Kubernetes调度器源码学习(三):Preempt抢占机制、调度失败与重试处理

本文基于Kubernetes v1.22.4版本进行源码学习
5、Preempt抢占机制
当高优先级的Pod没有找到合适的节点时,调度器会尝试抢占低优先级的Pod的节点。抢占过程是将低优先级的Pod从所在的节点上驱逐走,再让高优先级的Pod运行在该节点上,被驱逐走的低优先级的Pod会重新进入调度队列并等待再次选择合适的节点
1)、调度失败尝试进行抢占
scheduleOne()方法中如果调度失败,就会尝试进行抢占,代码如下:
// pkg/scheduler/scheduler.go
func (sched *Scheduler) scheduleOne(ctx context.Context) {
...// 真正执行调度的地方scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, sched.Extenders, fwk, state, pod)if err != nil {// Schedule() may have failed because the pod would not fit on any host, so we try to// preempt, with the expectation that the next time the pod is tried for scheduling it// will fit due to the preemption. It is also possible that a different pod will schedule// into the resources that were preempted, but this is harmless.// 调度失败后,尝试进行抢占nominatedNode := ""if fitError, ok := err.(*framework.FitError); ok {if !fwk.HasPostFilterPlugins() {klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed")} else {// Run PostFilter plugins to try to make the pod schedulable in a future scheduling cycle.result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)if status.Code() == framework.Error {klog.ErrorS(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)} else {klog.V(5).InfoS("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)}// 抢占成功后,将nominatedNodeName设置为被抢占的node,然后重新进入下一个调度周期if status.IsSuccess() && result != nil {nominatedNode = result.NominatedNodeName}}// Pod did not fit anywhere, so it is counted as a failure. If preemption// succeeds, the pod should get counted as a success the next time we try to// schedule it. (hopefully)metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))} else if err == ErrNoNodesAvailable {// No nodes available is counted as unschedulable rather than an error.metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))} else {klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod))metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))}// recordSchedulingFailure记录pod调度失败的事件,并将调度失败的pod加入到不可调度的pod的队列中去sched.recordSchedulingFailure(fwk, podInfo, err, v1.PodReasonUnschedulable, nominatedNode)return}
...
scheduleOne()方法中调用fwk.RunPostFilterPlugins()方法执行具体的抢占逻辑,然后返回被抢占的Node节点。抢占者并不会立刻被调度到被抢占的Node上,调度器只会将抢占者的status.nominatedNodeName字段设置为被抢占的Node的名称,当然即使在下一个调度周期,调度器也不会保证抢占者一定会运行在被抢占的节点上
这样设计的一个重要原因就是调度器只会通过标准的DELETE API来删除被抢占的Pod,所以,这些Pod必然有一定的优雅退出时间(默认是30秒)。而在这段时间里,其他的节点也是有可能变成可调度的,或者有新的节点被添加到这个集群中来
而在抢占者等待被调度的过程中,如果有其他更高优先级的Pod也要抢占同一个节点,那么调度器就会清空原抢占者的status.nominatedNodeName字段,从而允许更高优先级的抢占者执行抢占,这也使得原抢占者也有机会去重新抢占其他节点
fwk.RunPostFilterPlugins()方法会遍历所有的PostFilter插件,然后调用插件的PostFilter方法
// pkg/scheduler/framework/runtime/framework.go
func (f *frameworkImpl) RunPostFilterPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, filteredNodeStatusMap framework.NodeToStatusMap) (_ *framework.PostFilterResult, status *framework.Status) {startTime := time.Now()defer func() {metrics.FrameworkExtensionPointDuration.WithLabelValues(postFilter, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime))}()statuses := make(framework.PluginToStatus)for _, pl := range f.postFilterPlugins {// 调用postFilter插件的PostFilter方法r, s := f.runPostFilterPlugin(ctx, pl, state, pod, filteredNodeStatusMap)if s.IsSuccess() {return r, s} else if !s.IsUnschedulable() {// Any status other than Success or Unschedulable is Error.return nil, framework.AsStatus(s.AsError())}statuses[pl.Name()] = s}return nil, statuses.Merge()
}
PostFilter插件只有一个DefaultPreemption来执行抢占逻辑
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func (pl *DefaultPreemption) PostFilter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, m framework.NodeToStatusMap) (*framework.PostFilterResult, *framework.Status) {defer func() {metrics.PreemptionAttempts.Inc()}()// 执行抢占nnn, status := pl.preempt(ctx, state, pod, m)if !status.IsSuccess() {return nil, status}// This happens when the pod is not eligible for preemption or extenders filtered all candidates.if nnn == "" {return nil, framework.NewStatus(framework.Unschedulable)}return &framework.PostFilterResult{NominatedNodeName: nnn}, framework.NewStatus(framework.Success)
}
2)、抢占逻辑
