测试开发岗 - 一面复盘

1. 什么是软件测试, 谈谈你对软件测试的了解
软件测试就是验证产品特性是否符合用户需求, 软件测试贯穿于软件的整个生命周期.
>>>
那软件测试具体是什么呢 ?
就拿生活中的例子来说, 比如说我们去商场买衣服, 会有以下几个步骤 :
第一步: 我们会走进门店, 看看衣服的外观好不好看, 进行外观测试;
第二步 : 我们会摸一下衣服的材质如何, 看看衣服是纯棉的, 还是涤纶的, 进行材质测试;
第三步 : 我们会将衣服拿到试衣间试穿一下, 看是否合身, 进行试穿测试;
第四步 : 我们会询问服务人员衣服的价格如何, 看看是否符合自己的预期;
如果上述步骤都符合自己的需求, 那么才会有后续的交易完成.
>>>
其实软件测试也是类似的流程, 是需要站在用户的角度, 了解用户的需求, 再针对产品进行一系列的软件测试, 看看产品的功能, 性能, 界面, 兼容性, 易用性是否符合用户需求.
以上就是我对软甲测试的一个了解.
2. 我看你简历上有写了解常见的开发模型和测试模型, 那你跟我讲一下敏捷模型
敏捷模型中最熟悉的就是敏捷宣言, 它的内容包括四点 :
1. 个体与交互重于过程和工具;
2. 可用的软件重于完备的文档;
3. 客户协作重于合同谈判;
4. 响应变化重于遵循计划.
总结来说, 敏捷模型的特点就是 : 轻流程, 轻文档, 重目标, 重产出.
>>>
另外呢, 敏捷模型中最典型的就是 scrum 模型.
scrum 模型主要包括三个重要角色和五个重要会议.
三个重要角色 : 分别是产品经理, 项目经理和研发团队;
而五个重要会议呢 :
首先会有一个需求池, 里面放着一个个的用户需求
1. 然后会议 1 是需求发布会议, 根据需求池中的需求确定本次迭代要实现的需求有哪些.
2. 会议 2 是迭代计划会议, 该会议将需求拆分成一个一个的任务, 明确每个任务对应的负责人, 初步评估工时.
3. 会议 3 是每日会议, 会议中每个研发团队成员需要回答三个问题 : 第一个问题是昨天做了什么, 这个问题可以及时的, 实时的知道研发团队的工作进度; 第二个问题是今天要做什么, 这个问题对应了敏捷宣言里的重目标; 第三个问题是遇到了什么问题, 可以让研发团队针对你这个问题给出一些合理的建议, 保证尽快的解决问题.
4. 会议 4 是演示会议, 演示会议的产物是用户的需求, 然后将这些需求继续放入需求池中, 为下一个周期提供新的需求.
5. 会议 5 是回顾会议, 简单来说就是复盘.
以上就是我对敏捷模型的一些了解.
3. 我看你简历上还写了挺多开发技能的, 那你给我讲讲哈希表的实现流程
在 jdk1.7 的时候, 它是数组 + 链表的数据结构实现方式, 在 jdk1.8 的时候, 它是数组 + 链表或者红黑树的数据结构实现方式.
哈希表的实现流程主要就是两个方法 - put 和 get, put 方法呢, 主要就是用于存储对象, 它在存储对象的时候呢, 会先调用参数 key 的 hashcode() 方法, 得到一个哈希值, 然后再使用这个哈希值去模上数组的长度得到一个下标, 而这个下标就表示当前键值对是需要存储在数组中哪一个哈希桶里, 然后再遍历当前哈希桶下的链表, 查找链表 :
1. 是否为空, 如果为空, 就直接插入;
2. 如果已经包含该 key, 那么就进行 value 覆盖;
3. 如果当前是红黑树, 就直接插入该键值对;
4.如果当前数组长度 >= 64, 链表长度 >= 8 时, 就 先将链表转成红黑树, 然后再进行插入.
5. 其他情况就是不包含该 key, 然后也不需要转成红黑树, 就进行链表的尾插, 在 jdk1.7 的时候, 是进行链表的头插, 但是存在链表成环问题, 所以 jdk1.8 做出了优化.
>>>
每当我们向哈希表中插入一个键值对后, 都需要检查当前负载因子是否超过默认负载因子, 当前负载因子是用数组中元素的个数除以数组的长度得到的, 如果超过了, 就需要进行重新哈希, 重新哈希需要遍历数组中每一个哈希桶下链表中的每一个结点, 然后重新哈希到新的哈希表中.
