Clickhouse 引擎之MergeTree详解

分区详解
数据存储底层分布
# 数据在这个位置
root@fjj001:~# cd /var/lib/clickhouse/data
root@fjj001:/var/lib/clickhouse/data# ls
# 数据库
default system
root@fjj001:/var/lib/clickhouse/data# cd default/
root@fjj001:/var/lib/clickhouse/data/default# ls
#表
enum test_array testroot@fjj001:/var/lib/clickhouse/data/default# cd test
root@fjj001:/var/lib/clickhouse/data/default/test# ls
# 分区目录 443ada38955287b00e4adb6717a67dc5_3_3_0
# detached 通过DETACH语句卸载后的表分区存放位置
# format_version.txt 纯文本,记录存储的格式
443ada38955287b00e4adb6717a67dc5_3_3_0 549e808cec4345228ef62a54e16b445c_1_1_0 detached fb922197bb861a044ab5b3f46a94d710_2_2_0 format_version.txtroot@fjj001:/var/lib/clickhouse/data/default/test# cd 443ada38955287b00e4adb6717a67dc5_3_3_0/
root@fjj001:/var/lib/clickhouse/data/default/test/443ada38955287b00e4adb6717a67dc5_3_3_0# lschecksums.txt columns.txt count.txt data.bin data.mrk3 default_compression_codec.txt minmax_birthday.idx partition.dat primary.idx
# columns.txt 纯文本文件,记录了表的结构信息
# count.txt 纯文本文件 记录表的数据行数
# checksums.txt 校验和
# default_compression_codec.txt 默认压缩算法
# data.bin 二进制文件
# data.mrk3 标记文件
# skp_idx_[column].idx:跳数索引,在使用了二级索引时会生成,否则这不生成。
数据分区目录命名规则
比如20231115_2_2_0,其中 20231115是分区ID ,2_2对应的是最小的数据块编号和最大的数据块编号,最后的 _0 表示目前分区合并的层级。这么命名是为了数据目录合并算法。
分区ID:该值由 insert 数据时分区键的值来决定。分区键支持使用任何一个或者多个字段组合表达式,针对取值数据类型的不同,分区ID的生成逻辑目前有四种规则:
不指定分区键:如果建表时未指定分区键,则分区ID默认使用all,所有数据都被写入all分区中。
整型字段:如果分区键取值是整型字段,并且无法转换为YYYYMMDD的格式,则会按照该整型字段的字符形式输出,作为分区ID取值。