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func (pl *DefaultPreemption) preempt(ctx context.Context, state *framework.CycleState, pod *v1.Pod, m framework.NodeToStatusMap) (string, *framework.Status) {cs := pl.fh.ClientSet()// 获取node列表nodeLister := pl.fh.SnapshotSharedLister().NodeInfos()// 0) Fetch the latest version of <pod>.// It's safe to directly fetch pod here. Because the informer cache has already been// initialized when creating the Scheduler obj, i.e., factory.go#MakeDefaultErrorFunc().// However, tests may need to manually initialize the shared pod informer.podNamespace, podName := pod.Namespace, pod.Namepod, err := pl.podLister.Pods(pod.Namespace).Get(pod.Name)if err != nil {klog.ErrorS(err, "getting the updated preemptor pod object", "pod", klog.KRef(podNamespace, podName))return "", framework.AsStatus(err)}// 1) Ensure the preemptor is eligible to preempt other pods.// 1)确认抢占者是否能够进行抢占if !PodEligibleToPreemptOthers(pod, nodeLister, m[pod.Status.NominatedNodeName]) {klog.V(5).InfoS("Pod is not eligible for more preemption", "pod", klog.KObj(pod))return "", nil}// 2) Find all preemption candidates.// 2)查找所有抢占候选者candidates, nodeToStatusMap, status := pl.FindCandidates(ctx, state, pod, m)if !status.IsSuccess() {return "", status}// Return a FitError only when there are no candidates that fit the pod.if len(candidates) == 0 {fitError := &framework.FitError{Pod: pod,NumAllNodes: len(nodeToStatusMap),Diagnosis: framework.Diagnosis{NodeToStatusMap: nodeToStatusMap,// Leave FailedPlugins as nil as it won't be used on moving Pods.},}return "", framework.NewStatus(framework.Unschedulable, fitError.Error())}// 3) Interact with registered Extenders to filter out some candidates if needed.// 3)如果有extender则执行candidates, status = CallExtenders(pl.fh.Extenders(), pod, nodeLister, candidates)if !status.IsSuccess() {return "", status}// 4) Find the best candidate.// 4)查找最佳抢占候选者bestCandidate := SelectCandidate(candidates)if bestCandidate == nil || len(bestCandidate.Name()) == 0 {return "", nil}// 5) Perform preparation work before nominating the selected candidate.// 5)在抢占之前做一些准备工作if status := PrepareCandidate(bestCandidate, pl.fh, cs, pod, pl.Name()); !status.IsSuccess() {return "", status}return bestCandidate.Name(), nil
}
preempt()方法首先会获取Node列表,然后获取最新的要执行抢占的Pod信息,接着分下面几步执行抢占:
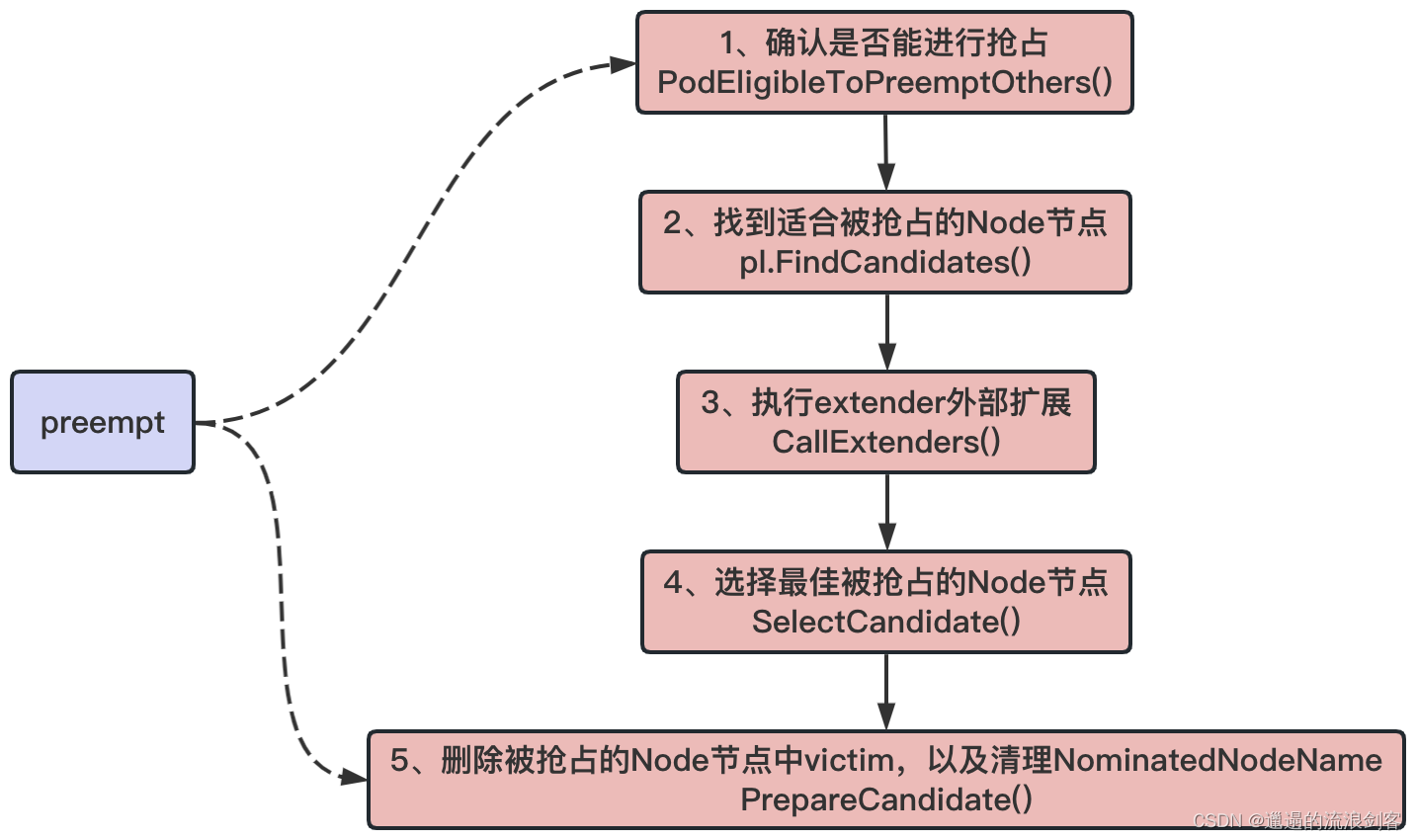
- 调用
PodEligibleToPreemptOthers()方法,检查抢占者是否能够进行抢占,如果当前的Pod已经抢占了一个Node节点或者在被抢占Node节点中有Pod正在执行优雅退出,那么不应该执行抢占 - 调用
FindCandidates()方法找到所有Node中能被抢占的Node节点,并返回候选列表以及Node节点中需要被删除的Pod - 若有extender则执行
- 调用
SelectCandidate()方法在所有候选列表中找出最合适的Node节点进行抢占 - 调用
PrepareCandidate()方法删除被抢占的Node节点中victim(牺牲者),以及清理NominatedNodeName字段信息
3)、确认是否能进行抢占
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func PodEligibleToPreemptOthers(pod *v1.Pod, nodeInfos framework.NodeInfoLister, nominatedNodeStatus *framework.Status) bool {if pod.Spec.PreemptionPolicy != nil && *pod.Spec.PreemptionPolicy == v1.PreemptNever {klog.V(5).InfoS("Pod is not eligible for preemption because it has a preemptionPolicy of Never", "pod", klog.KObj(pod))return false}// 查看抢占者是否已经抢占过nomNodeName := pod.Status.NominatedNodeNameif len(nomNodeName) > 0 {// If the pod's nominated node is considered as UnschedulableAndUnresolvable by the filters,// then the pod should be considered for preempting again.if nominatedNodeStatus.Code() == framework.UnschedulableAndUnresolvable {return true}// 获取被抢占的node节点if nodeInfo, _ := nodeInfos.Get(nomNodeName); nodeInfo != nil {// 查看是否存在正在被删除并且优先级比抢占者pod低的podpodPriority := corev1helpers.PodPriority(pod)for _, p := range nodeInfo.Pods {if p.Pod.DeletionTimestamp != nil && corev1helpers.PodPriority(p.Pod) < podPriority {// There is a terminating pod on the nominated node.return false}}}}return true
}
PodEligibleToPreemptOthers()方法会检查该Pod是否已经抢占过其他Node节点,如果是的话就遍历节点上的所有Pod,如果发现节点上有Pod的优先级小于该Pod并处于终止状态,则返回false,不会发生抢占
4)、找到适合被抢占的Node节点
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func (pl *DefaultPreemption) FindCandidates(ctx context.Context, state *framework.CycleState, pod *v1.Pod, m framework.NodeToStatusMap) ([]Candidate, framework.NodeToStatusMap, *framework.Status) {allNodes, err := pl.fh.SnapshotSharedLister().NodeInfos().List()if err != nil {return nil, nil, framework.AsStatus(err)}if len(allNodes) == 0 {return nil, nil, framework.NewStatus(framework.Error, "no nodes available")}// 找到predicates阶段失败但是通过抢占也许能够成功调度的nodepotentialNodes, unschedulableNodeStatus := nodesWherePreemptionMightHelp(allNodes, m)if len(potentialNodes) == 0 {klog.V(3).InfoS("Preemption will not help schedule pod on any node", "pod", klog.KObj(pod))// In this case, we should clean-up any existing nominated node name of the pod.if err := util.ClearNominatedNodeName(pl.fh.ClientSet(), pod); err != nil {klog.ErrorS(err, "cannot clear 'NominatedNodeName' field of pod", "pod", klog.KObj(pod))// We do not return as this error is not critical.