DSL查询文档

目录
- 1、查询DSL基本语法
- 2、基本查询类型
- 3、复合查询FunctionScoreQuery
-
- 案例:给名字为如家的品牌排名靠前一些
- 4、Boolean Query查询
-
- 案例:如家酒店,价格<=400,且在坐标10km范围内所有酒店
- 5、指定排序字段
-
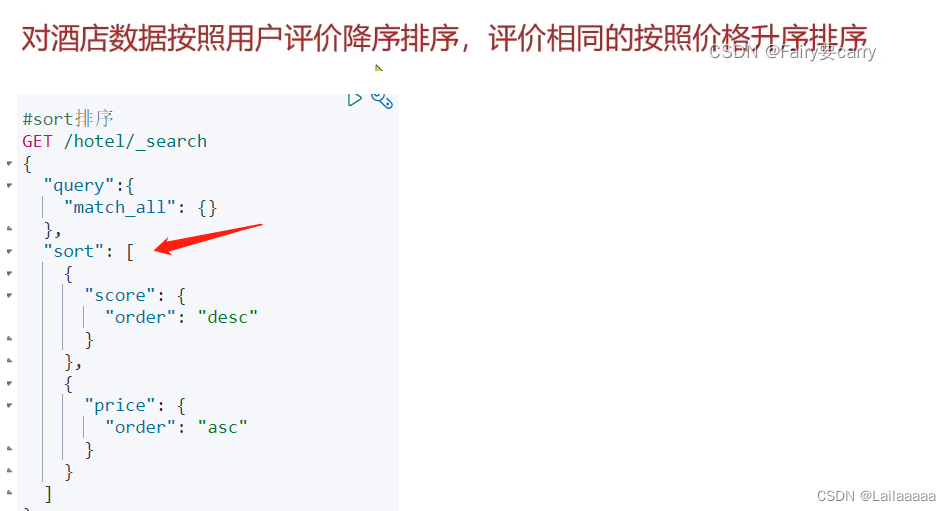
- 案例:根据用户评价排序,评价相同则按照价格升序排序
- 案例:根据经纬度排序附近的酒店
- 6、分页
- 7、高亮
1、查询DSL基本语法
GET /索引库名/_search
{“query”:{
“查询类型”:{“FIELD”:“TEXT”}}
}
took:花费时间
time_out:花费时间
hits:击中的数据——>value:指的是多少个
下面那个hits是具体的数据

2、基本查询类型
全文检索查询
1.match类型:可以根据一个字段进行查询(字段为索引库创建时的约束字段)
#match查询
GET /hotel/_search
{"query":{"match": {"name": "外滩"}}
}GET /hotel/_search
{"query":{"match": {"business": "如家"} }
}2.muti_match类型:可以根据多个字段进行查询,字段越多,效率越低
#muti_match 查询
GET /hotel/_search
{"query": {"multi_match": {"query": "外滩如家","fields": ["brand","name","business"]}}
}GET /hotel/_search
{"query":{"multi_match":{"query":"如梦","fields":["business","name"]}}
}

地理查询


3、复合查询FunctionScoreQuery
算分的算法介绍
FunctionScoreQuery:在原有查询基础上+打分

function score打分场景:比如在百度上,你进行搜索,向我们看到最前面的,都是广告投放的,也就是人工对文档进行了算分方面的控制;
打分与词条频率有关

实践: 1、query:原始的查询条件,会根据条件来得到我们想要的文档
2、过滤条件:filter->定义了哪些文档会被重新算分
3、算分函数:function score
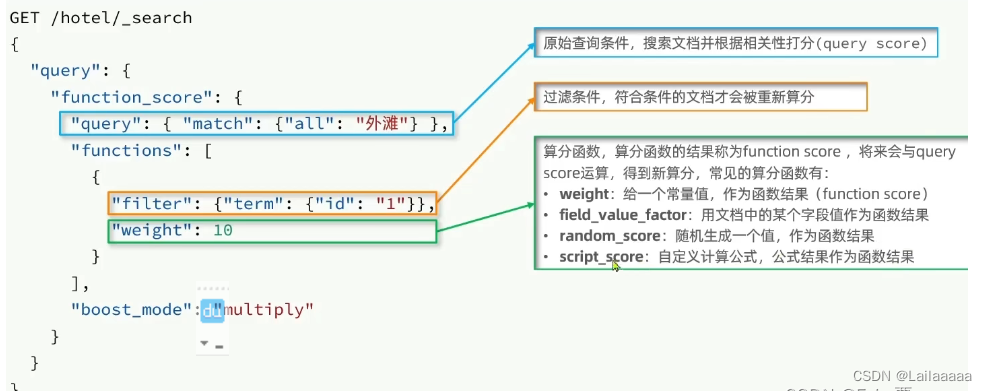
4、那么fuction score(算分函数)和query score(原始打分)是怎么进行运算的呢?
通过boost_mode进行加权
比如说上面那个场景,假设我们查询出来的文档,它里面的词条根据默认的打分算法求得是0.5,那么根据算分函数,加权完后=10*0.5=5;

