SwinTransformer学习

参考:
- Swin-Transformer网络结构详解
https://blog.csdn.net/qq_37541097/article/details/121119988
x.1 前言
x.1.1 特点
它具有两个特点:
- 采用类似卷积神经网络中的层次构建方法
- 采用W-MSA和SW-MSA
- 全新的位置编码方式
- 层次构建方法
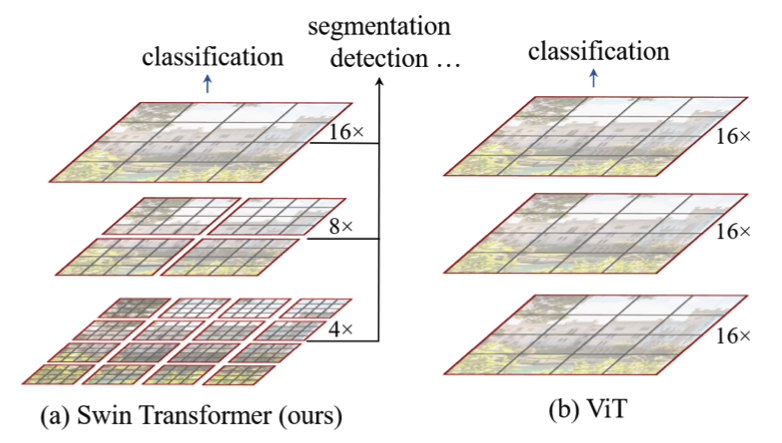
相比较于ViT,第一个Conv2d直接将图片下采样16x16倍,swin-Transformer则使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。他的特征提取方式如下:
- W-MSA和SW-MSA
