python零基础实现基于旋转特征的自监督学习(一)——算法思路解析以及数据集读取

系列文章目录
基于旋转特征的自监督学习(一)——算法思路解析以及数据集读取
基于旋转特征的自监督学习(二)——在resnet18模型下应用自监督学习
基于旋转特征的自监督学习(一)——算法思路解析
- 系列文章目录
- 前言
- 算法概述
- 数据加载
-
- 基于旋转特征的自监督学习数据加载器
-
- 旋转过程
- 通道转换
- 实现代码
- 监督学习数据加载器
前言
在本专栏的第一个项目pytorch实现手写数学符号识别项目中,我们实现了多分类问题。有这样一个论文中提到的方法,能够通过简单的处理使得图像任务的处理效果更好(是的,下面介绍的方法不只是可以用于图像分类任务,还可以用于其他任务)。
代码地址:https://github.com/AiXing-w/little-test-for-FeatureLearningRotNet
算法的翻译可见:论文翻译——通过预测图像旋转进行自监督学习(英汉对照),不过博主只是做了对于算法思路的翻译,后边实验的效果需要查看的话可以自行查看原论文:https://arxiv.org/abs/1803.07728,当然,本文中也会先介绍论文的思路。
算法概述
论文中的思路是将图片进行0度,90度,180度和270度的旋转,此时将0度,90度,180度和270度的旋转结果的标签设置为0,1,2,3。然后使用旋转的四个图像以及标签作为训练数据训练一个四分类模型。此时需要注意的是每一张图片的旋转结果(4张图片)一定要同时全部传入四分类模型。这里的标签形如[0,1,2,3,0,.1,2,3,......0,1,2,3][0, 1, 2, 3, 0,. 1, 2, 3, ......0, 1, 2, 3][0,1,2,3,0,.1,2,3,......0,1,2,3]
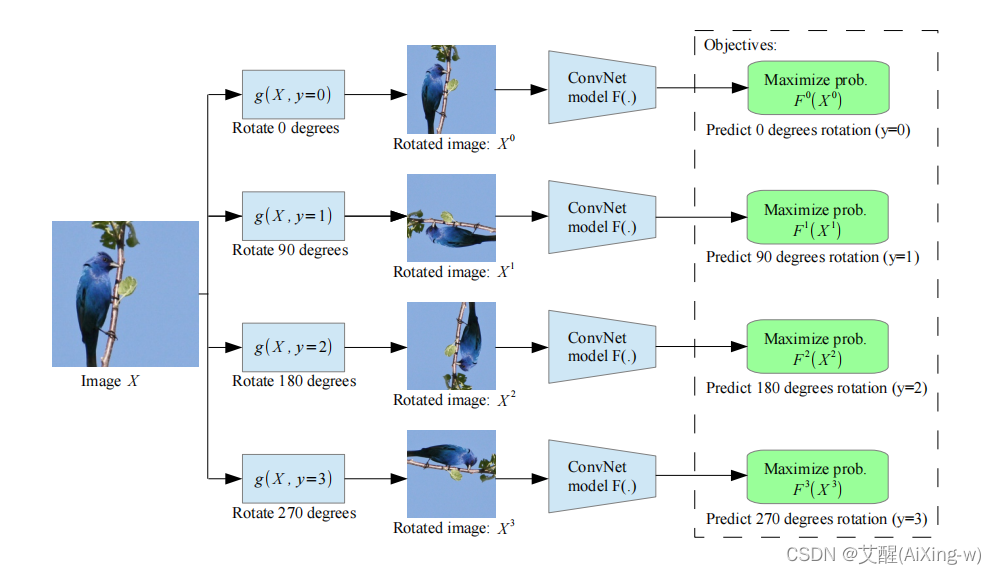
接下来就是对四分类模型的训练过程,训练结束后将最后的全连接层去掉,然后拼接上新的全连接层(全连接层与实际任务相关,以分类任务举例就是与实际分类相符合的全连接层)。
下面的图像是监督学习与使用特征旋转的自监督学习方法得到的特征的对比,可以看到使用了特征旋转的自监督学习得到的特征更为清晰