案例:给名字为如家的品牌排名靠前一些

流程:
1.首先,在query下定义一个function_score,我们根据算分搜索数据,query查询能够match到的文档(比如我们这里的name:“外滩”),里面包含符合的词条(并且用BM25算法默认打分)
2.然后,定义一个functions,里面是算分的方法:符合的才会被重新算分(filter),并且设置算分函数,比如weight…,
3.最后设置加权模式,重新算分的函数与之前query的打分进行一个加权
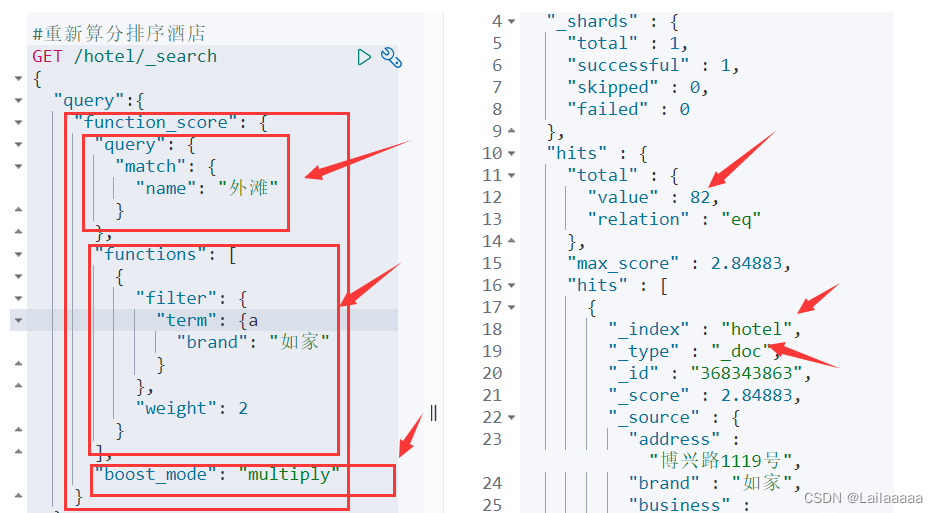
function score query分别定义三要素是什么?

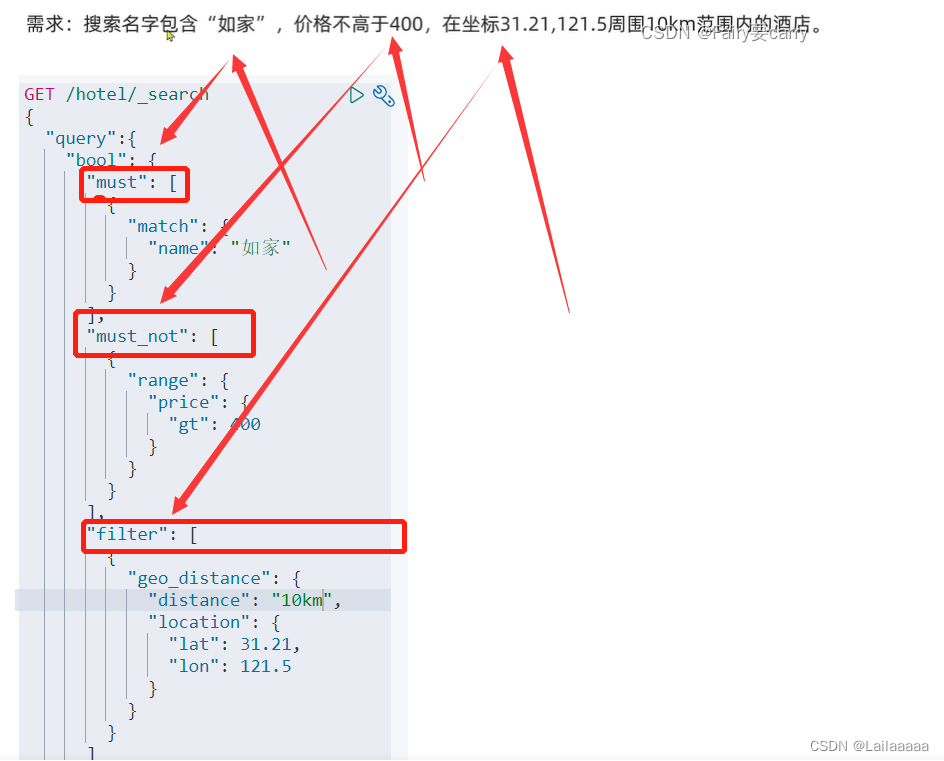
4、Boolean Query查询

比如关键字的搜索,像酒店名字等等,可以放到must里面
must:必须匹配的条件,里面的条件会参与算分
should:选择性匹配,可以理解为“或”
must_not:像不是必须的,品牌这种keyword,不参与算分的就可以放到下面,直接根据条件筛
filter:与must一样,不过不参与打分
一般来说,我们都是将关键字,那些参与打分的字段放入must中,其余的在must_not或者Filter
案例:如家酒店,价格<=400,且在坐标10km范围内所有酒店
5、指定排序字段
elasticsearch默认是对搜索结果进行排序,按照相关的算分(_score)来排序——>也就是说默认是按照type=text的打分排序;
我们可以根据->不能打分(没有分词)的字段:像keyword类型、地理坐标、日期等类型进行结果排序;
注意:一旦发生了sort排序,打分失效
案例:根据用户评价排序,评价相同则按照价格升序排序
案例:根据经纬度排序附近的酒店
根据位置排序周围的酒店:
1.首先规定sort排序,因为是关于地理位置的排序,所以要设置_geo_distance
2.在_geo_distance里面确定基点位置location(经纬度)
3.排序方式order以及单位unit