日期类型:如果分区键属于日期格式,或可以转换为YYYYMMDD格式的整型,则按照YYYYMMDD格式化后的字符形式输出,作为分区ID取值。
其他类型:如果使用其他类似Float、String等类型作为分区键,会通过对其插入数据的128位Hash值作为分区ID的取值。
MinBlockNum 和 MaxBlockNum: BlockNum 是一个整型的自增长型编号,该编号在单张MergeTree表中从1开始全局累加,当有新的分区目录创建后,该值就加1,对新的分区目录来讲,MinBlockNum 和 MaxBlockNum 取值相同。
Level: 表示合并的层级。相当于某个分区被合并的次数,它不是以表全局累加,而是以分区为单位,初始创建的分区,初始值为0,相同分区ID发生合并动作时,在相应分区内累计加1。
分区目录的合并过程
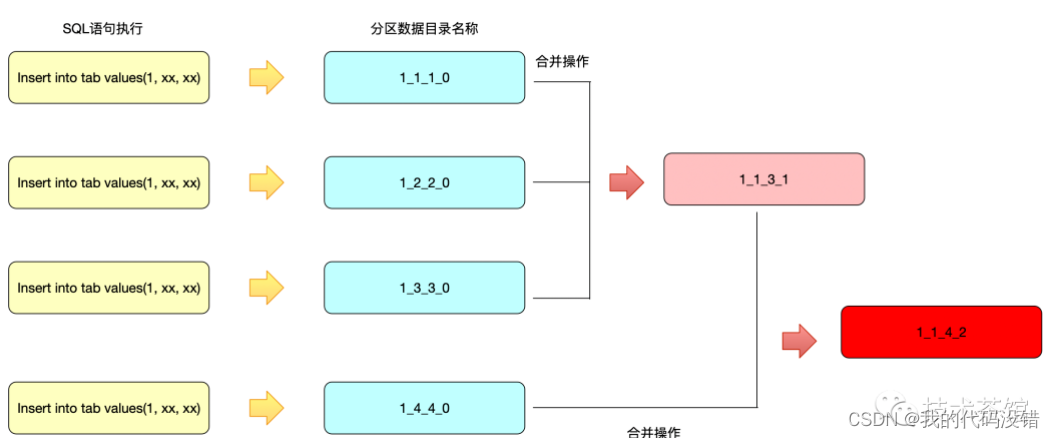
ergeTree的分区目录和传统意义上其他数据库有所不同。MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。也就是说如果一张数据表没有任何数据,那么也不会有任何分区目录存在。 MergeTree的分区目录伴随着每一批数据的写入(一次INSERT语句),MergeTree都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。在之后的某个时刻(写入后的10~15分钟,也可以手动执行optimize查询语句),ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认8分钟)。
但是有些特殊场景下,用户希望立刻删除老的数据目录,这种需求可以在创建MergeTree表的时候通过Settings属性来设置。如下所示
CREATE TABLE partition_directory_merge
(partition_key Int32,orderBy_key String,data String
)
ENGINE = MergeTree()
PARTITION BY partition_key
ORDER BY orderBy_key
SETTINGS old_parts_lifetime = 1
# old_parts_lifetime 这个属性的含义是多久删除老的分区数据目录。单位是秒
主键索引
概述
MergeTree的主键使用PRIMARY KEY定义,待主键定义之后,MergeTree会依据index_granularity间隔(默认8192行),为数据表生成主键索引并保存至primary.idx文件内,索引数据按照PRIMARY KEY排序。相比使用PRIMARY KEY定义,更为常见的简化形式是通过ORDER BY指代主键。在此种情形下,PRIMARY KEY与ORDER BY定义相同,所以索引(primary.idx)和数据(.bin)会按照完全相同的规则排序。
ClickHouse的主键索引和别的数据库是不一样的,他不是唯一的,可以使用相同的主键插入多行。
ClickHouse的主键索引使用了稀疏索引实现,即每一行索引表记录对应的是一段数据,而不是一行数据。它使用少量的索引标记就可以记录大量数据的区间位置信息。
稀疏索引的含义
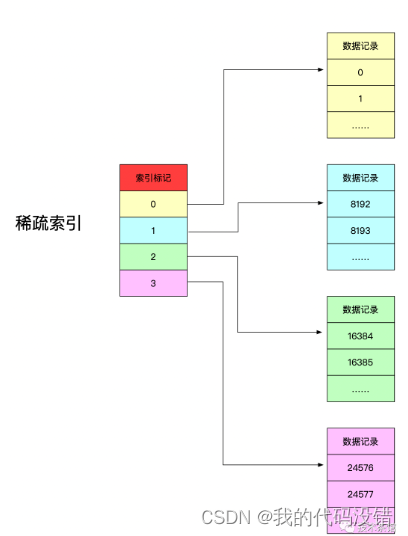