采用了Windows Multi-Head Self-Attention(W-MSA)和Shifted Windows Multi-Head Self-Attention(SW-MSA)。W-MSA为了减少参数量?还是计算量?,将特征提取图划分成一个一个小模块;SW-MSA效果同Masked-MSA,为了防止不同的特征图分割后产生的耦合。
- 全新的位置编码方式
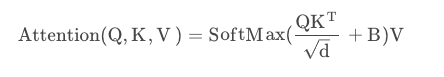
根据上面公式,我们的相对位置编码会增加在Attention计算中,通过计算以及查表我们得到最终的偏置矩阵。
增加偏置后我们的精度能提高三个点。
x.1.2 网络结构图
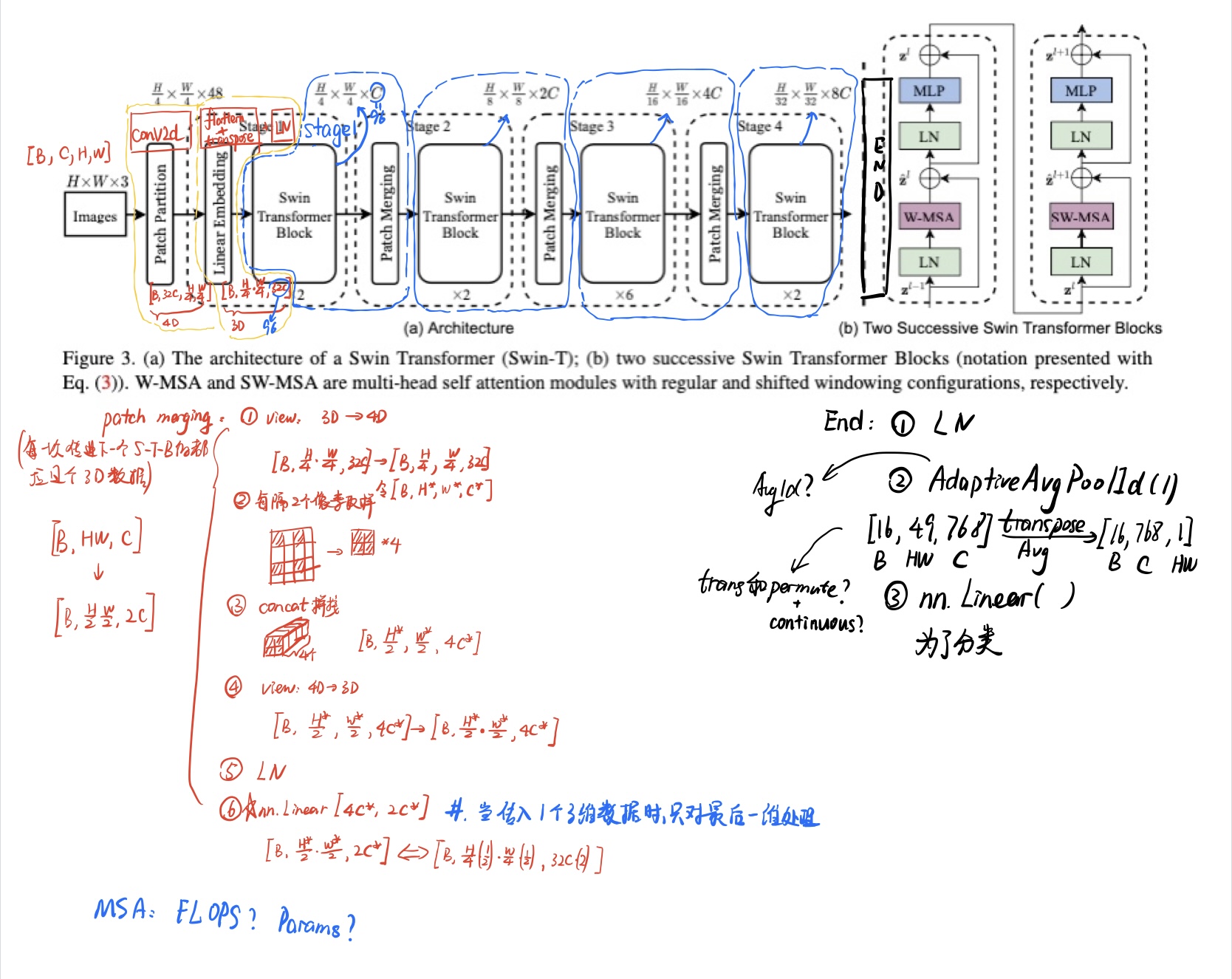
x.2 Patch-Partition + Linear Embedding
当一个Images图片塞入网络训练的时候,我们先要通过Patch-Partition即Conv2d将图片下采样4x4,通道数量增加32倍。
