C++学习3

基础理论
讲右值、移动比较清楚容易入门的一篇文档
参考:https://zhuanlan.zhihu.com/p/606580366
左值:可以取地址的、有名字的值就是左值,左值可以放到赋值语句的左边(没有被const限定的情况下)。
右值:不能够取地址、没有名字的值就是右值。右值不能用&获取内存地址,而且生命周期短(只在定义的这一行语句内有效),在构造、使用后立刻就释放了。
左值引用:左值引用能绑定左值,但不能直接绑定右值,只有const的左值引用才可以绑定右值,不能修改。
std::string& r = std::string{"Hello"}; //error: non-const lvalue reference to type xxx
const std::string& cr = std::string{"Hello"}; // ok
右值引用:右值引用的定义方式为type&& r。右值引用可以直接绑定右值,但不能绑定左值。
std::string&& r = std::string{"Hello"}; // ok
std::string s{"hello"};
std::string&& rs = s; //error: rvalue reference to type 'basic_string<...>' cannot bind to lvalue of type 'basic_string<...>'
入参为左值的函数类型:
template<typename T>
void func(T& param) {cout << param << endl;
}
入参为右值的函数类型定义:
template<typename T>
void func(T&& param) {cout << param << endl;
}
右值引用本身是个左值:
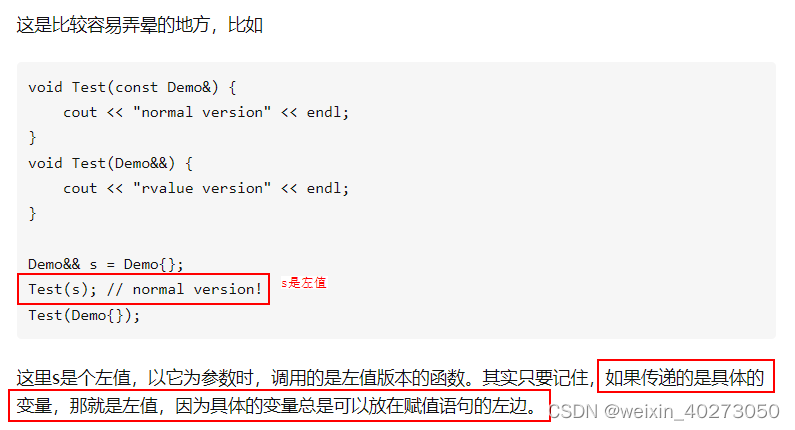
std::move的入参是个左值!
大神的无敌总结如下:

C++11中的default函数
https://blog.csdn.net/u013318019/article/details/113894153
对于C++ 11标准中支持的default函数,编译器会为其自动生成默认的函数定义体,从而获得更高的代码执行效率(比用户自定义的代码效率更高,哪怕是相同的空函数),也可免除程序员手动定义该函数的工作量。详细内容参考上面链接。
C++ override
https://blog.csdn.net/qq_41540355/article/details/120751543
(1) 这个关键字一般是加在子类中的;
(2) 主要目的是为了在子类(派生类)中提醒父类(基类)中被继承的虚函数必须要加上virtual关键字,否则没有被override的同名对象就会报编译失败。
(3) 设计virtual的目的是为了提醒编译器析构时除了析构父类,还要析构子类,防止内存泄露;
std::uniquer_ptr用法
参考:https://en.cppreference.com/w/cpp/memory/unique_ptr
常用用法:
std::unique_ptr<int> ptr = std::make_unique<int>(10);std::cout << *ptr << std::endl; // 打印10{std::unique_ptr<int[]> p(new int[3]); } // 析构时会自动释放所有三个new出来的int类型的指针数据;
std::make_unique会自己去系统申请内存,并且利用传入的数据(10)作为原始的构造参数;
std::make_unique可以自定义析构函数,由RAII帮助我们自动调用该析构函数:
std::ofstream("demo.txt") << 'x'; // prepare the file to read{using unique_file_t = std::unique_ptr<std::FILE, decltype(&close_file)>;unique_file_t fp(std::fopen("demo.txt", "r"), &close_file);if (fp)std::cout << char(std::fgetc(fp.get())) << '\\n';} // `close_file()` called here (if `fp` is not null)
全部完整用例如下:
#include <cassert>
#include <cstdio>
#include <fstream>
#include <iostream>
#include <memory>
#include <stdexcept>// helper class for runtime polymorphism demo below
struct B
{virtual ~B() = default;virtual void bar() { std::cout << "B::bar\\n"; }
};struct D : B
{D() { std::cout << "D::D\\n"; }~D() { std::cout << "D::~D\\n"; }void bar() override { std::cout << "D::bar\\n"; }
};// a function consuming a unique_ptr can take it by value or by rvalue reference
std::unique_ptr<D> pass_through(std::unique_ptr<D> p)
{p->bar();return p;
}// helper function for the custom deleter demo below
