虚拟线程详解

前言
虚拟线程又叫协程。
JDK19 中引入了虚拟线程,这是一个重大的更新项,虚拟线程在Project Loom项目中已经孵化很久了。据官方阐述,引入的原因是虚拟线程是轻量级线程,它可以大大减少编写、维护和观察高吞吐量并发应用程序的工作量,能够大大提升服务的高并发性能。允许通过 java.lang.ThreadAPI 的现有代码来使用虚拟线程,并且只做最小的更改。(当然虚拟线程不是Java语言独有的,更不是Java发明的,只是JDK19时才引入,比如Go语言的goroutines和Erlang语言早就支持虚拟线程了)
各种语言争相引入虚拟线程的原因就是它能以简单的方式来提高系统并发性能。那么虚拟线程是怎么做到的?它背后的原理是怎样的?它和我们之前接触的普通线程(后面我们称之为“平台线程”)又有什么区别?怎么使用?下面我们一起来深入探讨一下。
一、虚拟线程 vs 平台线程
我们先来看看虚拟线程和我们之前接触的普通线程(平台线程)的区别。
1.1 平台线程
平台线程就是我们平时接触的普通线程,JDK19之前,Java中的线程就是一个平台线程。
平台线程就是对底层操作系统线程的包装,而且两者是一对一的关系,即一个平台线程就对于一个操作系统的线程。因为操作系统的线程资源是有限的,能够支持的线程总数是有边界的,所以平台线程也是有限的,不能无限生产。
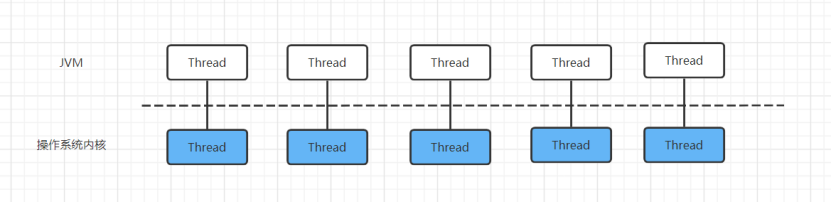
在单台服务器硬件资源确定的情况下,平台线程的数量会因为硬件资源而受到限制,也成为单台服务器吞吐量提升的主要障碍。比如一台机器最多只支持1000个系统线程,那么这个机器所能产生的平台线程数最多也就1000个。因此线程数量在平台线程这里成了瓶颈。平台线程模型如下:
另外,平台线程的创建和销毁所带来的开销是非常大的,所以JAVA采用线程池的方式来维护平台线程而避免线程的反复创建和销毁。但是线程池也仅仅只是缩短了线程创建和销毁的时间成本,并不能增加线程数量。一般情况下,往往在CPU和网络连接成为系统瓶颈前,平台线程数量会先成为系统瓶颈。
1.2 虚拟线程
虚拟线程则是由JDK而非操作系统提供的一种线程轻量级实现,它没有绑定到特定操作系统线程。
注意这里说的是没绑定到“特定”的系统线程,虚拟线程和系统线程并不是一对一的映射关系,实际上是m:n(m一般远大于n)的关系。
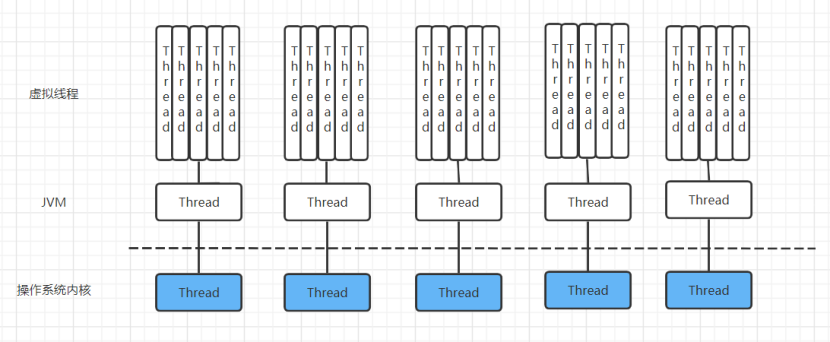
可以看到虚拟线程不再是每一个线程都一对一的对应一个操作系统的线程了,而是会将多个虚拟线程映射到少量操作系统线程中,这些虚拟线程是由JVM管理的,因此它们不会增加额外的上下文切换开销,因为它们作为普通Java对象存储在RAM中。
对于操作系统来说,仍然只知道平台线程,它是基本的调度单元,虚拟线程是在JVM中实现的,Java运行虚拟线程时通过将其安装在某个平台线程(称为载体线程)上来运行它。挂载虚拟线程到平台线程的时候,JVM会将所需的线程栈从堆中临时复制到载体线程堆栈中,并在挂载时借用载体堆栈。当在虚拟线程中运行的代码因为IO、锁或者其他资源可用性而阻塞时,虚拟线程可以从载体线程中卸载,并且复制的任何线程栈改动信息都将会存回到堆中,从而释放载体线程,以使其继续运行其他虚拟线程。JDK中几乎所有的阻塞掉都已经调整过了,因此当在虚拟线程上遇到阻塞操作时,虚拟线程会从其载体上卸载而不是阻塞。
