【模态综合和增强:弱监督:医学图像融合】

MSE-Fusion: Weakly supervised medical image fusion with modal synthesis and enhancement
现有的多模态图像融合方法利用多模态图像作为输入,需要对患者进行多次成像,对患者的身体造成伤害,成本较大,而且图像融合需要大量配准图像,耗时且难以获得,并且融合图像的纹理和结构不清楚。因此,提出了一种具有模态综合和增强的弱监督医学图像融合方法。在模态综合中,使用弱监督方法训练模型以减少对配准图像的要求,并通过训练将MR图像作为输入,通过深层结构和浅细节生成器合成CT图像,以减少所需的输入模态,使纹理和结构更清晰。在图像增强中,MR图像通过训练的生成器以生成增强的MR图像,从而增强MR图像的纹理和结构。然后使用合成的CT和增强的MR图像以及原始PET图像作为输入,实现三模态图像融合。
介绍
随着医学影像的不断发展,医学影像已成为疾病诊断的有效工具。如今,医学图像包含各种模态,例如磁共振 (MR) 图像,计算机断层扫描 (CT) 图像,正电子发射断层扫描 (PET) 图像等,每种模态都有其优缺点。例如,CT图像可以很好地显示骨骼信息,但不能清楚地表征软组织等结构信息。MR图像可以充分显示软组织信息,但是它们在骨骼信息表示方面存在明显缺陷。PET图像可以提供关于人体代谢的丰富的临床信息,但是图像的分辨率低。因此,将CT,MR和PET图像信息集成到一个图像中,以完成多模态图像融合,可以提供来自不同模态的互补信息。多模态融合图像保留了原始图像的特征 ,同时补偿了单模态图像的局限性并显示出丰富的详细信息,这可以帮助医生准确有效地诊断疾病。
传统的图像融合方法可以保留多模态的源图像信息,实现多模态医学图像融合。然而,它们在特征提取过程中失去了关键特征的目标 ,并且很难完全表征融合图像中的深层结构和浅细节信息。近年来,深度学习在图像处理领域得到了广泛的应用,如模态综合、图像融合、图像分割,由于其出色的特征提取能力,并取得了良好的性能。卷积神经网络 (CNN) 作为深度学习的代表性方法 ,在图像融合中发挥着越来越重要的作用 。例如,Li和Wu提出的基于CNN的DenseFuse融合方法和Zhang等人提出的IFCNN融合方法具有出色的特征融合能力,但就医学图像的纹理细节信息而言,它们的特征提取过程准确性较低。生成对抗网络 (GAN) 通过生成器和鉴别器之间的相互对抗来提高图像特征提取的准确性。Zhou等提出了基于GAN的Hi-Net 混合融合网络,有效地提高了图像融合性能,但精细结构的表示仍不够清晰。此外,上述方法基于监督训练,这需要大量注册的配对训练图像。此外,图像配准过程既耗时又费力。
