大模型学习

大模型学习
- 计算机视觉方向
-
- ViT
-
- Image Token Embedding
- Multi-head Self-attention
- Stable Diffusion
-
- stable diffusion支持功能
- stable diffusion整体结构
- ClipText如何训练
- 图像信息创建器(Image information creator)
- 自动编码解码器(降噪绘制图形)
- 总的流程
- MAE
- DALL-E 2
-
- 总体结构
- 详细原理
-
- 链接文本和视觉语义
- 从视觉语义生成图像
- GLIDE模型
- 自然语言处理
-
- BERT和GPT
- 多模态
-
- ViLBERT阶段
- ViLT阶段
- BLIP-2
-
- Q-Former
- LLM
- 训练
计算机视觉方向
ViT
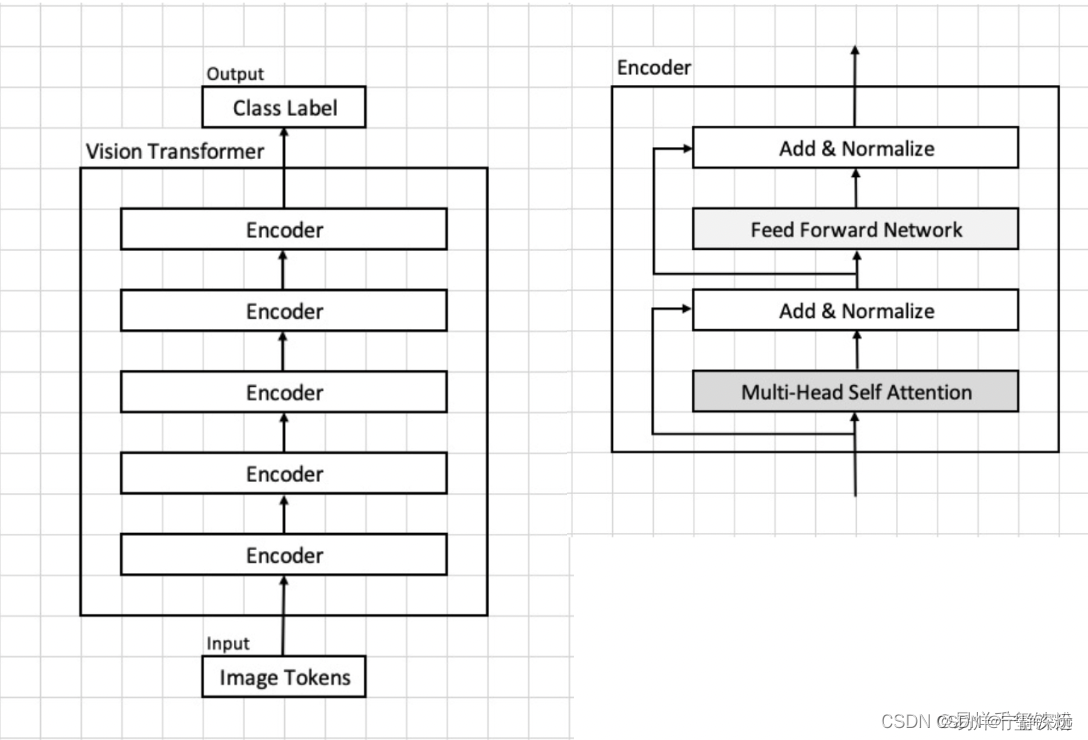
Image Token Embedding
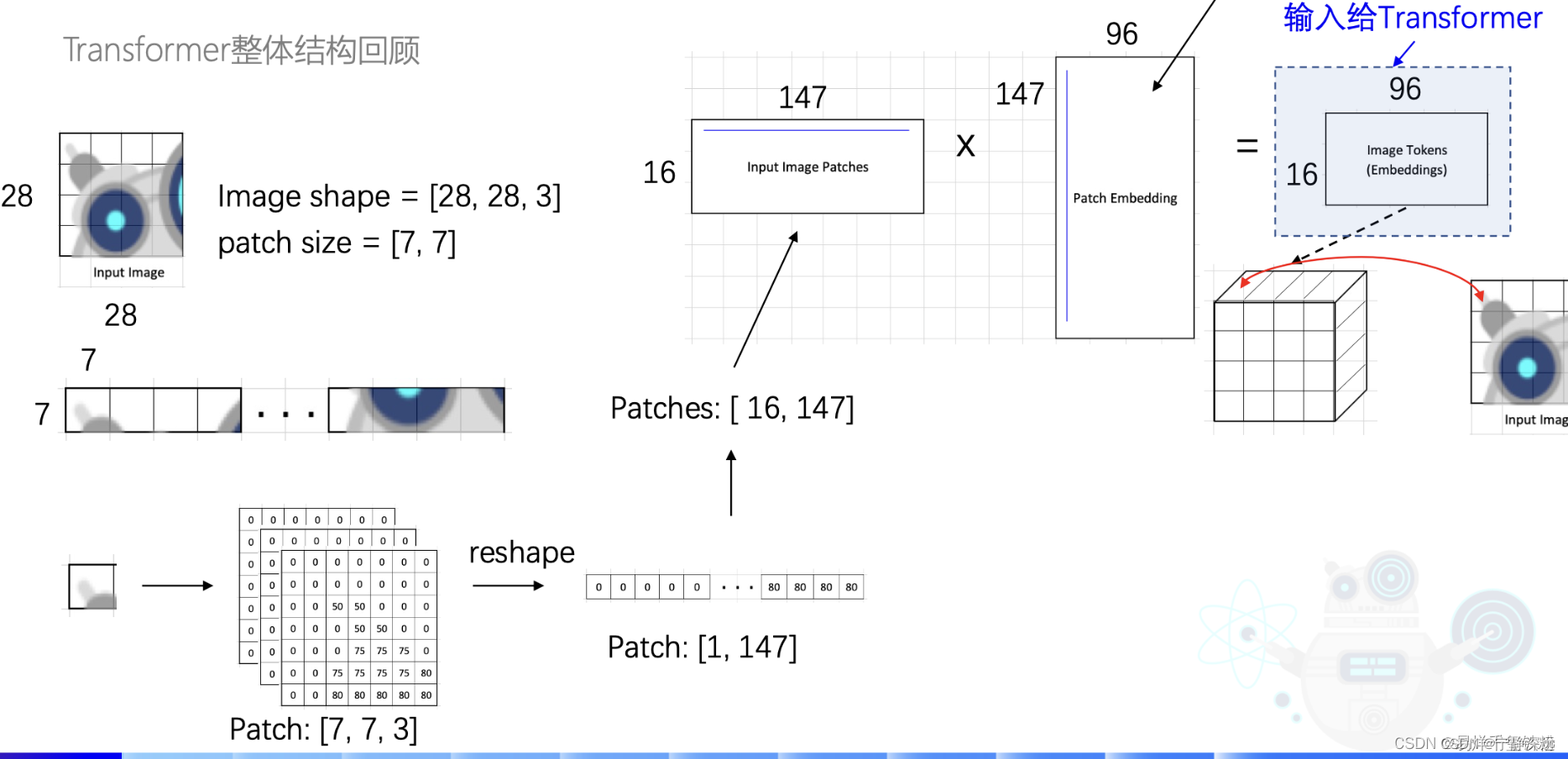
模型输入一个将一张28x28x3的图片,模型先将图片切成一个16块,每一块为7x7。还是3通道的。
再将7x7,3通道的数据,并成一行,[1,7x7x3]=[1,147],
有16块那就是[16,147]。
接着将图片转为特征向量Embedding:
Image16∗147∗W147∗96Image_{16*147}*W_{147*96}Image16∗147∗W147∗96=Embedding
其中W147∗96W_{147*96}W147∗96就是要训练的参数,也就是下图中的Patch Embedding,
Multi-head Self-attention
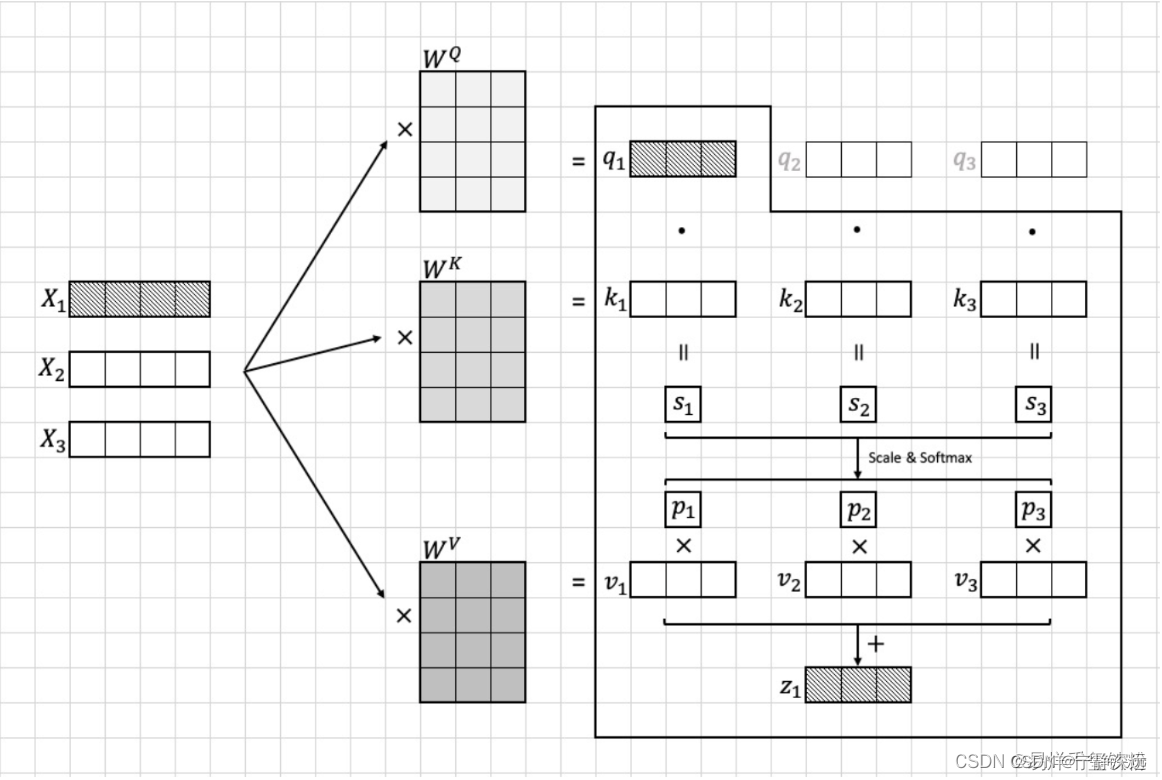