最重要的,既然可以将多个虚拟线程映射到少量操作系统线程中,那么线程数量就不再是瓶颈。100W个虚拟线程底层可以绑定同一个系统线程,可以说虚拟线程的数量是一种近乎于无限多的线程。硬件利用率接近最佳,允许高水平的并发性,从而提高吞吐量。在相同硬件配置服务器的情况下,虚拟线程比使用平台线程具备更高的并发性,从而提升整个应用程序的吞吐量(关于这一点,后面会进一步阐述)。如果说平台线程和系统线程调度为1:1的方式,虚拟线程则采用M:N的调度方式,其中大量的虚拟线程M在较少的系统线程N上运行。
小结:
- 平台线程:与系统线程一对一映射,创建、上下文切换、销毁成本高,数量瓶颈
- 虚拟线程:与系统线程多对多映射,由JVM管理,更廉价,数量不受限制
二、 并发风格
上面是从整体上给大家介绍了一下虚拟线程以及它和平台线程的区别,这里进一步阐述虚拟线程的优势,在说明之前大家还要了解下两种并发风格,所谓的并发风格其实就是我们使用线程去处理每个请求的方式。
2.1 thread-per-request style
第一种并发风格就是 thread-per-request style,字面意思就是一个请求用一个线程去处理的风格。即在整个请求持续期间为该请求分配一个线程来处理该请求。这种 style 易于理解、易于编程、易于调试和配置,堆栈信息追踪也比较容易。
但这种风格的缺点也是明显的,那就是分配的这个线程在这个请求没有完成之前是没有机会去处理其他请求的,即使这个请求中出现了IO阻塞这个线程也只能等待。举个例子假设一个平均延迟为 50ms 的应用程序通过并发处理 10 个请求实现每秒 200 个请求的吞吐量。为了使该应用程序的吞吐量达到每秒 2000 个请求,它将需要同时处理 100 个请求。如果在请求持续期间每个请求都在一个线程中处理,那么为了让应用程序跟上,线程的数量必须随着吞吐量的增长而增长。
不幸的是,可用线程的数量是有限的,因为 JDK 将线程实现为操作系统(OS)线程的包装器。如果每个请求在其持续时间内消耗一个线程,从而消耗一个 OS 线程,那么线程的数量通常会在其他资源(如 CPU 或网络连接)耗尽之前很久成为限制因素。JDK 当前的线程实现将应用程序的吞吐量限制在远低于硬件所能支持的水平。即使在线程池中也会发生这种情况,因为池有助于避免启动新线程的高成本,但不会增加线程的总数。
虚拟线程和线程池的区别:
- 线程池也仅仅只是缩短了线程创建和销毁的时间成本,并不能增加线程数量
- 虚拟线程数量不受限制,随用随取
2.2 asynchronous style
这种就是异步风格,它是一种共享的思想。
请求处理代码不是从头到尾处理一个线程上的请求,而是在等待 I/O 操作完成时将其线程返回到一个池中,以便该线程能够处理其他请求。这种细粒度的线程共享(其中代码只在执行计算时保留一个线程,而不是在等待 I/O 时保留该线程)允许大量并发操作,而不需要消耗大量线程。那这样相对于thread-per-request style这种风格可以大大的提高系统的吞吐量,提升高并发能力。
Every coin has two sides,这种异步风格也有它的缺陷,首先就是它需要异步编程 style ,采用一组独立的 I/O 方法,这些方法不等待 I/O 操作完成,而是在以后将其完成信号发送给回调。如果没有专门的线程,开发人员必须将请求处理逻辑分解成小的阶段,通常以 lambda 表达式的形式编写,然后将它们组合成带有 API 的顺序管道(例如,参见 CompletableFuture,或者所谓的“反应性”框架)。因此,它们放弃了语言的基本顺序组合运算符,如循环和 try/catch 块。
