YOLOv8详解全流程捋清楚-每个步骤

从第一步,到最后一步,带着你捋
整体架构
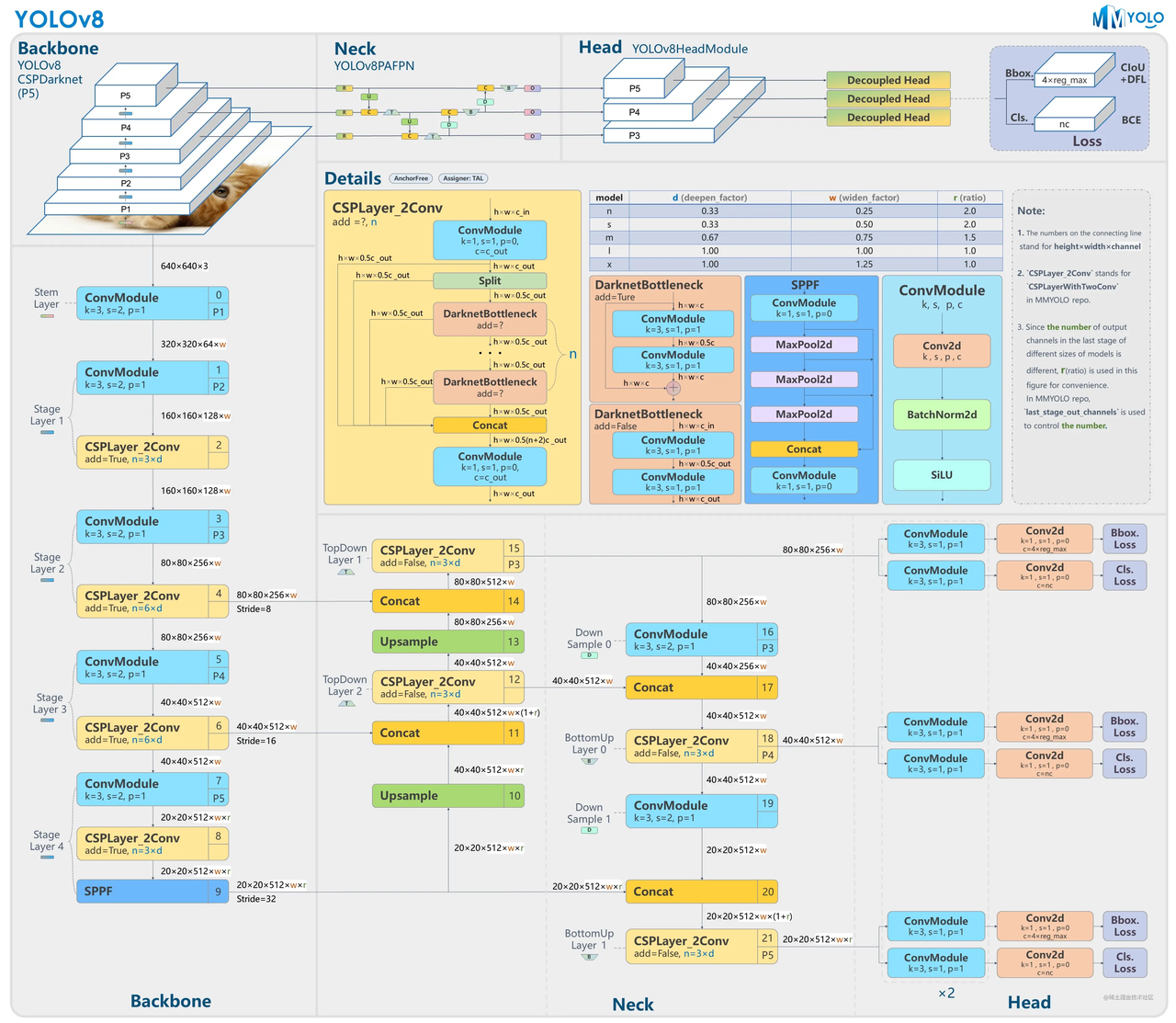
Backbone: Feature Extractor提取特征的网络,其作用就是提取图片中的信息,供后面的网络使用
Neck : 放在backbone和head之间的,是为了更好的利用backbone提取的特征
Head:利用前面提取的特征,做出识别
常见的一些Backbone, Neck, Head网络
Backbone
Darknet-53
53指的是“52层卷积”+output layer。
借鉴了其他算法的这些设计思想
-
借鉴了VGG的思想,使用了较多的3×3卷积,在每一次池化操作后,将通道数翻倍;
-
借鉴了network in network的思想,使用全局平均池化(global average pooling)做预测,并把1×1的卷积核置于3×3的卷积核之间,用来压缩特征;(我没找到这一步体现在哪里)
-