稀疏索引中,每一行索引标记对应的是一段数据,而不是一行。用一个形象的例子来说明:如果把MergeTree比作一本书,那么稀疏索引就好比是这本书的一级章节目录。一级章节目录不会具体对应到每个字的位置,只会记录每个章节的起始页码。
稀疏索引的优势
稀疏索引的优势是显而易见的,它仅需使用少量的索引标记就能够记录大量数据的区间位置信息,且数据量越大优势越为明显。以默认的索引粒度(8192)为例,MergeTree只需要12208行索引标记就能为1亿行数据记录提供索引。由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度自然极快
索引粒度
ClickHouse通过index_granularity参数来控制索引粒度,默认为8192,最新版本可以使用自适应索引粒度大小,则标记文件会被命名为(column.mrk2)。数据会以该参数的大小被标记为多个小区间,每个区间默认最多8192行数据,MergeTree使用MarkRange来表示一个具体区间,并通过start和end表示具体范围。

ClickHouse中,索引粒度不仅影响主键索引(primary.idx),同时也影响数据标记文件(column.mrk)和数据文件(column.bin)。这是由于MergeTree无法只通过索引来完成查询工作,通过标记文件建立以稀疏索引(primary.idx)和对应数据文件(column.bin)的映射关系,MergeTree会先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(column.mrk),再通过偏移量直接从数据文件(column.bin)读取数据。所以主键索引和数据标记的间隔粒度相同,均有index_granularity参数决定,数据文件也会依据该参数生成压缩数据块。
二级索引
1.除以及索引之外,MergeTree 还支持二级索引
2.二级索引又称为跳数索引,由数据的聚合信息构成
3.根据索引类型不用,内容不同
4.设计二级索引的目的与一级索引一样 为了在查询时减少数据的范围
5.二级索引需要在create 语句内定义 支持元祖喝表达式的声明形式
6.如果声明了二级索引,那么在会额外生成对应的索引文件(skp_idx[column].idx)跟标记文件(skp_idx_[colimn].mrk)
创建跳数索引
INDEX index_name expr TYPE type(...) GRANULARITY granularity_value
跳数索引
针对不同的场景,ClickHouse提供了不同类型的跳数索引。每种跳数索引都有一个 GRANULARITY 参数,表示每隔 GRANULARITY 个索引粒度 (index_granularity ) 才会生成一次跳数索引。
※ 注意区分 GRANULARITY 和 index_granularity 的不同。
(1)minmax
minmax顾名思义就是和分区目录下的 minmax_{column_name}.idx 文件类似,只不过不再是只有一个min/max值,例如上面的minmax跳数索引 a,表示每隔 3 * index_granularity 的区间就会记录一次 u64 * i32 和 s 的最大最小值。当我们通过s查询数据时,可以先基于minmax值判断,从而跳过大多数不需要扫描的索引粒度。
(2)set(max_rows)
