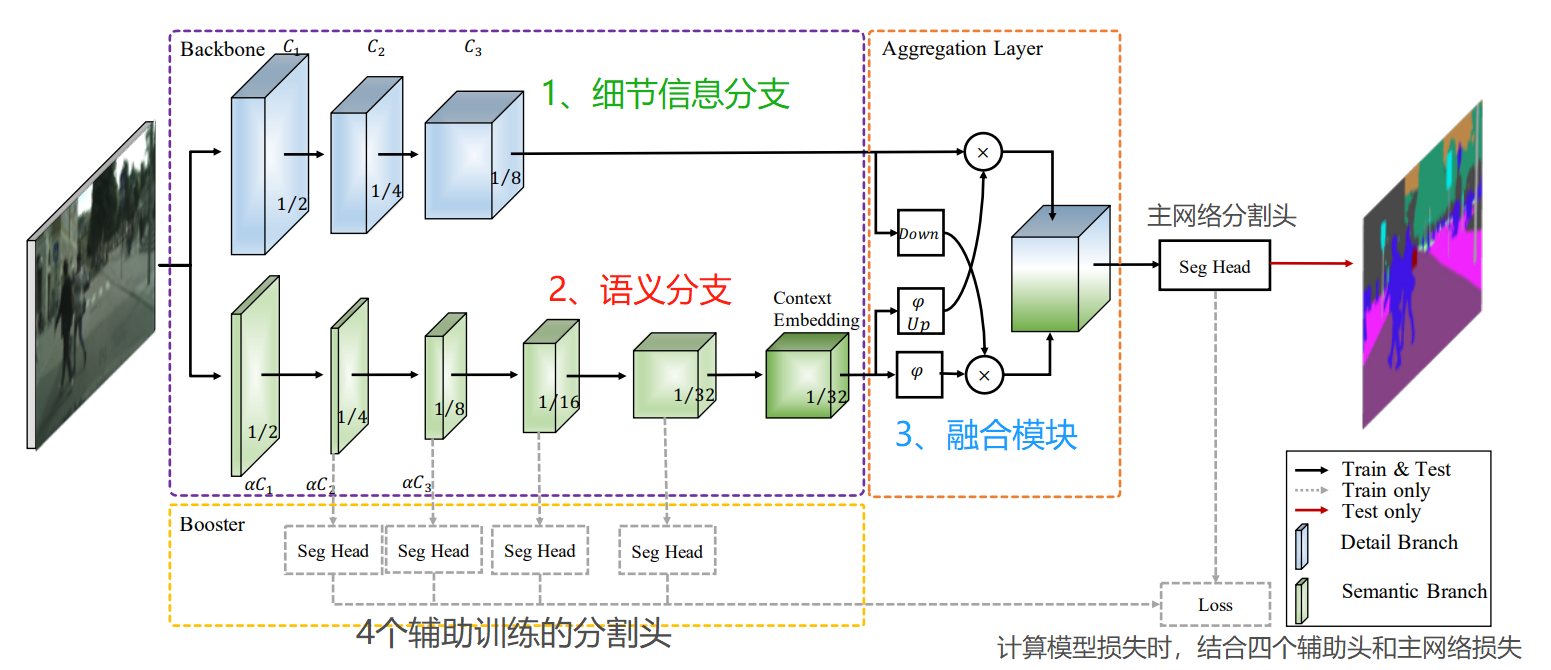
在语义分支中,作者添加了4个辅助训练的分割头,让浅层的信息更好地学习。在训练时,会结合4个辅助头的损失和主网络分割头的损失,一起计算损失。在推理时,不走4个辅助分割头,主网络的分割头会直接输出推理结果的。
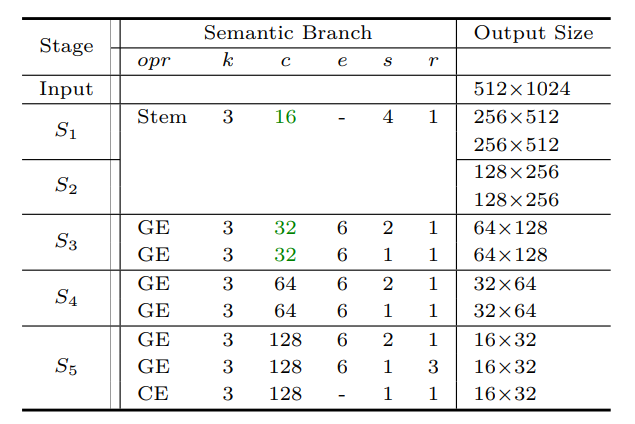
下面的表格是整体模型的参数:
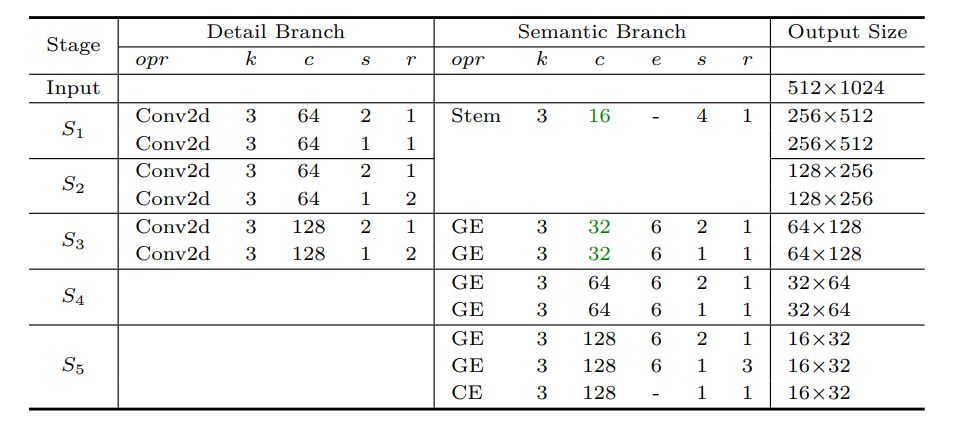
整体有5个阶段(S1-S5)。细节分支Detail Branch,有3个阶段;语义分支Semantic Branch,有5个阶段。
每个阶段包含一个或多个操作opr(例如,Conv2d、Stem、GE、CE)。 其中:Conv2d表示卷积层,然后是BN批归一化层和 relu 激活函数。 Stem表示stem block。 GE代表聚合和扩张层。 CE是上下文信息嵌入层。
每个操作都有一个内核大小 k,步长 s 和输出通道 c,重复 r 次。扩张因子 e 来扩展操作的通道数。这里的通道比为 λ = 1/4,绿色标记细节分支相应阶段的语义分支通道的比例;比如S1阶段,细节分支的通道数为64,语义分支的通道数为16。
2.1 细节分支
细节分支包含丰富的空间细节信息,这是低层(浅层)的信息,没有做太多的下采样,特征图尺寸大,用于提取空间细节信息。