}return nil, unschedulableNodeStatus, nil}// 获取pdb对象,pdb能够限制同时终止pod的数量,以保证集群的高可用性pdbs, err := getPodDisruptionBudgets(pl.pdbLister)if err != nil {return nil, nil, framework.AsStatus(err)}offset, numCandidates := pl.getOffsetAndNumCandidates(int32(len(potentialNodes)))if klog.V(5).Enabled() {var sample []stringfor i := offset; i < offset+10 && i < int32(len(potentialNodes)); i++ {sample = append(sample, potentialNodes[i].Node().Name)}klog.Infof("from a pool of %d nodes (offset: %d, sample %d nodes: %v), ~%d candidates will be chosen", len(potentialNodes), offset, len(sample), sample, numCandidates)}// 找到适合被抢占的node节点,并封装成candidates数组返回candidates, nodeStatuses := dryRunPreemption(ctx, pl.fh, state, pod, potentialNodes, pdbs, offset, numCandidates)for node, status := range unschedulableNodeStatus {nodeStatuses[node] = status}return candidates, nodeStatuses, nil
}
FindCandidates()方法首先会获取Node列表,然后调用nodesWherePreemptionMightHelp()方法找出Predicates(预选)阶段失败但是通过抢占也许能够调度成功的Node列表,最后调用dryRunPreemption()方法来找到适合被抢占的Node节点
dryRunPreemption()方法代码如下:
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func dryRunPreemption(ctx context.Context, fh framework.Handle,state *framework.CycleState, pod *v1.Pod, potentialNodes []*framework.NodeInfo,pdbs []*policy.PodDisruptionBudget, offset int32, numCandidates int32) ([]Candidate, framework.NodeToStatusMap) {nonViolatingCandidates := newCandidateList(numCandidates)violatingCandidates := newCandidateList(numCandidates)parallelCtx, cancel := context.WithCancel(ctx)nodeStatuses := make(framework.NodeToStatusMap)var statusesLock sync.MutexcheckNode := func(i int) {nodeInfoCopy := potentialNodes[(int(offset)+i)%len(potentialNodes)].Clone()stateCopy := state.Clone()// 找到node上被抢占的pod,也就是victimspods, numPDBViolations, status := selectVictimsOnNode(ctx, fh, stateCopy, pod, nodeInfoCopy, pdbs)if status.IsSuccess() && len(pods) != 0 {victims := extenderv1.Victims{Pods: pods,NumPDBViolations: int64(numPDBViolations),}c := &candidate{victims: &victims,name: nodeInfoCopy.Node().Name,}if numPDBViolations == 0 {nonViolatingCandidates.add(c)} else {violatingCandidates.add(c)}nvcSize, vcSize := nonViolatingCandidates.size(), violatingCandidates.size()if nvcSize > 0 && nvcSize+vcSize >= numCandidates {cancel()}return}if status.IsSuccess() && len(pods) == 0 {status = framework.AsStatus(fmt.Errorf("expected at least one victim pod on node %q", nodeInfoCopy.Node().Name))}statusesLock.Lock()nodeStatuses[nodeInfoCopy.Node().Name] = statusstatusesLock.Unlock()}fh.Parallelizer().Until(parallelCtx, len(potentialNodes), checkNode)return append(nonViolatingCandidates.get(), violatingCandidates.get()...), nodeStatuses
}
dryRunPreemption()方法中会默认开启16个goroutine并行调用checkNode()方法,checkNode()方法中会调用selectVictimsOnNode()方法来检查这个Node是不是能被执行抢占,如果能抢占返回的pods表示被抢占的Pod,然后封装成candidate添加到candidates列表中返回
selectVictimsOnNode()方法代码如下:
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func selectVictimsOnNode(ctx context.Context,fh framework.Handle,state *framework.CycleState,pod *v1.Pod,nodeInfo *framework.NodeInfo,pdbs []*policy.PodDisruptionBudget,
) ([]*v1.Pod, int, *framework.Status) {var potentialVictims []*framework.PodInfo// 移除node节点的podremovePod := func(rpi *framework.PodInfo) error {if err := nodeInfo.RemovePod(rpi.Pod); err != nil {return err}status := fh.RunPreFilterExtensionRemovePod(ctx, state, pod, rpi, nodeInfo)if !status.IsSuccess() {return status.AsError()}return nil}// 将node节点添加podaddPod := func(api *framework.PodInfo) error {nodeInfo.AddPodInfo(api)status := fh.RunPreFilterExtensionAddPod(ctx, state, pod, api, nodeInfo)if !status.IsSuccess() {return status.AsError()}return nil}// As the first step, remove all the lower priority pods from the node and// check if the given pod can be scheduled.// 获取pod的优先级,并将node中所有优先级低于该pod的调用removePod方法移除podPriority := corev1helpers.PodPriority(pod)for _, pi := range nodeInfo.Pods {if corev1helpers.PodPriority(pi.Pod) < podPriority {potentialVictims = append(potentialVictims, pi)if err := removePod(pi); err != nil {return nil, 0, framework.AsStatus(err)}}}// No potential victims are found, and so we don't need to evaluate the node again since its state didn't change.