依据模型输入的图片转换为的Image token Embedding,我们假设这个图像块集合为[x1,x2,...,x16][{x_1, x_2, ..., x_{16}}][x1,x2,...,x16],每个图像块的维度为96×1696 \\times 1696×16,接着将这个embedding输入到transformer中。在transformer首先进入到Multi-head Self-attention进行以下四个步骤:线性变换、多头机制、scale和softmax、多头机制。下面我们将逐步说明这些步骤的算法流程。
线性变换
我们首先将每个图像块xix_ixi映射到一个10维的向量ziz_izi这个映射是通过对xix_ixi做一个线性变换得到的,具体而言,我们将xix_ixi乘以一个96×1096 \\times 1096×10的权重矩阵WqW_qWq得到一个10维的向量ziz_izi:
zi=Wqaiz_i = W_q a_izi=Wqai
其中ziz_izi向量包含有qi,ki,viq_i,k_i,v_iqi,ki,vi模型训练需要算出参数有三个变换矩阵 Wq,Wk,WvW_q,W_k,W_vWq,Wk,Wv
MatMul
我们计算每个图像块xix_ixi与其他所有图像块的注意力分数。具体而言,我们计算每对图像块(xi,xj)(x_i, x_j)(xi,xj)的注意力分数ai,ja_{i,j}ai,j,并将其用于加权求和所有图像块的向量表示。
为了计算注意力分数,我们需要先计算每对图像块之间的“相似度”,这个相似度是通过将qiq_iqi与kjk_jkj做点积得到的。
其中,qiq_iqi和kjk_jkj分别是图像块i和图像块j通过线性变换得到的向量。这个点积的结果可以看作是两个向量的余弦相似度,用于衡量它们之间的相似程度,i ∈ [ 1 , 16 ] , j ∈ [ 1 , 16 ] i \\in[1,16],j\\in [1,16]i∈[1,16],j∈[1,16].