此外,现有的多模态医学图像融合方法需要将多模态医学图像一起用作输入。但是患者在诊断过程中需要进行多次医学成像以获得多模式融合图像。在医学成像中产生的高辐射可能对患者健康有害,并且医学成像的高成本使得其对患者来说非常昂贵。因此,有必要引入一种多模态医学图像融合方法,该方法可以减少医学成像对患者身体的伤害并降低成本。 模态综合作为一种图像处理技术,可以从一个模态图像执行到另一个模态图像。CT和MR图像包含丰富的特征信息,从MR图像中合成具有较少细节信息的CT图像,与从CT图像合成MR图像相比,具有更多纹理细节信息,可以保留更多的图像信息。因此,我们引入模态综合作为图像融合的基础,以最小化图像融合过程中输入图像的模态。与需要三种模态作为输入的现有图像融合方法相比,我们的方法首先将单个模态图像合成为具有两种模态(一个是本体,一个是输入的另一种模态图像)作为输入。它可以减少成像次数,对患者的伤害以及成本。
近年来,随着GAN的进步,在模态综合领域取得了显著的成果,Nie等提出了一种基于GAN的单发生器和鉴别器的模态综合方法 通过对抗性学习生成逼真的合成图像。尽管与目标预测图像相比,合成图像具有良好的结构特征,但图像细节模糊,无法很好地表征图像纹理细节。Wang等人提出了一种自动基于上下文的GAN合成方法,以使合成的图像保留更详细的特征。他们利用自动上下文方法从源图像中提取更多的图像特征,这可以增强合成图像中的关键信息。但是,纹理细节信息和精细结构的清晰度仍有待提高。Jiang等人、Tang等人开发了一种基于GAN的全局-局部发生器模态综合网络,该网络采用两个发生器来学习和呈现全局信息,即图像结构信息,并增强细节信息,即图像纹理和精细结构。它渲染具有完整的全局结构表示以及增强的图像细节的合成图像,但是其纹理细节和精细结构的表示不稳定。Zhu等人通过采用双生成器和双重鉴别器提出了无监督循环一致的生成对抗网络 (CycleGAN),这获得了详细信息清晰度的显著改进,但是精细结构的表示仍然不够清晰。
针对上述问题,提出了一种模态综合和增强的弱监督医学图像融合方法 (MSE-fusion)。
贡献
1)我们分析了当前多模态图像融合方法中存在的问题,例如使用多个模型作为输入,需要对患者进行多次成像,从而对患者的身体造成伤害,并且成本较高,需要大量注册图像,这确实很难获得并且耗时,同时也不清楚融合图像的纹理和结构。
2)我们提出了一种基于CycleGAN的多生成器模态综合网络,该网络使用弱监督训练方法来降低对配准图像的要求。将生成器分为用于突出高级信息 (例如整体图像结构) 的深层结构生成器和用于突出低级信息 (例如图像纹理和精细结构) 的浅细节生成器,以解决当前融合方法的纹理和结构不清晰的问题。