>>>
然后 get 方法呢, 主要就是传入一个 key, 获取对应的 value, 首先同样也是先调用 key 的hashcode() 方法, 得到一个哈希值, 然后再模上数组的长度得到一个下标, 找到对应的哈希桶, 然后遍历当前哈希桶下的链表, 找到对应的 key, 返回 value 即可.
>>>
当然哈希表源码中, 不是通过哈希值 % 数组长度去找到对应的哈希桶, 而是使用了
(数组长度 - 1) & hash, 去找到对应的哈希桶, 因为 JDK 规定哈希表的数组长度必须是 2 的某个次幂, 而且当数组的长度是 2 的某个次幂时, 这两种方式找到的哈希桶是相同的, 而且位运更高效.
例如 : 哈希值(hash)为 22, 数组长度(n)为 8 时, 通过 hash % n 找到的是下标为 6 的哈希桶, 通过 hash & (n - 1) 找到的也是下标为 6 的哈希桶.
>>>
最后就是 hashmap 的容量和扩容机制 :
当我们写出 HashMap<key, value> map = new HashMap<>() 这样一行代码时, 它此时的容量为 0, 当我们第一次 put 元素的时候, 它的大小就扩容为了 16. 如果我们手动指定 hashmap 的大小为 19, 那么它的真实容量其实是 32, 因为 JDK 规定数组的长度必须是 2 的某个次幂, 然后 2^4 是 16, 不够19, 就需要向上取整, 也就是 2^5 = 32.