对空间细节使用宽通道和浅层,得到特征表示具有较大的空间尺寸和较宽的通道。同时作者建议:最好不要采用残差连接,这会增加内存访问成本并降低速度。
2.2 语义分支
语义分支比较深,特征图尺寸小,感受野大,来捕获高级语义信息,利于对像素分类。
语义分支可以采用不同的轻量级卷积模型,同时使用窄通道和深层,快速下采样策略 (快速扩大感受野)、全局平均池嵌入全局上下文响应 (更大的感受野)。
2.3 融合模块
细节分支和语义分支是并行运行的,其中一个分支不知道另一个分支的信息,需要设计一个聚合层来融合两个分支的信息。考虑到准确性和效率,作者采用了双向聚合方法。
三、细节分支
细节分支的包含三个阶段,每个阶段的每一层都是一个卷积层,然后是批量归一化和激活函数。每个阶段的第一层具有步长s=2,而同一阶段中的其他层具有相同数量的过滤器和输出特征图大小。因此,该分支提取的输出特征映射是原始输入的1/8。

该细节分支的通道数量高,具有丰富的空间细节信息。由于通道数高,空间尺寸大,残差结构将增加内存访问成本。因此,该分支主要遵循VGG网络的原理来堆叠层。
四、语义分支
考虑到同时具有大的感受野和高效的计算,作者在设计语义分支时,参考轻量级识别模型的理念,例如,Xception,MobileNet,ShuffleNet。
语义分支结构参数如下:
-