3)我们提出了一种基于模态综合和图像增强的图像融合方法。与现有的使用多种模态作为输入的图像融合方法不同,我们的方法通过首先通过模态综合从MR图像中合成CT来减少所需的输入模态,并通过图像增强生成增强的MR图像,从而实现多模态图像融合,增强后的MR图像的纹理和结构更清晰。然后使用合成的CT和增强的MR图像以及原始PET图像作为输入,实现三模态图像融合。
4)通过与13种最先进的模态综合和图像融合方法相比,对7个客观评估指标进行了实验,验证了该方法的性能。所提出的方法在主观视觉效果和客观评价指标上都优于现有的图像融合方法。
相关工作
Deep learning in image processing
近年来,深度学习在模态综合和图像融合 以其强大的特征提取能力,并取得了良好的效果。其中,CNN在图像处理领域也发挥了越来越重要的作用。例如,Li和Wu提出了一种基于CNN的DenseFuse图像融合方法,该方法具有良好的图像处理能力,但其特征提取过程精度较差。GAN作为一种深度学习方法,通过生成器和鉴别器的相互对抗,提高了图像特征提取的准确性,使得更多源图像信息保留在图像处理后的图像中。但是,图像细节模糊,无法很好地表征图像纹理细节。Zhu等人提出了CycleGAN,其使用具有双重鉴别器的双生成器来循环训练网络,从而在详细信息的图像表示的定义方面做出了显著的改进。
CycleGAN
Zhu等人提出了使用未配对图像进行图像到图像转换的周期一致的生成对抗网络 (CycleGAN)。CycleGAN是一种将图像从源域 𝑋 变换到目标域 𝑌 的方法,没有成对的图像。目标是学习域 𝑋 和 𝑌 之间的两个映射函数 𝐺 ∶ 𝑋 → 𝑌 和 𝐹 ∶ 𝑌 → 𝑋。给定训练样本 {𝑥𝑖 }𝑁 𝑖=1,{𝑦𝑖 }𝑁𝑗=1,其中 𝑥𝑖 ∈ 𝑋,𝑦𝑗 ∈ 𝑌,数据分布记为 𝑥 ~ 𝑝𝑑𝑎𝑎𝑡𝑡( 𝑥),𝑦 ~ 𝑝𝑑𝑎𝑡𝑡𝑎 (𝑦)。此外,网络中使用了两个对抗性鉴别器 𝐷𝑋 和 𝐷𝑌。其中 𝐷𝑋 旨在区分图像 {𝑥} 和变换图像 {𝐹 (𝑦)}。𝐷𝑌 旨在区分图像 {𝑦} 和变换图像 {𝐺 (𝑥)},如图1(a) 所示。网络包含两种类型的损失函数: 对抗损失和周期一致性损失。对抗损失使生成的图像的数据分布与目标域匹配。网络包含两种类型的损失函数: 对抗损失和周期一致性损失。对抗损失使生成的图像的数据分布与目标域匹配。如图1(b) 所示,域 𝑋 中的每个图像 𝑥 满足 𝑥 → 𝐺 (𝑥) → 𝐹 (𝐺 (𝑥)) ≈ 𝑥,称为前向循环一致性。同样,如图1© 所示,对于域 𝑌 中的每个图像 𝑦,𝐺 和 𝐹 也应满足逆循环一致性 𝑦 → 𝐹 (𝑦) → 𝐺 (𝐹 (𝑦)) ≈ 𝑦。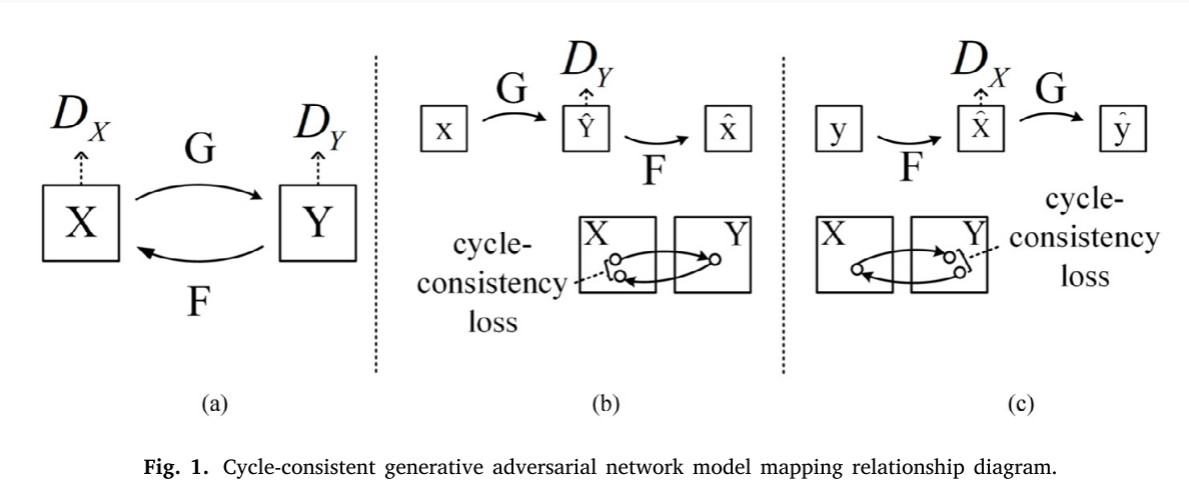
Deep learning segmentation network for multi-modal medical images (OctopusNet)