扩展问题(根据实际情况回答) :
3.1 两个 key 调用 hashcode() 得到的结果相同, 调用 equals() 得到的结果一定相同吗 ?
答案 : 不一定相同.
因为 hashcode 找到的是当前键值对要存放的哈希桶是哪一个, 而 equals 比较的是同一个哈希桶下链表中的结点是否相同.
3.2 两个 key 调用 equals() 得到的结果相同, 调用 hashcode() 得到的结果一定相同吗 ?
答案 : 一定相同.
因为 equals() 找到的是对应哈希桶下的链表中的结点, 如果 equals() 都相同了, 那么肯定在同一个哈希桶下.
4. 谈一谈什么是线程安全问题, 如何解决
线程安全问题的万恶之源, 就是因为操作系统的随机调度, 抢占式执行这个过程. 在随机调度的情况下, 多线程程序执行的时候, 有无数种排列方式, 在这些排列方式中, 有一些排列方式的额逻辑是正确的, 而有一些排列方式, 可能会引起程序 bug, 对于多线程并发时, 会使程序出现 bug 的代码, 称作线程不安全的代码, 这个就是线程安全问题. 为什么排列方式的不同可能会导致线程安全问题呢 :
最好举例证明: 共享屏幕举例说明, 例如多个线程针对同一个变量进行 + 1 操作时, 此过程类似于计算 1 + 1 = 2.