保存指定表达式的去重值,尤其是对于那些重复性很高的列,例如性别、年龄段等,max_rows 参数表示在一个索引粒度内,最多记录不超过 max_rows 行,即不多于 max_rows 个去重值,max_rows=0 表示不限制。
(3)ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
存储一个包含数据块中所有 n元短语(ngram) 的布隆过滤器(Bloom filter)。对String, FixedString 和 Map类型数据有效,可用于优化 EQUALS, LIKE 和 IN表达式。
什么是布隆过滤器呢?
本质上布隆过滤器是一种数据结构,一种比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你:某个数据一定不存在或者可能存在(注意:布隆过滤器是不能判断某条数据一定存在的,存在误报率 (false_positive) )。相比于传统的 List、Set、Map 等数据结构,布隆过滤器更高效、占用空间更少,因为不需要存储原始值,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器会定义一个初始值全为0,长度为m的 bit 向量或者说 bit 数组:
然后再定义k个hash函数,使得原始数据可以映射到bit向量中(是不是和redis的bitmap很像,还记得那个怎么记录上亿用户在线状态的问题吗?)。例如,定义3个hash函数,
对于“python”得到3个hash值:1、5、6,就将bit向量中的1、5、6 bit位置1。
对于“java”得到3个hash值:2、3、9,就将bit向量中的2、3、9 bit位置1。
对于“rust”得到3个hash值:7、8、9,就将bit向量中的7、8、9 bit位置1。
可以发现,对于不同的数据,因为bit向量的长度是有限的,所以可能会出现重复的bit位被置1的情况,即不同数据之间有交集。当我们查数据的时候,例如:“go”,得到的三个hash值为:4、6、7,因为4号bit位是0,所以“go”一定不存在。如果查询数据“shell”得到的hash值是:2、5、9,虽然这个三个bit位都有数据,但是我们也不能确定“shell”一定存在。
布隆过滤器的好处是可以用较少的空间存储多条复杂数据的存在信息,但是不容易确定bit向量的长度m的值,因为m越小,bit向量就越容易被占满,越容易误报(false_positive越大),起不到过滤作用。hash函数的个数k也不容易确定,因为k越大,bit向量也越容易被占满,k越小,越容易误报,因为更容易撞车。而且,可以发现布隆过滤器是不支持删除的,因为被置1的bit位可能存储了多条数据信息,对于经常变动的数据是不合适的。
再来介绍一下ngrambf_v1的参数:
n:ngram短语长度。
size_of_bloom_filter_in_bytes:布隆过滤器的大小 m,以字节为单位(可以使用较大的值,例如256或512,因为它可以很好地被压缩,并且有更强的表达能力)。
number_of_hash_functions:布隆过滤器中使用的哈希函数的个数 k 。
random_seed:布隆过滤器哈希函数的种子。
(4)tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