为了更好地提取包含在多模态图像中的关键信息,Chen等人提出了一种用于多模态医学图像的深度学习分割网络,称为OctopusNet。如图2所示,该网络针对每个输入模态使用单独的模态编码器来执行特征提取,从而可以保留源图像的更多结构和细节信息。这里,每个模态编码器中的不同立方体表示从不同阶段生成的特征图。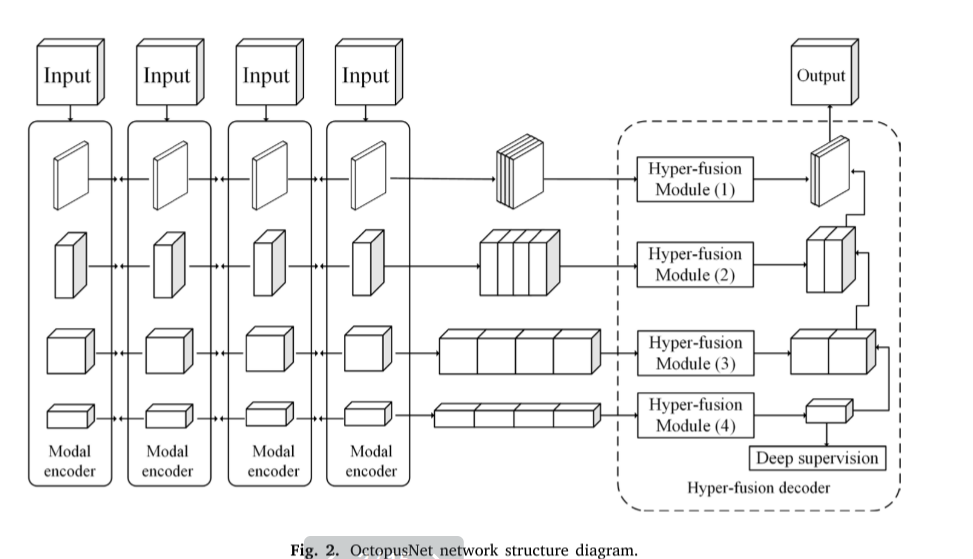
为了更好地利用不同模态中包含的显式信息,将提取的特征图级联并馈送到超融合解码器。超融合解码器采用超融合模块进行特征融合,并使用深度监督来更好地训练收敛。然后,将融合的特征图与上采样的特征图连接以产生分割结果。该网络获得了优异的分割精度,优于常见的特征融合方法。
方法
针对文中提出的问题,以 (1) 减少对多模态图像融合中患者的多重医学成像的需求,以最大程度地降低成本和对患者健康的危害;(2) 解决了图像融合需要配准大量成对的图像,使其耗时且困难的问题; (3) 使融合图像的纹理和精细结构更加清晰。我们提出了一种具有模态综合和增强功能的弱监督医学图像融合方法,称为MSE融合。
该方法由模态合成、图像增强和图像融合三部分组成,如图3所示。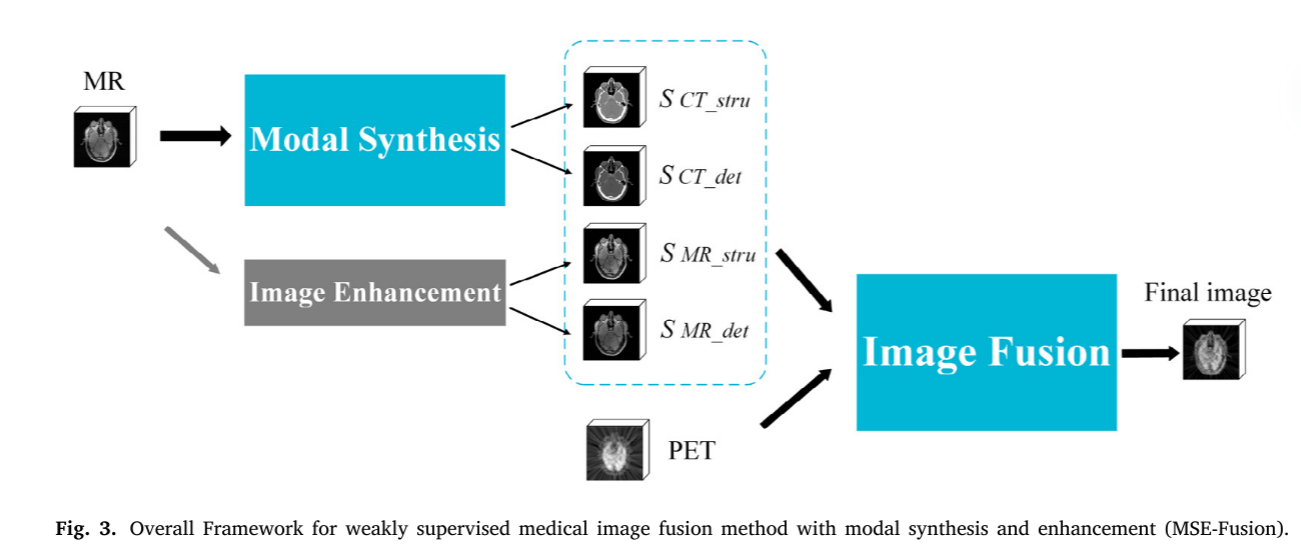
在模态综合中,我们提出了一种基于CycleGAN的多生成器模态综合网络。它将生成器分为深层结构和浅层生成器。深层结构生成器用于突出显示高级信息,例如整体图像结构。并且使用浅细节生成器来突出显示低级信息,例如图像纹理和精细结构。以CT、MR、PET三模态图像融合为例,在模态综合中,将MR图像输入到多生成器模态综合网络训练的发生器中,生成深结构合成图像𝑠𝐶𝑇_𝑠𝑡𝑟u和浅细节合成图像 𝑠𝐶𝑇_𝑑𝑒t。在图像增强中,MR图像通过基于GAN的双生成器图像增强网络训练的结构和细节生成器,生成具有更突出的深层结构增强图像 𝑠𝑀R_𝑠𝑡𝑟𝑢 和浅细节增强图像 𝑠𝑀R_𝑑𝑒𝑡的增强MR图像。
在图像融合中,通过模态合成和图像增强生成的CT和MR图像𝑠𝐶𝑇_𝑠𝑡𝑟u,𝑠𝐶𝑇_𝑑𝑒t,𝑠𝑀R_𝑠𝑡𝑟𝑢,𝑠𝑀R_𝑑𝑒𝑡,并将原始PET图像送入基于OctopusNet的生成对抗网络进行多模态图像融合。它逐层由浅入深地提取图像信息,并将获得的各层特征图进行融合,输入到训练好的图像融合发生器中,得到具有CT、MR、PET三模态特征的融合图像。
Multi-generator modal synthesis
如图4所示,多生成器模态综合包括两个阶段: 模态综合训练和模态综合预测。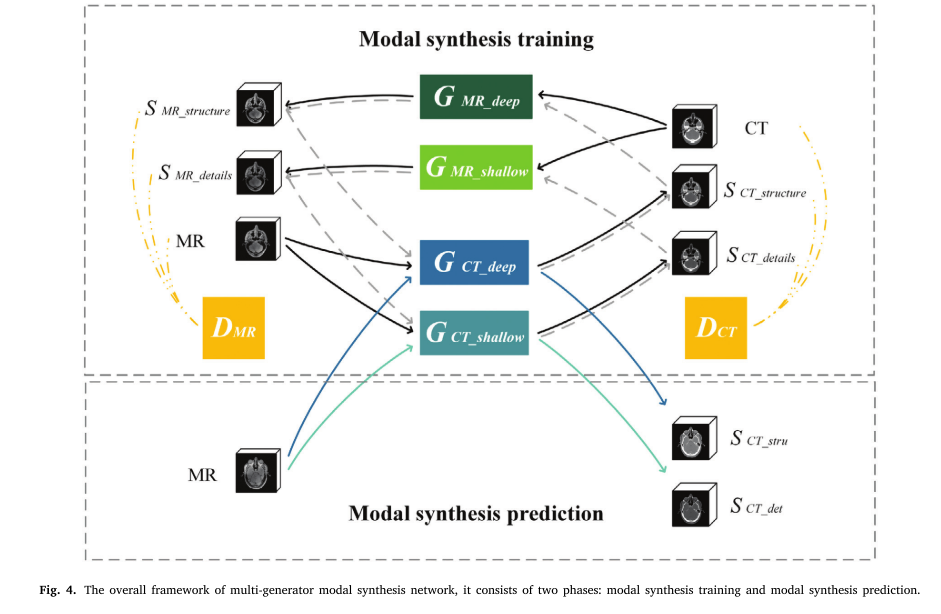
