神经网络/深度学习(二)

Seq2Seq 模型
Encoder-Decoder
摘文不一定和目录相关,但是取自该链接
1. Seq2Seq 模型详解
https://baijiahao.baidu.com/s?id=1650496167914890612&wfr=spider&for=pc
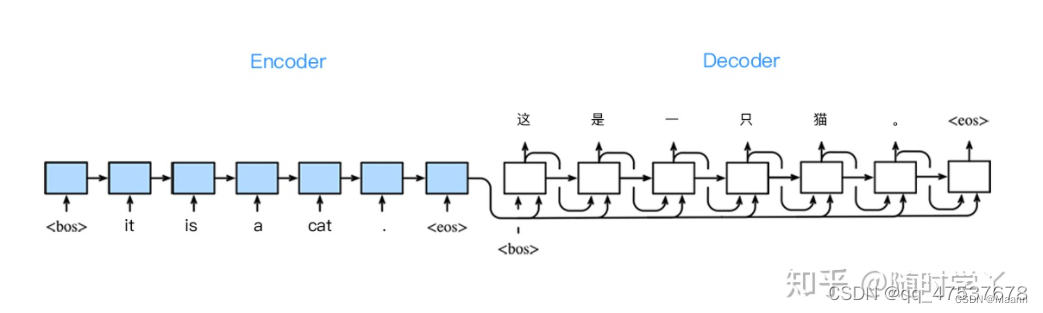
Seq2Seq 是一种循环神经网络的变种,包括编码器 (Encoder) 和解码器 (Decoder) 两部分。Seq2Seq 是自然语言处理中的一种重要模型,可以用于机器翻译、对话系统、自动文摘。
1.1 RNN 结构及使用
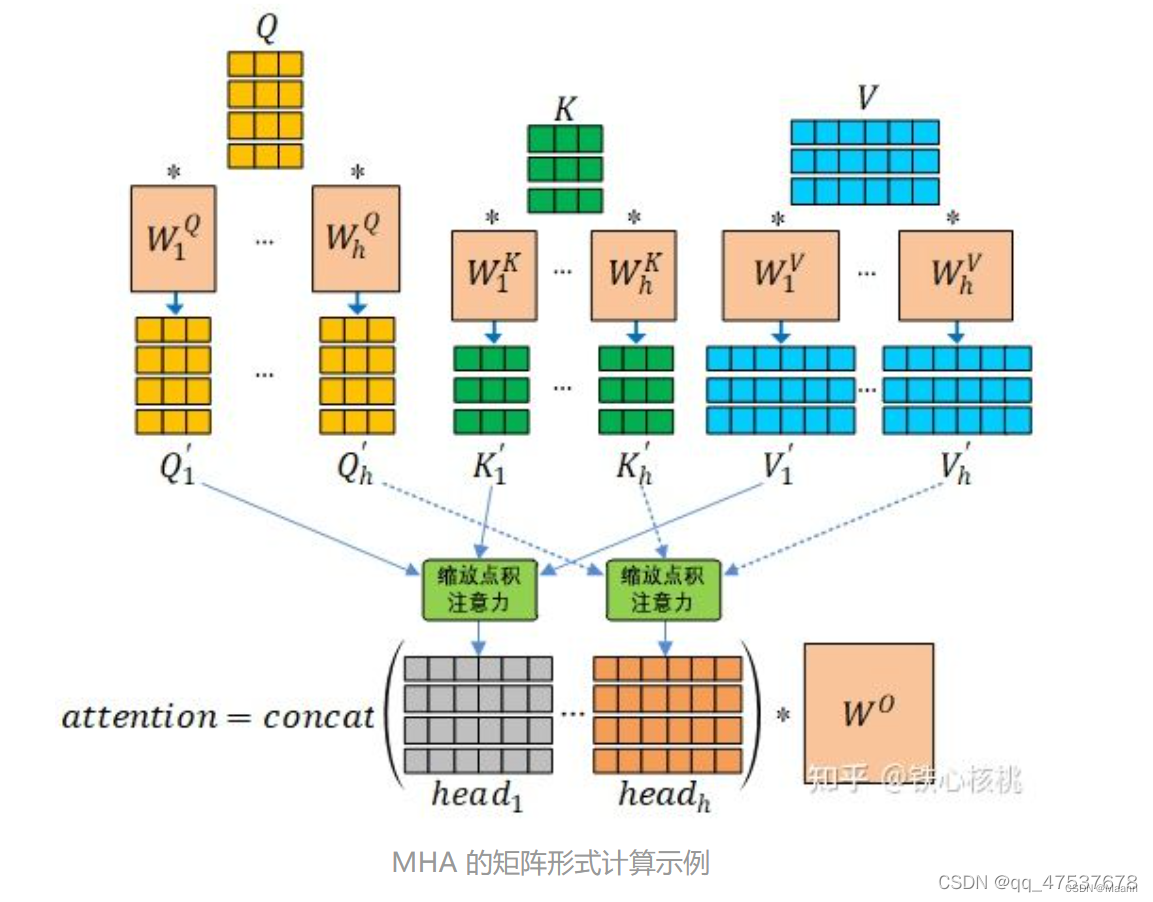
每个神经元接受的输入包括:前一个神经元的隐藏层状态 h(用于记忆) 和当前的输入 x (当前信息)。神经元得到输入之后,会计算出新的隐藏状态 h 和输出 y,然后再传递到下一个神经元。因为隐藏状态 h 的存在,使得 RNN 具有一定的记忆功能。
针对不同任务,通常要对 RNN 模型结构进行少量的调整,根据输入和输出的数量,分为三种比较常见的结构:N vs N、1 vs N、N vs 1。