sj=qi⋅kjs_j = q_i \\cdot k_jsj=qi⋅kj
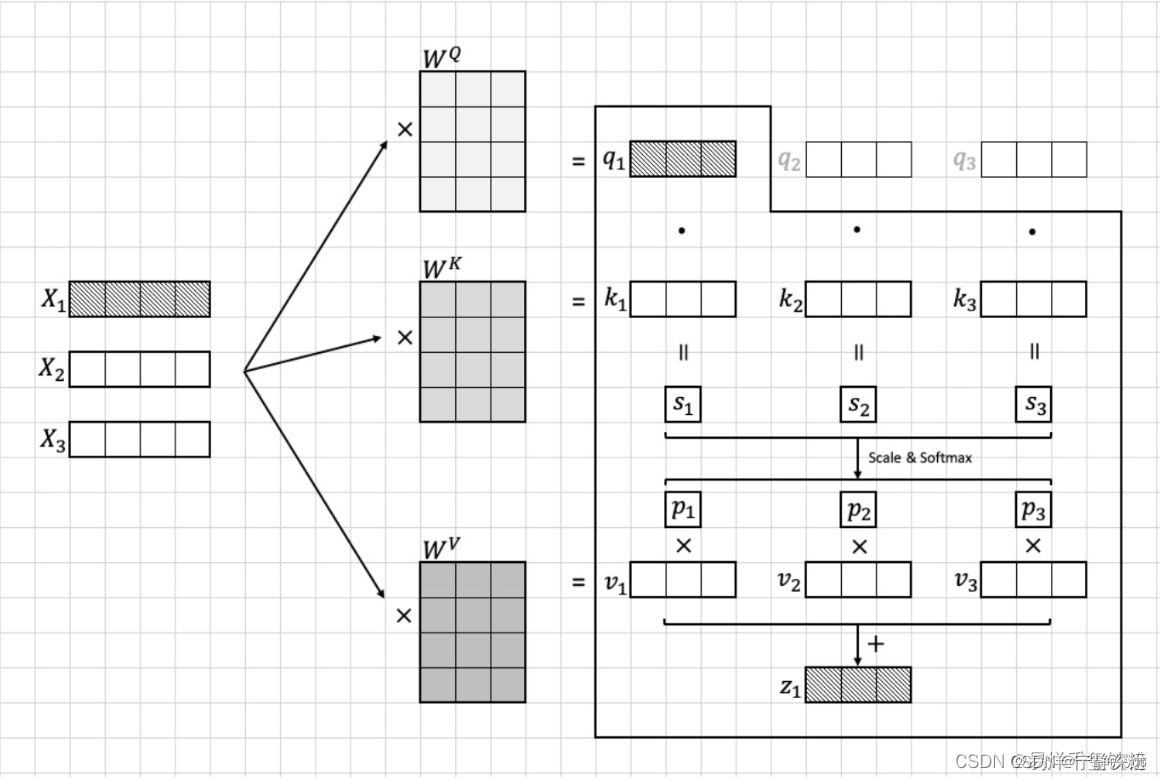
Scale和softmax
然而,直接计算点积可能会因为向量维度较大而导致计算上的不稳定性,因此我们在计算前先将qiq_iqi和kjk_jkj除以一个缩放因子10\\sqrt{10}10,就是特征的维度10,从而保证点积的值较小,不容易出现计算上的不稳定性,然后在进行softmax函数计算。
具体公式如下:
pj=softmax(∑i∑jqi⋅kj10)=qi⋅kj10∑i∑jqi⋅kj10p_j =softmax(\\sum_{i}\\sum_{j}\\frac{q_i \\cdot k_j}{\\sqrt{10}})=\\frac{ \\frac{q_i \\cdot k_j}{\\sqrt{10}}}{\\sum_{i}\\sum_{j} \\frac{q_i \\cdot k_j}{\\sqrt{10}}}pj=softmax(∑i∑j10qi⋅kj)=∑i∑j10qi⋅kj10qi⋅kj
其中,⋅\\cdot⋅表示向量点积运算。注意力分数的分母10\\sqrt{10}10。
MatMul
最后结合向量viv_ivi计算出xix_ixi的注意力特征向量ziz_izi:zi=∑ii=16pi∗viz_i=\\sum_{i}^{i=16} p_i*v_izi=∑ii=16pi∗vi
具体流程可以看下图
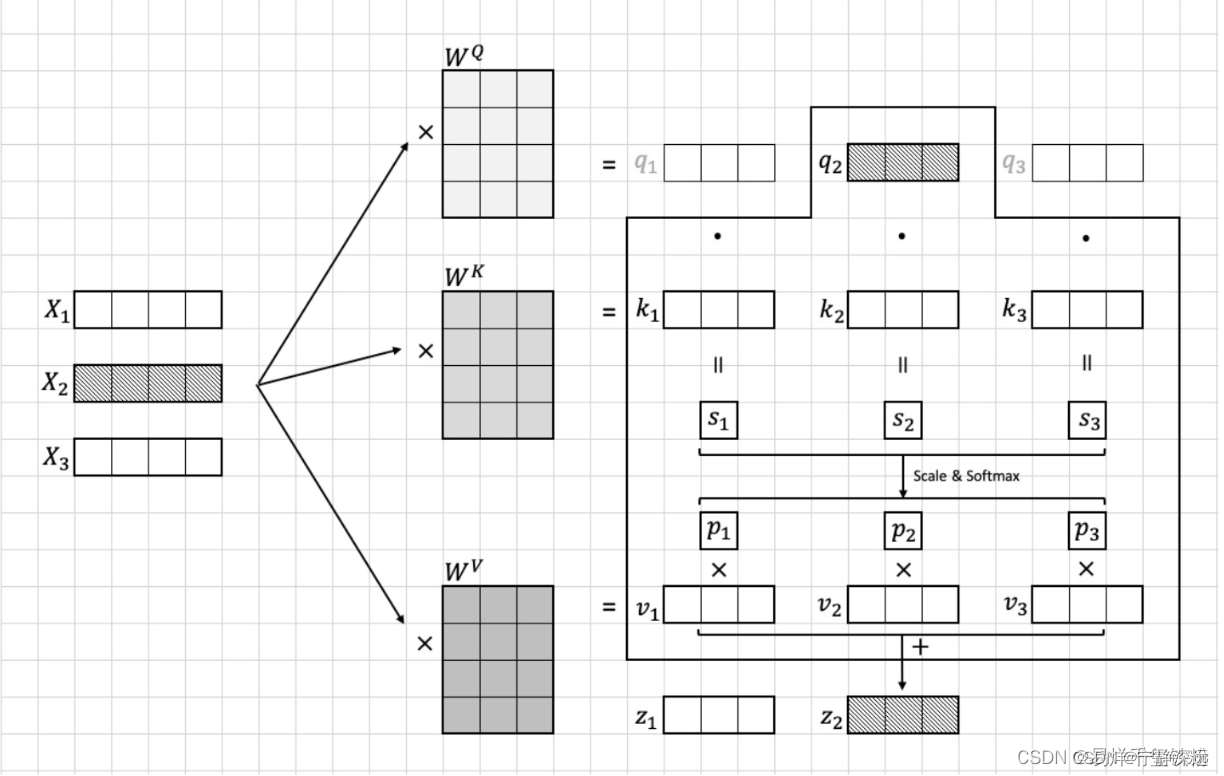
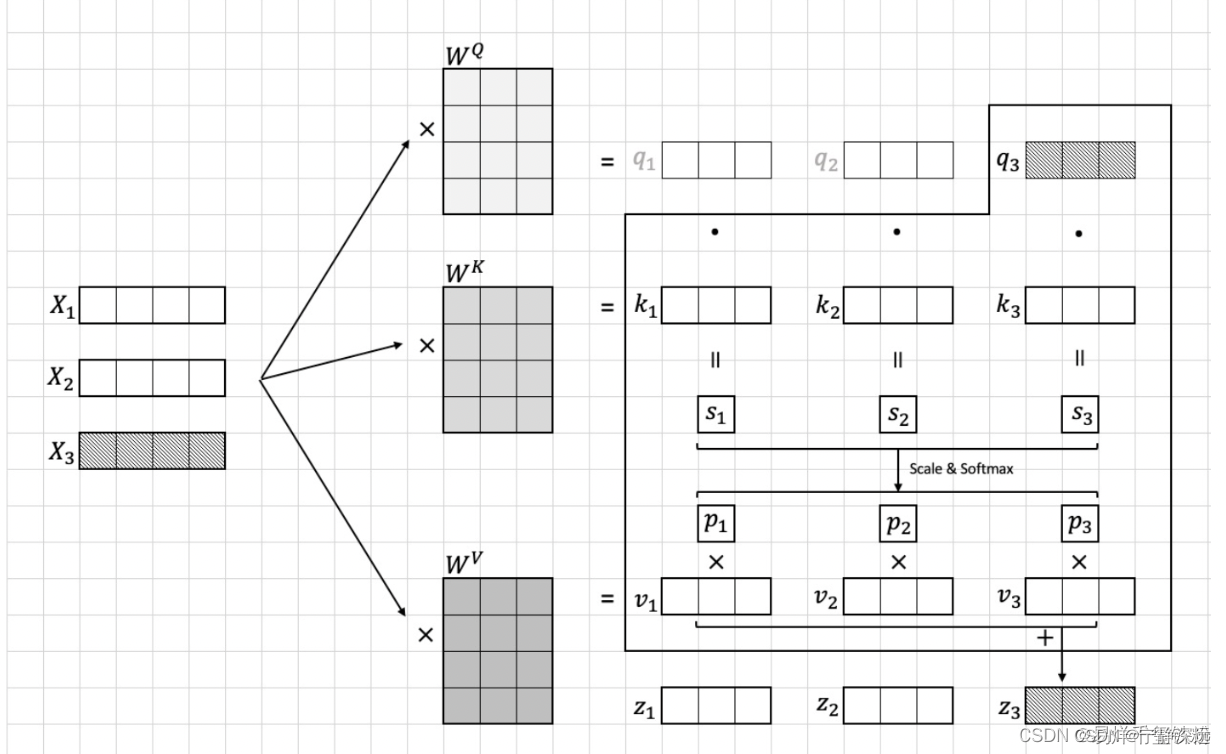
上面这种是对于自注意力的,还有一种多注意力
多注意力实现其实就是多个自注意力这样的结构结合起来,如下图所示
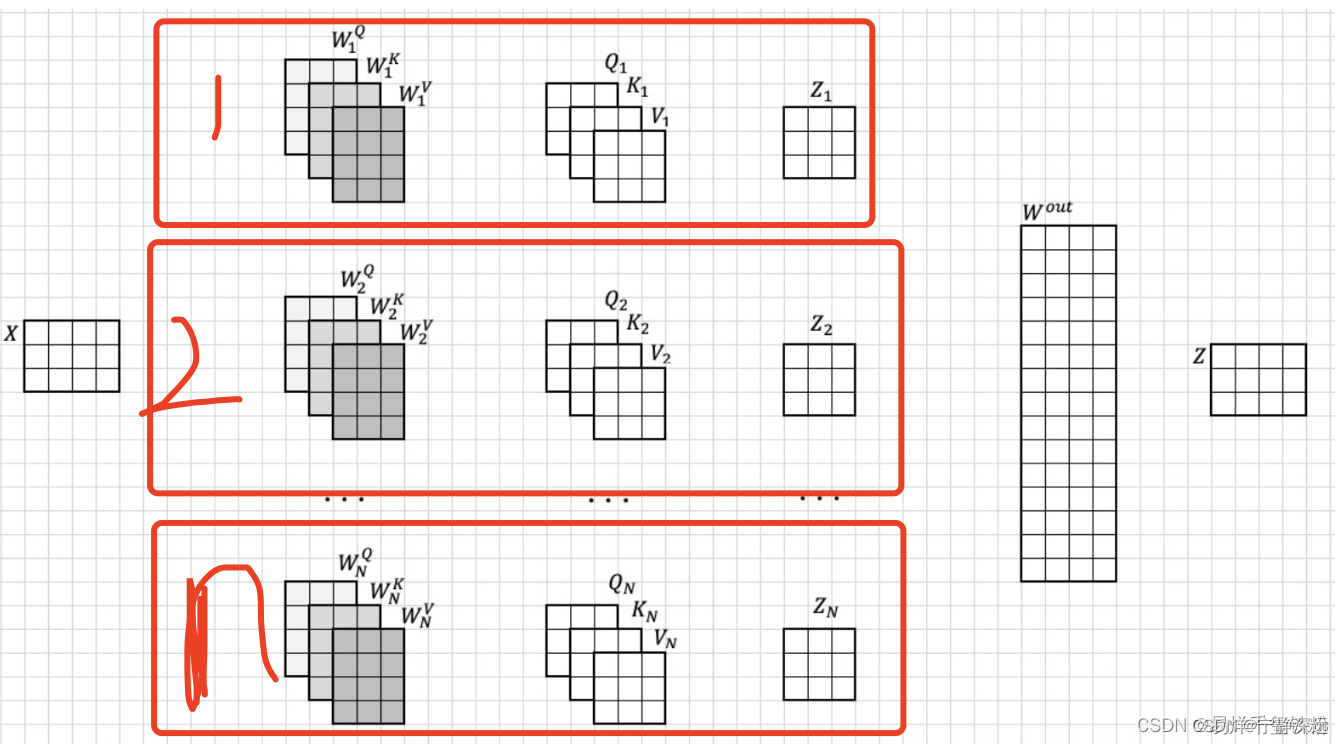
上面的x,就是[x1,x2,x3,...,x16][x_1,x_2,x_3,...,x_{16}][x1,x2,x3,...,x16]