紧接着我们通过flattern+transpose将输入矩阵由4维变成3维[B, C, H, W]->[B, H*W, C],因为Attention模块只处理3维数据。
最后我们将矩阵传入Layer Norm。接下来便可以将矩阵传入后续的stage中进行训练。
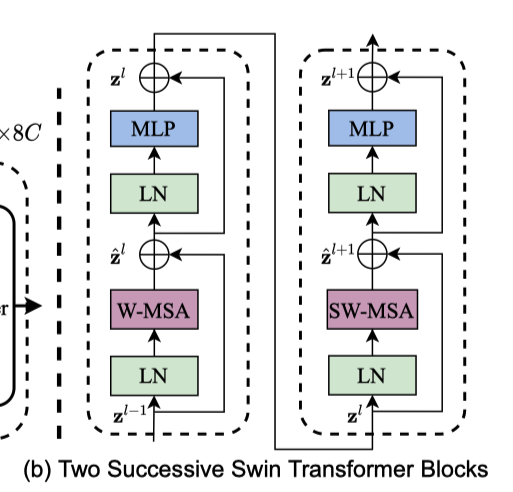
x.3 Swin Transformer Block
每一个Block由一个含W-MSA的块和一个含SW-MAS的块组成。
x.3.1 W-MSA
为了减少params,引入W-MSA。虽然传入的是个3维矩阵,但是形象地来说就是将图片进行了分割,分割成了一个一个的windows,一个window由多个patches组成,一个patch(一个patch不是指一个像素,而是指一块区域,包含多个像素)转成一个token再传入网络训练。每次对一个window进行Attention做特征提取。
