NVIDIA-cuSPARSE稀疏矩阵加速求解官方教程精简(一)
听说有个叫cuSPARSE的库,专治稀疏矩阵的加速问题,听起来牛逼!稀疏矩阵?就是那种大部分都是零的矩阵,对吧?好家伙,用普通的矩阵运算那不是浪费内存和计算资源吗?这库就是为了解决这个问题。
这篇文章介绍了cuSPARSE的分类,分四类:向量转 dense、矩阵转 dense、矩阵向量转dense,还有各种格式转换和压缩。感觉这个库就是个瑞士军刀,稀疏矩阵的各种操作都能搞定。对了,还能用GPU加速,想想都刺激!
命名习惯是重点,S是单精度,D是双精度,还有C、Z这种复杂类型。函数名里还带操作类型,比如axpyi、mv这些,感觉像是一套完整的语言。函数都返回cusparseStatus_t,处理错误的时候得小心点噢。
异步执行这个功能太赞了,函数执行完直接返回,不用等结果,效率肯定高!但要确保数据传输出去的时候用对 cudaMemcpyDeviceToHost 这些函数,否则数据可能会出错。
静态库支持也是一个亮点,编译的时候记得加上 -lcusparse_static,而且Linux下还要加pthread和dl库。这样一来,即使没有GPU也能优雅运行,真是考虑周全!
索引和数据格式这块儿得好好理解。COO、CSR、CSC这些格式各有特点,COO记录非零元素的位置,CSR按行压缩,CSC按列压缩,选对了格式能事半功倍。
总之,cuSPARSE是个强大的工具,用好了能大幅度提升稀疏矩阵的运算效率。不过得花时间熟悉它的API和数据格式,才能真正发挥它的威力。对了,官网教程里肯定还有更多干货,得好好研究研究!


cuSPARSE,一个CUDA的稀疏矩阵求解库
官网教程链接
介绍
该库包含了一系列的用于处理稀疏矩阵的线性代数的子例程,适用于0元素占比高达95%的矩阵求解,适用于C与C++调用
库的方案可以被分为4类:(类别1234)
- 稀疏的向量与密集向量转化的方法(1)
- 稀疏的矩阵与密集矩阵转化的方法(2)
- 稀疏的矩阵与密集的向量之间的转化(3)
- 允许不同格式之间的转化,以及CSR矩阵的压缩(4)
cuSPARSE 库允许开发人员使用GPU进行加速,允许输入与输出数据驻留在GPU内存中,其中包含了许多分配的方法例如
- cudaMalloc()
- cudaFree()
- cudaMemcpy(),
- cudaMemcpyAsync()
1.1命名习惯
-
类别123均符合下面的命名习惯

-
< t >可以是 S, D, C, Z, X,分别 对应float, double, cuComplex, cuDoubleComplex, 以及generic type
-
< matrix data format > 可以是dense, coo, csr, or csc, 分别对应dense, coordinate, compressed sparse row, 以及compressed sparse column 格式
-
< operation>可以是axpyi, gthr, gthrz, roti或sctr,对应于1级函数;也可以是mv或sv,对应于第2级函数,也可以是mm或sm,对应于第3级函数。
所有函数的返回类型都是cusparseStatus_t
1.2异步执行
-
cuSPARSE库函数是相对于主机异步执行的并且在结果准备好之前将控制权返回鬼主机上的应用程序。开发人员可以使用cudaDeviceSynchronize()函数来确保特定的csSPARSE例程已经完成。
-
cudaMemcpy()使用cudaMemcpyDeviceToHost与cudaMemcpyHostToDevice参数将数据在GPU与主机之间进行传输
1.3静态库支持
从6.5版开始,cuSPARSE库也以静态形式作为libcusparse_static交付
例如,要对动态库使用cuSPARSE编译一个小型应用程序,可以使用以下命令:
nvcc myCusparseApp.c -lcusparse -o myCusparseApp>
然而要对静态cuSPARSE库进行编译,必须使用以下命令:
nvcc myCusparseApp.c -lcusparse_static -o myCusparseApp>
也可以使用本机主机c++编译器。根据主机操作系统的不同,链接行上可能需要一些额外的库,如pthread或dl。Linux下建议使用如下命令:
g++ myCusparseApp.c -lcusparse_static -lcudart_static -lpthread -ldl -I <cuda-toolkit-path>/include -L <cuda-toolkit-path>/lib64 -o myCusparseApp
注意,在后一种情况下,cuda是不需要的。如果需要,CUDA运行时将尝试显式地打开CUDA库。在系统没有安装CUDA驱动程序的情况下,这允许应用程序优雅地处理这个问题,并可能在只有cpu的路径可用的情况下运行。
1.4库依赖
2(没有具体用处,也是一些介绍,具体移步官网)
3cuSPARSE索引和数据格式
cuSPARSE支持稀疏与密集的向量与矩阵形式
3.1索引基本格式
该库支持基于零和基于一的索引。索引基是通过cusparseIndexBase_t类型选择的,该类型作为一个独立参数或作为矩阵描述符cusparseMatDescr_t类型中的字段传递。
3.1.1向量格式
本节介绍稠密向量格式
3.1.1.1稠密形式
[1 0 0 2 3 0 4 ]这种含有少量0元素的向量
3.1.1.2稀疏形式
上面向量可以表示为[1 2 3 4],[0 3 4 6],第一个表示非零数值,第二个表示索引
3.2矩阵形式
本节讨论稠密矩阵与一些稀疏矩阵
3.2.1稠密形式
矩阵X表示:
- m 行
- n 列
- ldx 矩阵X的前导维数,必须大于等于m,如果大于m,那X就表示存储在内存中的较大矩阵的子矩阵
- X表示矩阵元素的数据数组,假设为X分配了足够的存储空间来保存所有矩阵元素,并且cuSPARSE库函数可以访问子矩阵之外的值,但永远不会覆盖它们。
例如,一个有着ldx前导维度的m*n数组可以被如下的索引进行访问
3.2.2Coordinate Format(COO)
矩阵A
- nnz 矩阵中非零元素的个数
- cooValA 指向长度为nnz的数据数组,该数组以行格式保存所有非零值
- cooRowIndA 行索引(通常0为开始索引)
- cooColIndA 列索引(通常0为开始索引)
例如

- cooValA为从左到右,从上到下的方式排列非零值
Compressed Sparse Row Format(CSR)
矩阵A参数
- nnz 非零元素的个数
- csrValA 行格式保存所有非零值
- csrRowPtrA 指向长度为m+1的整数数组,该数组包括了
- csrColIndA 长度为nnz的数组,包含了对应元素的列索引
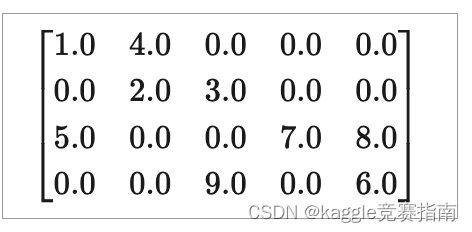

- csrValA 从左到右,从上到下的非零元素
- csrRowPtrA 长度为4+1 第i个元素记录了前i+1行非零元素的值,其中第一个0是说明0开始索引

3.2.4Compressed Sparse Column Format(CSC)
A
- nnz 非零元素的个数
- cscValA 非零元素的数组
- cscRowIndA 数组cscValA中相应元素的行下标。
- cscColPtrA 长度n+1,第i个元素记录了前i+1列非零元素的水量,其中第一个0是说明0开始索引