组合起来,以第一个自注意力来看,Q1,K1,V1Q_1,K_1,V_1Q1,K1,V1
其实就是自注意力里的[q1,q2,q3,...,q16],[k1,k2,k3,...,k16],[v1,v2,v3,...,v16][q_1,q_2,q_3,...,q_{16}],[k_1,k_2,k_3,...,k_{16}],[v_1,v_2,v_3,...,v_{16}][q1,q2,q3,...,q16],[k1,k2,k3,...,k16],[v1,v2,v3,...,v16]
Stable Diffusion
stable diffusion支持功能
- 根据文字生成图片

- 文字+图片生成新的图片

stable diffusion整体结构

- ClipText: 用于文本编码。输入: 文本。输出: 77个token embeddings向量,每个向量有768维。
- UNet+调度程序: 在信息(潜在)空间中逐步处理信息。输入: 文本embeddings和一个初始化的多维数组(结构化的数字列表,也称为张量)组成的噪声。输出:经过处理的信息数组。
- 自动编码解码器(Autoencoder Decoder): 使用经过处理的信息数组绘制最终图像。输入:经过处理的信息数组(维数:(4,64,64))输出: 生成的图像(维数:(3,512,512),即(红/绿/蓝;宽,高))。
ClipText如何训练
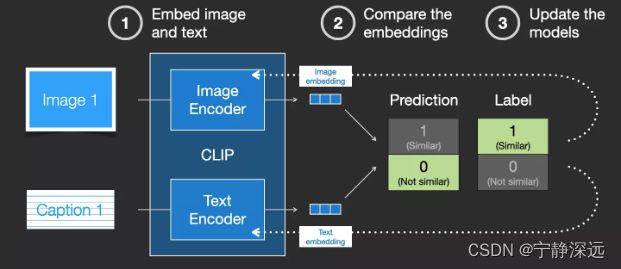
图像和文本描述分别经过图像编码和文本编码,然后计算两个编码的相似度,并形成loss更新编码器参数。
图像信息创建器(Image information creator)
diffusion整体
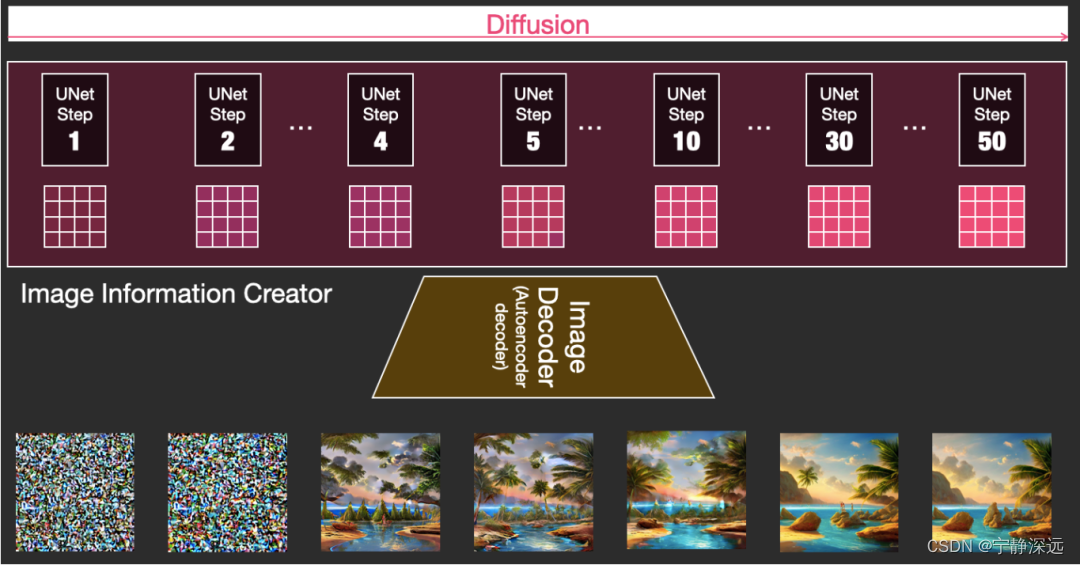
- diffusion采用多步的方式生成,每一步的latents可以通过解码器可视化
- 每个step都在输入的latents数组上运行,并且会产生另一个latents数组
