Hadoop复习回顾

文章目录
1. Hadoop 常见面试题
1.1 常用端口号
hadoop 2.x
HDFS NameNode内部常用端口:8020/9000
HDFS NameNode对外查询端口: 50070
YARN 查看任务运行情况: 8088
历史服务器:19888
hadoop 3.x
HDFS NameNode内部常用端口:8020/9000/9820
HDFS NameNode对外查询端口: 9870
YARN 查看任务运行情况: 8088
历史服务器:19888
1.2 常用的配置文件
2.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml slaves
3.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers
1.3 HDFS基础
-
HDFS文件块大小(面试重点)
block小公司128大公司256
磁盘读写速度寻址时间为传输时间的1%最佳状态 -
HDFS的Shell操作(开发重点)
2.1 小基础
1)启动Hadoop集群(方便后续的测试)
[hadoop@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[hadoop@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
2)-help:输出这个命令参数
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -help rm
3)创建/sanguo文件夹
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /sanguo
4)-moveFromLocal:从本地剪切粘贴到HDFS
[hadoop@hadoop102 hadoop-3.1.3]$ vim shuguo.txt
输入:
shuguo
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
5)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[hadoop@hadoop102 hadoop-3.1.3]$ vim weiguo.txt
输入:
weiguo
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
6)-put:等同于copyFromLocal,生产环境更习惯用put
[hadoop@hadoop102 hadoop-3.1.3]$ vim wuguo.txt
输入:
wuguo
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
7)-appendToFile:追加一个文件到已经存在的文件末尾
[hadoop@hadoop102 hadoop-3.1.3]$ vim liubei.txt
输入:
liubei
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
2.2 下载
1)-copyToLocal:从HDFS拷贝到本地
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
2)-get:等同于copyToLocal,生产环境更习惯用get
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
2.3 HDFS直接操作
1)-ls: 显示目录信息
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
2)-cat:显示文件内容
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
3)-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -chown hadoop:hadoop /sanguo/shuguo.txt
4)-mkdir:创建路径
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:在HDFS目录中移动文件
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7)-tail:显示一个文件的末尾1kb的数据
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8)-rm:删除文件或文件夹
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:递归删除目录及目录里面内容
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-du统计文件夹的大小信息
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
说明:27表示文件大小;81表示27*3个副本;/jinguo表示查看的目录
11)-setrep:设置HDFS中文件的副本数量
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt
- HDFS的读写流程(面试重点)
2. HDFS写数据流程
2.1 剖析文件写入
HDFS的写数据流程
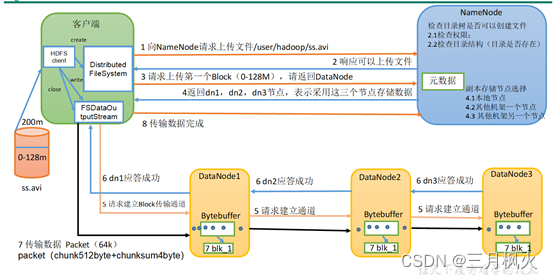
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
2.2 网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode选会择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
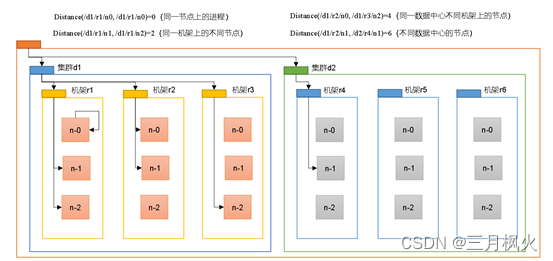
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
大家算一算每两个节点之间的距离。

3. 非大规模定义类内容
3.1 相关术语介绍
HDFS只是分布式文件管理系统中的一种
Hadoop Distributed File System,简称HDFS,是分布式文件系统
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
HDFS :NameNode dataNode 2NN
YARN负责资源管理:ResourceManager、NodeManager
MapReduce:container mapTask
3.2 重要目录
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
3.3 三种模式:
本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
完全分布式模式:多台服务器组成分布式环境。生产环境使用
4. HDFS的API案例实操
4.1 HDFS文件上传(测试参数优先级)
1)编写源代码
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {// 1 获取文件系统Configuration configuration = new Configuration();configuration.set("dfs.replication", "2");FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "hadoop");// 2 上传文件fs.copyFromLocalFile(new Path("d:/sunwukong.txt"), new Path("/xiyou/huaguoshan"));// 3 关闭资源fs.close();
}
2)将hdfs-site.xml拷贝到项目的resources资源目录下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
3)参数优先级
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的自定义配置(xxx-site.xml) >(4)服务器的默认配置(xxx-default.xml)
4.2 HDFS文件下载
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "hadoop");// 2 执行下载操作// boolean delSrc 指是否将原文件删除// Path src 指要下载的文件路径// Path dst 指将文件下载到的路径// boolean useRawLocalFileSystem 是否开启文件校验fs.copyToLocalFile(false, new Path("/xiyou/huaguoshan/sunwukong.txt"), new Path("d:/sunwukong2.txt"), true);// 3 关闭资源 fs.close();
}
注意:如果执行上面代码,下载不了文件,有可能是你电脑的微软支持的运行库少,需要安装一下微软运行库。
4.3 HDFS文件更名和移动
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "hadoop"); // 2 修改文件名称fs.rename(new Path("/xiyou/huaguoshan/sunwukong.txt"), new Path("/xiyou/huaguoshan/meihouwang.txt"));// 3 关闭资源fs.close();
}
4.4 HDFS删除文件和目录
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "hadoop");// 2 执行删除fs.delete(new Path("/xiyou"), true);// 3 关闭资源fs.close();
}
4.5 HDFS文件详情查看
查看文件名称、权限、长度、块信息