使用了批归一化层稳定模型训练,加速收敛,并且起到正则化作用。
以上三点为Darknet19借鉴其他模型的点。Darknet53当然是在继承了Darknet19的这些优点的基础上再新增了下面这些优点的。因此列在了这里
-
借鉴了ResNet的思想,在网络中大量使用了残差连接,因此网络结构可以设计的很深,并且缓解了训练中梯度消失的问题,使得模型更容易收敛。
-
使用步长为2的卷积层代替池化层实现降采样。(这一点在经典的Darknet-53上是很明显的,output的长和宽从256降到128,再降低到64,一路降低到8,应该是通过步长为2的卷积层实现的;在YOLOv8的卷积层中也有体现,比如图中我标出的这些位置)
-
特征融合
模型架构图如下
Darknet-53的特点可以这样概括:(Conv卷积模块+Residual Block残差块)串行叠加4次
Conv卷积层+Residual Block残差网络就被称为一个stage
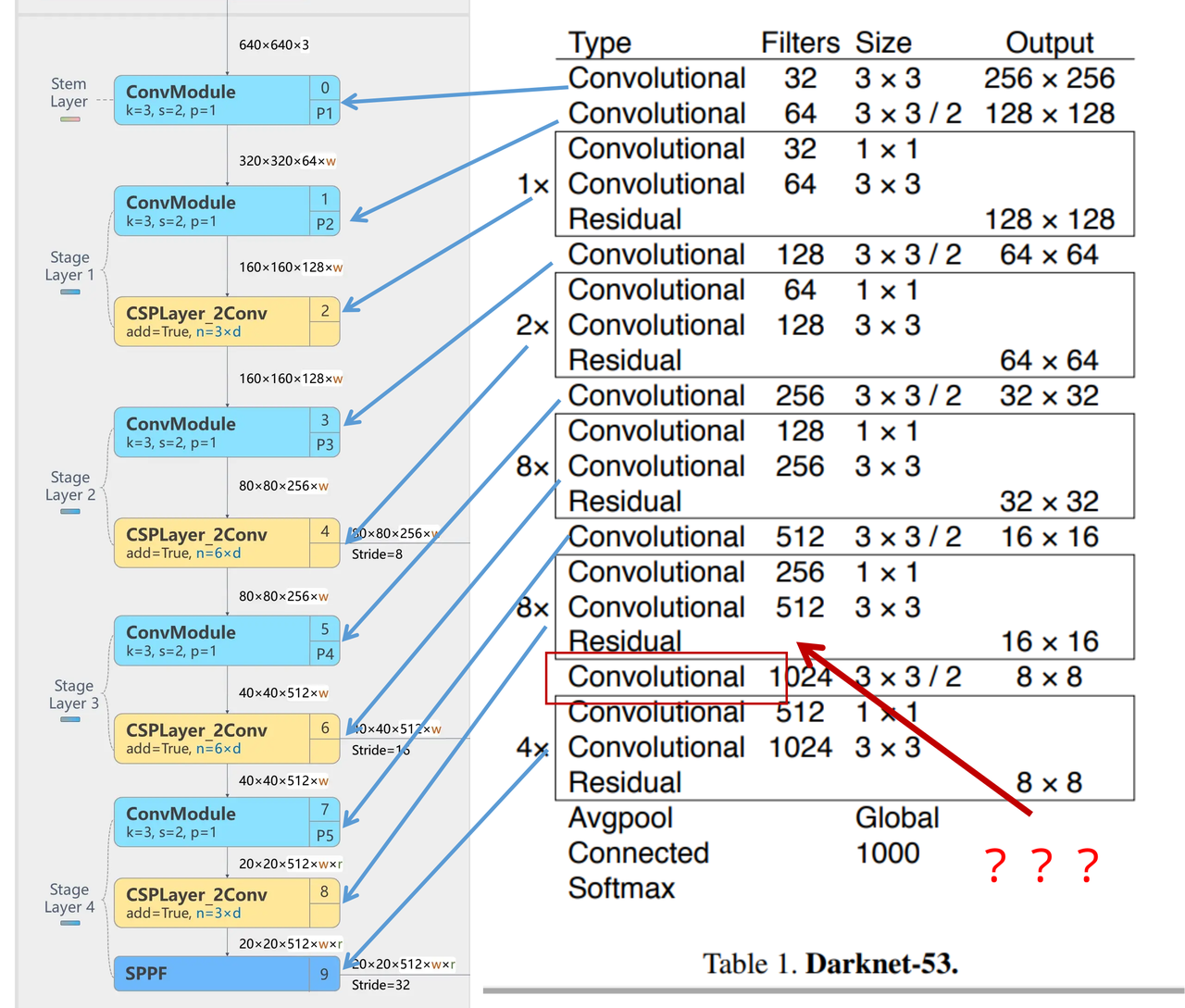