// 没有优先级低的pod,直接返回if len(potentialVictims) == 0 {message := fmt.Sprintf("No victims found on node %v for preemptor pod %v", nodeInfo.Node().Name, pod.Name)return nil, 0, framework.NewStatus(framework.UnschedulableAndUnresolvable, message)}// If the new pod does not fit after removing all the lower priority pods,// we are almost done and this node is not suitable for preemption. The only// condition that we could check is if the "pod" is failing to schedule due to// inter-pod affinity to one or more victims, but we have decided not to// support this case for performance reasons. Having affinity to lower// priority pods is not a recommended configuration anyway.// 检查抢占pod是否符合在node节点上运行,如果移除所有低优先级的pod之后抢占pod都无法在node节点上运行,那么就认为不适合抢占该node节点if status := fh.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo); !status.IsSuccess() {return nil, 0, status}var victims []*v1.PodnumViolatingVictim := 0// 将potentialVictims集合里的pod按照优先级进行排序sort.Slice(potentialVictims, func(i, j int) bool { return util.MoreImportantPod(potentialVictims[i].Pod, potentialVictims[j].Pod) })// Try to reprieve as many pods as possible. We first try to reprieve the PDB// violating victims and then other non-violating ones. In both cases, we start// from the highest priority victims.// 将potentialVictims集合里的pod基于pod是否有pdb被分为两组violatingVictims, nonViolatingVictims := filterPodsWithPDBViolation(potentialVictims, pdbs)reprievePod := func(pi *framework.PodInfo) (bool, error) {// 先将删除的pod添加回来if err := addPod(pi); err != nil {return false, err}// 判断添加完之后是否还符合抢占pod的调度status := fh.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)fits := status.IsSuccess()if !fits {// 不符合就再删除podif err := removePod(pi); err != nil {return false, err}rpi := pi.Pod// 并将这个需要删除的pod添加到victims(最终需要删除的pod列表中)victims = append(victims, rpi)klog.V(5).InfoS("Pod is a potential preemption victim on node", "pod", klog.KObj(rpi), "node", klog.KObj(nodeInfo.Node()))}return fits, nil}// 依次调用reprievePod方法尽可能多的让低优先级Pod不被移除for _, p := range violatingVictims {if fits, err := reprievePod(p); err != nil {return nil, 0, framework.AsStatus(err)} else if !fits {numViolatingVictim++}}// Now we try to reprieve non-violating victims.for _, p := range nonViolatingVictims {if _, err := reprievePod(p); err != nil {return nil, 0, framework.AsStatus(err)}}return victims, numViolatingVictim, framework.NewStatus(framework.Success)
}
selectVictimsOnNode()方法逻辑如下:
- 首先定义了两个函数:removePod和addPod,这两个函数都差不多,removePod会把Pod从Node中移除,然后修改Node的属性,如将
Requested.MilliCPU、Requested.Memory中减去,表示已用资源大小,将该Pod从Node节点的Pods列表中移除等等 - 遍历找出Node中所有优先级小于抢占Pod的Pod,调用
removePod()方法将其从Node中移除,加入potentialVictims集合中 - 调用
fh.RunFilterPluginsWithNominatedPods()检查抢占Pod是否符合在Node节点上运行,这个就是调度的预选算法中调用的函数,同样会执行两遍,检查加上NominatedPods是否满足,再将NominatedPods移除检查是否满足。如果移除所有低优先级的Pod之后抢占Pod都无法在Node节点上运行,那么就认为不适合抢占该Node节点 - 将potentialVictims集合里的Pod按照优先级进行排序,排序算法为先看Pod的优先级,然后看Pod的启动时间,启动越早优先级越高
- 通过
filterPodsWithPDBViolation()方法计算删除的Pod是否满足PDB的要求,将potentialVictims分为violatingVictims和nonViolatingVictims - 根据上面选出来的violatingVictims和nonViolatingVictims,通过
reprievePod()方法尽可能多的让低优先级Pod不被移除。reprievePod()函数先将删除的Pod添加回来,判断添加完之后是否还符合抢占Pod的调度,如果不符合再删除该Pod,并将这个需要删除的Pod添加到victims列表中
5)、选择最佳被抢占的Node节点
SelectCandidate()方法代码如下:
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func SelectCandidate(candidates []Candidate) Candidate {if len(candidates) == 0 {return nil}if len(candidates) == 1 {return candidates[0]}victimsMap := candidatesToVictimsMap(candidates)// 选择最佳被抢占的node节点candidateNode := pickOneNodeForPreemption(victimsMap)// Same as candidatesToVictimsMap, this logic is not applicable for out-of-tree// preemption plugins that exercise different candidates on the same nominated node.if victims := victimsMap[candidateNode]; victims != nil {return &candidate{victims: victims,name: candidateNode,}}// We shouldn't reach here.klog.ErrorS(errors.New("no candidate selected"), "should not reach here", "candidates", candidates)// To not break the whole flow, return the first candidate.return candidates[0]
}
SelectCandidate()方法中调用pickOneNodeForPreemption()方法选择最佳被抢占的Node节点