void close_file(std::FILE* fp)
{std::fclose(fp);
}// unique_ptr-based linked list demo
struct List
{struct Node{int data;std::unique_ptr<Node> next;};std::unique_ptr<Node> head;~List(){// destroy list nodes sequentially in a loop, the default destructor// would have invoked its `next`'s destructor recursively, which would// cause stack overflow for sufficiently large lists.while (head)head = std::move(head->next);}void push(int data){head = std::unique_ptr<Node>(new Node{data, std::move(head)});}
};int main()
{std::cout << "1) Unique ownership semantics demo\\n";{// Create a (uniquely owned) resourcestd::unique_ptr<D> p = std::make_unique<D>();// Transfer ownership to `pass_through`,// which in turn transfers ownership back through the return valuestd::unique_ptr<D> q = pass_through(std::move(p));// p is now in a moved-from 'empty' state, equal to nullptrassert(!p);}std::cout << "\\n" "2) Runtime polymorphism demo\\n";{// Create a derived resource and point to it via base typestd::unique_ptr<B> p = std::make_unique<D>();// Dynamic dispatch works as expectedp->bar();}std::cout << "\\n" "3) Custom deleter demo\\n";std::ofstream("demo.txt") << 'x'; // prepare the file to read{using unique_file_t = std::unique_ptr<std::FILE, decltype(&close_file)>;unique_file_t fp(std::fopen("demo.txt", "r"), &close_file);if (fp)std::cout << char(std::fgetc(fp.get())) << '\\n';} // `close_file()` called here (if `fp` is not null)std::cout << "\\n" "4) Custom lambda-expression deleter and exception safety demo\\n";try{std::unique_ptr<D, void(*)(D*)> p(new D, [](D* ptr){std::cout << "destroying from a custom deleter...\\n";delete ptr;});throw std::runtime_error(""); // `p` would leak here if it were a plain pointer}catch (const std::exception&) { std::cout << "Caught exception\\n"; }std::cout << "\\n" "5) Array form of unique_ptr demo\\n";{std::unique_ptr<D[]> p(new D[3]);} // `D::~D()` is called 3 timesstd::cout << "\\n" "6) Linked list demo\\n";{List wall;for (int beer = 0; beer != 1'000'000; ++beer)wall.push(beer);std::cout << "1'000'000 bottles of beer on the wall...\\n";} // destroys all the beers
}
构造函数可以抛出异常吗
https://blog.csdn.net/K346K346/article/details/50144947
可以,但是不建议这样。因为在构造函数中抛出异常,在概念上将被视为该对象没有被成功构造。
左值引用必须加const吗
左值引用不必须加const,但是如果你想保证函数内部不会修改这个左值引用所绑定的对象,那么可以加上const关键字。这样做的好处是可以让编译器在编译时检查是否有修改左值引用所绑定的对象的行为,从而提高代码的安全性。
lambda表达式
https://blog.csdn.net/gongjianbo1992/article/details/105128849
https://blog.csdn.net/chloe_zh1102/article/details/121871437
Lambda表达式的本质就是个函数对象!