在异步样式中,请求的每个阶段可能在不同的线程上执行,每个线程以交错的方式运行属于不同请求的阶段,那么堆栈跟踪不能提供可用的上下文,调试器不能单步执行请求处理逻辑,分析器不能将操作的成本与其调用方关联。
小结:

三、取其精华,去其糟粕
可以看到,以上两种并发风格各有优缺点,虚拟线程则是结合两者的优点,摒弃了它们的缺点。
为什么虚拟线程可以做到“取其精华,去其糟粕”?
因为thread-per-request style风格实际上已经很完美了,唯一的短板就是线程数量不够!虚拟线程这个时候就是雪中送炭了,因为虚拟线程可以理解成是无限资源,一个请求过来就用一个虚拟线程去处理这个请求完全没有压力。
因为虚拟线程的加入,thread-per-request 风格的应用程序代码可以在整个请求期间在虚拟线程中运行,但是虚拟线程只在 CPU 上执行计算时使用绑定的操作系统线程。
也就是说,整个过程就是这个虚拟线程小弟在跟踪主导,只是在有计算任务时让操作系统线程大哥出面来处理下,大哥处理完这个请求的计算任务后可以回到池中执行其他请求的计算任务而不用等待,等待的事情接着由虚拟线程这个小弟去完成。那么系统线程大哥是一直在忙碌的,忙着执行各个请求的CPU计算任务,没有停下等待的情况,这也是前面说虚拟线程硬件利用率接近最佳,允许高水平的并发性,从而提高吞吐量,可以让机器的硬件资源发挥到最佳的原因。
同时,因为兼顾了 thread-per-request style 风格所以可以方便地对虚拟线程进行故障排除、调试和分析。
四、虚拟线程的使用场景
基于第三节的介绍,thread-per-request 风格的应用程序代码可以在整个请求期间在虚拟线程中运行,但是虚拟线程只在 CPU 上执行计算时使用绑定的操作系统线程。虚拟线程可以代替系统线程去完成IO等待,系统线程则一直在处理计算任务,因此可以将硬件性能发挥到最佳。
那么可以摄像一种极端的情况:就是这个应用是计算密集性服务,也就是没有或很少有IO操作,那么这种服务中使用虚拟线程就没有太大必要了。
总结下虚拟线程的使用场景:
- 应用系统有大量的并发任务(超过几千个并发任务),这些任务也需要大量的时间等待
- IO密集型场景,工作负载不受CPU限制
五、使用虚拟线程
虚拟线程在设计之初就考虑了自身使用时的便捷性,就如一开始说的,它在提高并发度的同时,又可以大大减少编写、维护和观察高吞吐量并发应用程序的工作量。
所以虚拟线程允许通过 java.lang.ThreadAPI 的现有代码使用虚拟线程,并且只做最小的更改。虚拟线程具有相对较少的新的API,创建完虚拟线程后,他们是普通的Thread对象,并且表现得向我们已经所了解的线程。例如,Thread.currentThread、ThreadLocal、中断、堆栈遍历等,在虚拟线程上的工作方式与在平台线程上的工作方式完全相同,这意味着我们可以自信地在虚拟线程上运行我们现有的代码。
5.1 创建虚拟线程
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {IntStream.range(0, 10000).forEach(i -> {executor.submit(() -> {Thread.sleep(Duration.ofSeconds(1));return i;});});
} // executor.close() is called implicitly, and waits上面就是一个创建大量虚拟线程的示例程序,为每个提交的任务创建一个新的虚拟线程。然后,它提交10000项任务,等待所有任务完成。这里轻松就创建了1w个线程,要是这里创建的是平时的平台线程,如果机器物理资源不支持这些个数的线程数那么创建时就会报错。但这里创建的是虚拟线程,理论上可以创建无穷大个虚拟线程,所以这里即使创建100w个虚拟线程也不会报错,这100w个虚拟线程可能底层只绑定到少数的系统线程上。