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func pickOneNodeForPreemption(nodesToVictims map[string]*extenderv1.Victims) string {if len(nodesToVictims) == 0 {return ""}// 1)取被驱逐的pod违反pdb最少的节点minNumPDBViolatingPods := int64(math.MaxInt32)var minNodes1 []stringlenNodes1 := 0for node, victims := range nodesToVictims {numPDBViolatingPods := victims.NumPDBViolationsif numPDBViolatingPods < minNumPDBViolatingPods {minNumPDBViolatingPods = numPDBViolatingPodsminNodes1 = nillenNodes1 = 0}if numPDBViolatingPods == minNumPDBViolatingPods {minNodes1 = append(minNodes1, node)lenNodes1++}}if lenNodes1 == 1 {return minNodes1[0]}// There are more than one node with minimum number PDB violating pods. Find// the one with minimum highest priority victim.// 2)如果存在多个节点,取被驱逐的pod最高优先级最小的节点minHighestPriority := int32(math.MaxInt32)var minNodes2 = make([]string, lenNodes1)lenNodes2 := 0for i := 0; i < lenNodes1; i++ {node := minNodes1[i]victims := nodesToVictims[node]// highestPodPriority is the highest priority among the victims on this node.highestPodPriority := corev1helpers.PodPriority(victims.Pods[0])if highestPodPriority < minHighestPriority {minHighestPriority = highestPodPrioritylenNodes2 = 0}if highestPodPriority == minHighestPriority {minNodes2[lenNodes2] = nodelenNodes2++}}if lenNodes2 == 1 {return minNodes2[0]}// There are a few nodes with minimum highest priority victim. Find the// smallest sum of priorities.// 3)如果存在多个节点,取被驱逐的pod优先级之和最小的节点minSumPriorities := int64(math.MaxInt64)lenNodes1 = 0for i := 0; i < lenNodes2; i++ {var sumPriorities int64node := minNodes2[i]for _, pod := range nodesToVictims[node].Pods {// We add MaxInt32+1 to all priorities to make all of them >= 0. This is// needed so that a node with a few pods with negative priority is not// picked over a node with a smaller number of pods with the same negative// priority (and similar scenarios).sumPriorities += int64(corev1helpers.PodPriority(pod)) + int64(math.MaxInt32+1)}if sumPriorities < minSumPriorities {minSumPriorities = sumPrioritieslenNodes1 = 0}if sumPriorities == minSumPriorities {minNodes1[lenNodes1] = nodelenNodes1++}}if lenNodes1 == 1 {return minNodes1[0]}// There are a few nodes with minimum highest priority victim and sum of priorities.// Find one with the minimum number of pods.// 4)如果存在多个节点,取被驱逐的pod数量最小的节点minNumPods := math.MaxInt32lenNodes2 = 0for i := 0; i < lenNodes1; i++ {node := minNodes1[i]numPods := len(nodesToVictims[node].Pods)if numPods < minNumPods {minNumPods = numPodslenNodes2 = 0}if numPods == minNumPods {minNodes2[lenNodes2] = nodelenNodes2++}}if lenNodes2 == 1 {return minNodes2[0]}// There are a few nodes with same number of pods.// Find the node that satisfies latest(earliestStartTime(all highest-priority pods on node))// 5)如果存在多个节点,取被驱逐的pod中创建时间最近的节点latestStartTime := util.GetEarliestPodStartTime(nodesToVictims[minNodes2[0]])if latestStartTime == nil {// If the earliest start time of all pods on the 1st node is nil, just return it,// which is not expected to happen.klog.ErrorS(errors.New("earliestStartTime is nil for node"), "should not reach here", "node", minNodes2[0])return minNodes2[0]}nodeToReturn := minNodes2[0]for i := 1; i < lenNodes2; i++ {node := minNodes2[i]// Get earliest start time of all pods on the current node.earliestStartTimeOnNode := util.GetEarliestPodStartTime(nodesToVictims[node])if earliestStartTimeOnNode == nil {klog.ErrorS(errors.New("earliestStartTime is nil for node"), "should not reach here", "node", node)continue}if earliestStartTimeOnNode.After(latestStartTime.Time) {latestStartTime = earliestStartTimeOnNodenodeToReturn = node}}return nodeToReturn
}
pickOneNodeForPreemption()方法根据以下标准选择一个节点作为最终被抢占的节点:
- 取被驱逐的Pod违反PDB最少的节点
- 如果上一步选择完存在多个节点,取被驱逐的Pod最高优先级最小的节点
- 如果上一步选择完存在多个节点,取被驱逐的Pod优先级之和最小的节点
- 如果上一步选择完存在多个节点,取被驱逐的Pod数量最小的节点
- 如果上一步选择完存在多个节点,取被驱逐的Pod中创建时间最近的节点
- 如果上一步选择完存在多个节点,取第一个节点
6)、抢占之前的准备工作
PrepareCandidate()方法代码如下:
// pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go
func PrepareCandidate(c Candidate, fh framework.Handle, cs kubernetes.Interface, pod *v1.Pod, pluginName string) *framework.Status {// 调用DeletePod删除victims列表里面的podfor _, victim := range c.Victims().Pods {// If the victim is a WaitingPod, send a reject message to the PermitPlugin.// Otherwise we should delete the victim.if waitingPod := fh.GetWaitingPod(victim.UID); waitingPod != nil {waitingPod.Reject(pluginName, "preempted")} else if err := util.DeletePod(cs, victim); err != nil {klog.ErrorS(err, "Preempting pod", "pod", klog.KObj(victim), "preemptor", klog.KObj(pod))return framework.AsStatus(err)}fh.EventRecorder().Eventf(victim, pod, v1.EventTypeNormal, "Preempted", "Preempting", "Preempted by %v/%v on node %v",pod.Namespace, pod.Name, c.Name())}metrics.PreemptionVictims.Observe(float64(len(c.Victims().Pods)))// Lower priority pods nominated to run on this node, may no longer fit on// this node. So, we should remove their nomination. Removing their// nomination updates these pods and moves them to the active queue. It// lets scheduler find another place for them.// 移除低优先级pod的nominatedNodeNamenominatedPods := getLowerPriorityNominatedPods(fh, pod, c.Name())if err := util.ClearNominatedNodeName(cs, nominatedPods...); err != nil {klog.ErrorS(err, "cannot clear 'NominatedNodeName' field")// We do not return as this error is not critical.}return nil