diffusion单步原理
- 训练数据生成(生成的随机噪声作为label,加了噪声的图片作为输入)
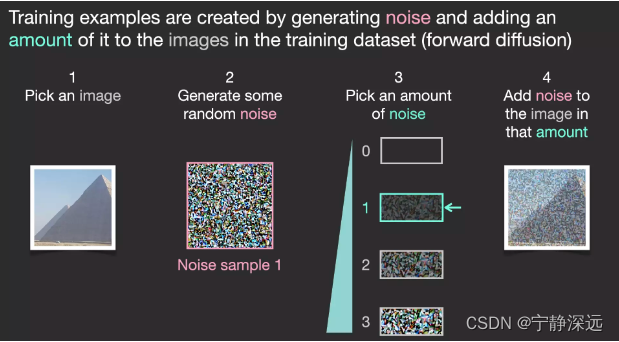
- 训练一个可以预测出噪声的模型
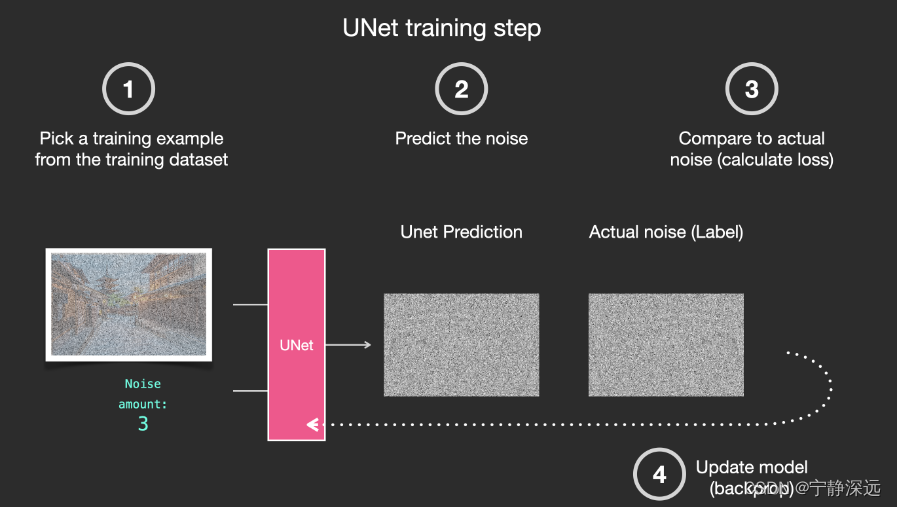
自动编码解码器(降噪绘制图形)
- 经过训练的噪音预测器可以对噪音图像进行降噪处理,并且可以预测噪音。
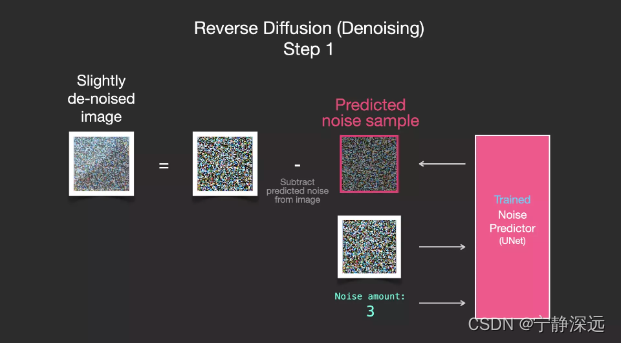
通过采用将noise amount后的图像减去预测的噪声图像来去噪,逐步反向传播实现去噪。
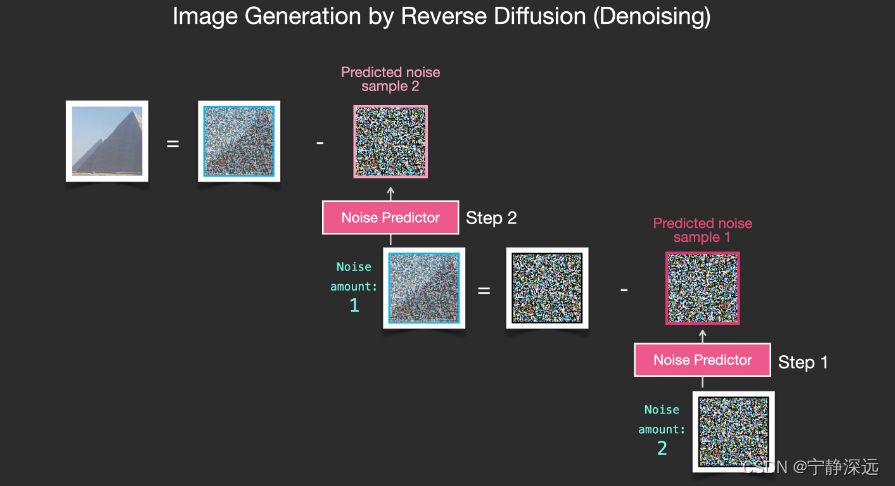
总的流程
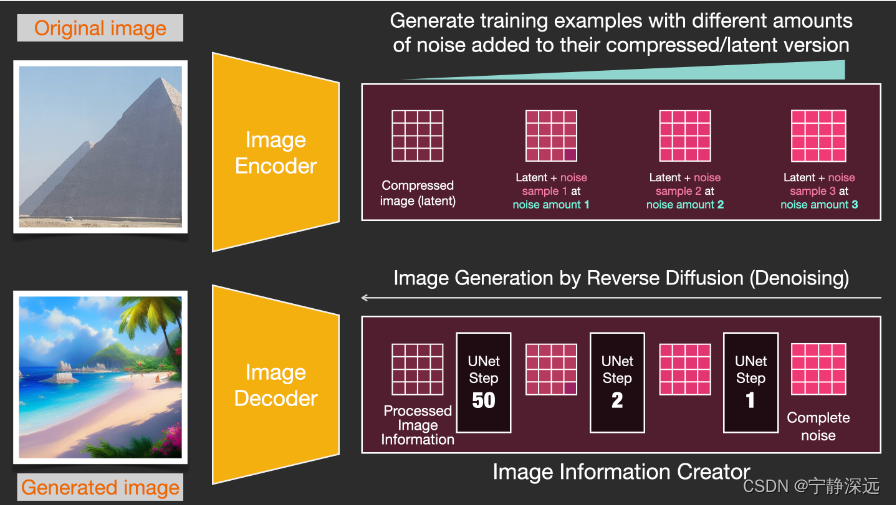
正向扩散是使用Image Encoder生成图像数据,来训练噪声预测器。训练一旦完成,就可以执行反向扩散,使用Image Decoder生成图像。
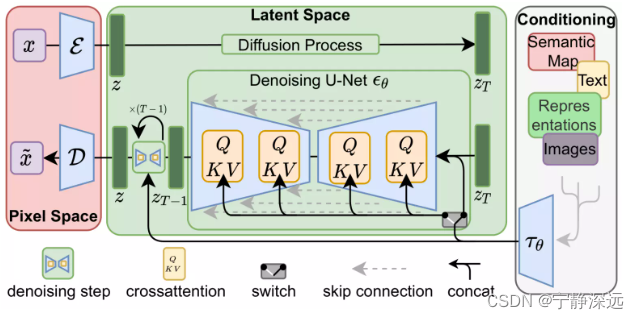
MAE
DALL-E 2
openAI推出
总体结构
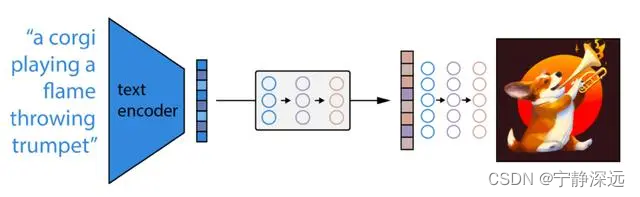
- 首先,CLIP 文本编码器将图像描述映射到表征空间。
- 然后扩散先验从 CLIP 文本编码映射到相应的 CLIP 图像编码。
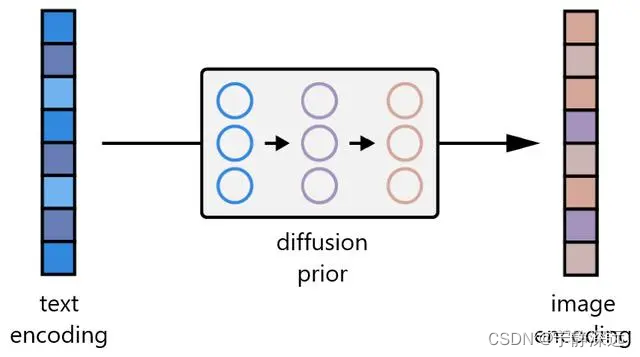
- 最后,修改后的 GLIDE 生成模型通过反向扩散从表征空间映射到图像空间,生成许多可能的图像之一,这些图像在输入说明中传达语义信息。
详细原理
链接文本和视觉语义
训练 CLIP 的基本原则非常简单:
- 首先,所有图像及其相关标题都通过它们各自的编码器,将所有对象映射到一个 m 维空间。
- 然后,计算每个(图像,文本)对的余弦相似度。
