pytorch进阶学习(四):使用不同分类模型进行数据训练(alexnet、resnet、vgg等)

课程资源:5、帮各位写好了十多个分类模型,直接运行即可【小学生都会的Pytorch】_哔哩哔哩_bilibili
目录
一、项目介绍
1. 数据集准备
2. 运行CreateDataset.py
3. 运行TrainModal.py
4. 如何切换显卡型号
二、代码
1. CreateDataset.py
2.TrainModal.py
3. 运行结果
一、项目介绍
1. 数据集准备
数据集在data文件夹下

2. 运行CreateDataset.py
运行CreateDataset.py来生成train.txt和test.txt的数据集文件。
3. 运行TrainModal.py
进行模型的训练,从torchvision中的models模块import了alexnet, vgg, resnet的多个网络模型,使用时直接取消注释掉响应的代码即可,比如我现在训练的是vgg11的网络。
# 不使用预训练参数# model = alexnet(pretrained=False, num_classes=5).to(device) # 29.3%''' VGG系列 '''model = vgg11(weights=False, num_classes=5).to(device) # 23.1%# model = vgg13(weights=False, num_classes=5).to(device) # 30.0%# model = vgg16(weights=False, num_classes=5).to(device)''' ResNet系列 '''# model = resnet18(weights=False, num_classes=5).to(device) # 43.6%# model = resnet34(weights=False, num_classes=5).to(device)# model = resnet50(weights= False, num_classes=5).to(device)#model = resnet101(weights=False, num_classes=5).to(device) # 26.2%# model = resnet152(weights=False, num_classes=5).to(device)同时需要注意的是, vgg11中的weights参数设置为false,我们进入到vgg的定义页发现weights即为是否使用预训练参数,设置为FALSE说明我们不使用预训练参数,因为vgg网络的预训练类别数为1000,而我们自己的数据集没有那么多类,因此不使用预训练。