}
7)、小结

6、调度失败与重试处理
1)、podBackoffQ
backoff(回退)机制就是如果调度任务反复执行依旧失败,则会按此增加等待调度时间,降低重试的频率,从而避免反复失败浪费调度资源
podBackoffQ也是一个优先级队列,在Scheduler初始化优先级队列的时候会初始化podBackoffQ,其中最重要的是比较队列中元素优先级的函数podsCompareBackoffCompleted():
// pkg/scheduler/internal/queue/scheduling_queue.go
func NewPriorityQueue(lessFn framework.LessFunc,informerFactory informers.SharedInformerFactory,opts ...Option,
) *PriorityQueue {options := defaultPriorityQueueOptionsfor _, opt := range opts {opt(&options)}comp := func(podInfo1, podInfo2 interface{}) bool {pInfo1 := podInfo1.(*framework.QueuedPodInfo)pInfo2 := podInfo2.(*framework.QueuedPodInfo)return lessFn(pInfo1, pInfo2)}if options.podNominator == nil {options.podNominator = NewPodNominator(informerFactory.Core().V1().Pods().Lister())}pq := &PriorityQueue{PodNominator: options.podNominator,clock: options.clock,stop: make(chan struct{}),podInitialBackoffDuration: options.podInitialBackoffDuration,podMaxBackoffDuration: options.podMaxBackoffDuration,activeQ: heap.NewWithRecorder(podInfoKeyFunc, comp, metrics.NewActivePodsRecorder()),unschedulableQ: newUnschedulablePodsMap(metrics.NewUnschedulablePodsRecorder()),moveRequestCycle: -1,clusterEventMap: options.clusterEventMap,}pq.cond.L = &pq.lockpq.podBackoffQ = heap.NewWithRecorder(podInfoKeyFunc, pq.podsCompareBackoffCompleted, metrics.NewBackoffPodsRecorder())if utilfeature.DefaultFeatureGate.Enabled(features.PodAffinityNamespaceSelector) {pq.nsLister = informerFactory.Core().V1().Namespaces().Lister()}return pq
}// 比较podBackoffQ队列中元素的优先级,谁的回退时间短,谁的优先级高
func (p *PriorityQueue) podsCompareBackoffCompleted(podInfo1, podInfo2 interface{}) bool {pInfo1 := podInfo1.(*framework.QueuedPodInfo)pInfo2 := podInfo2.(*framework.QueuedPodInfo)bo1 := p.getBackoffTime(pInfo1)bo2 := p.getBackoffTime(pInfo2)return bo1.Before(bo2)
}// getBackoffTime返回podInfo完成回退的时间
func (p *PriorityQueue) getBackoffTime(podInfo *framework.QueuedPodInfo) time.Time {duration := p.calculateBackoffDuration(podInfo)backoffTime := podInfo.Timestamp.Add(duration)return backoffTime
}// calculateBackoffDuration是一个辅助函数,用于根据pod的尝试次数计算backoffDuration
func (p *PriorityQueue) calculateBackoffDuration(podInfo *framework.QueuedPodInfo) time.Duration {// initialBackoffDuration是1sduration := p.podInitialBackoffDuration// podAttempts里面包含pod的尝试失败的次数for i := 1; i < podInfo.Attempts; i++ {duration = duration * 2// 最大10sif duration > p.podMaxBackoffDuration {return p.podMaxBackoffDuration}}return duration
}
podBackoffQ队列元素中谁的回退时间(backoffTime)短,谁的优先级高,backoffTime=pod最新一次更新的时间+backoffDuration,而backoffDuration是根据Pod尝试失败的次数(podAttempts)来计算的,公式是2的N次幂,初始backoffDuration是1秒,最大是10秒
2)、unschedulableQ
unschedulableQ是不可调度队列,该队列中的Pod是已经被确定为不可调度的Pod,虽说是个队列,实际的数据结构是一个map类型,结构体定义如下:
// pkg/scheduler/internal/queue/scheduling_queue.go
// UnschedulablePodsMap持有无法调度的pod,此数据结构用于实现unschedulableQ
type UnschedulablePodsMap struct {// podInfoMap is a map key by a pod's full-name and the value is a pointer to the QueuedPodInfo.// podInfoMap的key为pod的全名(pod.Name_pod.Namespace),value为指向QueuedPodInfo的指针podInfoMap map[string]*framework.QueuedPodInfokeyFunc func(*v1.Pod) string// metricRecorder updates the counter when elements of an unschedulablePodsMap// get added or removed, and it does nothing if it's nilmetricRecorder metrics.MetricRecorder
}
3)、调度失败处理
scheduleOne()方法中当真正执行调度操作后,如果出现了错误,会调用recordSchedulingFailure()来记录Pod调度失败的事件,并将调度失败的Pod加入到不可调度的Pod的队列中去,代码如下:
// pkg/scheduler/scheduler.go
// recordSchedulingFailure为pod记录一个调度失败的事件
// 如果设置了pod condition和nominated提名节点名称,也要更新
// 这里最重要的是要将调度失败的pod加入到不可调度的pod的队列中去