在模态综合训练中,网络是基于CycleGAN的,从MR图像中合成CT有两个生成器: deepstructure生成器 𝐺𝐶T_𝑑𝑒𝑒𝑝 和浅细节生成器 𝐺𝐶T_𝑠ℎallow。以及两个用于从CT图像合成MR的生成器: 深层结构生成器 𝐺𝑀R_𝑑𝑒𝑒𝑝 和浅细节生成器 𝐺𝑀R_𝑠ℎallow。通过四个生成器与模态综合鉴别器 𝐷𝐶𝑇 、 𝐷~𝑀𝑅 ~的相互对抗循环训练网络,不断提取图像的深层结构和浅层细节特征,提高发生器的图像合成性能。
在模态综合预测中,MR图像作为输入提供给训练好的 𝐺𝐶T_𝑑𝑒𝑒𝑝 和 𝐺𝐶T_𝑠ℎallow,以合成CT图像 𝑠𝐶𝑇_𝑠𝑡𝑟u和𝑠𝐶𝑇_𝑑𝑒t。
Modal synthesis training
模态综合利用弱监督方法,以少量配对图像和大量未配对图像作为训练数据对模型进行训练。首先以配对的MR和CT图像训练模型,然后以未配对的MR和CT图像作为训练集,同时加载以配对的MR和CT图像训练的模型作为训练集,继续进行多发电机模态综合网络的训练。其中成对的CT和MR图像提高了图像结构,纹理细节和精细结构的准确性,而不成对的CT和MR图像减少了配准的难度和时间。模态综合作为图像融合的基础,不仅保留了更多源图像结构和细节信息,而且解决了图像融合需要配准的成对图像,获得大量成对图像既耗时又困难的问题。
模态综合训练过程如图5所示。
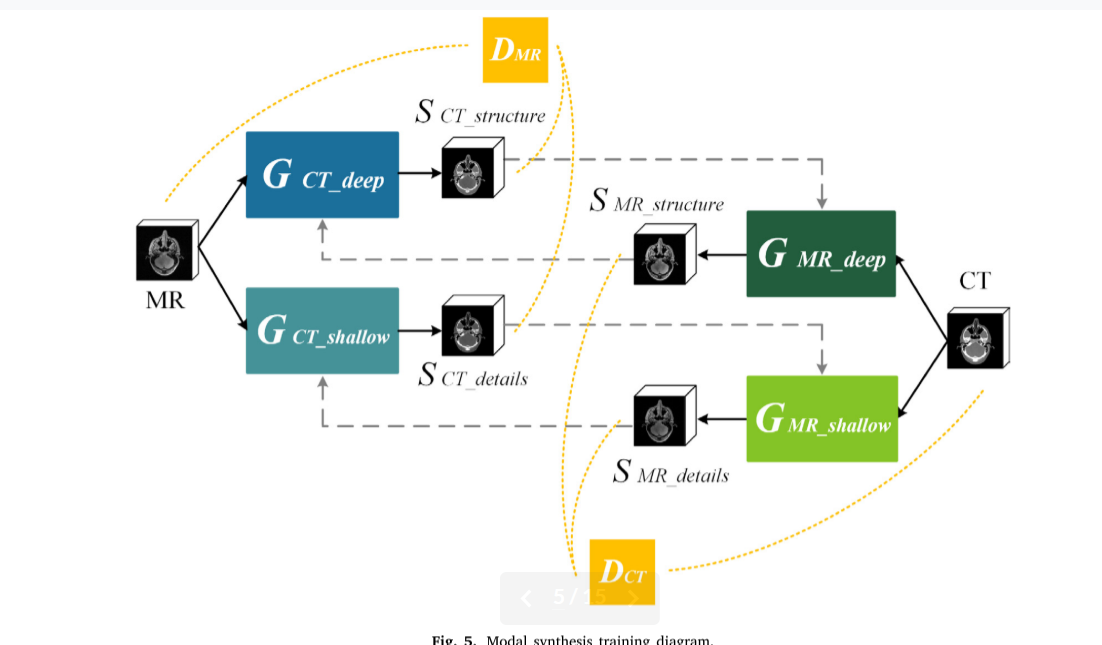
首先,将MR图像作为训练数据输入到 𝐺𝐶𝑇_𝑑𝑒𝑒𝑝 和𝐺𝐶T_𝑠ℎallow 中,生成CT深层结构合成图像 𝑠𝐶𝑇_𝑠𝑡𝑟ucture和CT浅细节合成图像 𝑆𝐶𝑇_𝑑𝑒𝑡ails。作为训练数据的CT图像还输入 𝐺𝑀𝑅_𝑑𝑒𝑒𝑝和 𝐺𝑀𝑅_𝑠ℎallow,生成MR深度结构合成图像 𝑆𝑀R_𝑠𝑡𝑟ucture 和MR浅细节合成图像 𝑆𝑀R_𝑑𝑒𝑡ails 。然后,将 𝑠𝐶𝑇_𝑠𝑡𝑟ucture和 𝑆𝐶𝑇_𝑑𝑒𝑡ails输入到 𝐺𝑀𝑅_𝑑𝑒𝑒𝑝 和 𝐺𝑀𝑅_𝑠ℎallow,并将 𝑆𝑀R_𝑠𝑡𝑟ucture 和 𝑆𝑀R_𝑑𝑒𝑡ails输入到 𝐺𝐶𝑇_𝑑𝑒𝑒𝑝 和 𝐺𝐶T_𝑠ℎallow。𝐺𝐶𝑇_𝑑𝑒𝑒𝑝 𝐺𝐶𝑇_𝑠ℎ𝑎𝑙𝑙𝑜𝑤 和 𝐷𝐶𝑇,以及𝐺𝑀𝑅_𝑑𝑒𝑒𝑝,𝐺𝑀𝑅_𝑠ℎ𝑎𝑙𝑙𝑜𝑤 和𝐷𝑀𝑅之间的相互对抗,显著提高生成器的模态综合性能。
其中,深层结构生成器 𝐺𝐶𝑇_𝑑𝑒𝑒𝑝 和 𝐺𝑀𝑅_𝑑𝑒𝑒𝑝用于突出高级信息,如整体图像结构,它包含编码、变换和解码三个部分。每个层的参数设置如图6(a) 所示。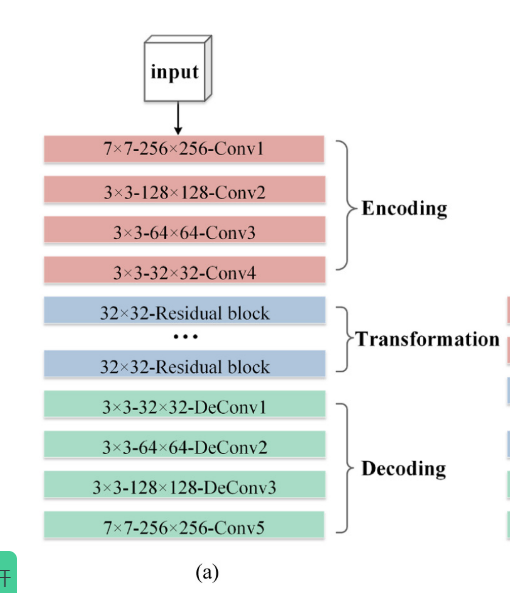