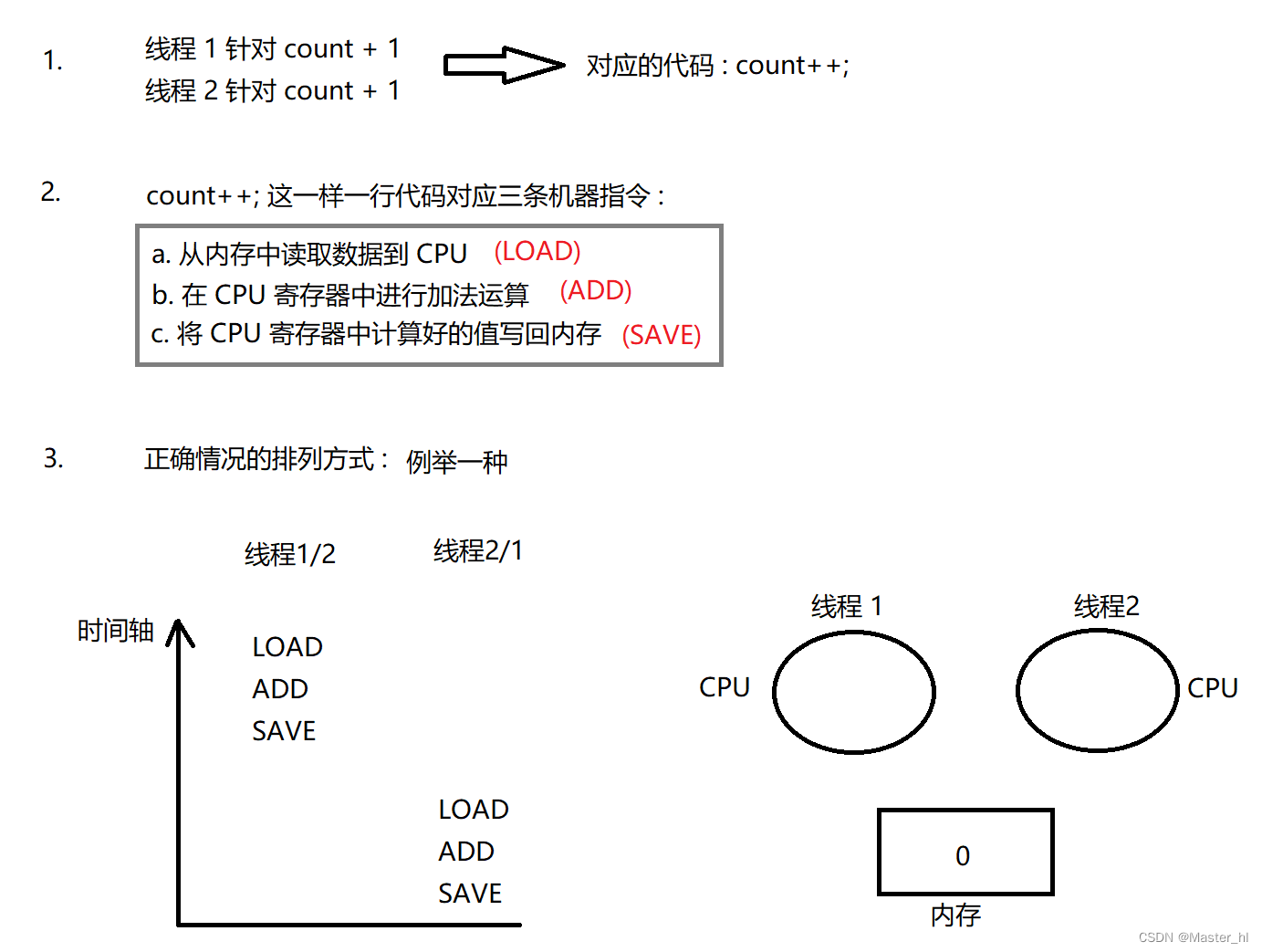
线程 1 执行 LOAD,ADD,SAVE :
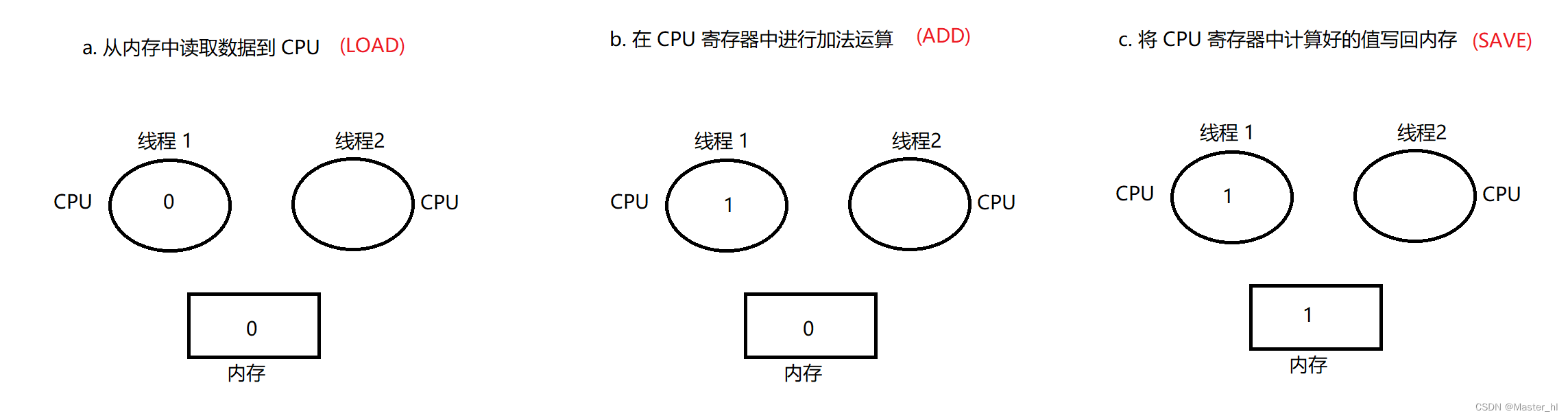
线程 2 的执行 LOAD,ADD,SAVE :
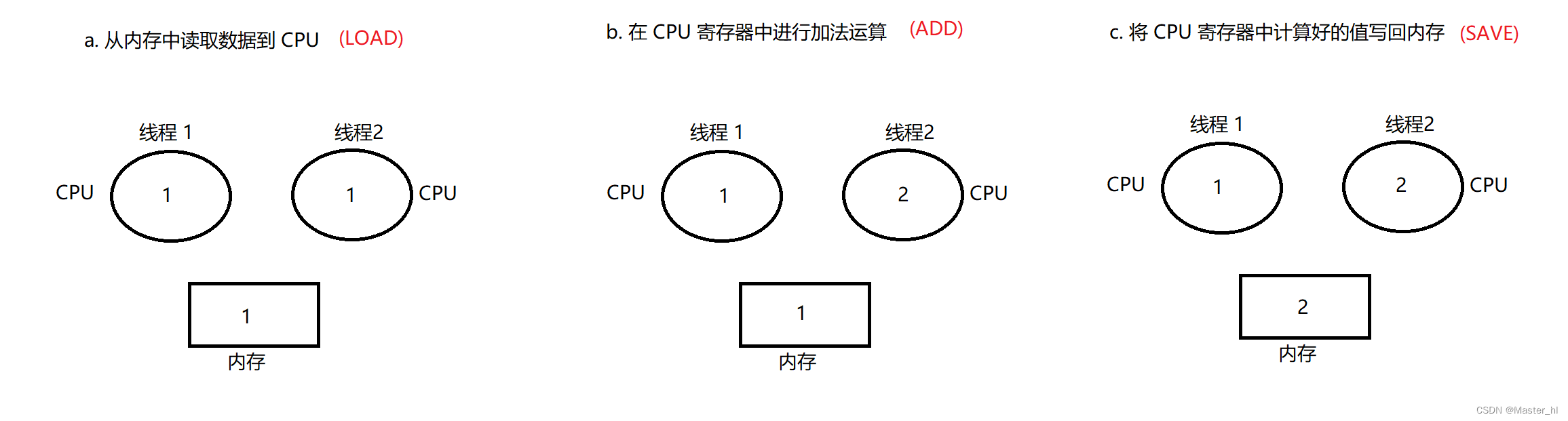
两个线程针对同一变量 + 1, count 的结果为 2 , 此种排列方式逻辑正确.
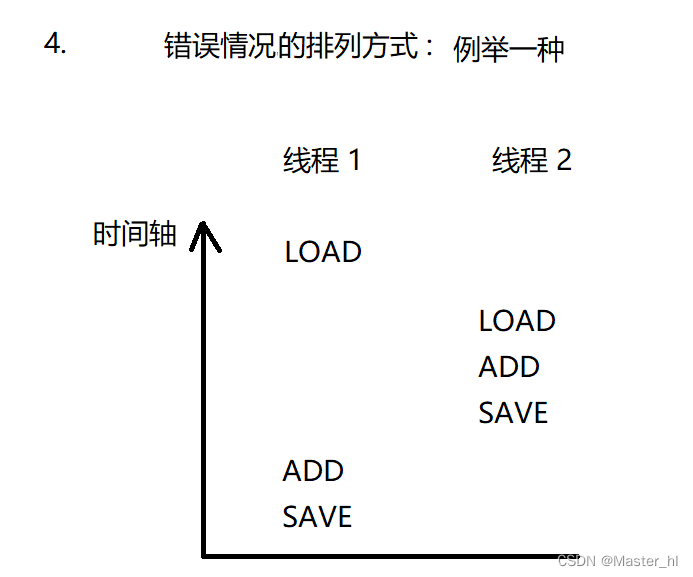
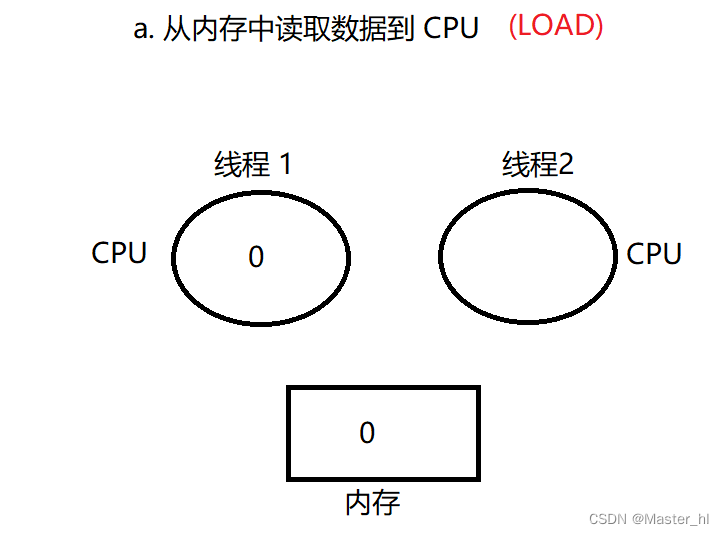
错误的排列方式下, 线程 1 线程 2 的执行流程 :
线程 1 执行 LOAD :
线程 2 执行 LOAD,ADD,SAVE :
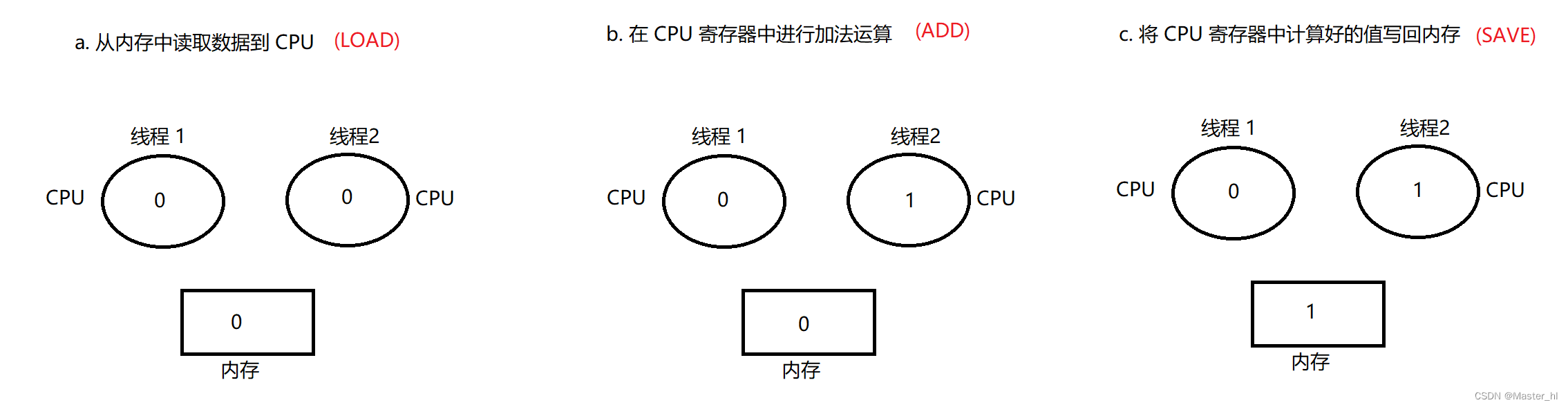
线程 1 执行 ADD,SAVE :
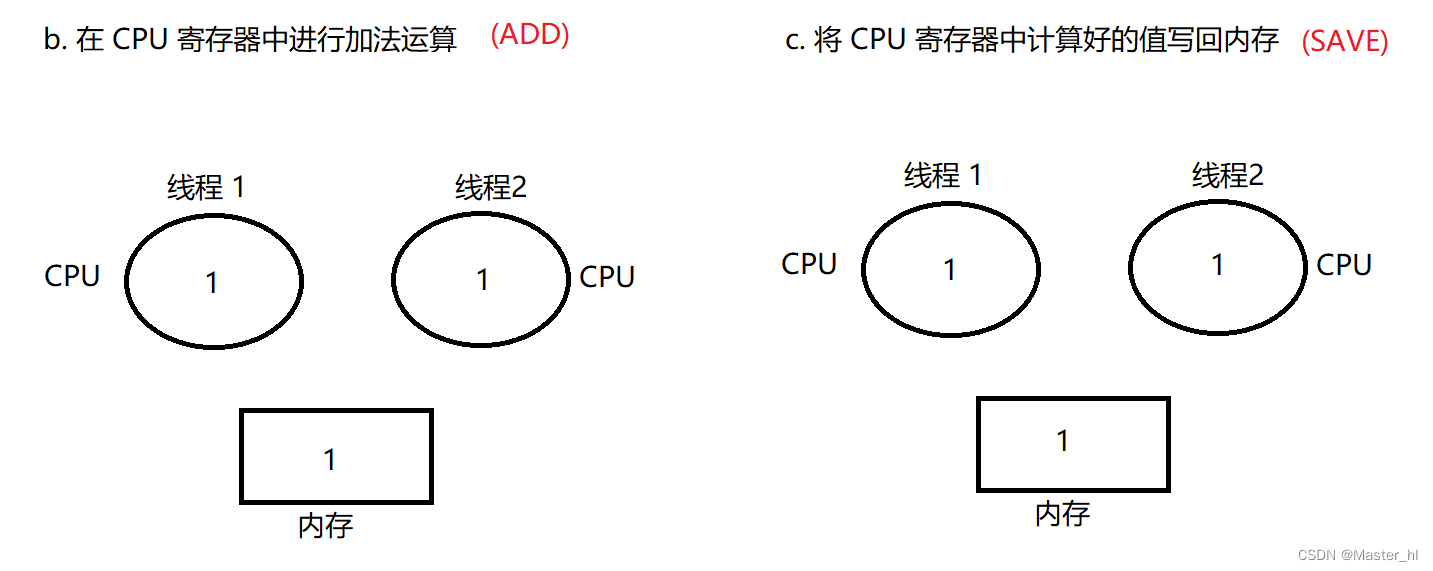
上述排列方式就导致了 1 + 1 = 1, 这种排列方式就是一种 bug, 所以说多线程程序排列方式的不同, 就可能会导致线程安全问题.
>>>
线程安全问题主要有五大因素 :
1. 第一点也是最重要的一点, 就是刚才的操作系统的随机调度, 抢占式执行导致的.