Lambda表达式是C++11引入的一种新特性,它允许我们在需要函数对象的地方,使用一个匿名函数。Lambda表达式可以看作是一个匿名函数,它可以捕获上下文中的变量,并且可以像普通函数一样被调用。Lambda表达式的语法如下:
[capture list] (params list) mutable exception-> return type { function body }
其中,capture list表示捕获列表,params list表示参数列表,mutable表示可变性说明符,exception表示异常说明符,return type表示返回类型,function body表示函数体。
例如,下面的代码展示了如何使用Lambda表达式来定义一个简单的函数对象:
auto f = [] (int x, int y) -> int { return x + y; };
这个Lambda表达式定义了一个函数对象f,它接受两个整数参数x和y,并返回它们的和。
其中Lambda表达式的捕获列表指定了哪些变量可以在Lambda表达式内部访问,并且如何访问它们。捕获列表可以包含以下内容:
按值捕获:将变量的值复制到Lambda表达式内部。
按引用捕获:将变量的引用传递给Lambda表达式。
隐式捕获:根据上下文自动推断要捕获的变量。
例如,下面的代码展示了如何使用按值和按引用捕获:
int x = 10;
auto f = [x] () { return x; }; // 按值捕获
auto g = [&x] () { return x; }; // 按引用捕获
在C++中,lambda表达式的捕获列表和参数列表都是用来定义lambda函数的。捕获列表用于指定lambda函数可以访问的外部变量,而参数列表用于指定lambda函数的参数。它们之间的区别在于,捕获列表是用于访问外部变量,而参数列表是用于指定函数参数。
注意:Lambada表达式比一般函数指针强大的地方是可以捕获“本地变量”,(如this指针或其它变量等)!这可以让我们实现如下功能:类A中有一个funcA,私有成员变量member_A,funcA中会修改member_A;类B中提供函数注册接口RegisterFunc(funcA),并保存funcA;类B在合适的实际执行注册的函数funcA并更新member_A的数据;
如果不用Lambda表达式捕获this,用普通的函数指针会编译不过(编译时会告知函数类型不匹配)!
示例代码如下:
class ClassB {
public:using funcType = void(*)(int);void Register(std::function<void(int)> cbkFunc) {cbk = cbkFunc;}void Test() {cbk(count++);}private:std::function<void(int)> cbk;int count = 0;
};class ClassA {
public:ClassA():classb(ClassB()){classb.Register([this](int value) {a = value;});// 注意:如下代码会编译不过,类型不匹配// classb.Register(SetMember);}void SetMember(int value) {a = value;}void Excute(){classb.Test();}void print() {std::cout << "a=" << a << std::endl;}
private:int a = 0;ClassB classb;
};int main() {ClassA ca;ca.print();ca.Excute();ca.print();ca.Excute();ca.print();return 0;
}
总结:lambda可以让代码块可以像普通类型数据那样做为参数随意传递,并且提供合适的地方来保存捕捉变量的值。
C++获取变量类型、变量名称、类型名称
https://www.jiyik.com/tm/xwzj/prolan_5399.html
在C++中可以使用库中的typeid运算符或decltype(x)运算符来获取变量的类型。
(1) typeid(x).name():typeid运算符返回的类型信息是一个const std::type_info&类型的引用,因此需要使用type_info类提供的name()函数来获取类型名称。
(2) decltype(x):在C++11中引入了decltype(x)运算符,它将表达式转换为生成的结果的类型,也可以用来获取变量的类型。
(3) 区别:typeid(x).name()在运行时提供类型,decltype(x)在编译时提供类型。
#include <iostream>
#include <typeinfo>int main()
{int i = 0;double d = 0.0;std::cout << "i is of type " << typeid(i).name() << std::endl;std::cout << "d is of type " << typeid(d).name() << std::endl;std::cout << "type(i + d) is " << typeid(i + d).name() << std::endl;float ft = 4.8;decltype(ft) a = ft + 9.8;std::cout << typeid(a).name();return 0;
}
(4) 当子类继成虚类时,获取子类名称:
class Vclass {virtual void Collect() = 0;
};class Tclass : public virtual Vclass {Tclass() = default;void Collect() {std::cout << "Tclass: collect" << std::endl;}
};void main() {std::vector<std::shared_ptr<Vclass>> vect;vect.emplace_back(std::make_shared<Tclass>());for (const auto& it : vect) {std::cout << "typeid(it).name()=" << typeid(*it).name() << std::endl; // 会打印 "class Tclass"}
}