func (sched *Scheduler) recordSchedulingFailure(fwk framework.Framework, podInfo *framework.QueuedPodInfo, err error, reason string, nominatedNode string) {sched.Error(podInfo, err)// Update the scheduling queue with the nominated pod information. Without// this, there would be a race condition between the next scheduling cycle// and the time the scheduler receives a Pod Update for the nominated pod.// Here we check for nil only for tests.if sched.SchedulingQueue != nil {sched.SchedulingQueue.AddNominatedPod(podInfo.PodInfo, nominatedNode)}pod := podInfo.Podmsg := truncateMessage(err.Error())fwk.EventRecorder().Eventf(pod, nil, v1.EventTypeWarning, "FailedScheduling", "Scheduling", msg)if err := updatePod(sched.client, pod, &v1.PodCondition{Type: v1.PodScheduled,Status: v1.ConditionFalse,Reason: reason,Message: err.Error(),}, nominatedNode); err != nil {klog.ErrorS(err, "Error updating pod", "pod", klog.KObj(pod))}
}
recordSchedulingFailure()方法中调用了sched.Error()回调函数,这个回调函数是在初始化调度器的时候传入的,会把当前调度失败的Pod加入到unschedulableQ或podBackoffQ中去:
// pkg/scheduler/factory.go
func MakeDefaultErrorFunc(client clientset.Interface, podLister corelisters.PodLister, podQueue internalqueue.SchedulingQueue, schedulerCache internalcache.Cache) func(*framework.QueuedPodInfo, error) {return func(podInfo *framework.QueuedPodInfo, err error) {pod := podInfo.Podif err == ErrNoNodesAvailable {klog.V(2).InfoS("Unable to schedule pod; no nodes are registered to the cluster; waiting", "pod", klog.KObj(pod))} else if fitError, ok := err.(*framework.FitError); ok {// Inject UnschedulablePlugins to PodInfo, which will be used later for moving Pods between queues efficiently.podInfo.UnschedulablePlugins = fitError.Diagnosis.UnschedulablePluginsklog.V(2).InfoS("Unable to schedule pod; no fit; waiting", "pod", klog.KObj(pod), "err", err)} else if apierrors.IsNotFound(err) {klog.V(2).InfoS("Unable to schedule pod, possibly due to node not found; waiting", "pod", klog.KObj(pod), "err", err)if errStatus, ok := err.(apierrors.APIStatus); ok && errStatus.Status().Details.Kind == "node" {nodeName := errStatus.Status().Details.Name// when node is not found, We do not remove the node right away. Trying again to get// the node and if the node is still not found, then remove it from the scheduler cache._, err := client.CoreV1().Nodes().Get(context.TODO(), nodeName, metav1.GetOptions{})if err != nil && apierrors.IsNotFound(err) {node := v1.Node{ObjectMeta: metav1.ObjectMeta{Name: nodeName}}if err := schedulerCache.RemoveNode(&node); err != nil {klog.V(4).InfoS("Node is not found; failed to remove it from the cache", "node", node.Name)}}}} else {klog.ErrorS(err, "Error scheduling pod; retrying", "pod", klog.KObj(pod))}// Check if the Pod exists in informer cache.cachedPod, err := podLister.Pods(pod.Namespace).Get(pod.Name)if err != nil {klog.InfoS("Pod doesn't exist in informer cache", "pod", klog.KObj(pod), "err", err)return}// In the case of extender, the pod may have been bound successfully, but timed out returning its response to the scheduler.// It could result in the live version to carry .spec.nodeName, and that's inconsistent with the internal-queued version.if len(cachedPod.Spec.NodeName) != 0 {klog.InfoS("Pod has been assigned to node. Abort adding it back to queue.", "pod", klog.KObj(pod), "node", cachedPod.Spec.NodeName)return}// As <cachedPod> is from SharedInformer, we need to do a DeepCopy() here.podInfo.PodInfo = framework.NewPodInfo(cachedPod.DeepCopy())// 把调度失败的pod加入到unschedulableQ或podBackoffQ中if err := podQueue.AddUnschedulableIfNotPresent(podInfo, podQueue.SchedulingCycle()); err != nil {klog.ErrorS(err, "Error occurred")}}
}
真正加入到队列是通过调用podQueue.AddUnschedulableIfNotPresent()方法来完成的:
// pkg/scheduler/internal/queue/scheduling_queue.go
// AddUnschedulableIfNotPresent将一个不可调用的pod添加到队列中
// 一般情况下会把不可调度的pod添加到unschedulableQ中,但如果最近有move request,则会将pod添加到podBackoffQ中
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pInfo *framework.QueuedPodInfo, podSchedulingCycle int64) error {p.lock.Lock()defer p.lock.Unlock()pod := pInfo.Podif p.unschedulableQ.get(pod) != nil {return fmt.Errorf("Pod %v is already present in unschedulable queue", klog.KObj(pod))}if _, exists, _ := p.activeQ.Get(pInfo); exists {return fmt.Errorf("Pod %v is already present in the active queue", klog.KObj(pod))}if _, exists, _ := p.podBackoffQ.Get(pInfo); exists {return fmt.Errorf("Pod %v is already present in the backoff queue", klog.KObj(pod))}// Refresh the timestamp since the pod is re-added.// 刷新pod被重新添加后的时间戳pInfo.Timestamp = p.clock.Now()// If a move request has been received, move it to the BackoffQ, otherwise move// it to unschedulableQ.// 如果收到move request,将其移动到podBackoffQ,否则将其移动到unschedulableQif p.moveRequestCycle >= podSchedulingCycle {if err := p.podBackoffQ.Add(pInfo); err != nil {return fmt.Errorf("error adding pod %v to the backoff queue: %v", pod.Name, err)}metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", ScheduleAttemptFailure).Inc()} else {p.unschedulableQ.addOrUpdate(pInfo)metrics.SchedulerQueueIncomingPods.WithLabelValues("unschedulable", ScheduleAttemptFailure).Inc()}p.PodNominator.AddNominatedPod(pInfo.PodInfo, "")return nil