把最后一行中产生的pth的文件名称改成对应网络的名称,如model_vgg11.pth。
# 保存训练好的模型torch.save(model.state_dict(), "model_vgg11.pth")print("Saved PyTorch Model Success!")4. 如何切换显卡型号
我在运行过程中遇到了“torch.cuda.OutOfMemoryError”的问题,显卡的显存不够,在服务器中使用查看显卡占用情况命令:
nvidia -smi
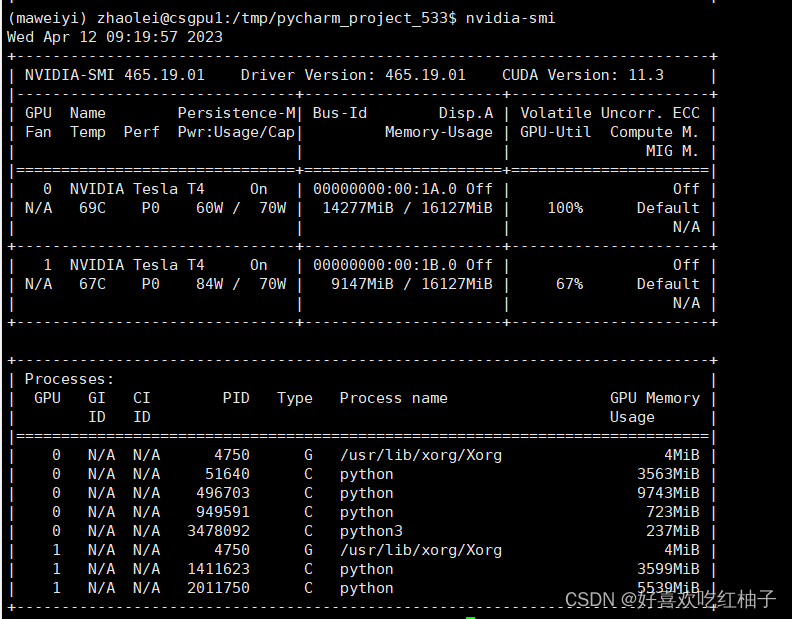
可以看到我一直用的是默认显卡0,使用情况已经到了100%,但是显卡1使用了67%,还用显存使用空间,所以使用以下代码来把显卡0换成显卡1.
# 设置显卡型号为1
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
二、代码
1. CreateDataset.py
'''
生成训练集和测试集,保存在txt文件中
'''
##相当于模型的输入。后面做数据加载器dataload的时候从里面读他的数据
import os
import random#打乱数据用的# 百分之60用来当训练集
train_ratio = 0.6# 用来当测试集
test_ratio = 1-train_ratiorootdata = r"data" #数据的根目录train_list, test_list = [],[]#读取里面每一类的类别
data_list = []#生产train.txt和test.txt
class_flag = -1
for a,b,c in os.walk(rootdata):print(a)for i in range(len(c)):data_list.append(os.path.join(a,c[i]))for i in range(0,int(len(c)*train_ratio)):train_data = os.path.join(a, c[i])+'\\t'+str(class_flag)+'\\n'train_list.append(train_data)for i in range(int(len(c) * train_ratio),len(c)):test_data = os.path.join(a, c[i]) + '\\t' + str(class_flag)+'\\n'test_list.append(test_data)class_flag += 1print(train_list)
random.shuffle(train_list)#打乱次序
random.shuffle(test_list)with open('train.txt','w',encoding='UTF-8') as f:for train_img in train_list:f.write(str(train_img))with open('test.txt','w',encoding='UTF-8') as f:for test_img in test_list:f.write(test_img)2.TrainModal.py
'''加载pytorch自带的模型,从头训练自己的数据
'''
import time
import torch
from torch import nn
from torch.utils.data import DataLoader
from utils import LoadDataimport os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'from torchvision.models import alexnet #最简单的模型
from torchvision.models import vgg11, vgg13, vgg16, vgg19 # VGG系列
from torchvision.models import resnet18, resnet34,resnet50, resnet101, resnet152 # ResNet系列
from torchvision.models import inception_v3 # Inception 系列# 定义训练函数,需要
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。for batch, (X, y) in enumerate(dataloader):# 将数据存到显卡X, y = X.cuda(), y.cuda()# 得到预测的结果predpred = model(X)# 计算预测的误差# print(pred,y)loss = loss_fn(pred, y)# 反向传播,更新模型参数optimizer.zero_grad()loss.backward()optimizer.step()# 每训练10次,输出一次当前信息if batch % 10 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")def test(dataloader, model):size = len(dataloader.dataset)# 将模型转为验证模式model.eval()# 初始化test_loss 和 correct, 用来统计每次的误差test_loss, correct = 0, 0# 测试时模型参数不用更新,所以no_gard()# 非训练, 推理期用到with torch.no_grad():# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)for X, y in dataloader:# 将数据转到GPUX, y = X.cuda(), y.cuda()# 将图片传入到模型当中就,得到预测的值predpred = model(X)# 计算预测值pred和真实值y的差距test_loss += loss_fn(pred, y).item()# 统计预测正确的个数correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= sizecorrect /= sizeprint(f"correct = {correct}, Test Error: \\n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \\n")if __name__=='__main__':batch_size = 8# # 给训练集和测试集分别创建一个数据集加载器train_data = LoadData("train.txt", True)valid_data = LoadData("test.txt", False)train_dataloader = DataLoader(dataset=train_data, num_workers=4, pin_memory=True, batch_size=batch_size, shuffle=True)test_dataloader = DataLoader(dataset=valid_data, num_workers=4, pin_memory=True, batch_size=batch_size)# 如果显卡可用,则用显卡进行训练device = "cuda" if torch.cuda.is_available() else "cpu"print(f"Using {device} device")'''随着模型的加深,需要训练的模型参数量增加,相同的训练次数下模型训练准确率起来得更慢'''# 不使用预训练参数# model = alexnet(pretrained=False, num_classes=5).to(device) # 29.3%''' VGG系列 '''model = vgg11(weights=False, num_classes=5).to(device) # 23.1%# model = vgg13(weights=False, num_classes=5).to(device) # 30.0%# model = vgg16(weights=False, num_classes=5).to(device)''' ResNet系列 '''# model = resnet18(weights=False, num_classes=5).to(device) # 43.6%# model = resnet34(weights=False, num_classes=5).to(device)# model = resnet50(weights= False, num_classes=5).to(device)#model = resnet101(weights=False, num_classes=5).to(device) # 26.2%# model = resnet152(weights=False, num_classes=5).to(device)print(model)# 定义损失函数,计算相差多少,交叉熵,loss_fn = nn.CrossEntropyLoss()# 定义优化器,用来训练时候优化模型参数,随机梯度下降法optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # 初始学习率# 一共训练1次epochs = 1for t in range(epochs):print(f"Epoch {t+1}\\n-------------------------------")time_start = time.time()train(train_dataloader, model, loss_fn, optimizer)time_end = time.time()print(f"train time: {(time_end-time_start)}")test(test_dataloader, model)print("Done!")# 保存训练好的模型torch.save(model.state_dict(), "model_vgg11.pth")print("Saved PyTorch Model Success!")3. 运行结果
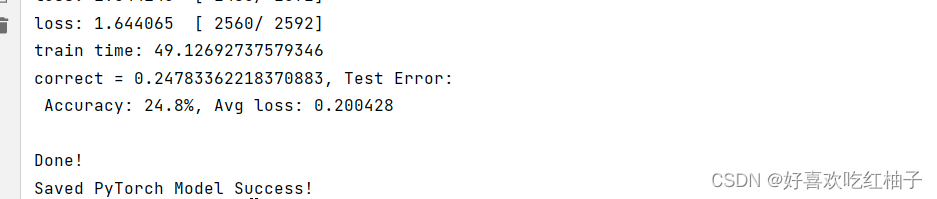
vgg11的运行结果:,可以看到最后的准确率是24.8%,因为没有用预训练模型,所以准确率很低。