整个YOLOv8的backbone,画出图来是下面这样
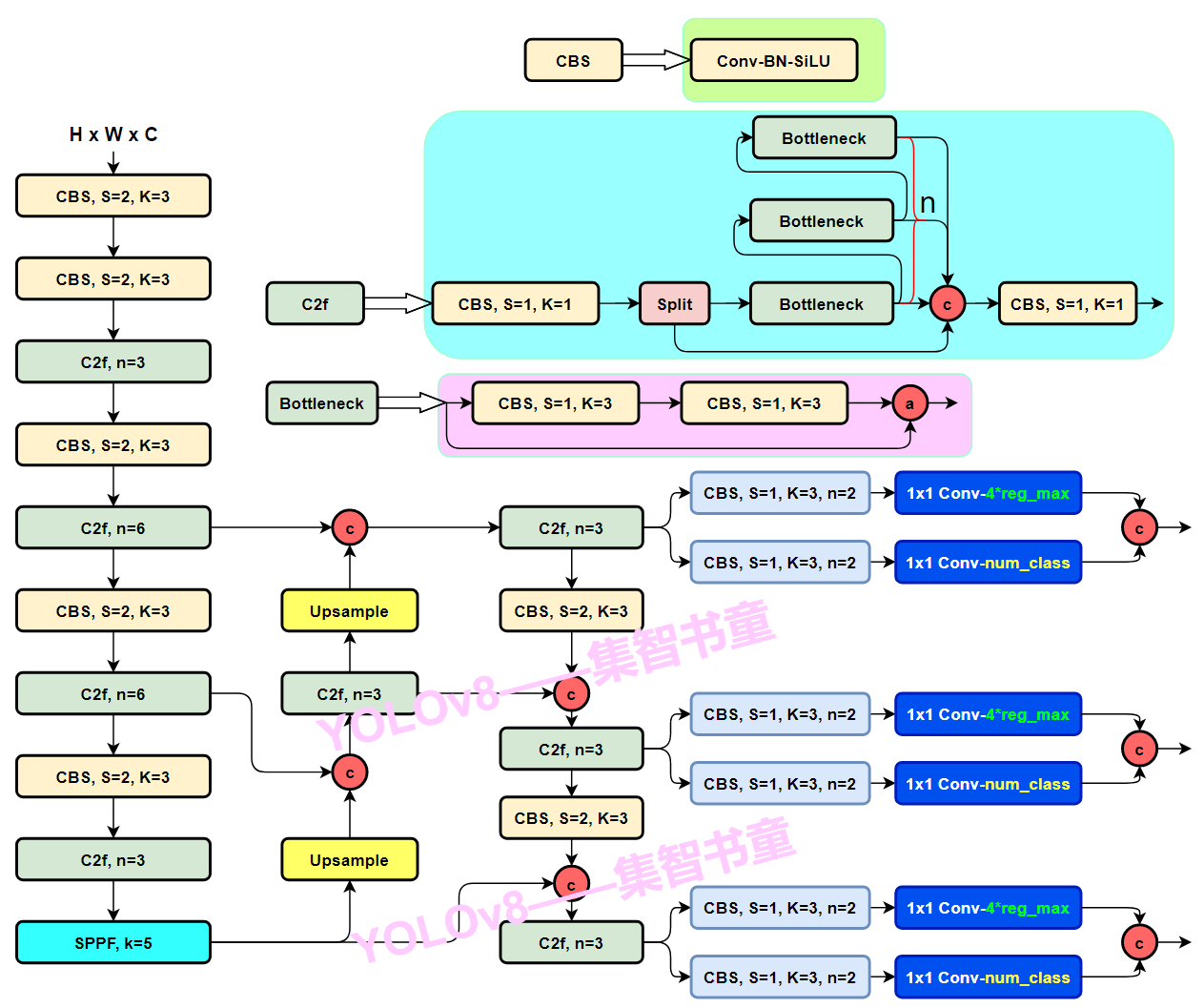
我们可以看到这个backbone由三种模块组成,CBS、C2f、SPPF
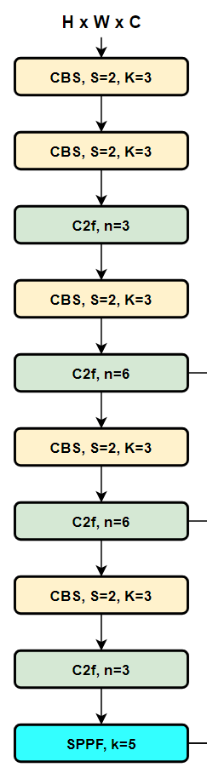
卷积模块使用CBS
三部分组成(1)一个二维卷积+(2)二维BatchNorm+(3)SiLU激活函数
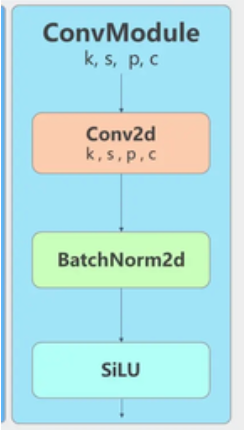
SiLU的激活是通过sigmoid函数乘以其输入来计算的,即xσ(x)。
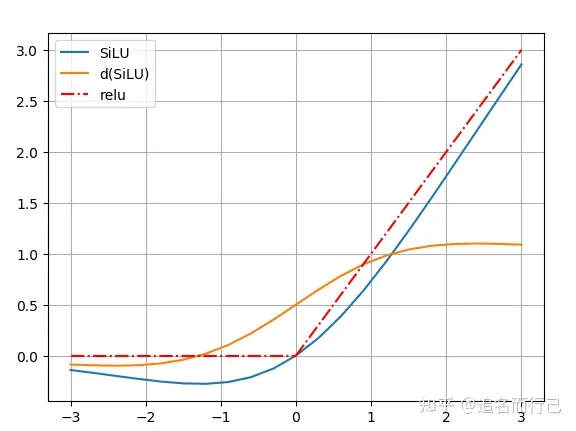
SiLU的优势:
-
无上界(避免过拟合)
-
有下界(产生更强的正则化效果)
-
平滑(处处可导 更容易训练)
-
x<0具有非单调性(对分布有重要意义 这点也是Swish和ReLU的最大区别)
Residual block使用C2f
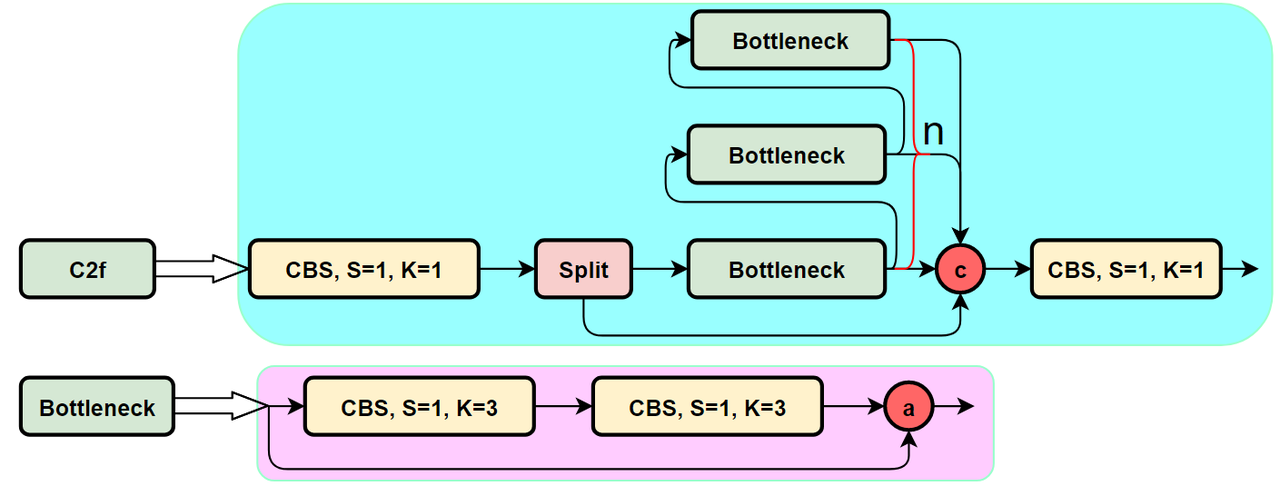