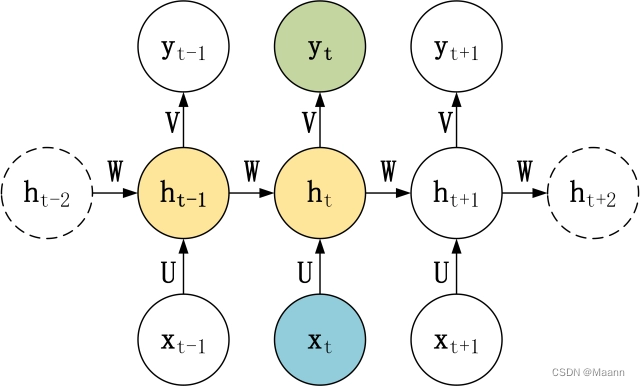
N vs N
上图是RNN 模型的一种 N vs N 结构,包含 N 个输入 x1, x2, …, xN,和 N 个输出 y1, y2, …, yN。N vs N 的结构中,输入和输出序列的长度是相等的,通常适合用于以下任务:
(1)词性标注
(2)训练语言模型,使用之前的词预测下一个词等
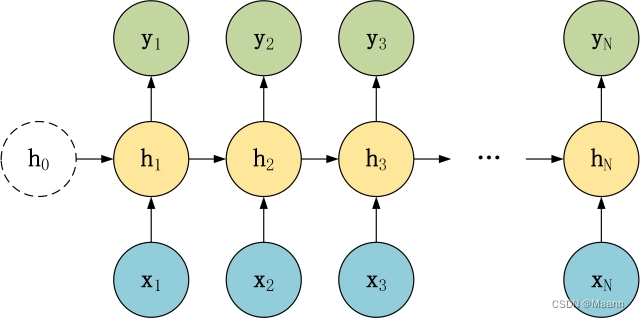
1 vs N
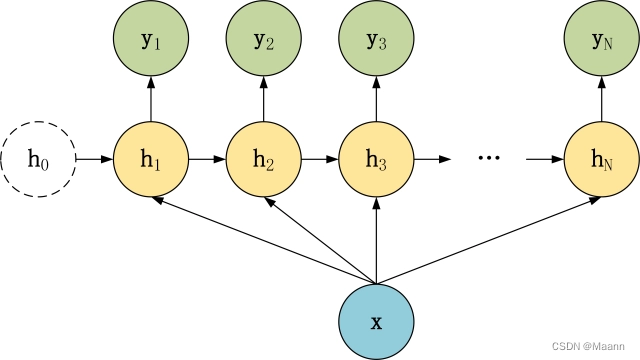
在 1 vs N 结构中,我们只有一个输入 x,和 N 个输出 y1, y2, …, yN。可以有两种方式使用 1 vs N,第一种只将输入 x传入第一个 RNN 神经元,第二种是将输入 x 传入所有的 RNN 神经元。1 vs N 结构适合用于以下任务:
(1)图像生成文字,输入 x 就是一张图片,输出就是一段图片的描述文字。
(2)根据音乐类别,生成对应的音乐。
(3)根据小说类别,生成相应的小说。
N vs 1
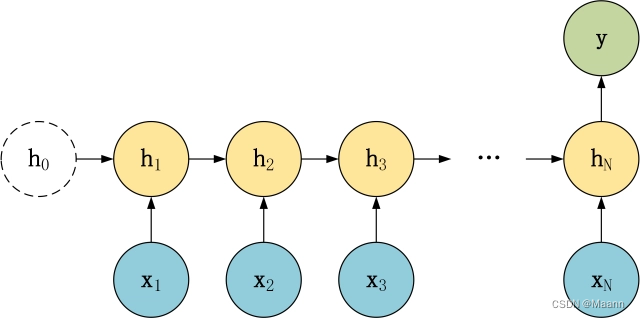