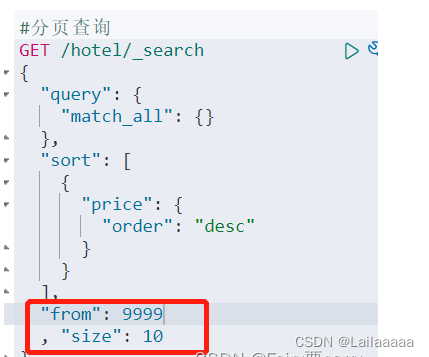
6、分页
与query同级, 以下就是:按照价格降序,从第一条数据开始,看10条数据,如果我们要查第二页,直接from改为10即可;

深度分页问题
就比如场景:一个年级参加比赛,有尖子班和普通班(对应也就是ES集群两个分片),筛选最优秀的十个人参加比赛,你不可能是普通版参加十个,尖子班参加十个,因为你普通班的前十到尖子班可能就是倒数了,所以需要将结果聚合,重新筛选,选出最优秀的十个

from+size>10000会报错
深度分页解决方案:

scroll因为是快照,说明不能实时更新,那么海量数据获取更新就不行了,而且快照的话还要额外内存消耗,所以不是蛮推荐;
after search:没有查询上限(from+size有上限10000),只能向后翻页,不支持随机翻页,比如小说翻页;
from+size:百度京东、谷歌这种都是这样,<10000
7、高亮
注意:高亮的话,肯定是对关键字高亮,那么查询文档不能用query:match_all,我们可以用matchQuery();
1.首先,先得到高亮文档,source就相当于整个大的json数据,然后从外往里即可
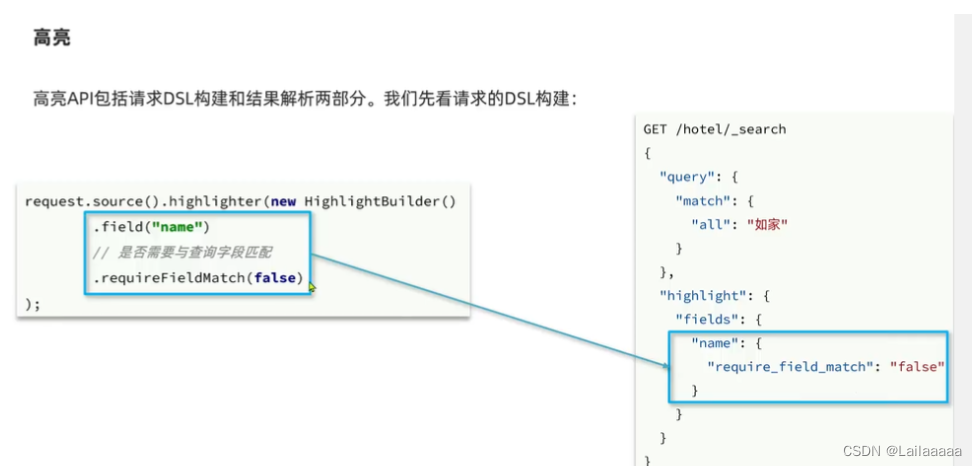
/* 高亮测试*/@Testvoid testHighlight() throws IOException {SearchRequest request = new SearchRequest("hotel");//准备queryrequest.source().query(QueryBuilders.matchQuery("name","如家"));//准备字段高亮request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));//发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//解析响应extracted(response);}
2.我们获取到高亮文档之后,因为高亮字段是不再_source里面的,所以我们需要对响应结果的解析进行修改

/* 辅助方法,解析响应结果 @param response:响应结果*/private void extracted(SearchResponse response) {/* 第二部分:响应结果的解析*/SearchHits searchHits = response.getHits();//4.1得到总条数long total = searchHits.getTotalHits().value;System.out.println("共获取到" + total + "条数据");//4.2文档数组SearchHit[] hits = searchHits.getHits();//4.3遍历for (SearchHit hit : hits) {//获取文档sourceString json = hit.getSourceAsString();//将文档source利用fackjson进行反序列化得到HotelDoc对象HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);/* 在打印结果之前我们从文档取出字段的高亮结果*//*取出高亮结果*/Map<String, HighlightField> highlightFields = hit.getHighlightFields();if(!CollectionUtils.isEmpty(highlightFields)){/*根据高亮字段名获取高亮结果*/HighlightField highlightField = highlightFields.get("name");if(highlightField!=null){/*取出高亮值并且覆盖非高亮文档*/String name = highlightField.getFragments()[0].string();hotelDoc.setName(name);}}System.out.println(hotelDoc);}}