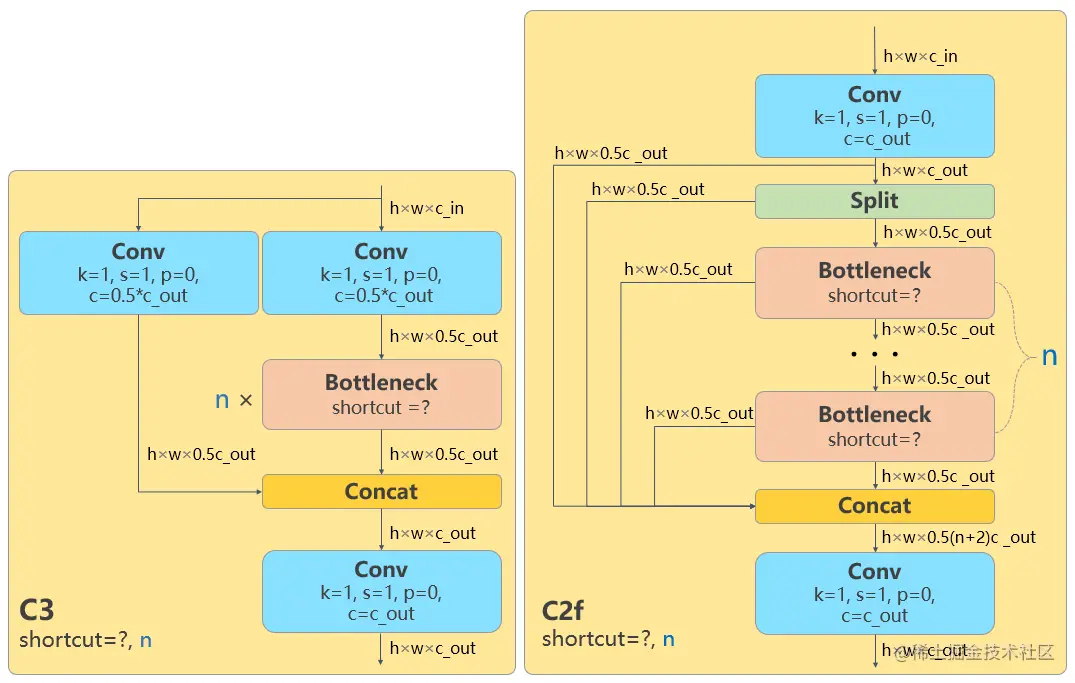
一个CBS卷积层,
一个split,就是把 height × width × c_out这个feature map的channel这一维度(c_out)切成两半,一半的feature map是h × w × 0.5c_cout,另一半是h × w × 0.5c_cout。这个把channel一劈两半的行为称之为split
bottleneck之前的feature map和bottleneck之后的feature map进行concat融合,这叫残差连接
n个Bottleneck串行,每个Bottleneck都和最后一个Bottleneck concatenate起来,类似于做了特征融合
优势:让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。(我没看出来哪里实现了轻量化? 梯度流信息丰富性如何体现?梯度流信息丰富了有什么好处?)