在 N vs 1 结构中,我们有 N 个输入 x1, x2, …, xN,和一个输出 y。N vs 1 结构适合用于以下任务:
(1)序列分类任务,一段语音、一段文字的类别,句子的情感分析。
1.2 Seq2Seq 模型
上面的三种结构对于 RNN 的输入和输出个数都有一定的限制,但实际中很多任务的序列的长度是不固定的,例如机器翻译中,源语言、目标语言的句子长度不一样;对话系统中,问句和答案的句子长度不一样。
Seq2Seq 是一种重要的 RNN 模型,也称为 Encoder-Decoder 模型,可以理解为一种 N×M的模型。模型包含两个部分:Encoder 用于编码序列的信息,将任意长度的序列信息编码到一个向量 c 里。而 Decoder 是解码器,解码器得到上下文信息向量 c 之后可以将信息解码,并输出为序列。Seq2Seq 模型结构有很多种,下面是几种比较常见的:
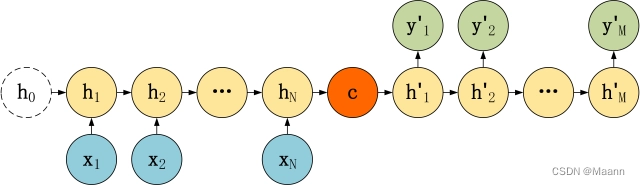
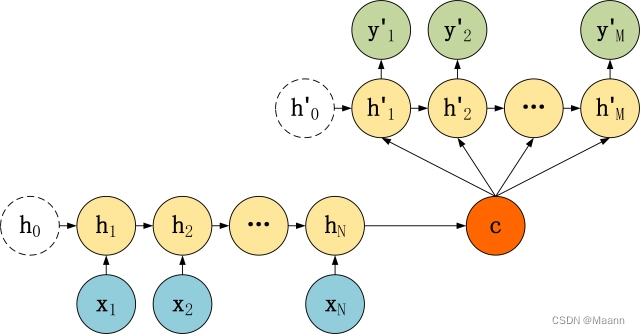
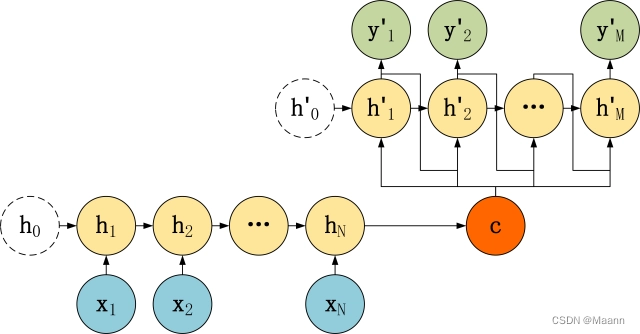