数据加载
由于在自监督学习阶段需要经过多次旋转并且更改标签,所以我们需要写两个数据加载器,其一是加载旋转特征的数据,其二是原任务的数据,在开始之前,我们新建一个./data文件夹
基于旋转特征的自监督学习数据加载器
在torchvision.datasets中可以可以直接读取CIFAR10数据集,首先我们直接使用torch.datasets.CIFAR10下载并读入cifar-10数据集,然后通过迭代所有的数据,通过cv2.flip对图像进行旋转。
旋转过程
假设我们有这样一张图

我们用以下代码来测试旋转效果
import cv2
import numpy as npimg = cv2.imread("1.jpg")
print(img.shape)
img_90 = cv2.flip(cv2.transpose(img), 1)
img_180 = cv2.flip(cv2.transpose(img_90), 1)
img_270 = cv2.flip(cv2.transpose(img_180), 1)cv2.imshow('i', np.hstack([img, img_90, img_180, img_270]))
cv2.waitKey(0)
cv2.destroyAllWindows()
运行结果:

通道转换
要注意的是使用torch模型需要用到torch.tensor类型的数据而opencv使用的是numpy.array类型的数据。以及torch中图像格式是(c, h, w)[即(通道数,图像高, 图像宽)],而opencv中图像格式是(h, w, c)[即(图像高, 图像宽,通道数)]所以还需要对通道数进行转换。
其中可以使用permute对通道数进行调整,如果原始图像是(c, h, w),那么使用permute(1, 2, 0)即可转换成(h, w, c), 反之,可以使用permute(2, 0, 1)将(h, w, c)转换成(c, h, w)。
实现代码
from torchvision import datasets
import cv2class RotationDataLoader(Dataset):# 数据加载器def __init__(self, is_train, trans=None):if is_train:if trans is not None:dataset = datasets.CIFAR10(root='data/', train=True, transform=trans, download=True)else:dataset = datasets.CIFAR10(root='data/', train=True, download=True)else:if trans is not None:dataset = datasets.CIFAR10(root='data/', train=False, transform=trans, download=True)else:dataset = datasets.CIFAR10(root='data/', train=False, download=True)self.length = len(dataset)self.images = []self.labels = [i % 4 for i in range(self.length * 4)]for image, _ in dataset:img = image.permute(1, 2, 0).detach().numpy()img_90 = cv2.flip(cv2.transpose(img.copy()), 1)img_180 = cv2.flip(cv2.transpose(img_90.copy()), 1)img_270 = cv2.flip(cv2.transpose(img_180.copy()), 1)self.images += [torch.tensor(img).permute(2, 0, 1), torch.tensor(img_90).permute(2, 0, 1),torch.tensor(img_180).permute(2, 0, 1), torch.tensor(img_270).permute(2, 0, 1)]def __getitem__(self, index):return self.images[index], self.labels[index]def __len__(self):return self.length
我们使用torch.utils.data.DataLoader调用数据加载器构造数据迭代器,经过迭代器的构建后,生成了训练数据迭代器与测试数据迭代器。
from torch.utils.data import DataLoaderdef LoadRotationDataset(batch_size, trans=None):if trans is not None:train_iter = DataLoader(RotationDataLoader(is_train=True, trans=trans), batch_size=batch_size, shuffle=True)test_iter = DataLoader(RotationDataLoader(is_train=False, trans=trans), batch_size=batch_size)else:train_iter = DataLoader(RotationDataLoader(is_train=True), batch_size=batch_size, shuffle=True)test_iter = DataLoader(RotationDataLoader(is_train=False), batch_size=batch_size)return train_iter, test_iter
监督学习数据加载器
监督学习的数据加载器的构建就较为简单了,直接使用torch.datasets.CIFAR10加载并使用torch.utils.data.DataLoader数据构建迭代器
def LoadSuperviseDataset(batch_size, trans=None):if trans is not None:train_dataset = datasets.CIFAR10(root='data/', train=True, transform=trans, download=True)test_dataset = datasets.CIFAR10(root='data/', train=False, transform=trans, download=True)else:train_dataset = datasets.CIFAR10(root='data/', train=True, download=True)test_dataset = datasets.CIFAR10(root='data/', train=False, download=True)train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_iter = DataLoader(test_dataset, batch_size=batch_size)return train_iter, test_iter