另外,上面"typeid(*it).name"用法会报编译告警/错误:
error: expression with side effects will be evaluated despite being used as an operand to ‘typeid’
原因是:人们大多认为typeid不计算表达式。对于返回多态对象的表达式,编译器必须生成代码来计算表达式。它是有效的C++代码,但人们可能不知道后果。当这种情况发生时,Clang会发出警告。
解决办法是获取共享指针中保存的原始指针,如下:
std::unique_ptr<Tclass> ptr_foo = std::make_unique<Tclass>();if(ptr_foo.get()){auto& r = *ptr_foo.get(); // 关键std::cout << typeid(r).name() << '\\n';
}
实战篇
模板类
https://zhuanlan.zhihu.com/p/402105825
https://blog.csdn.net/hsxyfzh/article/details/95797029
定义时,模板的定义和实现都放在头文件中,不能分离在.cpp和.h中,否则在链接的时候可能就会提示找不到外部符号。
// ClassicalTemplate.htemplate<class T>
class MyTemplate
{T Member;void SetMember(const T& InMember);T GetMemebr();
}template<T>
void MyTemplate<T>::SetMember(const T& InMember)
{Member = InMember;
}template<T>
T MyTemplate<T>::GetMemebr()
{return Member;
}
自定义数据库并提供迭代函数
#include <iostream>
#include <map>
#include <string>class Database {
public:class iterator {public:iterator(std::map<std::vector<std::string>, std::string>::iterator it) : it_(it) {}// 重载操作符 a++,如果数据库想实现边遍历边删除该重载是必须的iterator& operator++() { ++it_; return *this; //返回当前对象}// 重载操作符 ++aconst std::map<std::vector<std::string>, std::any>::iterator operator++(int){auto temp = iter;++iter;return temp; //该处返回的是一个值}// 1、因为值不能为左值,所以a++不能为左值(本质上是因为temp是个临时变量,这一行执行完就会被析构)。++a可以为左值。// 2、另外,a++返回的是加之前的值temp。++a返回的本对象(加之后的值)。这也就能解释为什么++a先自加,a++后自加。bool operator!=(const iterator& other) const { return it_ != other.it_; }std::pair<const std::vector<std::string>, std::string>& operator*() { return *it_; }private:std::map<std::vector<std::string>, std::string>::iterator it_;};// 支持传入的参数是左值void insert(const std::string key, const std::string value) {data_[key] = value;}// 支持传入的参数是左值引用void insert(const std::string& key, const std::string& value) {data_[key] = value;}// 支持传入的参数是右值引用void insert(const std::string&& key, const std::string&& value) {// 使用std::forward保留"右值引用"特性data_[std::forward<std::vector<std::string>>(key)] = std::forward<std::any>(data);}iterator begin() { return iterator(data_.begin()); }iterator end() { return iterator(data_.end()); }private:std::map<std::vector<std::string>, std::string> data_;
};int main() {Database db;db.insert({"key1"}, "value1");db.insert({"key2"}, "value2");db.insert({"key3"}, "value3");for (auto& [key, value] : db) {std::cout << "key:";for (auto it = key.begin(); it != key.end(); it++) {std::cout << *it << std::endl;}std::cout << "value:";std::cout << value << std::endl;// db.Delete(key); // 这种遍历方法不支持边遍历边删除,会导致程序崩溃(因为key从Db中被erase后,++操作非法)}for (auto it = db.begin(); it != db.end(); ) {auto& key = (*it).first;auto& value = (*it).second;std::cout << "key=";for (auto subit = key.begin(); subit != key.end(); subit++) {std::cout << *subit << std::endl;}std::cout << "value=" << value << std::endl;db.Delete(it++); // 这种边遍历边删除的方法才是正确的,OK}return 0;
}