作者采用Stem Block作为语义分支前部分特征提取,它使用两种不同的下采样方式来缩小特征表示;然后将两个分支的输出特征连接为输出。该结构具有高效的计算量和有效的特征表达能力。
-
中间部分使用GE聚集和扩张层,提取语义特征信息。
-
最后通过CE上下文信息嵌入层。语义分支需要大的感受野来捕获高级语义,作者设计了CE(Context Embedding Block),该块使用全局平均池和残差连接,有效嵌入全局上下文信息
语义分支中,有两个结构组件 Stem Block(GE)和Context Embedding Block(CE)。
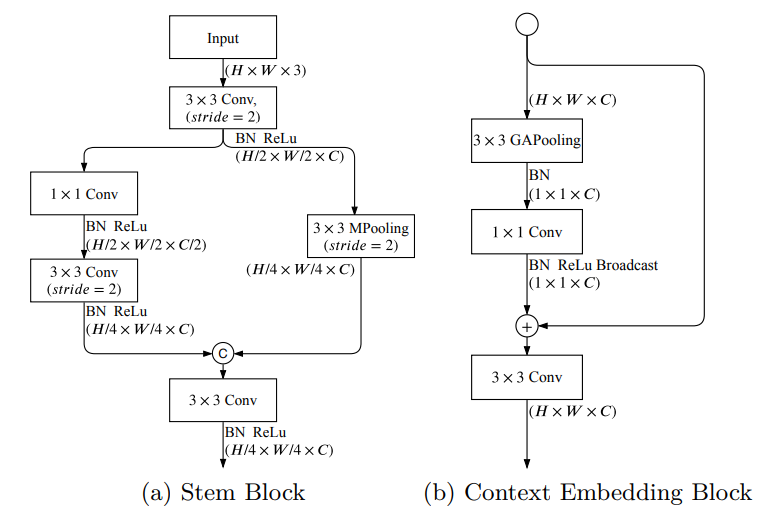
上图中,Conv是卷积运算,BN是批量归一化,ReLu是激活函数,Mpooling是最大池,GPooling是全局平均池,C表示拼接。同时,1×1,3×3表示核的大小,H×W×C表示张量形状(高度、宽度、通道)。
GE聚集和扩张层,结构如下图所示。
(a) 是MobileNet V2中提出的反向瓶颈Conv。步幅为2时,虚线快捷路径和求和不存在。
(b)(c)为聚集与扩展层,(b)是stide=1时的结构,(c)是stide=2时的结构,它们使用深度卷积,具有以下优势:
1、3×3卷积 以有效地聚集特征,并扩展到更高维空间;
2、在扩展层的每个单独输出通道上独立执行的 3×3深度卷积