- 训练目标是同时最大化 N 个正确编码图像 / 标题对之间的余弦相似度,并最小化 N 2 - N 个不正确编码图像 / 标题对之间的余弦相似度。
从视觉语义生成图像
训练后,CLIP 模型被冻结,DALL-E 2 进入下一个任务。OpenAI 使用其先前模型 GLIDE (https://arxiv.org/abs/2112.10741) 的修改版本来执行此图像生成。GLIDE 模型学习反转图像编码过程,以便随机解码 CLIP 图像嵌入。
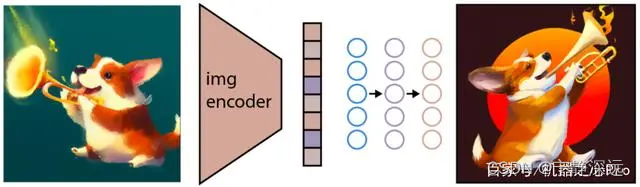
如上图所示,应该注意的是,目标不是构建一个自动编码器并在给定嵌入的情况下准确地重建图像,而是生成一个在给定嵌入的情况下保持原始图像显著特征的图像。为了执行这个图像生成,GLIDE 使用了一个扩散模型。
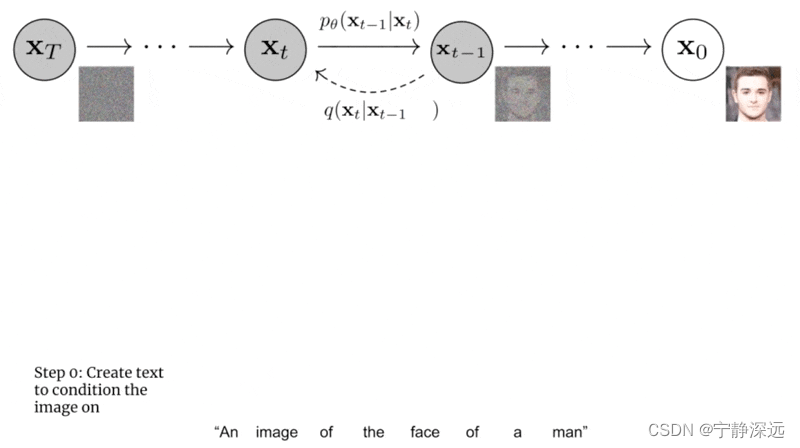
GLIDE模型
GLIDE 通过使用额外的文本信息增强训练来扩展扩散模型的核心概念,最终生成 text-conditional 图像。我们来看看 GLIDE 的训练过程:
自然语言处理
BERT和GPT
-
Bert的网络结构类似于Transformer的Encoder部分,而GPT类似于Transformer的Decoder部分
-
Bert使用Multi-Head-Attention,GPT使用Masked Multi-Head-Attention
-
在Bert的预训练任务中,Bert主要使用“填空题"的方式来完成预训练:
随机盖住一些输入的文字,被mask的部分是随机决定的,当我们输入一个句子时,其中的一些词会被随机mask。
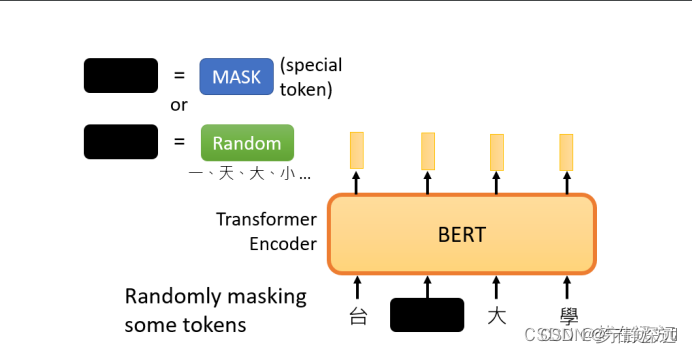
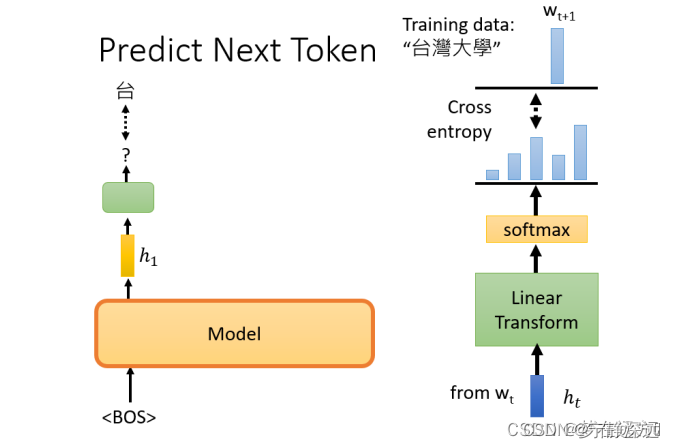
GPT要做的任务是,预测接下来,会出现的token是什么
-
Bert用的是上下文的信息,而GPT仅用了上文的信息。
-
GPT主要用于文本生成任务,而BERT则主要用于文本理解任务