}
在Pod调度失败时,会调用AddUnschedulableIfNotPresent()方法,其中有一个逻辑:
- 如果moveRequestCycle>=podSchedulingCycle,则对当前调度失败的Pod进行重试,也就是添加到podBackoffQ队列中
- 如果不满足,则添加到unschedulableQ不可调度队列中
对于moveRequestCycle这个属性只有集群资源发生过变更(在资源的事件监听处理器里面都会去设置moveRequestCycle=podSchedulingCycle)才会等于podSchedulingCycle。理论上来说,在Pod调度失败时,没有后续任何操作,会被添加到unschedulableQ不可调度队列中,但是有可能Pod刚刚调度失败,在错误处理之前,忽然发生了资源变更,这个时候,由于在这个错误处理的间隙,集群的资源状态已经发生了变化,所以可以认为这个Pod有了被调度成功的可能性,所以就被放进了podBackoffQ重试队列中,等待快速重试
4)、PriorityQueue子队列数据流转
PriorityQueue队列里面包含的3个子队列之间的数据是如何流转的呢?来看下调度启动的函数:
// pkg/scheduler/scheduler.go
func (sched *Scheduler) Run(ctx context.Context) {sched.SchedulingQueue.Run()wait.UntilWithContext(ctx, sched.scheduleOne, 0)sched.SchedulingQueue.Close()
}
其中调用了PriorityQueue的Run()方法:
func (p *PriorityQueue) Run() {go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)go wait.Until(p.flushUnschedulableQLeftover, 30*time.Second, p.stop)
}// flushBackoffQCompleted将podBackoffQ中已经完成了backoff的pod移动到activeQ
func (p *PriorityQueue) flushBackoffQCompleted() {p.lock.Lock()defer p.lock.Unlock()for {// 获取堆顶元素rawPodInfo := p.podBackoffQ.Peek()if rawPodInfo == nil {return}pod := rawPodInfo.(*framework.QueuedPodInfo).PodboTime := p.getBackoffTime(rawPodInfo.(*framework.QueuedPodInfo))// 如果该pod的backoffTime还没到,则忽略if boTime.After(p.clock.Now()) {return}// 将pod从podBackoffQ移动到activeQ_, err := p.podBackoffQ.Pop()if err != nil {klog.ErrorS(err, "Unable to pop pod from backoff queue despite backoff completion", "pod", klog.KObj(pod))return}p.activeQ.Add(rawPodInfo)metrics.SchedulerQueueIncomingPods.WithLabelValues("active", BackoffComplete).Inc()defer p.cond.Broadcast()}
}// flushUnschedulableQLeftover将在unschedulableQ中停留时间长于unschedulableQTimeInterval的pod移动到podBackoffQ或activeQ
func (p *PriorityQueue) flushUnschedulableQLeftover() {p.lock.Lock()defer p.lock.Unlock()var podsToMove []*framework.QueuedPodInfocurrentTime := p.clock.Now()for _, pInfo := range p.unschedulableQ.podInfoMap {// 最后调度的时间lastScheduleTime := pInfo.Timestamp// 如果pod在unschedulableQ中停留的时间超过unschedulableQTimeInterval(60秒)if currentTime.Sub(lastScheduleTime) > unschedulableQTimeInterval {podsToMove = append(podsToMove, pInfo)}}if len(podsToMove) > 0 {// 移动到podBackoffQ或activeQp.movePodsToActiveOrBackoffQueue(podsToMove, UnschedulableTimeout)}
}func (p *PriorityQueue) movePodsToActiveOrBackoffQueue(podInfoList []*framework.QueuedPodInfo, event framework.ClusterEvent) {moved := falsefor _, pInfo := range podInfoList {// If the event doesn't help making the Pod schedulable, continue.// Note: we don't run the check if pInfo.UnschedulablePlugins is nil, which denotes// either there is some abnormal error, or scheduling the pod failed by plugins other than PreFilter, Filter and Permit.// In that case, it's desired to move it anyways.if len(pInfo.UnschedulablePlugins) != 0 && !p.podMatchesEvent(pInfo, event) {continue}moved = truepod := pInfo.Podif p.isPodBackingoff(pInfo) {// 如果还在backoff时间内,添加到podBackoffQ队列if err := p.podBackoffQ.Add(pInfo); err != nil {klog.ErrorS(err, "Error adding pod to the backoff queue", "pod", klog.KObj(pod))} else {metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", event.Label).Inc()p.unschedulableQ.delete(pod)}} else {// 过了backoff时间,添加到activeQ队列if err := p.activeQ.Add(pInfo); err != nil {klog.ErrorS(err, "Error adding pod to the scheduling queue", "pod", klog.KObj(pod))} else {metrics.SchedulerQueueIncomingPods.WithLabelValues("active", event.Label).Inc()p.unschedulableQ.delete(pod)}}}// 将moveRequestCycle设置为当前的schedulingCyclep.moveRequestCycle = p.schedulingCycleif moved {p.cond.Broadcast()}
}
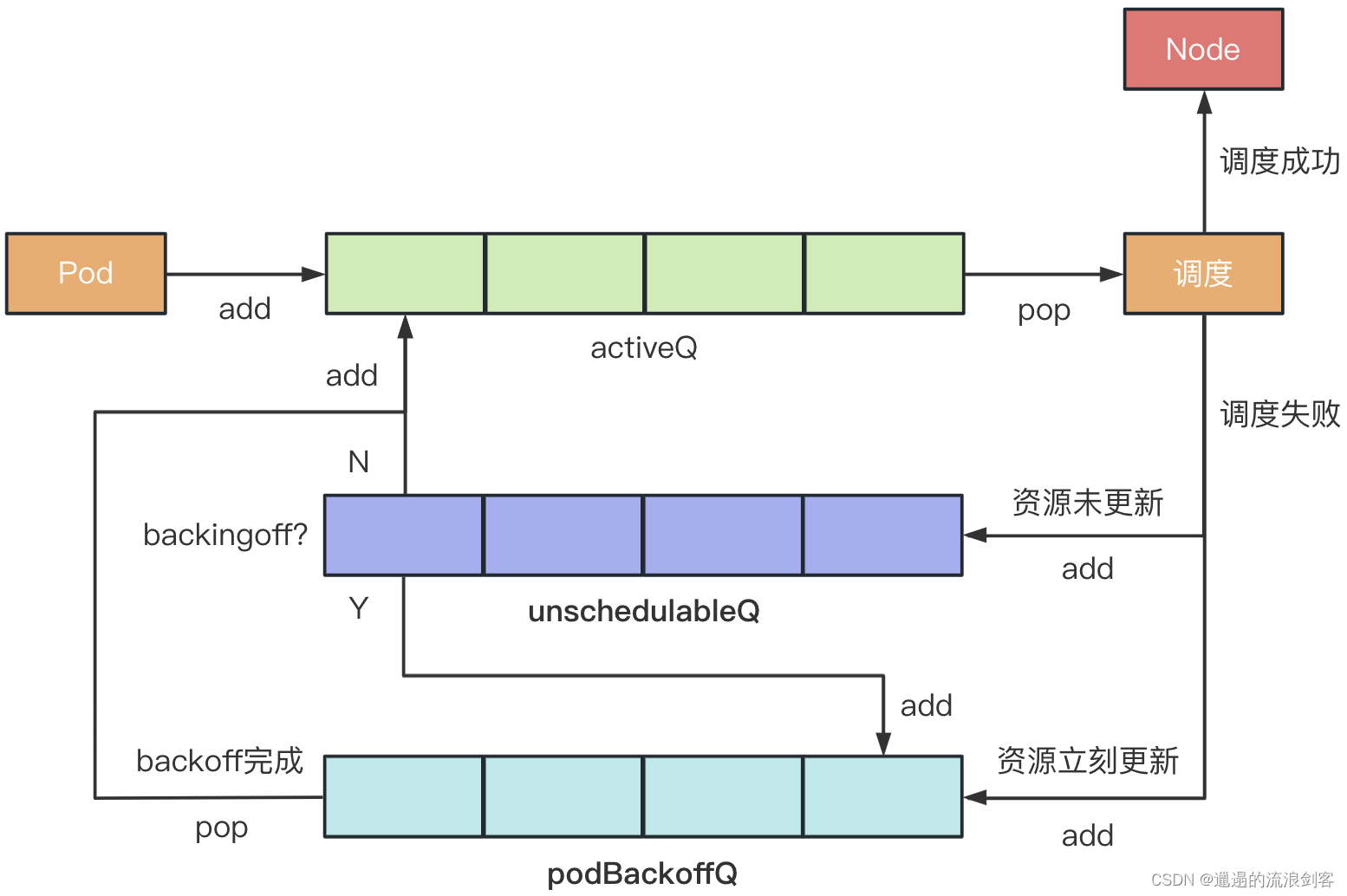
PriorityQueue中3个子队列的工作流程如下:
- 每隔1秒,检查podBackoffQ中是否有Pod可以被放进activeQ
- 每个30秒,检查unschedulableQ里是否有Pod可以被放进podBackoffQ或activeQ(默认条件是要在unschedulableQ中等待时间超过60秒)
- 不停地调用
scheduleOne()方法,从activeQ中取出Pod进行调度
如果一个Pod调度失败了,正常就是不可调度的,应该放入unschedulableQ队列。如果集群内的资源状态一直不发生变化,每隔60秒这些Pod还是会被重新尝试调度一次
一旦集群内的资源状态发生了变化,这些不可调度的Pod就很可能可以被调度了,也就是unschedulableQ中的Pod应该放进podBackoffQ或activeQ中去,等待安排重新调度。podBackoffQ里的Pod会根据重试的次数设定等待重试的时间,重试的次数越少,等待重新调度的时间也就越少。podBackoffQ里的Pod调度的速度会比unschedulableQ的Pod快得多
参考:
调度的优先级及抢占机制源码分析
调度Pod流程