基于支持向量机的Digits手写数字识别

基于支持向量机的Digits手写数字识别
描述
支持向量机(Support Vector Machine,简称SVM)模型既可以用于分类也可以用于回归。手写数字识别是一个多分类问题(判断一张手写数字图片是0~9中的哪一个),数据集采用Sklearn自带的Digits数据集,包括1797个手写数字样本,样本为8*8的像素图片,每个样本表示1个手写数字。我们的任务是基于支持向量机算法构建模型,使其能够识别测试集中的手写数字。
本任务的主要实践内容:
-
Digits手写数字数据集的加载与可视化
-
SVM分类模型的创建
-
模型参数调优、评估及手写数字识别预测
源码下载
环境
-
操作系统:Windows10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库
matplotlib 3.3.4 numpy 1.19.5 pandas 1.1.5 scikit-learn 0.24.2 mglearn 0.1.9
分析
Digits数据集中样本数据data的形状为(1797,64),每一行是一个图片的像素数组(长度为64)。样本对应的标签(即每张图片对应的实际数字)存储在target数组中,其长度为1797,因为训练数据是有标签的,因此本实验是监督学习中的一个分类问题。
本任务涉及以下几个环节:
a)加载、查看Digits数据集
b)数据集拆分
d)构建模型拟合数据、评估并做出预测
e)使用其他分类模型做对比
步骤
步骤一、加载、查看Digits数据集
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import matplotlib.pyplot as plt# 加载Digits数据集
digits = load_digits()
data = digits.data # 样本数据
target = digits.target # 标签数据
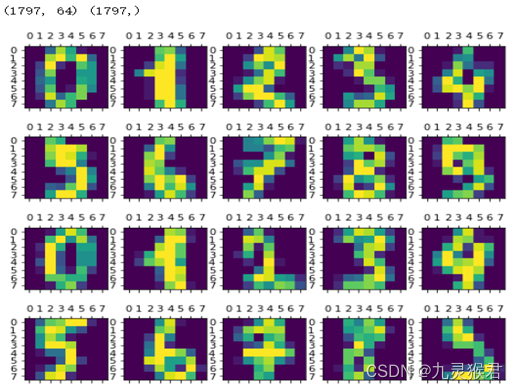
print(data.shape, target.shape) # 输出数组形状# 使用Matplotlib,显示前20张图片
fig = plt.figure(figsize=(8, 8), facecolor='w')
for i in range(20):ax = fig.add_subplot(4, 5, i+1) # matshow方法将像素矩阵显示为图片# data中的图片像素为长度64的一维数组,需要转成8*8的二维数组来显示ax.matshow(data[i].reshape(8, 8))plt.show()
显示结果:
步骤二、数据集拆分、创建模型并预测
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.25, random_state=0)
print(X_train.shape, X_test.shape)# 创建模型,拟合训练数据
# model = SVC().fit(X_train, y_train) # 默认参数准确率不高
model = SVC(gamma='scale').fit(X_train, y_train) # 指定参数# 评估模型
score = model.score(X_test, y_test)
print('score: ', score)# 预测结果并与实际结果对比(预测测试集前20张图片)
y_pred = model.predict(X_test[:20])
print('预测数字:', y_pred)
print('实际数字:', y_test[:20])
输出结果:
(1347, 64) (450, 64)
score: 0.9911111111111112
预测数字: [2 8 2 6 6 7 1 9 8 5 2 8 6 6 6 6 1 0 5 8]
实际数字: [2 8 2 6 6 7 1 9 8 5 2 8 6 6 6 6 1 0 5 8]
步骤三、使用其他分类模型实现
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier# 定义多个分类模型,加入字典中
models = {}
models['逻辑回归'] = LogisticRegression() # 逻辑回归
models['决策树'] = DecisionTreeClassifier() # 决策树
models['随机森林'] = RandomForestClassifier(100) # 集成算法-随机森林
models['K-最近邻'] = KNeighborsClassifier(n_neighbors=3) # K-最近邻
models['支持向量机'] = SVC(gamma='scale') # 支持向量机# 循环拟合数据,评估模型成绩
for key, value in models.items():model = value.fit(X_train, y_train)score = model.score(X_test, y_test)print('{} :{:0.2f}'.format(key, score))输出结果:
逻辑回归 :0.95
决策树 :0.82
随机森林 :0.98
K-最近邻 :0.99
支持向量机 :0.99