首先,输入图像传递到编码部分,用于图像的深度特征提取,该编码部分由四个卷积层Conv1,Conv2,Conv3和conv4组成。在这里,Conv1表示具有k个滤波器和步长1的7 × 7的卷积-InstanceNorm-remu层。Conv2,Conv3和Conv4是3 × 3的卷积-InstanceNorm-remu层,具有k个滤波器和步长2。其次,从一种模态到另一种模态的综合由变换部分完成,它有九个残差块。最后,提取的特征图像被馈送到解码部分以恢复图像。最后,解码部分包括三个反卷积层decov1,decov2和decov3,其中一个卷积层conv5。Decov1、decov2和decov3是3 × 3的分数阶卷积-InstanceNorm-relu层,具有k个滤波器和步长1/2。Conv5表示7 × 7的卷积-InstanceNorm-remu层,具有k个滤波器和步长1。
浅层细节生成器 𝐺𝐶T_𝑠ℎallow 和𝐺𝑀𝑅_𝑠ℎallow强化了底层信息,如图像纹理和精细结构,还包含三个部分: 编码、变换和解码。每个层的参数如图6(b) 所示设置。
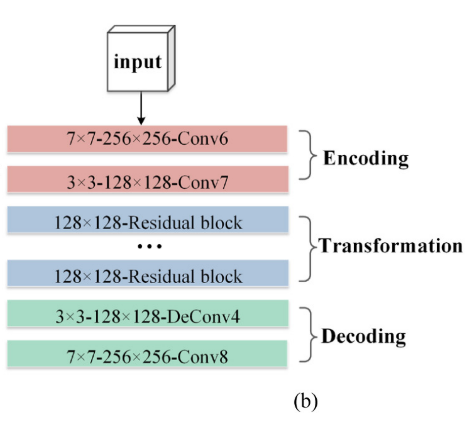
编码部分具有两个卷积层Conv6和Conv7,内部结构与Conv1和conv2相同。变换部分也有九个残差块。解码部分包括一个反卷积层decov4和一个卷积层Conv8,内部结构与decov3和conv5相同。
同时,在模态综合训练过程中,𝐷𝐶𝑇 和 𝐷𝑀R判别合成图像和原始训练图像的真实性,提高深度结构和浅细节生成器的综合效果。在从MR图像合成CT的过程中,𝐷𝐶𝑇 识别合成图像 𝑠𝐶𝑇_𝑠𝑡𝑟ucture、𝑆𝐶𝑇_𝑑𝑒𝑡ails与原始CT训练图像之间的真实性。在从CT图像合成MR的过程中,𝐷𝑀𝑅 识别了 𝑆𝑀R_𝑠𝑡𝑟ucture、 𝑆𝑀R_𝑑𝑒𝑡ails与原始MR训练图像之间的真实性。在训练过程中,该模型通过对抗性损失和周期一致性损失学习深层结构信息的 𝑋𝑀𝑅 和 𝑌𝐶𝑇域以及浅细节信息的 𝑋 ′𝑀𝑅和 𝑌 ′𝐶𝑇域。同时,该模型包括四个映射函数: 𝐺 ∶ 𝑋𝑀𝑅 → 𝑌𝐶𝑇,𝐹 ∶ 𝑌𝐶𝑇 → 𝑋𝑀𝑅,𝑀∶ 𝑋′𝑀𝑅 → 𝑌′𝐶𝑇 以及 𝑁 ∶ 𝑌′𝐶𝑇 → 𝑋′𝑀𝑅 。给定训练样本 {𝑥𝑖 }𝑁𝑖=1,{𝑦𝑗 }𝑁𝑗=1,其中 𝑥𝑖 ∈ 𝑋𝑀𝑅,𝑋 ′ 𝑀𝑅,𝑦𝑗 ∈ 𝑌𝐶𝑇,𝑌 ′𝐶𝑇。数据分布表示为 𝑥 〜 𝑝𝑑𝑎𝑡𝑎 (𝑥),𝑦 〜 𝑝𝑑𝑎𝑡𝑎( 𝑦),并将对抗性损失应用于四个映射函数。从MR图像合成CT的对抗性损失 𝐺 ∶𝑋𝑀𝑅 → 𝑌𝐶𝑇,𝑀 ∶ 𝑋′𝑀𝑅 → 𝑌′𝐶𝑇 和 𝐷𝐶𝑇 如Eqs(1) 和 (2)所示: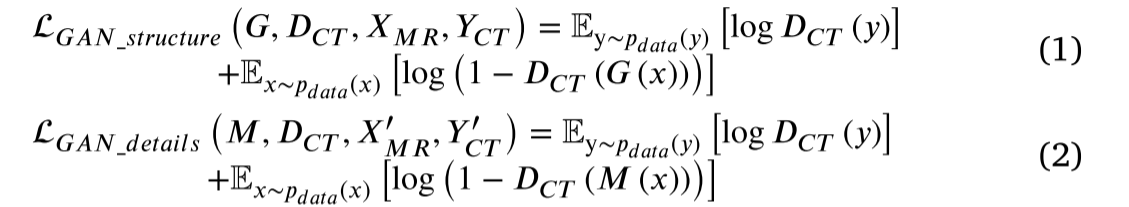
由CT图像合成MR的对抗性损失: 𝐹 ∶ 𝑌𝐶𝑇 → 𝑋𝑀𝑅, 𝑁 ∶ 𝑌′𝐶𝑇 → 𝑋′𝑀𝑅 以及𝐷𝑀𝑅,如Eqs(3) 和 (4)所示:
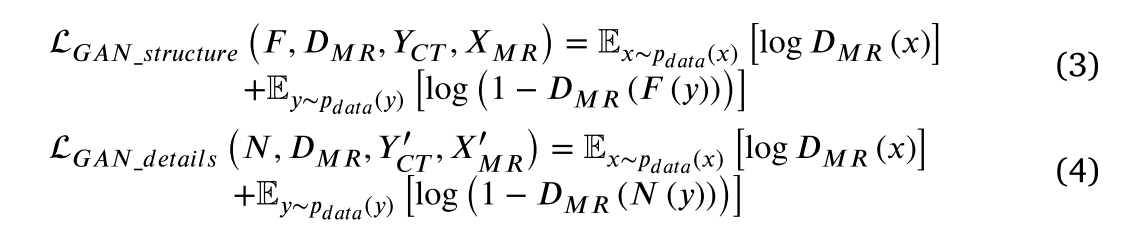