-
BERT和GPT是一个预训练模型,其必须要适应各种各样的自然语言任务。
多模态
多模态问答需要什么能力:
- 图片里发生了什么:一位男士在船头搂着一位女士。(感知-CV模型的能力)
- 问题问的什么:电影的结尾是什么?(感知-NLP模型的能力)
- 图片和电影有什么关系:这是泰坦尼克号里的经典镜头。(对齐融合-多模态模型的能力)
- 电影的结尾是什么:泰坦尼克号沉没了。(推理-LLM模型的能力)
ViLBERT阶段
19年20年的时候,ViLBERT和Uniter采用了Object-Text对来提升模型对图片的理解能力。Object的引入,不可避免的需要一个笨重的检测器,去检测各种框,使得图像模态显得比较笨重。而且检测器模型不可避免的会存在漏检的问题,可以参考后来Open-Vocabulary一些工作,比如ViLD。这一阶段,显然对图像的理解是多模态的重头戏,文本更多是辅助图像任务的理解。
ViLT阶段
到了21年22年,去掉检测器成了主流,ViLT,ALBEF,VLMo,BLIP 等等都抛弃了检测器,彻底摆脱了CNN网络的舒服,全面拥抱Transformer,当然这也得益于本身ViT模型在CV领域的大放光彩,让两个模态的有机融合成为了可能。在这一阶段,文本模态感觉已经可以和图像模态平起平坐了。从在各项具体下游任务(VQA、VG、ITR)的实际表现上来说,已经比较令人满意了。但总感觉差点味道,就是复杂推理。比如VQA上的问题,大多数是简单的逻辑计算或识别,感觉还不够智能。
BLIP-2
- 由微软发展
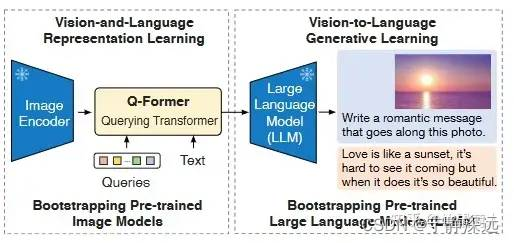
23年1月,BLIP2出来了,引入了LLM。从图像上看,BLIP2大概由这么几个部分组成,图像(Image)输入了图像编码器(Image Encoder),得到的结果与文本(Text)在Q-Former(BERT初始化)里进行融合,最后送入LLM模型。
Q-Former