SPPF

进来一个CBS卷积层,然后串行的三个Maxpooling,未做Maxpooling的feature map和每多做一次Maxpooling后得到的feauture map进行concat 拼接,实现特征融合
用CSP的“网络设计方法“对Darknet进行轻量化
把原始的feature map和原始feauture map经过卷积操作后得到的结果进行concat,就是CSP的思想

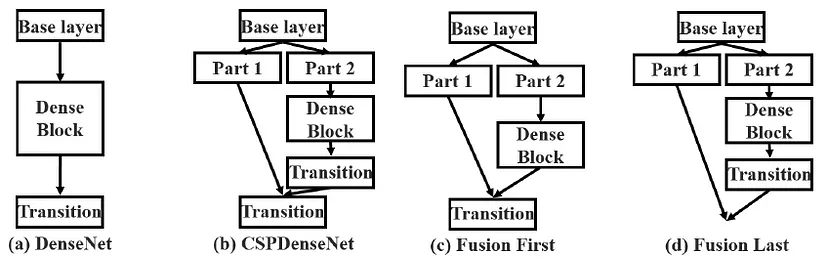
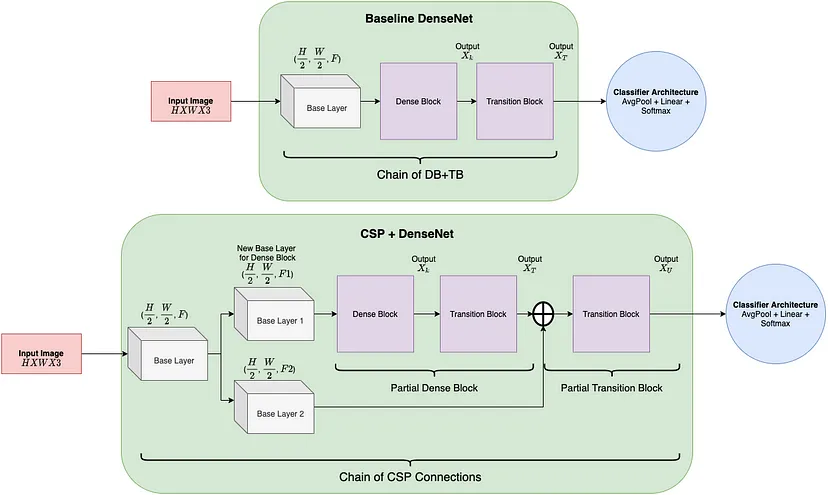
你单独去看backbone,你发现好像这些模块之间似乎没有使用CSP思想。一路串行下来,没有任何的跨层融合。
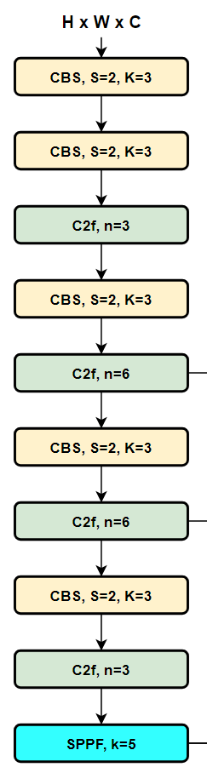
其实CSP思想的用在了组成backbone的这几个模块上,C2f模块和SPPF模块。C2f模块里面的DarknetBottleneck(add=True)也使用了CSP网络结构设计思想。
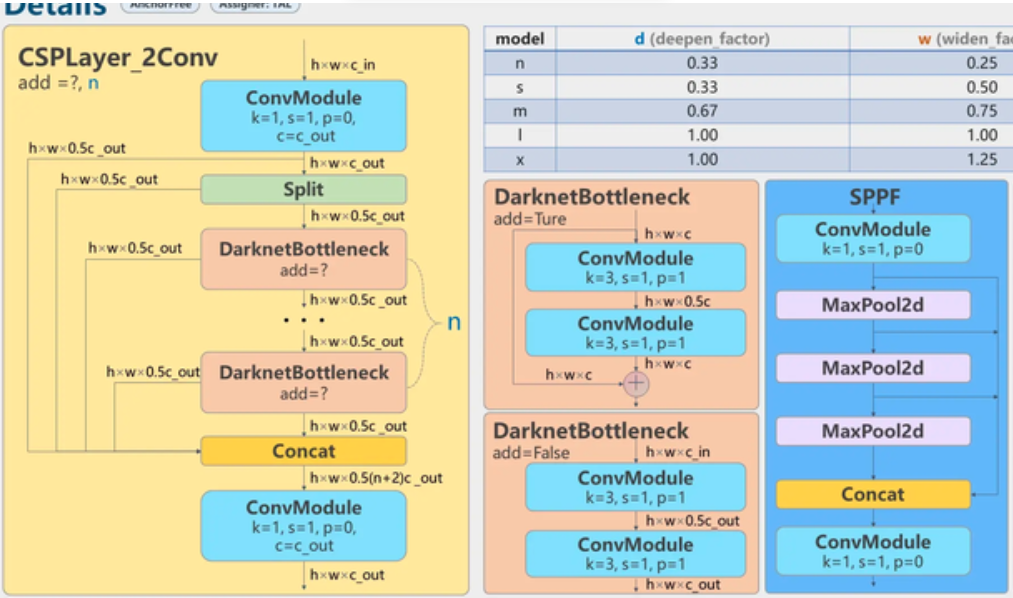
Neck
Neck上CSP思想的运用。
下图有四个 红心"c" 使用了CSP的思想。统统都是没做过卷积的原始feature map和将“原始特征图”进行过很多个卷积操作的feauture map进行融合,融合的位置就是在 四个 红心"c" 那里。
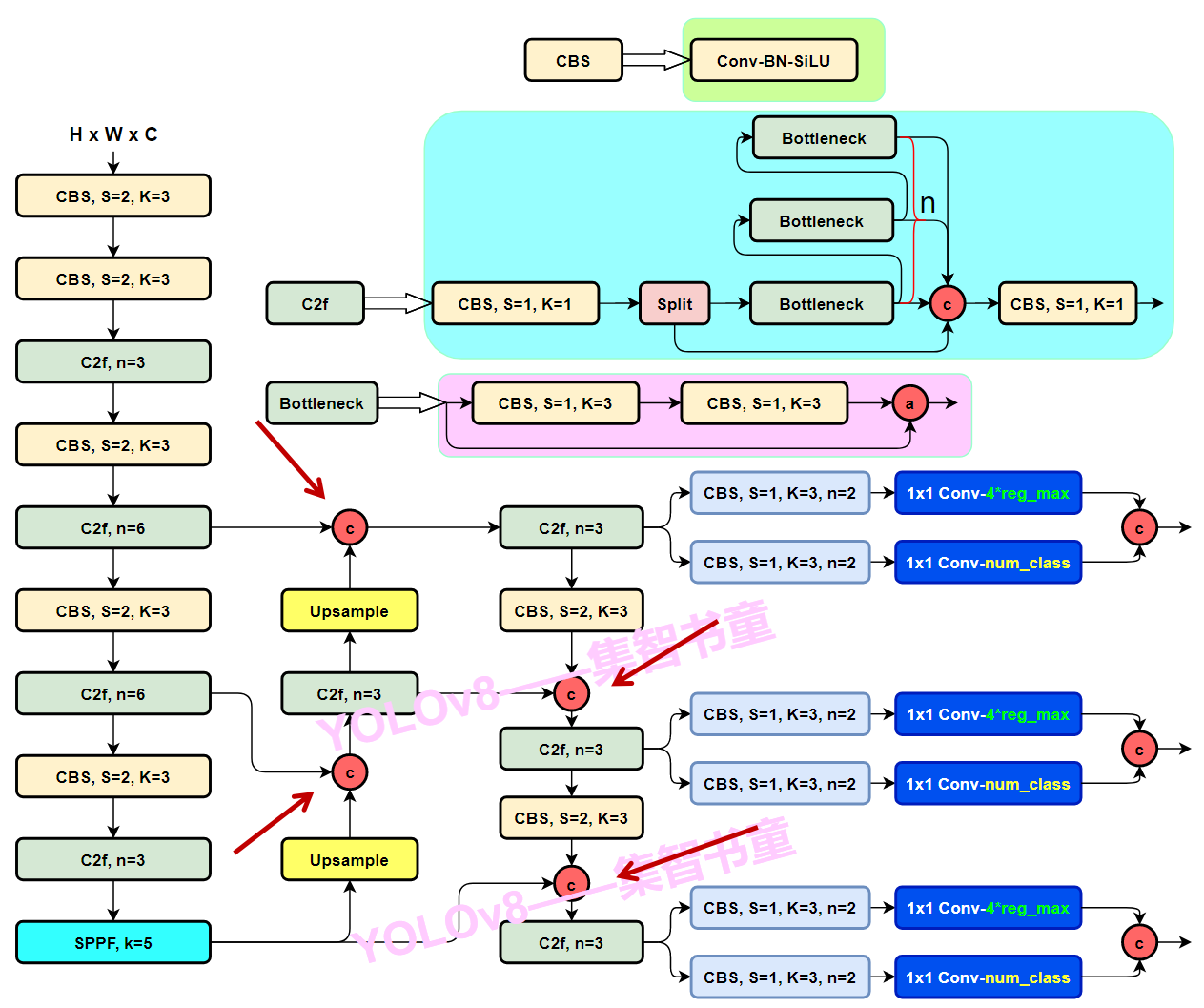
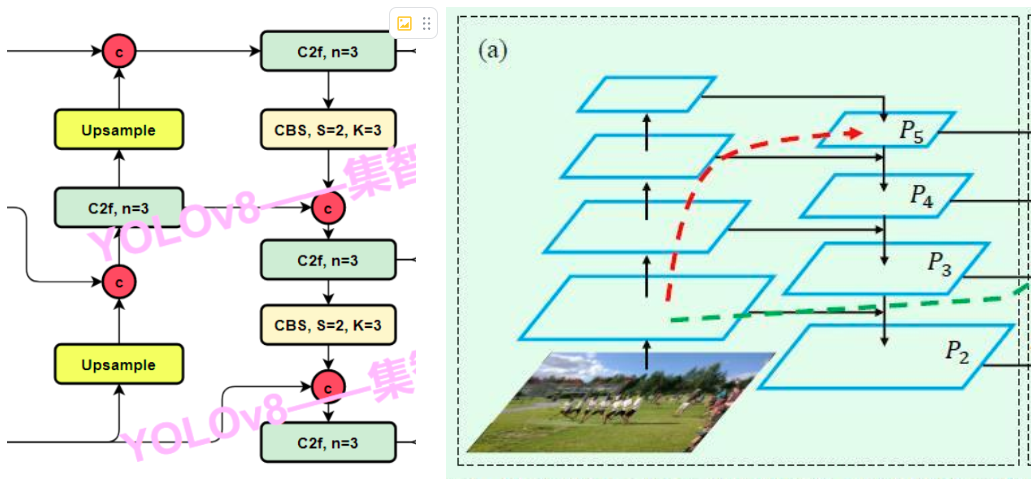
PAN-FPN