类似地,我们引入了周期一致性损失 𝐺 ∶ 𝑋𝑀𝑅 → 𝑌𝐶𝑇,𝐹 ∶ 𝑌𝐶𝑇 → 𝑋𝑀𝑅,𝑀∶ 𝑋′𝑀𝑅 → 𝑌′𝐶𝑇 以及 𝑁 ∶ 𝑌′𝐶𝑇 → 𝑋′𝑀𝑅 映射,如Eqs(5) 和 (6)所示: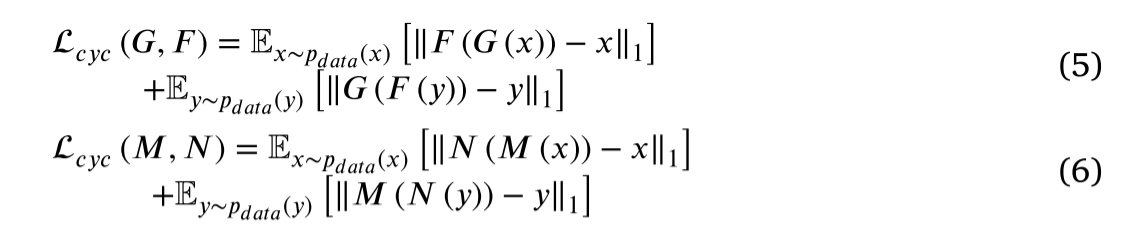
因此,深层结构信息的总目标函数如公式(7)所示: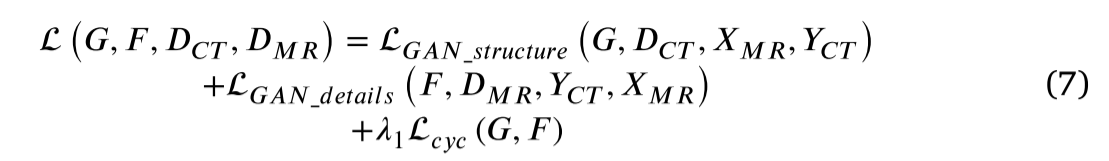
浅薄细节信息的总目标函数如公式(8)所示,其中 𝜆1,𝜆2控制目标的相对重要性。因此,总目标函数如公式(9)所示: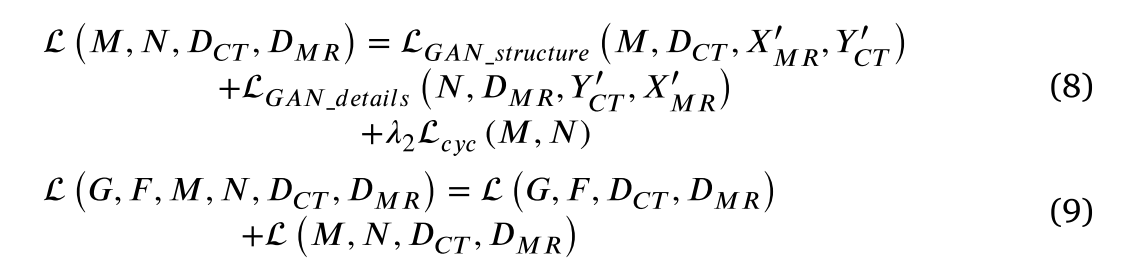
Modal synthesis prediction
在模态综合预测过程中,如图7所示,MR图像被送入训练好的 𝐺𝐶𝑇_𝑑𝑒𝑒𝑝和 𝐺𝐶𝑇_𝑠ℎallow,以合成 𝑠𝐶𝑇_𝑠𝑡r𝑢 和 𝑠~𝐶𝑇_ 𝑑𝑒𝑡~,在图像结构和细节信息方面都具有优越性。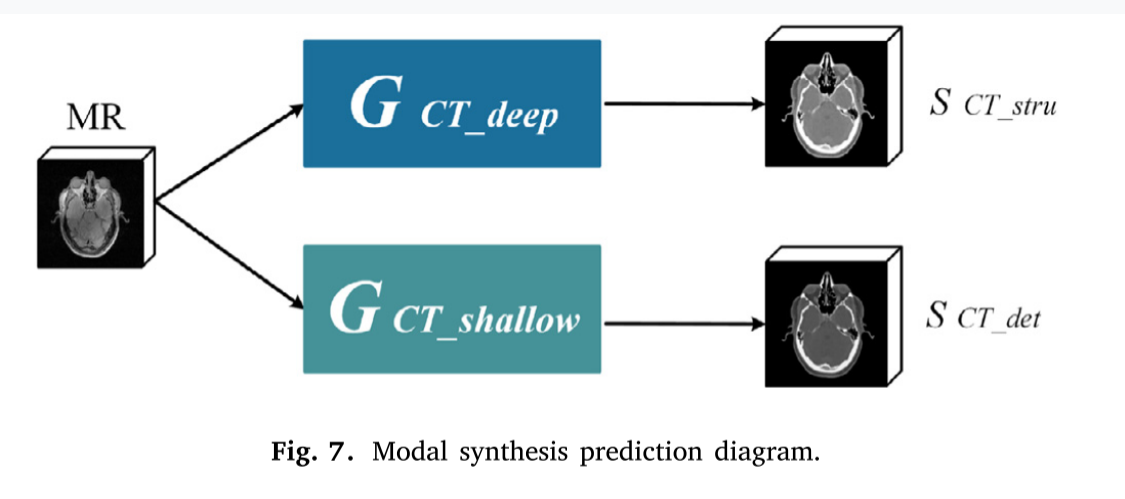
Dual-generator image enhancement
基于GAN的双生成器图像增强网络内部包含结构生成器 𝐺𝑠𝑡𝑟𝑢𝑐𝑡ure、细节生成器 𝐺𝑑𝑒𝑡和用于特征增强的增强型判别器 𝐷𝑒𝑛。在图像增强训练过程中,如图8(a) 所示,通过 𝐺𝑠𝑡𝑟𝑢𝑐𝑡ur𝑒、 𝐺𝑑𝑒𝑡𝑎i𝑙 和𝐷𝑒𝑛的相互对抗,提升了两个生成器的特征增强性能。在这里,两个生成器都由两部分组成: 编码和解码。𝐺𝑠𝑡𝑟𝑢𝑐𝑡ur𝑒的内部结构与 𝐺𝐶𝑇_𝑑𝑒𝑒𝑝 和 𝐺𝑀𝑅_𝑑𝑒𝑒𝑝 的编码和解码部分相同。𝐺𝑑𝑒𝑡𝑎𝑖l的结构与 𝐺𝐶𝑇_𝑠ℎallow和 𝐺𝑀𝑅_𝑠ℎallow的编码和解码部分相同。𝐷𝑒𝑛 的内部结构是基于CycleGAN鉴别器。在图像增强预测过程中,如图8(b) 所示,MR图像被输入到训练好的 𝐺𝑠𝑡𝑟𝑢𝑐𝑡𝑢𝑟𝑒和 𝐺𝑑𝑒𝑡𝑎i𝑙, 生成 𝑠𝑀𝑅_𝑠𝑡𝑟和 𝑠𝑀𝑅_𝑑𝑒𝑡。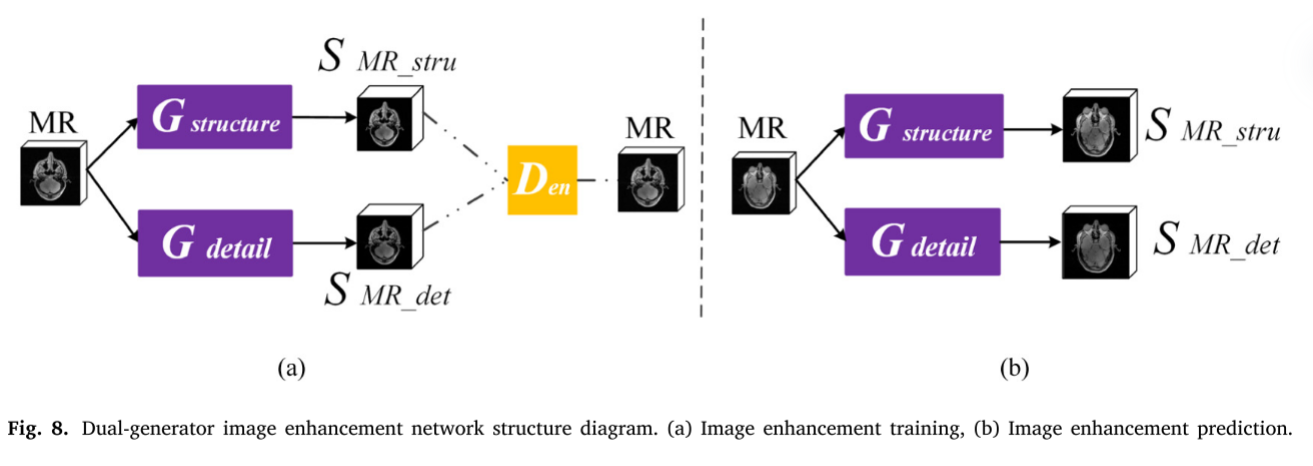
Generative adversarial network for multi-modal image fusion
基于OctopusNet的多模态图像融合的生成对抗网络包含三个部分: 编码,融合和解码。其网络结构如图9所示。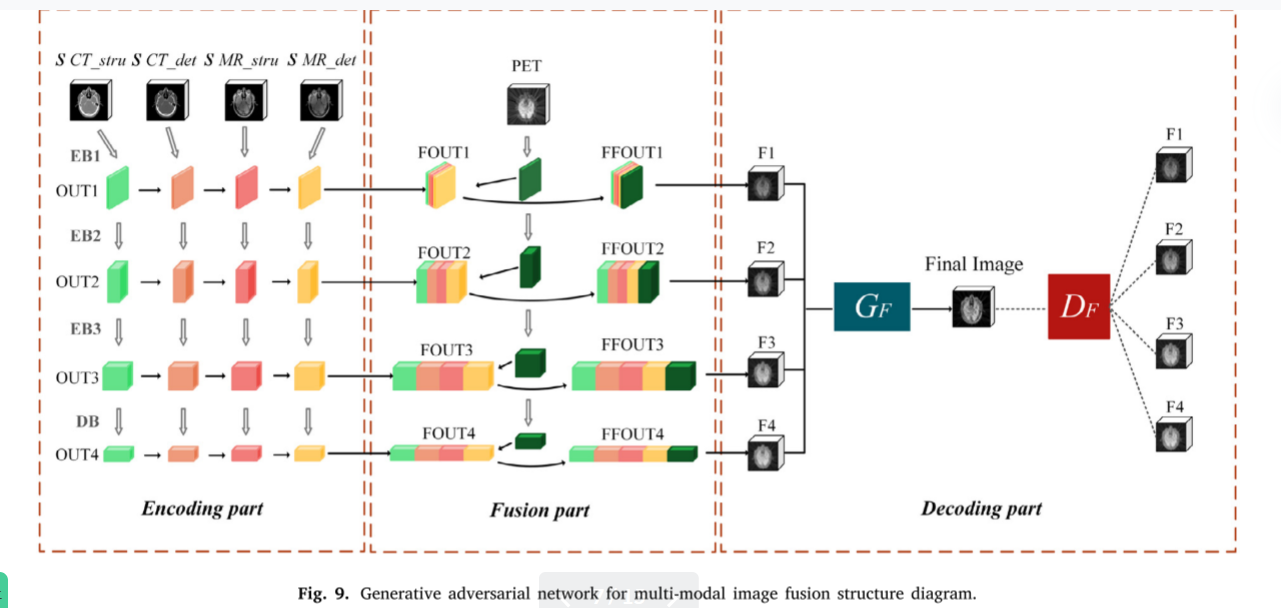
多发电机模态综合合成的 𝑠𝐶𝑇_𝑠𝑡𝑟u, 𝑠𝐶𝑇_𝑑𝑒𝑡 和双生成器图像增强得到的 𝑠𝑀𝑅_𝑠𝑡ru,,𝑠𝑀𝑅_𝑑𝑒t以及原始PET图像一起通过图像融合阶段。在网络训练过程中,我们采用图像融合发生器 (𝐺𝐹) 和图像融合鉴别器 (𝐷𝐹) 来提高 𝐺𝐹 的图像融合性能,实现三模态图像融合。