为了融合特征,那Transformer架构是最合适不过的了。熟悉ALBEF或者BLIP的同学或许发现,Q-Former的结构和ALBEF其实很像,如果看代码的话,可以发现就是在ALBEF基础上改的。
相较于ALBEF,最大的不同,就是Learned Query的引入。可以看到这些Query通过Cross-Attention与图像的特征交互,通过Self-Attention与文本的特征交互。这样做的好处有两个:(1)这些Query是基于两种模态信息得到的;(2)无论多大的视觉Backbone,最后都是Query长度的特征输出,大大降低了计算量。比如在实际实验中,ViT-L/14的模型的输出的特征是257x1024的大小,最后也是32x768的Query特征。
LLM
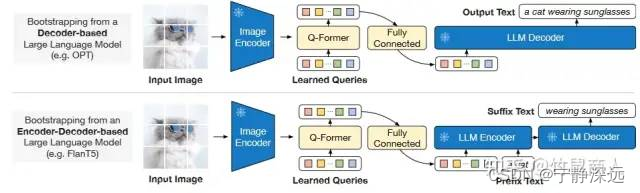
这里作者针对两类不同LLM设计了不同的任务:
- Decoder类型的LLM(如OPT):以Query做输入,文本做目标;
- Encoder-Decoder类型的LLM(如FlanT5):以Query和一句话的前半段做输入,以后半段做目标;
训练
训练细节
作为图文预训练的工作,工程问题往往是关键。BLIP2的训练过程主要由以下几个值得关注的点:
- 训练数据方面:包含常见的 COCO,VG,SBU,CC3M,CC12M 以及 115M的LAION400M中的图片。采用了BLIP中的CapFilt方法来Bootstrapping训练数据。
- CV模型:选择了CLIP的ViT-L/14和ViT-G/14,特别的是,作者采用倒数第二层的特征作为输出。
- LLM模型:选择了OPT和FlanT5的一些不同规模的模型。
- 训练时,CV模型和LLM都是冻结的状态,并且参数都转为了FP16。这使得模型的计算量大幅度降低。主要训练的基于BERT-base初始化的Q-Former只有188M的参数量。
- 最大的模型,ViT-G/14和FlanT5-XXL,只需要16卡A100 40G,训练6+3天就可以完成。
- 所有的图片都被缩放到224x224的大小。