跟 ngrambf_v1 类似,但是存储的是token而不是ngrams。Token是由非字母数字的符号分割的序列。不再需要ngram size参数,自动通过原始数据中的非字母数字字符切分原始数据。
(5)bloom_filter([false_positive])
为指定的列存储布隆过滤器,可用于优化 equals, notEquals, in, notIn, has, hasAny, hasAll 函数,false_positive 表示从过滤器接收到假阳性响应的概率(误报率),取值范围是 (0,1),默认值:0.025。支持数据类型:Int*, UInt*, Float*, Enum, Date, DateTime, String, FixedString, Array, LowCardinality, Nullable, UUID, Map.
对于Map类型数据,可以使用mapKeys或mapValues函数指定是否为键或值创建索引。如:
INDEX map_key_index mapKeys(map_column) TYPE bloom_filter GRANULARITY 1
INDEX map_key_index mapValues(map_column) TYPE bloom_filter GRANULARITY 1
假设已知布隆过滤器误报率 p,插入元素个数为n,则hash函数个数 k 和布隆过滤器bit向量长度 m 为:
跳数索引函数支持
在使用where条件查询的时候,如果where条件表达式中包含跳数索引列,ClickHouse会在执行函数时尝试使用索引。不同的函数对索引的支持是不同的,其中 set 索引对所有函数都生效,其他跳数索引支持如下:
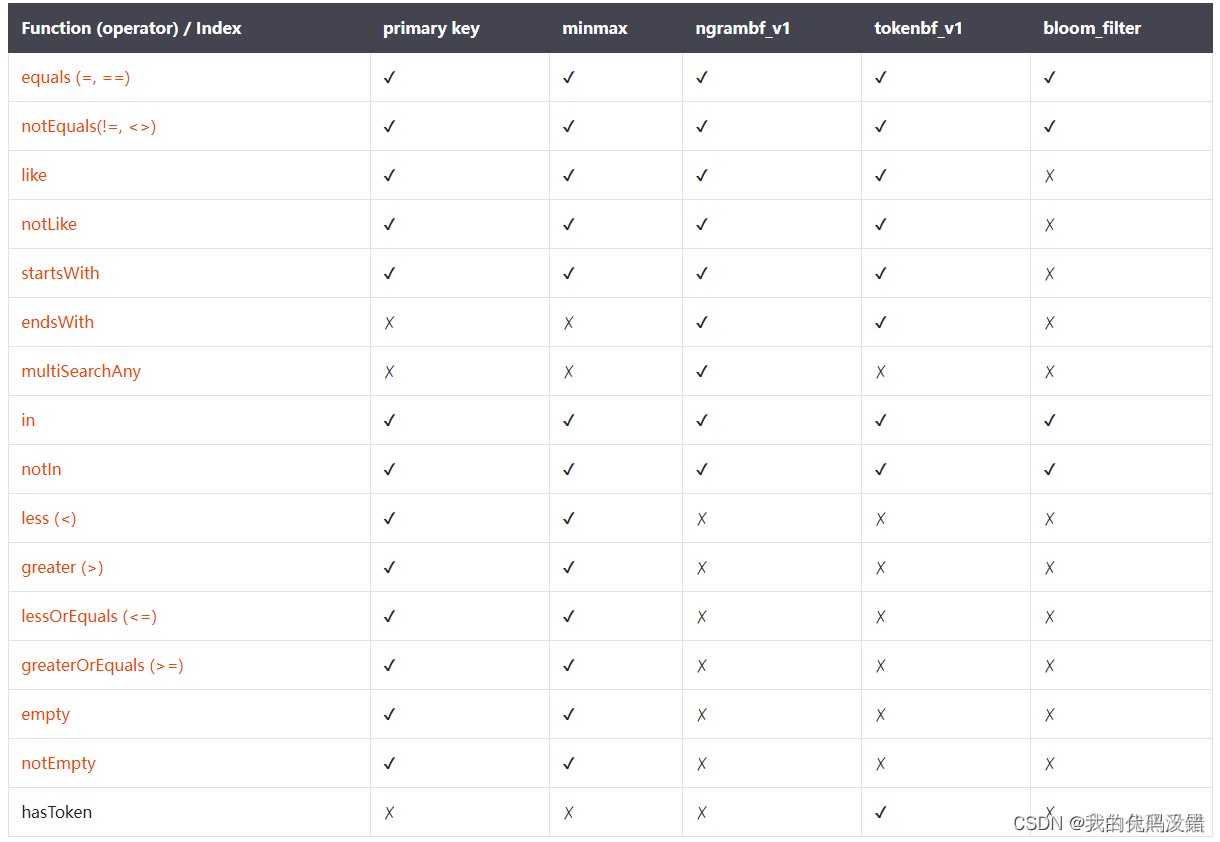
※ 注意:参数小于ngram大小的常量函数不能被ngrambf_v1用于查询优化。例如,ngrambf_v1的参数n为5,即5元短语,则 where like ‘ab%’ 不能被优化。
因为布隆过滤器存在误报率,所以 ngrambf_v1, tokenbf_v1, 和 bloom_filter 不能用于优化结果逻辑为False的查询。例如,下面查询语句可以优化:
s LIKE '%test%'
NOT s NOT LIKE '%test%'
s = 1
NOT s != 1
startsWith(s, 'test')
下面的语句不能被优化:
NOT s LIKE '%test%'
s NOT LIKE '%test%'
NOT s = 1
s != 1
NOT startsWith(s, 'test')
因为布隆过滤器可以明确地判断该条语句是不存在,但是却不能明确地判断一定是存在的,所以对于返回存在like后数据的块还需要全部解压扫描。
所有跳数索引的原则都是“排除法”,即尽可能的排除那些一定不满足条件的索引粒度。在写查询where条件时也要基于这一原则考虑。
数据TTL
Time To Live,MergeTree提供了可以管理数据表或者列的生命周期的功能,TTL用于设置值的生命周期,它既可以为整张表设置,也可以为每个列字段单独设置。表级别的 TTL 还会指定数据在磁盘和卷上自动转移的逻辑。
要定义TTL,必须要使用时间间隔操作符,如下所示
TTL date_time + INTERVAL 5 SECONDS
TTL date_time + INTERVAL 15 HOUR