为了更全面地提取图像的深结构和浅细节特征,融合图像在结构完整的同时保留了更多的纹理细节和精细结构,为每个输入图像设置一个单独的编码器,如图9中的编码部分所示。编码器由三个编码块EB1、EB2、EB3和一个解码块DB组成,如图10所示,编码器的内部网络结构设置如表1所示。每个编码块由一个卷积层和一个用于深度特征提取的密集块组成。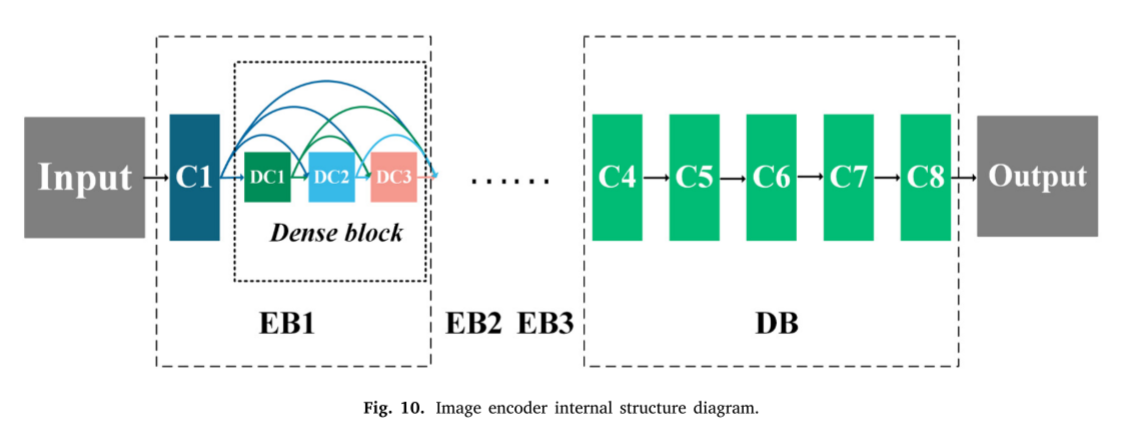
每个密集块包括三个卷积层,并且每个层的输出通过级联操作连接到每个其他层。解码块DB由五个卷积层组成。编码和解码块逐层提取输入的图像特征,并输出相应的图像特征块OUT1、OUT2、OUT3和OUT4,如图9中的编码部分所示。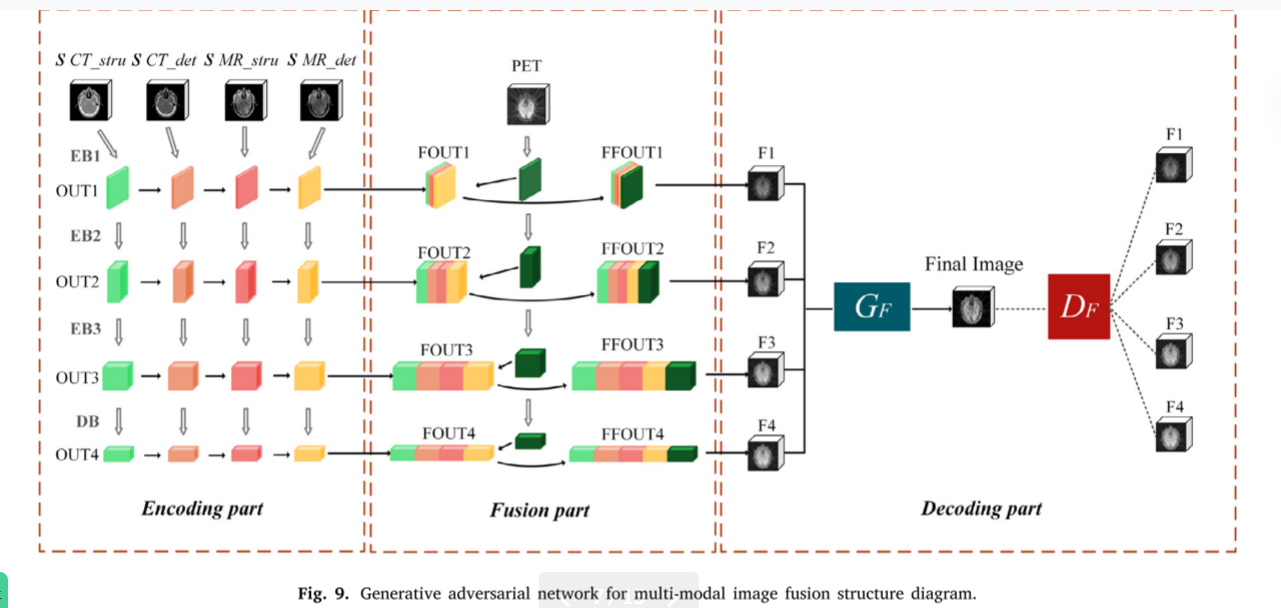
在特征融合部分 (融合部分) 中,为了更好地保留不同模型中包含的详细信息,图像特征块通过编码部分与同一层特征融合,得到融合块FOUT1、FOUT2、FOUT3、FOUT4,如图9的融合部分所示。由于PET图像分辨率低,为了更好地保留PET图像中包含的特征信息 (Wang等,2019b),编码器从原始PET图像中提取每一层的特征映射,并与融合块FOUT1,FOUT2,FOUT3,FOUT4以获得输出块FFOUT1,FFOUT2,FFOUT3,FFOUT4,如图9中的融合部分所示。
输出块FFOUT1、FFOUT2、FFOUT3、FFOUT4包含同一层不同输入图像的丰富细节特征,但由于特征提取结构不同,每个输出块的通道信息和空间维度不同。因此,在解码部分中,输出块FFOUT1、FFOUT2、FFOUT3、FFOUT4被输入到用于下采样的最大池化层,以获得生成的图像F1、F2、F3、F4。最后,将图像F1,F2,F3,F4馈送到图像融合生成器 𝐺𝐹 中,以获得最终的融合图像。
𝐺𝐹 的内部结构基于Li等人死亡研究,以及𝐷𝐹 的内部结构基于 Zhu等人的研究。目标是学习生成的 𝑃 域图像和最终融合的 𝑄 域图像之间的映射函数 𝑊 ∶ 𝑃 → 𝑄。𝐷𝐹 对生成的图像F1、F2、F3、F4和输出的图像进行逐一判别。式(10)中显示了 𝑊 ∶ 𝑃 → 𝑄 和 𝐷𝐹 的对抗性损失。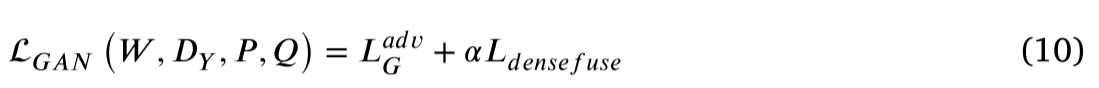
这里,总损失LGAN包括对抗性损失LadvG和𝐷𝐹 内部结构损失函数Ldensefuse。Ldensefuse包括包括pixel损耗和SSIM损耗。𝐺𝐹 的目的是最小化目标,𝐷𝐹 的目的是最大化目标,以实现minW、maxDF、LGAN(W、𝐷𝐹、 P、Q)。在图像融合测试一下阶段,将测试一下图像输入训练好的生成对抗网络进行多模态图像融合,得到具有CT、MR、PET三模态特征的最终融合图像。