PAN-FPN,是指的在在YOLOv8的neck部分模仿PANet里面的backbone,也就是FPN网络(feature pyramid network)进行组织。PAN-FPN这个网络的特点进行简单概括,就是先下采样,然后再上采样,上采样和下采样的这两个分支之间还有两个跨层融合连接。(也可以反过来,先上采样,再下采样)
用C2f模块作为residual block
没啥好说的,就是图中这四个绿蓝色的模块
Head
先分叉开两个CBS卷积模块,然后过一个Conv2d,最后分别算出classifcation loss和Bbox loss
Decoupled-Head解耦头
Head 部分相比 YOLOv5 改动较大,从原先的耦合头换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离。同时由于使用了DFL(Distributional Focal Loss) 的思想,因此回归头的通道数也变成了4*reg_max的形式,reg_max默认16。
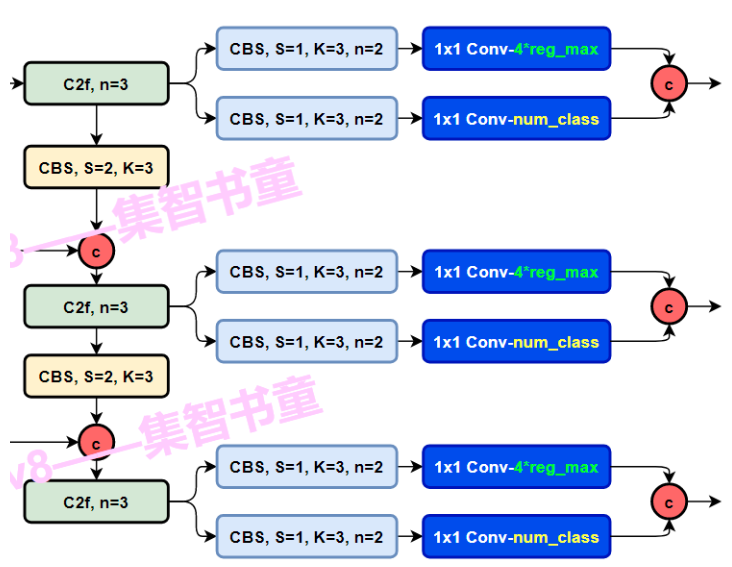

一个head做目标识别,用Bbox Loss来衡量。损失函数包括两部分CIoU和DFL
一个head做分类,用用BCE 二分类交叉熵损失函数 衡量,实际用的是VFL(Varifocal Loss)

损失函数的设计
分类损失VFL Loss
样本不均衡,正样本极少,负样本极多,需要降低负样本对 loss 的整体贡献了,于是用了focal loss。VFL当然具备focal loss拥有的所有特性。
VFL独有的:(1)学习 IACS 得分( localization-aware 或 IoU-aware 的 classification score)(2)如果正样本的 gt_IoU 很高时,则对 loss 的贡献更大一些,可以让网络聚焦于那些高质量的样本上,也就是说训练高质量的正例对AP的提升比低质量的更大一些。
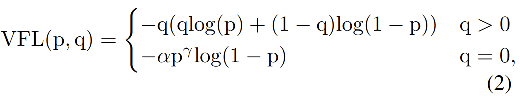