2. 第二个原因是因为多个线程同时修改同一个变量, 也就是刚才举的例子.
3. 第三个原因是因为有些修改操作不是原子性的. 比如赋值 "=" 操作符对应的就是一条机器指令, 而自增或者自减对应的就是三条机器指令, 也就是上述例子中的 (LOAD,ADD,SAVE), 多线程环境下, 如果不保证原子性, 当一个线程正在对一个变量操作时, 其他线程中途插入进来打断当前线程的操作时, 就可能会导致结果结果出错.
4. 第四个原因是内存可见性, 引起的线程安全问题. 内存可见性问题主要是一个线程修改, 一个线程读的场景. 当线程 1 反复读取内存中的数据, 然后判断 CPU 寄存器中的数据是否符合预期时, 线程 2 中途突然针对 CPU 寄存器中的值进行了修改, 然后写回内存, 而编译器看到的就是线程 1 在不断的读内存, 然后判断, 而且每次读内存读的都是同一个变量, 并且该变量似乎也没有发现变化, 于是就做出了 "编译器优化", 将不断的读内存, 判断操作, 优化成了读一次内存, 然后一直判断, 就如下图场景 (面试中可以画图举例)

此场景对应的代码例子如下 :
public class Main {static class Counter {public int flag = 0;}public static void main(String[] args) {Counter counter = new Counter();Thread t1 = new Thread(() -> {while(counter.flag == 0) {try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("t1 结束");});t1.start();Thread t2 = new Thread(() -> {//让用户输入一个数字,赋值给 flagScanner scanner = new Scanner(System.in);System.out.println("请输入一个整数: ");counter.flag = scanner.nextInt();});t2.start();}
}下次写。。。
5. 既然你选择走测试, 为什么还要学这么多的开发知识
首先我个人是对开发比较感兴趣, 所以在校期间学了很多开发方面的专业知识. (目的是为了凸显自己爱学习)
其次呢, 测试它不仅仅包含白盒测试, 黑盒测试, 它也是需要具备扎实的开发能力来提高个人的项目测试质量. 作为测试人员, 如果我们具备扎实的开发能力, 当我们给开发人员提 bug 的时候, 开发人员对我们所提出来的 bug 的可信度也是会比较高的. 并且 我们测试人员也是需要开发效能工具来提高测试效率的. (目的是为了凸显自己对软件测试工作的了解)
下次再补充......