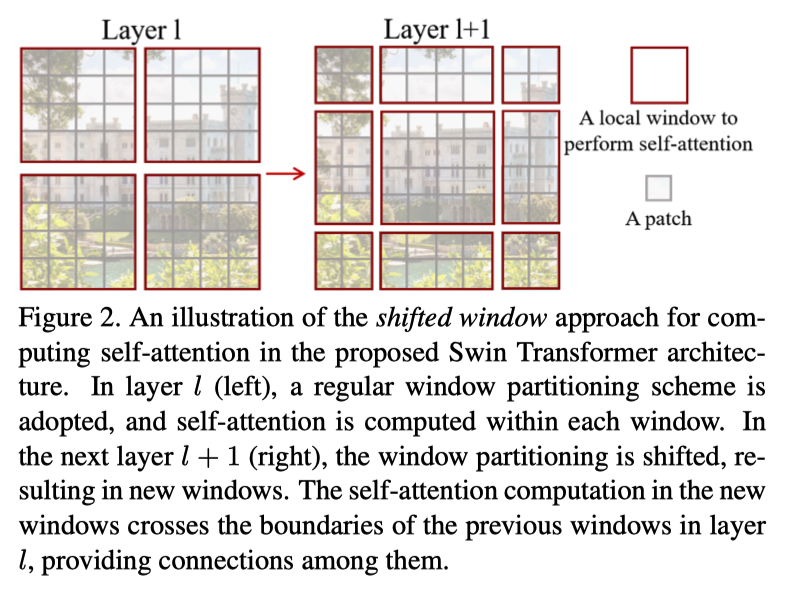
x.3.2 SW-MSA
由于分割后的4个图片间缺少相对位置关系,所以我们将图片重新分割,使得区域间具有相对位置关系。
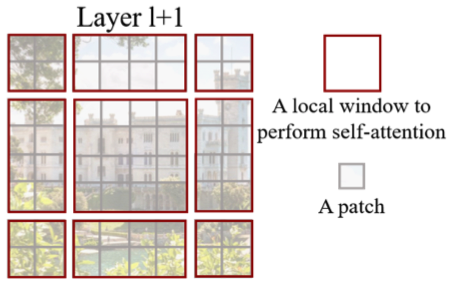
但是我们的矩阵计算都是对固定大小的window进行计算,所以我们需要shift移动切割后的window。
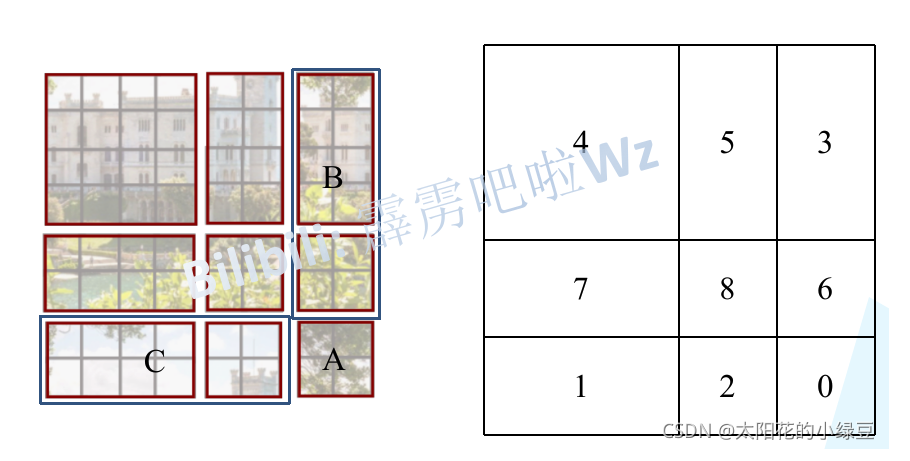
但是5和3之间并不具备位置关系,所以我们在计算5和3组成的大块的时候,我们需要单独计算5和单独计算3。这个时候我们使用了masked-MSA。几乎一模一样,赋值一个负无穷(这里是-100),经过softmax后变成0。
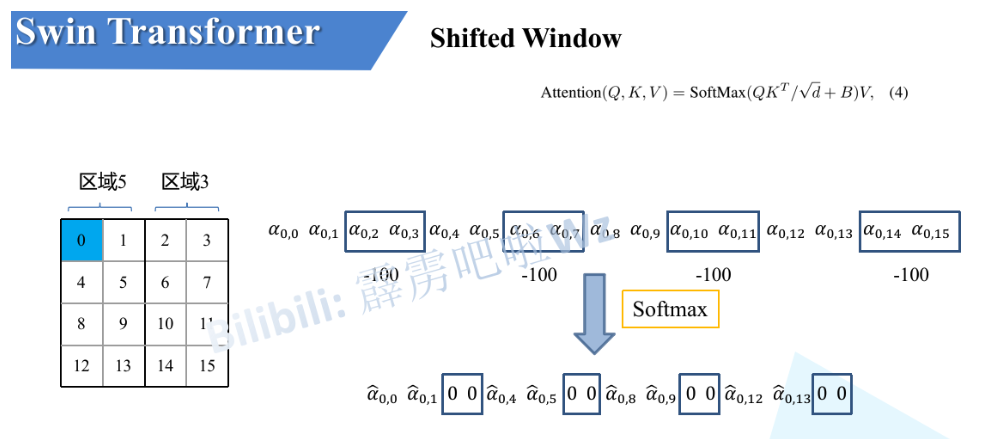
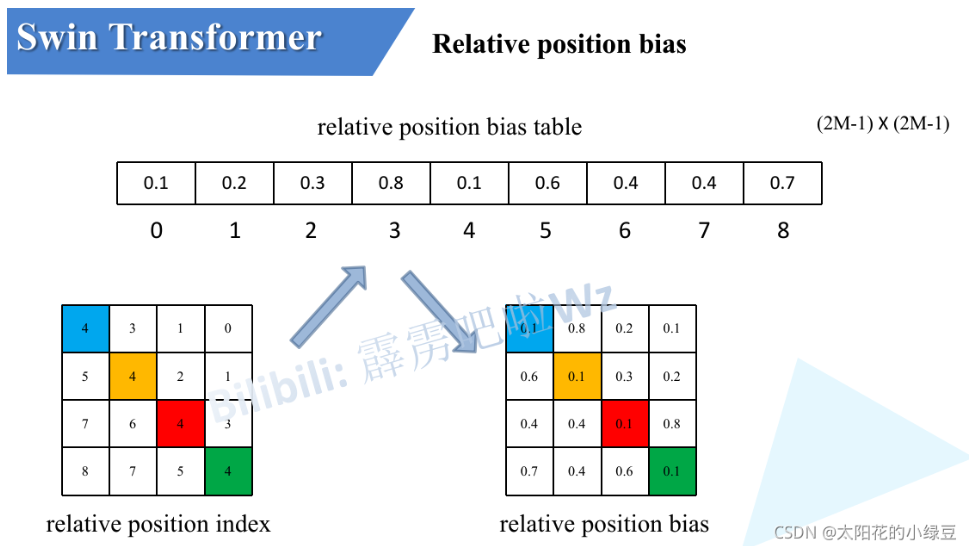