目标识别损失1-DFL(Distribution Focal Loss)
将框的位置建模成一个 general distribution,让网络快速的聚焦于和目标位置距离近的位置的分布

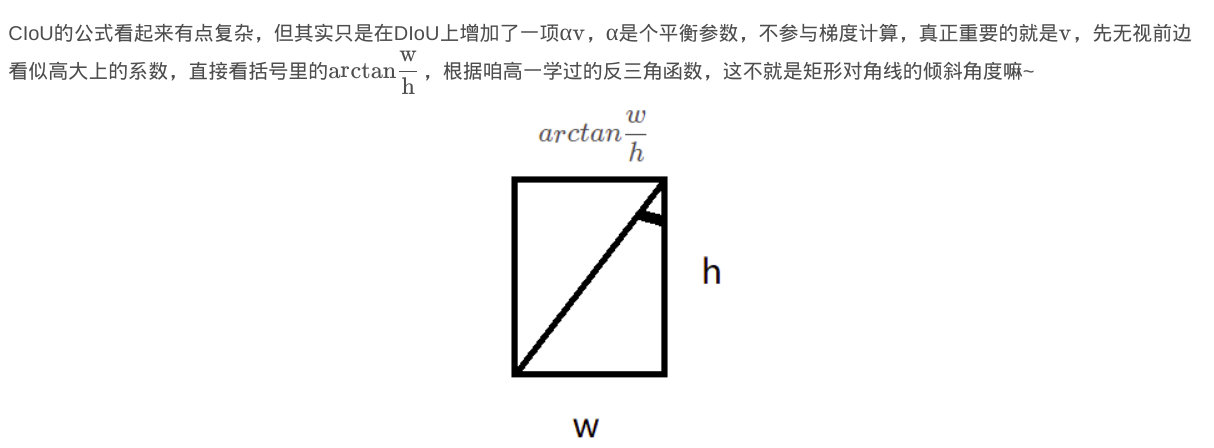
目标识别损失2-CIOU Loss
考虑到长宽比

样本匹配
YOLOv8则是(1)抛弃了Anchor-Base方法,转而使用Anchor-Free方法,(2)找到了一个替代边长比例的匹配方法——TaskAligned
Anchor-Based是什么?——Anchor-Based是指的利用anchor匹配正负样本,从而缩小搜索空间,更准确、简单地进行梯度回传,训练网络。
Anchor-Based方法的劣势是什么?——但是因为下列这些劣势,我们抛弃掉了anchor 这一多余的步骤:anchor也会对网络的性能带来影响,(1)如巡训练匹配时较高的开销、(2)有许多超参数需要人为尝试调节等
Anchor-free的优势是什么?——Anchor-free模型则摒弃或是绕开了锚的概念,用更加精简的方式来确定正负样本,同时达到甚至超越了两阶段anchor-based的模型精度,并拥有更快的速度。
为与NMS(non maximum suppression非最大抑制)搭配,训练样例的Anchor分配需要满足以下两个规则:——设计TaskAligned这个规则初衷
-
正常对齐的Anchor应当可以预测高分类得分,同时具有精确定位;
-
不对齐的Anchor应当具有低分类得分,并在NMS阶段被抑制。 基于上述两个目标,TaskAligned设计了一个新的Anchor alignment metric 来在Anchor level 衡量Task-Alignment的水平。并且,Alignment metric 被集成在了 sample 分配和 loss function里来动态的优化每个 Anchor 的预测。(完全没看懂这句话)