2. Encoder-Decoder
https://blog.csdn.net/qq_47537678/article/details/121921381
浅谈 Attention 机制的理解
Encoder-Decoder 通常称作 编码器-解码器 ,是深度学习中常见的模型框架,很多常见的应用都是利用编码-解码框架设计的。
Encoder 和 Decoder 部分可以是任意文字,语音,图像,视频数据,模型可以是 CNN,RNN,LSTM,GRU,Attention 等等。所以,基于 Encoder-Decoder,我们可以设计出各种各样的模型。
Encoder-Decoder 有一个比较显著的特征就是它是一个 End-to-End 的学习算法,以机器翻译为例,可以将法语翻译成英语。这样的模型也可以叫做 Seq2Seq 。
编码,就是将输入序列转化转化成一个固定长度向量。解码,就是讲之前生成的固定向量再转化出输出序列。
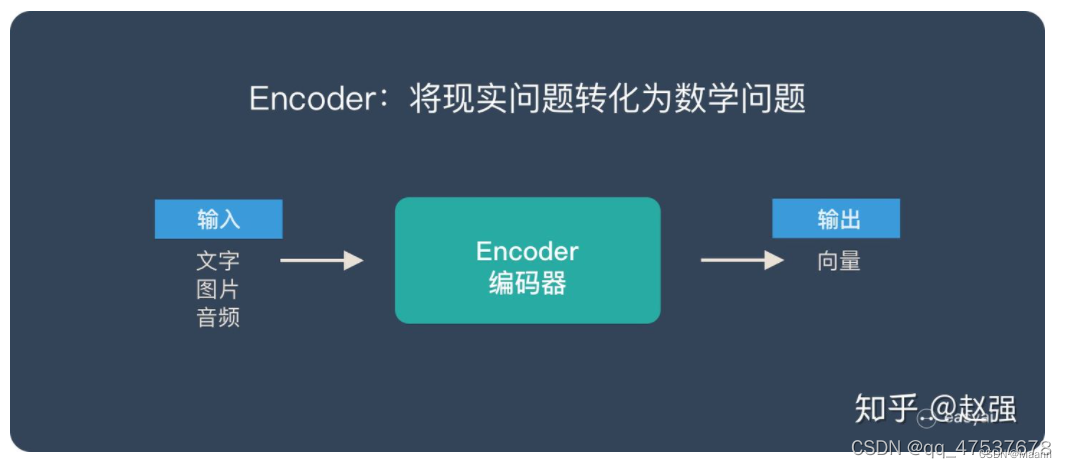
Encoder 又称作编码器。它的作用就是「将现实问题转化为数学问题」
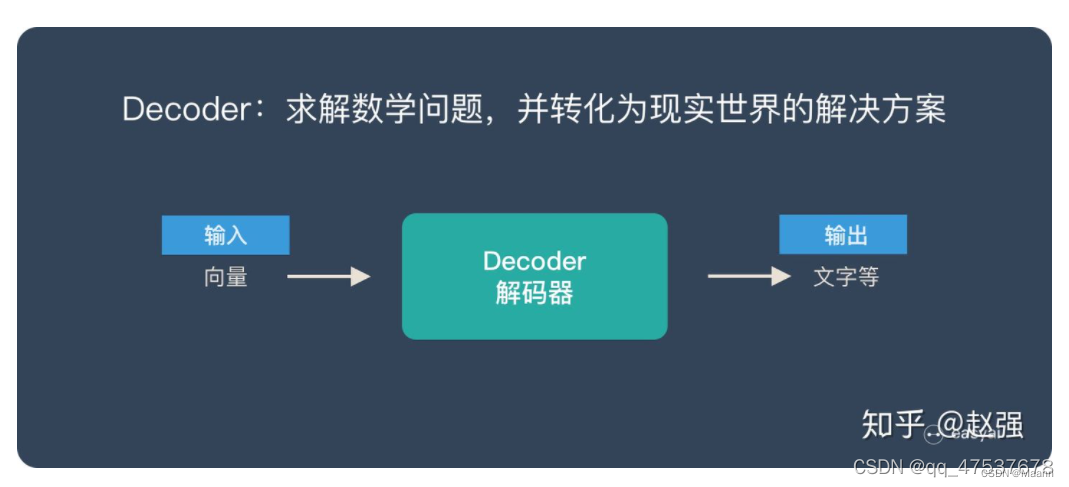