3、1×1卷积作为投影层,将深度卷积的输出投影到低信道容量空间
当stide=2时,采用两个3×3深度卷积,进一步扩大了感受野,并采用一个3×3可分离卷积作为捷径。
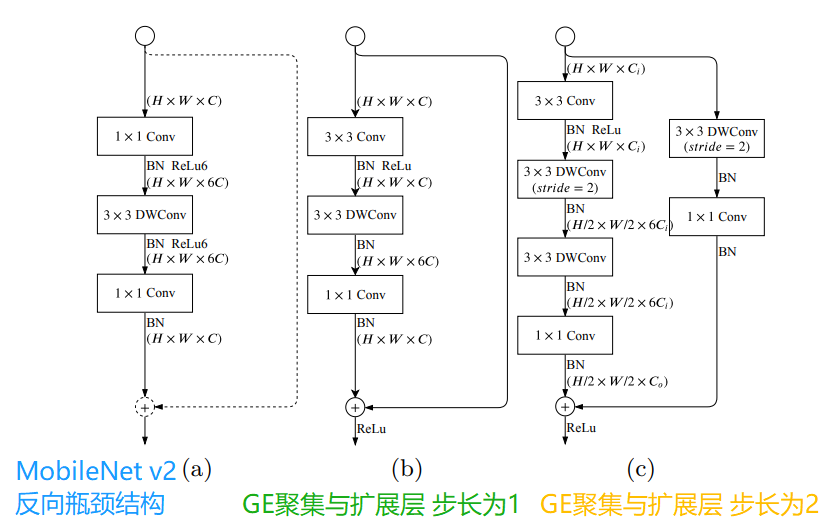
其中Conv是卷积运算,BN是批量归一化,ReLu是激活函数。同时,1×1,3×3表示核的大小,H×W×C表示张量形状(高度、宽度、通道)
特别点
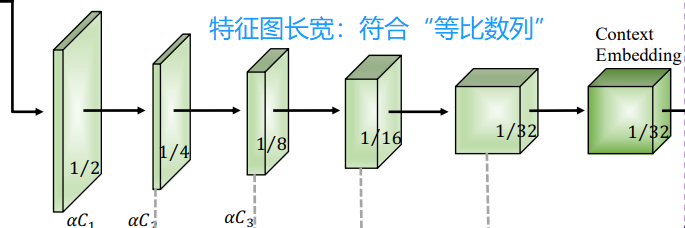
语义分支中,作者设计它符合等比数列;可以不同的设计。
1/2+1/4+1/8+1/8=1;
1/2+1/4+1/8+1/16+1/16=1;
1/2+1/4+1/8+1/16+1/32+1/32=1;
五、融合模块
常见的融合两种类型的特征图的方式,元素相加(add)和串联(concat)。
然而,在BiseNetv2中这两个分支的输出具有不同的特征表示级别。细节分支用于低级,语义分支用于高级。因此,简单的组合忽略了这两种类型信息的多样性,导致性能下降和难以优化。
作者提出了双边引导聚合层来融合来自两个分支的互补信息,如下图所示:
-
语义分支的一个输出,通过卷积和上采样操作,变成和细节分支相同尺寸的特征图,然后两者对于元素相乘,得到融合结果1(左边)。
-
细节分支的一个输出,通过卷积和池化进行下采样,变成和语义分支相同尺寸的特征图,然后两者对于元素相乘,得到融合结果2(右边)。