Anchor alignment metric:
分类得分和 IoU表示了这两个任务的预测效果,所以,TaskAligned使用分类得分和IoU的高阶组合来衡量Task-Alignment的程度。使用下列的方式来对每个实例计算Anchor-level 的对齐程度:
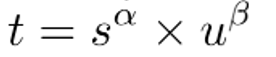
s 和 u 分别为分类得分和 IoU 值,α 和 β 为权重超参。 从上边的公式可以看出来,t 可以同时控制分类得分和IoU 的优化来实现 Task-Alignment,可以引导网络动态的关注于高质量的Anchor。TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
Training sample Assignment:
为提升两个任务的对齐性,TOOD(Task-aligned One-stage Object Detection)聚焦于Task-Alignment Anchor,采用一种简单的分配规则选择训练样本:对每个实例,选择m个具有最大t值的Anchor作为正样本,选择其余的Anchor作为负样本。然后,通过损失函数(针对分类与定位的对齐而设计的损失函数)进行训练。
看完后觉得哪些地方可以改进?
损失函数改进,毕竟还有个数人数的那个指标可以加进损失函数里
小目标检测的方法往里套
加入Transformer
拿市面上的对卷积层做一个优化改造方法拿来用
数据增强,最SOTA的方法拿来用
把backbone上更新、最SOTA的模型拿来用,——使用多个主干网络融合来提取特征(Multi-Backbone?
模型轻量化、加速
SOTA的新出的追踪算法或者追踪算法的优化