TTL date_time + INTERVAL 1 MONTH
要想在建表时使用TTL,则TTL 表达式的计算结果必须是日期或日期时间 类型的字段。
如 TTL time_column
TTL time_column + interval
列级别的TTL
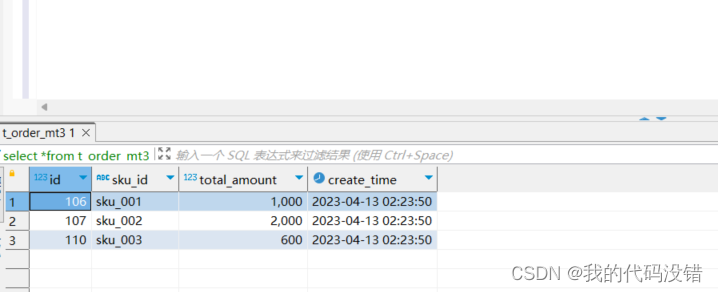
1)建立带有TTL列的表,这里定义total_amount 这一列的数据30s后结束生命周期
create table t_order_mt3(id UInt32,sku_id String,total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,create_time Datetime ) engine =MergeTreepartition by toYYYYMMDD(create_time)primary key (id)order by (id, sku_id);2)插入数据
insert into t_order_mt3 values
(106,'sku_001',1000.00,now()),
(107,'sku_002',2000.00,now()),
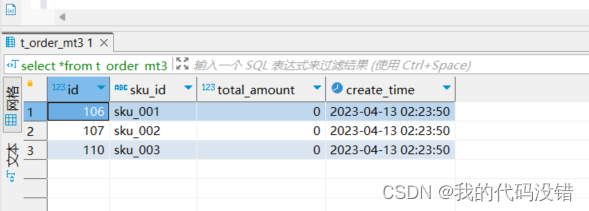
(110,'sku_003',600.00,now());此时查询还有数据
执行手动合并分区
optimize table t_order_mt3 final
执行手动合并后再次查询可以看到此时的total_amount这列数据已经清空了.
表级别TTL
可以在MergeTree的表参数中增加TTL表达式 为整张表设置TTL。
CREATE TABLE stu
(id Int32 ,name String ,create_time DateTime)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
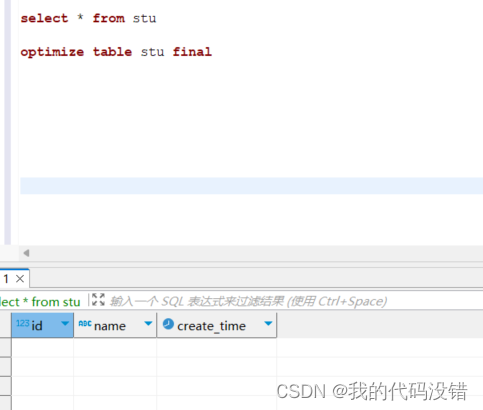
ORDER BY id TTL create_time + INTERVAL 30 SECOND DELETE ; 这里可以看到与列级TTL相比,表级TTL只不过是把TTL直接定义在了表外,相对于对全局的一个TTL定义,最后的DELETE 可加可不加,默认到期了整行数据都会删除.
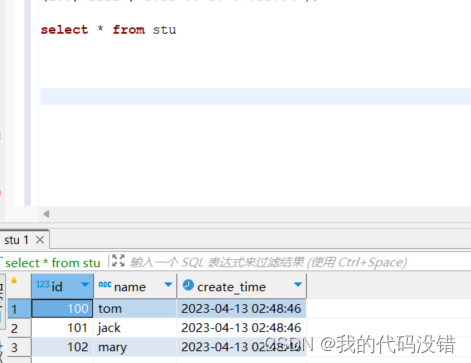
插入数据
insert into stu values
(100,'tom',now()),
(101,'jack',now()),
(102,'mary',now()),
(103,'lili','2021-08-18 07:12:34');此刻查询还有数据
强制合并
适用场景:
数仓建设需要考虑数据的生命周期问题,数据的生命周期包括数据最初的写入,存储,处理,查询,归档和销毁几个基本的阶段。
实际中数仓数据量的成倍增长,不但产生了巨大容量的存储,同时也造成管理的困难,更换存储方式和存储迁移对项目来讲都是需要考虑
成本和风险的。clickhouse这样的一个设计,可以有效处理解决数据有效的存储周期和销毁的问题。ck的出现对数据存储的
数仓的业务选型又添加一种选择。
概言之:
1.定期删除过期数据
2.定期移动过期数据进行归档