Decoder 又称作解码器,他的作用是「求解数学问题,并转化为现实世界的解决方案」
将两者连接起来:
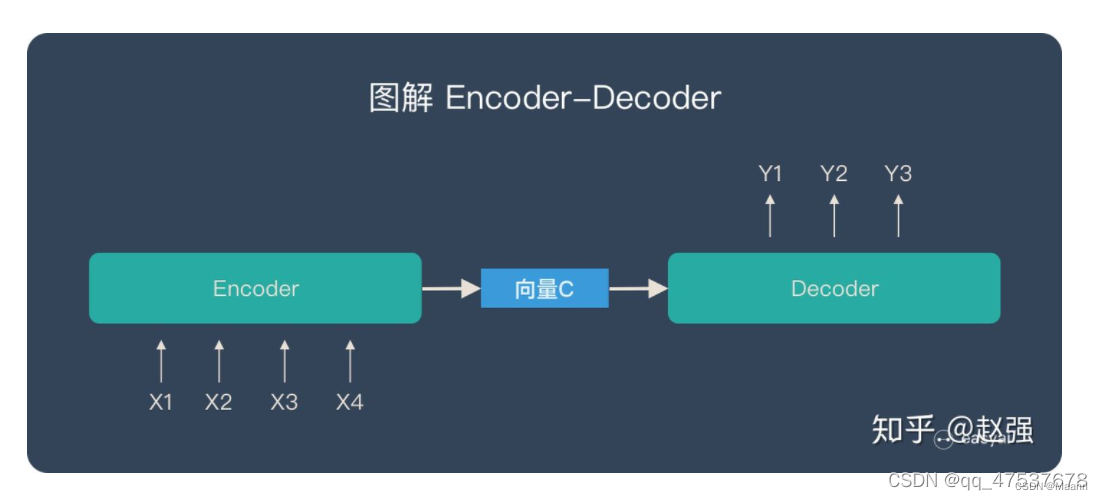
Seq2Seq模型
Seq2Seq ( Sequence-to-sequence 的缩写),就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
Seq2Seq 强调目的,不特指具体方法,满足输入序列,输出序列的目的,都可以统称为 Seq2Seq 模型。Seq2Seq 使用的具体方法基本都是属于 Encoder-Decoder 模型的范畴。
Seq2Seq模型是一类端到端(end-to-end)的算法框架,通过编码器-解码器架构来实现。
目标:给定长度为 m 的输入序列
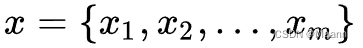
生成长度为 n 的目标序列
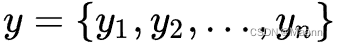
在机器翻译中,x 和 y 分别代表输入和输出的两个句子。
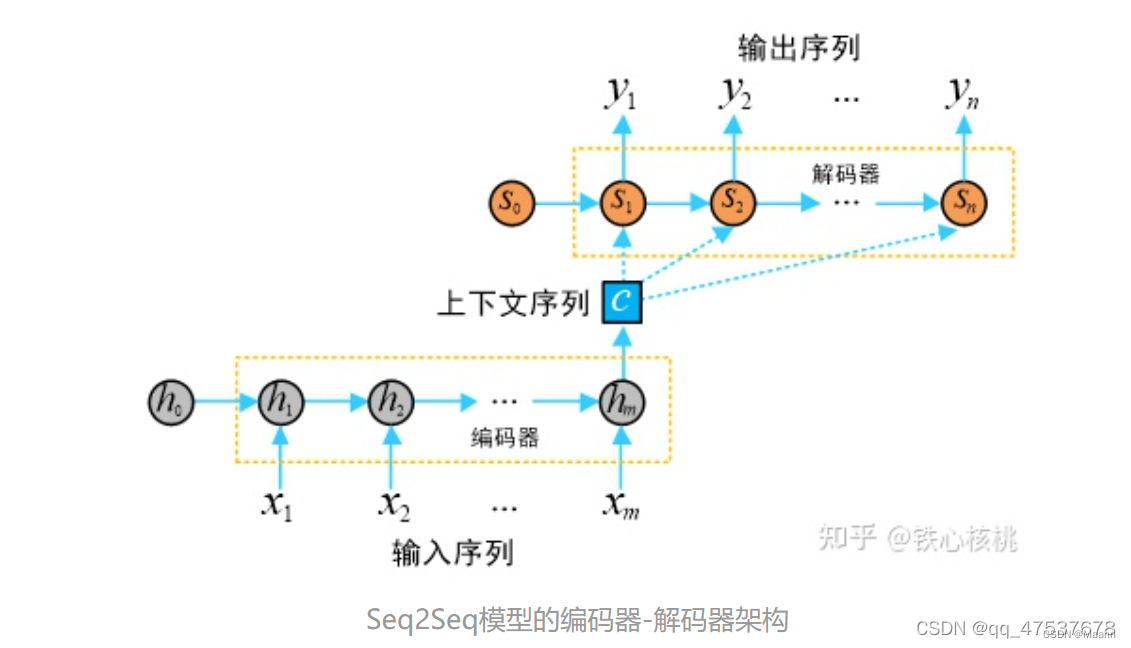
上图中:
编码器隐向量(hidden states):
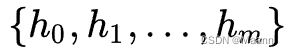
解码器隐向量:
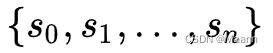
编码器实现将输入的任意长度的输入序列映射为固定长度的上下文序列 c,该上下文序列为输入序列的一个中间编码表示,表达为
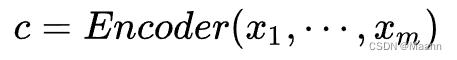
解码器用来将上述固定长度的中间序列c映射为变长度的目标序列作为最终输出 y。
-
问题一
当输入序列的长度过长时,上下文序列将无法表示整个输入序列的信息。
Seq2Seq模型理论上可以接受任意长度的序列作为输入,但是机器翻译的实践表明,输入的序列越长,模型的翻译质量越差。产生这一问题的原因在于无论输入序列的长短,编码器都会将其映射为一个具有固定长度的上下文序列c。 -
问题二
在生成每一个目标元素 [公式] 时使用的下文序列 [公式] 都是相同的,这就意味着输入序列 x 中的每个元素对输出序列 [公式] 中的每一个元素都具有相同的影响。
事实上在一个输入序列中,不同元素所携带的信息量是不同的,受到关注的程度也自然存在差异。
引入“注意力”机制
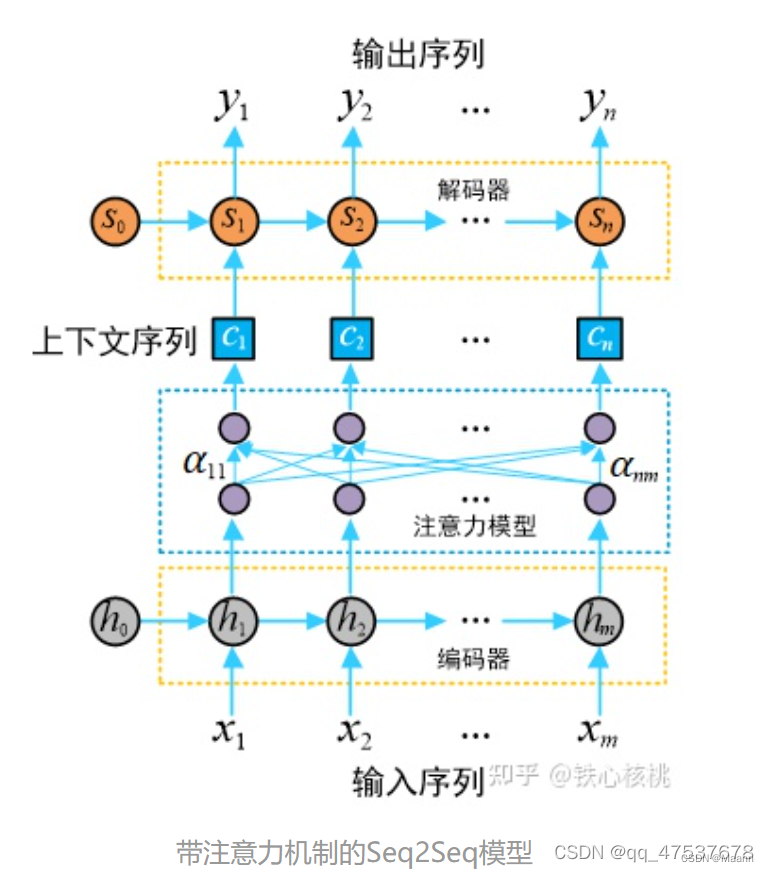
在注意力模型中,每一个上下文序列为编码器所有隐状态向量的加权和

将输入序列映射为多个下文序列 c1, c2, c3,…, cn,其中 ci 是与输出 yi 对应的上下文信息(其中 i = 1, 2, 3, …, n)。在解码器预测输出 yi 时,其结果依赖与之匹配的上下文序列 ci 以及其之前的隐状态,即
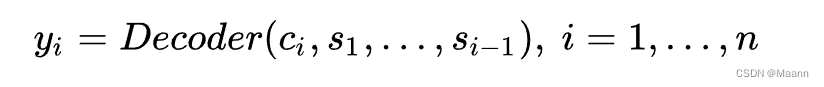
注意力模块可以视为是一个具有 m 个输入节点和 n 个输出节点的全连接神经网络。
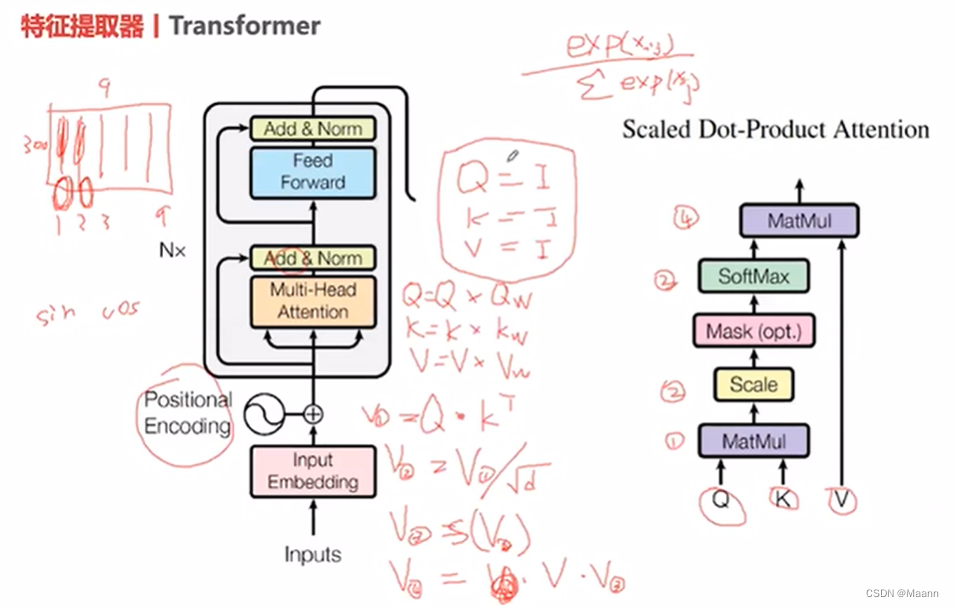
Transformer中的 Encoder-Decoder
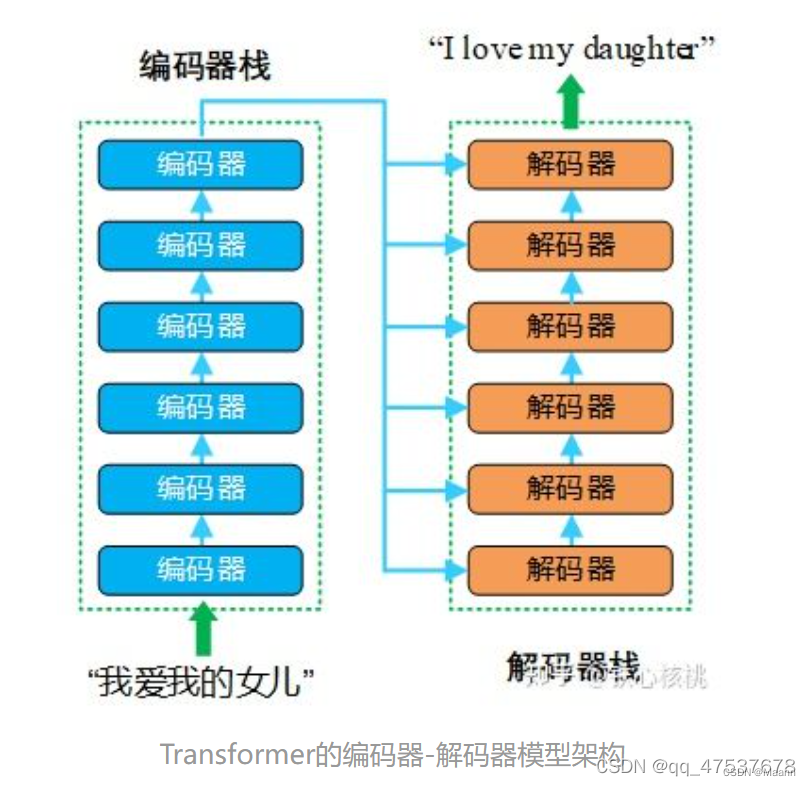
Transformer模型采用的也是编码器-解码器架构,但是在该模型中,编码器和解码器不再是 RNN结构,取而代之的是编码器栈(encoder stack)和解码器栈(decoder stack)(注:所谓的“栈”就是将同一结构重复多次,“stack”翻译为“堆叠”更为合适)。编码器栈和解码器栈中分别为连续 N(在 Transformer模型中 N = 6)个具有相同结构的编码器和解码器。