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException {// 1获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "hadoop");// 2 获取文件详情RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);while (listFiles.hasNext()) {LocatedFileStatus fileStatus = listFiles.next();System.out.println("========" + fileStatus.getPath() + "=========");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getGroup());System.out.println(fileStatus.getLen());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockSize());System.out.println(fileStatus.getPath().getName());// 获取块信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println(Arrays.toString(blockLocations));}// 3 关闭资源fs.close();
}
4.6 HDFS文件和文件夹判断
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件配置信息Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "hadoop");// 2 判断是文件还是文件夹FileStatus[] listStatus = fs.listStatus(new Path("/"));for (FileStatus fileStatus : listStatus) {// 如果是文件if (fileStatus.isFile()) {System.out.println("f:"+fileStatus.getPath().getName());}else {System.out.println("d:"+fileStatus.getPath().getName());}}// 3 关闭资源fs.close();
}4.7 wordcount 源码和序列化
4.7.1 Wordcount源码
(1)编写Mapper类
package com.igeek.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1 获取一行String line = value.toString();// 2 切割String[] words = line.split(" ");// 3 输出for (String word : words) {k.set(word);context.write(k, v);}}
}
(2)编写Reducer类
package com.igeek.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{int sum;
IntWritable v = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {// 1 累加求和sum = 0;for (IntWritable count : values) {sum += count.get();}// 2 输出v.set(sum);context.write(key,v);}
}
(3)编写Driver驱动类
package com.igeek.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取配置信息以及获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 关联本Driver程序的jarjob.setJarByClass(WordCountDriver.class);// 3 关联Mapper和Reducer的jarjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4 设置Mapper输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
(4)启动Hadoop集群
[hadoop@hadoop102 hadoop-3.1.3]sbin/start-dfs.sh
[hadoop@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(5)执行WordCount程序
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar com.igeek.mapreduce.wordcount.WordCountDriver /user/hadoop/input /user/hadoop/output
4.7.2 序列化部分
(1)编写流量统计的Bean对象
package com.igeek.mapreduce.writable;import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;//1 继承Writable接口
public class FlowBean implements Writable {private long upFlow; //上行流量private long downFlow; //下行流量private long sumFlow; //总流量//2 提供无参构造public FlowBean() {}//3 提供三个参数的getter和setter方法public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}public void setSumFlow() {this.sumFlow = this.upFlow + this.downFlow;}//4 实现序列化和反序列化方法,注意顺序一定要保持一致@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(upFlow);dataOutput.writeLong(downFlow);dataOutput.writeLong(sumFlow);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.upFlow = dataInput.readLong();this.downFlow = dataInput.readLong();this.sumFlow = dataInput.readLong();}//5 重写ToString@Overridepublic String toString() {return upFlow + "\\t" + downFlow + "\\t" + sumFlow;}
}
(2)编写Mapper类
package com.igeek.mapreduce.writable;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {private Text outK = new Text();private FlowBean outV = new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1 获取一行数据,转成字符串String line = value.toString();//2 切割数据String[] split = line.split("\\t");//3 抓取我们需要的数据:手机号,上行流量,下行流量String phone = split[1];String up = split[split.length - 3];String down = split[split.length - 2];//4 封装outK outV outK.set(phone);outV.setUpFlow(Long.parseLong(up));outV.setDownFlow(Long.parseLong(down));outV.setSumFlow();//5 写出outK outVcontext.write(outK, outV);}
}
(3)编写Reducer类
package com.igeek.mapreduce.writable;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {private FlowBean outV = new FlowBean();@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {long totalUp = 0;long totalDown = 0;//1 遍历values,将其中的上行流量,下行流量分别累加for (FlowBean flowBean : values) {totalUp += flowBean.getUpFlow();totalDown += flowBean.getDownFlow();}//2 封装outKVoutV.setUpFlow(totalUp);outV.setDownFlow(totalDown);outV.setSumFlow();//3 写出outK outVcontext.write(key,outV);}
}
(4)编写Driver驱动类
package com.igeek.mapreduce.writable;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//1 获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);//2 关联本Driver类job.setJarByClass(FlowDriver.class);//3 关联Mapper和Reducerjob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);//4 设置Map端输出KV类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);//5 设置程序最终输出的KV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);//6 设置程序的输入输出路径FileInputFormat.setInputPaths(job, new Path("D:\\\\inputflow"));FileOutputFormat.setOutputPath(job, new Path("D:\\\\flowoutput"));//7 提交Jobboolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}
}