相反,如果程序使用从池中获取平台线程的 ExecutorService (如 Executors.newFixedThreadPool (200)) ,情况也不会好到哪里去。ExecutorService 将创建200个平台线程,由所有10,000个任务共享,因此许多任务将按顺序运行,而不是并发运行,而且程序将需要很长时间才能完成。对于这个程序,一个有200个平台线程的池只能达到每秒200个任务的吞吐量,而虚拟线程达到每秒10,000个任务的吞吐量(在充分预热之后)。此外,如果示例程序中的10000被更改为1000000,那么该程序将提交1,000,000个任务,创建1,000,000个并发运行的虚拟线程,并且(在足够的预热之后)实现大约1,000,000任务/秒的吞吐量。
那这里你会问:那创建的虚拟线程是不是越多越好呢?
其实这里有个范围,在这个物理机器可以承受的范围内,虚拟线程数当然越多越好,但是如果这个物理机器上的所有系统线程都已经在工作了,机器线程满负荷在工作的时候,再去增加虚拟线程那么意义就不大了。另外,如果这些任务全是CPU计算型的任务,那么使用虚拟线程也没什么作用。
虚拟线程并不是更快的线程ーー它们运行代码的速度并不比平台线程快。它们的存在是为了提供规模(更高的吞吐量) ,而不是速度(更低的延迟) 。
继续举例:
void handle(Request request, Response response) {var url1 = ...var url2 = ...try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {var future1 = executor.submit(() -> fetchURL(url1));var future2 = executor.submit(() -> fetchURL(url2));response.send(future1.get() + future2.get());} catch (ExecutionException | InterruptedException e) {response.fail(e);}
}String fetchURL(URL url) throws IOException {try (var in = url.openStream()) {return new String(in.readAllBytes(), StandardCharsets.UTF_8);}
}以上代码, 聚合了另外两个服务的结果,可以看到虚拟线程不需要池,随时创建即可。
5.2 如何改造当前的线程池?
- 直接用虚拟线程代替线程池,如果代码中使用CompletableFuture,则直接将异步执行任务线程池替换为:Executors.newVirtualThreadPerTaskExecutor().
- 虚拟线程非常轻量化,不需要创建池,直接创建虚拟线程即可;
- synchronized更改为ReentrantLock减少固定到平台线程的虚拟线程;
- 虚拟线程中ThreadLocal使用方式和平台线程一致,但创建了大量的虚拟线程,每个虚拟线程中均有ThreadLocal实例及其引用的数据,则会对内存带来很大的负担。