下图为Transformer模型的编码器-解码器架构示意图。
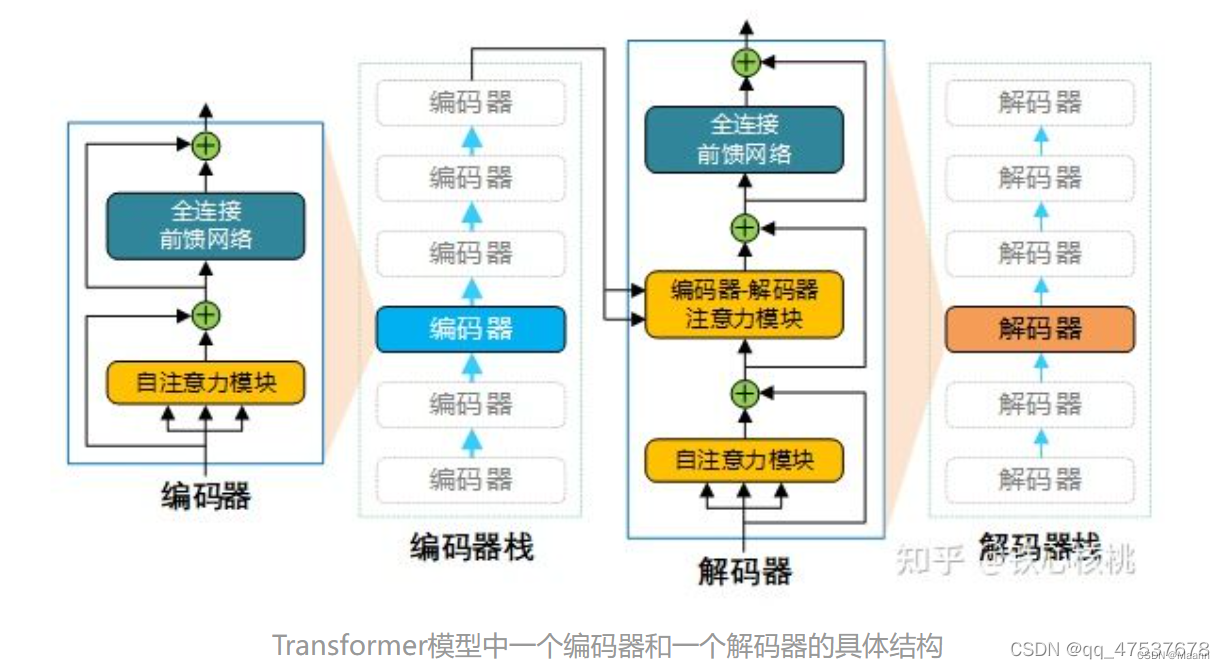
在每个解码器中,除了包含与解码器类似的自注意力模块和全连接前馈网络外,还额外在两个子网络之间添加了另外一个注意力模块(注:该注意力模块称为“编码-解码注意力”模块,同样也是采用多头注意力结构)。与编码器类似,解码器中的三个子网络也均具有残差连接,并且在每个残差合成其后都进行归一化操作。
- Transformer 中 Encoder 由 6 个相同的层组成,每个层包含 2 个部分:
Multi-Head Self-Attention
Position-Wise Feed-Forward Network (全连接层) - Decoder 也是由 6 个相同的层组成,每个层包含 3 个部分:
Multi-Head Self-Attention
Multi-Head Context-Attention
Position-Wise Feed-Forward Network