-
最后将融合结果1和融合结果2对于元素相加,再做一次卷积操作,输出最终结果。
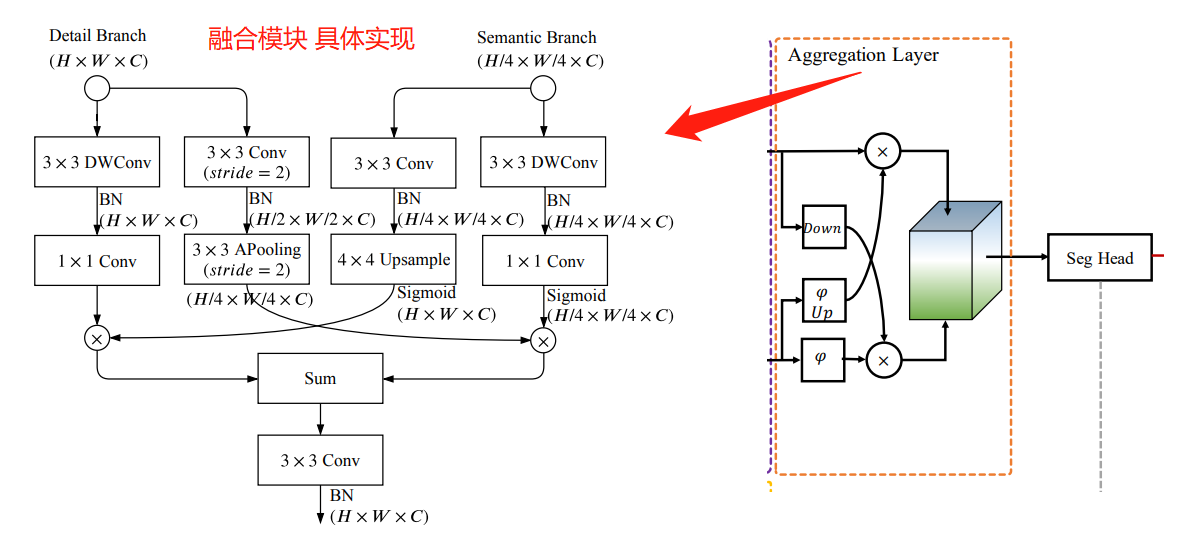
该层利用语义分支的上下文信息指导细节分支的特征。在不同的尺度引导下,可以捕获不同的尺度特征表示,这些特征表示模型编码了多尺度信息。同时,与简单的组合相比,这种引导方式能够实现两个分支之间的高效通信。
六、辅助训练分割头
作者提出了一种增强训练策略,它可以在训练阶段增强特征表示,在推理阶段可以丢弃。因此,在推理阶段增加的计算复杂度很小。如下图所示,可以将辅助分割头插入语义分支的不同位置。
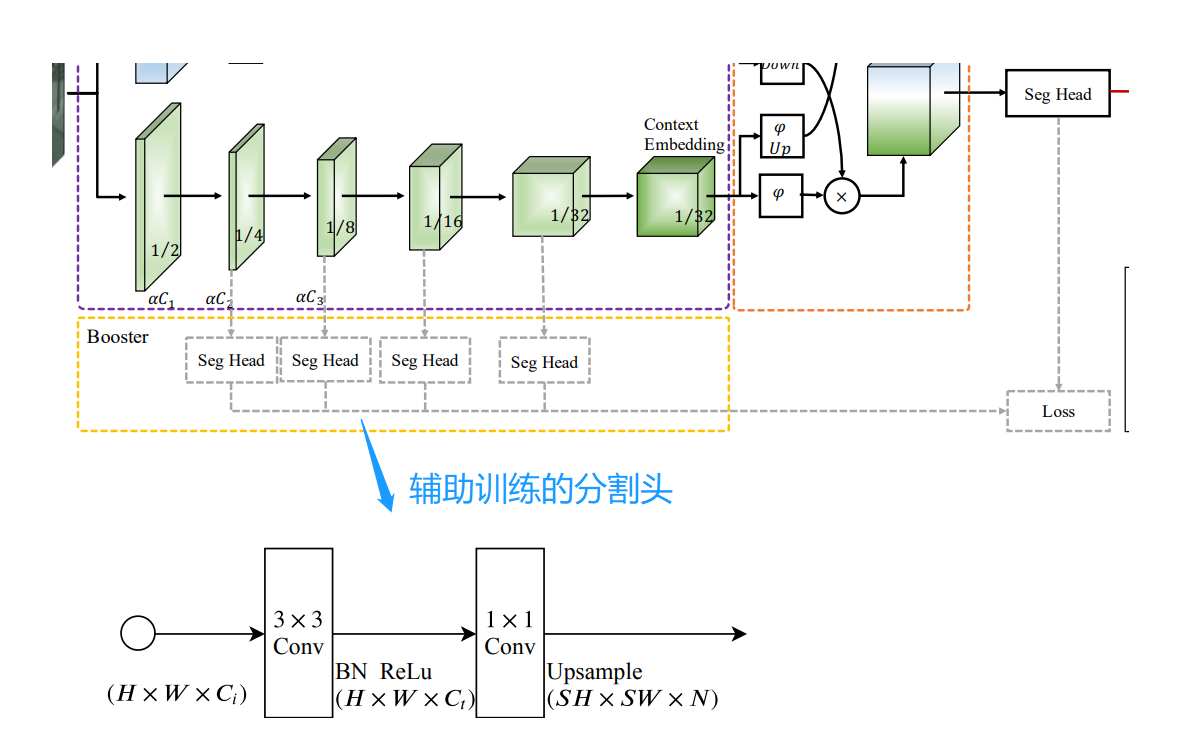
在语义分支中,作者添加了4个辅助训练的分割头,让浅层的信息更好地学习。在训练时,会结合4个辅助头的损失和主网络分割头的损失,一起计算损失。在推理时,不走4个辅助分割头,主网络的分割头会直接输出推理结果的。
七、总结
BiSeNet V2延续了v1版本的双边结构,分别处理空间细节信息、高层语义信息。同时设计更简洁高效的结构,进行特征提取,实现高精度和高速度。在训练模型时,使用了增强训练策略,添加多个辅助训练分支来促进不同浅层网络的特征提取能力。
它实时性好、精度高、轻量级、容易模型量化与部署;
本文只供大家参考与学习,谢谢~