x3.3 Relative Position Bias
通过公式,我们能够看到,在计算Attention的时候,我们还增加了相对位置偏置的矩阵。
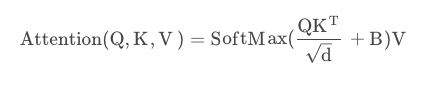
相对位置偏置矩阵是通过计算和查表得到的。我们计算相对位置,将相对位置展平拼成一个大矩阵;经过行列计算得到绝对位置;由绝对位置查表得到相对位置偏置矩阵。
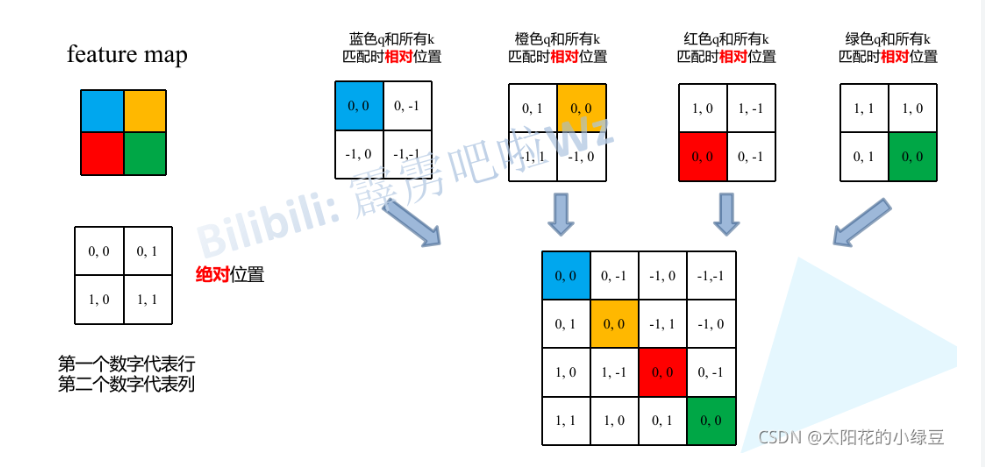
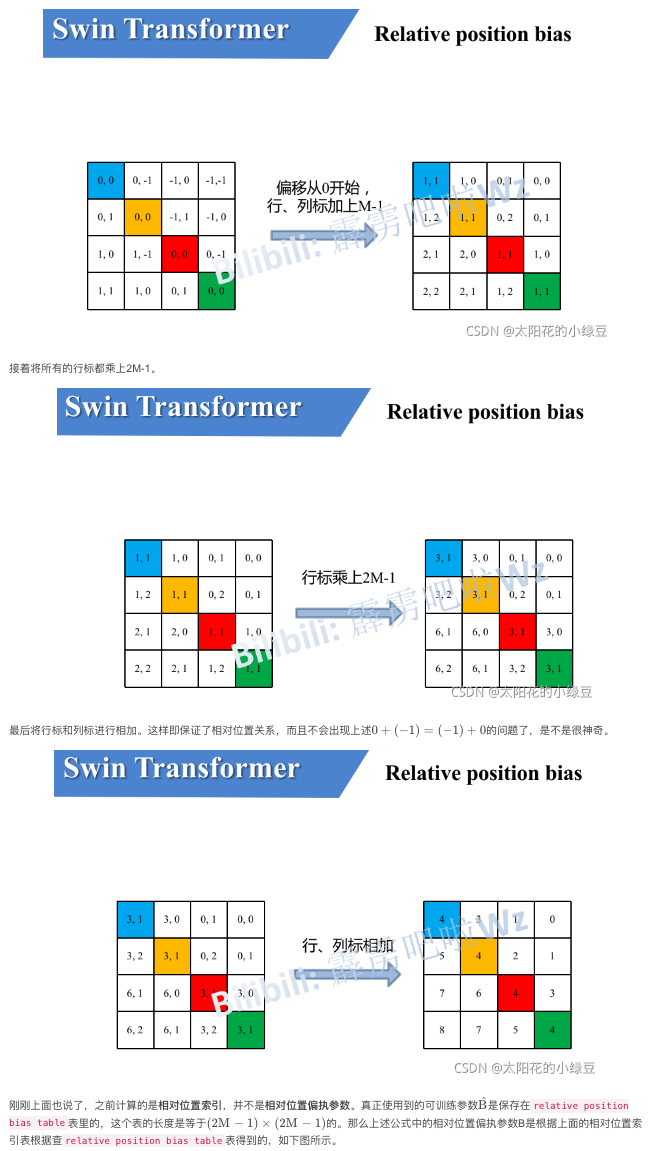
x.4 patch merging
patch merging即下采样。在Height和width方向上减半,Channel翻倍。

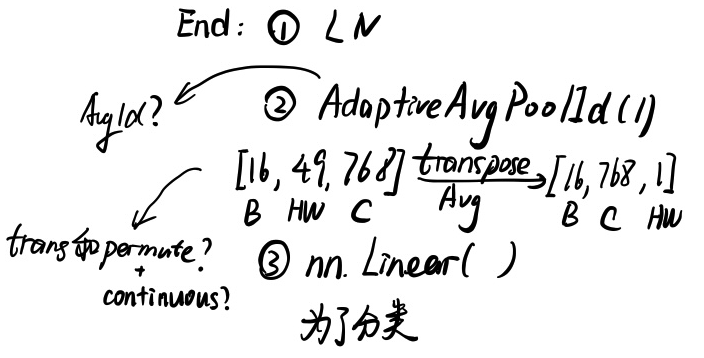
x.5 End层
最后增加一个End层为了和最后的分类类别数相匹配。