Iceberg编译 及 与 Spark、Flink整合

一、准备工作
1.1、安装gradle
由于iceberg采用gradle来管理项目, 在编译之前需要安装gradle
检查jdk版本, gradle需要jdk8以及以上版本
wget https://services.gradle.org/distributions/gradle-8.1-rc-3-all.zip
unzip gradle-8.1-rc-3-all.zip
配置环境变量
vi /etc/profile
export PATH=$PATH:/opt/soft/gradle-8.1-rc-3/binsource /etc/profile查看版本
[root@chb2 gradle-8.1-rc-3]# gradle -vWelcome to Gradle 8.1-rc-3!Here are the highlights of this release:- Stable configuration cache- Experimental Kotlin DSL assignment syntax- Building with Java 20For more details see https://docs.gradle.org/8.1-rc-3/release-notes.html------------------------------------------------------------
Gradle 8.1-rc-3
------------------------------------------------------------Build time: 2023-04-04 09:58:41 UTC
Revision: 7eb689e589a42dcabd23aa8ccffa9a020c2010d2Kotlin: 1.8.10
Groovy: 3.0.15
Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021
JVM: 1.8.0_181 (Oracle Corporation 25.181-b13)
OS: Linux 3.10.0-957.el7.x86_64 amd64[root@chb2 gradle-8.1-rc-3]#
参考文档 https://gradle.org/install/
1.2、编译 iceberg
git clone iceberg
cd /opt/soft/iceberg/
gradlew build -x test -x integrationTest
1.3、单独编译 flink 依赖包
修改 flink 版本
cd /opt/soft/iceberg/
vi gradle.properties
# 修改内容
systemProp.defaultFlinkVersions=1.15
单独编译flink
cd /opt/soft/iceberg/flink
/opt/soft/iceberg/gradlew build -x test
1.4、单独编译 spark
cd /opt/soft/iceberg/
vi gradle.properties
# 修改内容
systemProp.defaultFlinkVersions=1.15
编译
/opt/soft/iceberg/gradlew build -x test
结果
[root@chb2 libs]# pwd
/opt/soft/iceberg/spark/v2.4/spark-runtime/build/libs
[root@chb2 libs]# ll
total 32564
-rw-r--r--. 1 root root 33320702 Apr 8 14:50 iceberg-spark-runtime-2.4-1.3.0-SNAPSHOT.jar
-rw-r--r--. 1 root root 6044 Apr 8 14:37 iceberg-spark-runtime-2.4-1.3.0-SNAPSHOT-javadoc.jar
-rw-r--r--. 1 root root 6044 Apr 8 14:37 iceberg-spark-runtime-2.4-1.3.0-SNAPSHOT-sources.jar
-rw-r--r--. 1 root root 6044 Apr 8 14:37 iceberg-spark-runtime-2.4-1.3.0-SNAPSHOT-tests.jar
[root@chb2 libs]#

这个包也可以不用自己编译, 官方文档中已经提供
二、Flink 与Iceberg 整合
2.1、配置
将下面的jar拷贝到 flink lib目录下
cp iceberg-flink-runtime-1.15-1.2.0.jar /opt/soft/flink-1.15.2/lib
2.2、创建catalog
Flink 支持使用 FLinkSQL语法创建catalog
2.2.0、语法说明
CREATE CATALOG <catalog_name> WITH ('type'='iceberg',`<config_key>`=`<config_value>`
);
type: 必须是iceberg(必选)catalog-type: 支持hadoop、hive、内置的catalogrest、以及自定义的catalog。catalog-impl: 自定义 catalog 实现 全限定类名,catalog-type未设置,必须设置这个。property-version:描述属性版本的版本号,用于向后兼容,防止属性格式的更改。当前的数据版本是1。(可选)cache-enabled: 是否启用目录缓存, 默认是true。 (可选)cache.expiration-interval-ms: 本地缓存catalog条目多长时间(单位毫秒),负值表示不会过期,不可以设置为0。默认值为-1。(可选)
2.2.1、创建 Hive catalog
CREATE CATALOG hive_catalog WITH ('type'='iceberg','catalog-type'='hive','uri'='thrift://chb2:9083','clients'='5','property-version'='1','warehouse'='hdfs://chb3:8020//user/hive/warehouse/iceberg'
);
报错
[ERROR] Could not execute SQL statement. Reason:
java.lang.NoSuchMethodException: Cannot find constructor for interface org.apache.iceberg.catalog.CatalogMissing org.apache.iceberg.hive.HiveCatalog [java.lang.NoClassDefFoundError: org/apache/hadoop/hive/metastore/api/NoSuchObjectException]
缺少 flink-sql-connector-hive-2.2.0_2.12-1.15.4.jar
2.2.2、创建 Hadoop catalog
CREATE CATALOG hadoop_catalog WITH ('type'='iceberg','catalog-type'='hadoop','warehouse'='hdfs://chb3:8020//user/hive/warehouse/iceberg_hadoop','property-version'='1'
);
2.3、DDL 操作
2.3.1、Create Database
CREATE DATABASE iceberg_db;
USE iceberg_db;
2.3.2、 Create Table
支持使用Flink的建表语句
PARTITION BY (column1, column2, ...): 配置分区,Flink还不支持隐藏分区COMMENT 'table document': 表注释WITH ('key'='value', ...)设置表配置,该配置将存储在Iceberg表属性中。 支持的配置属性
目前,它不支持计算列、主键和水印定义等。
1、非分区表
CREATE TABLE `sample` (id BIGINT COMMENT 'unique id',data STRING
);
2、非分区表
CREATE TABLE `sample_pt` (id BIGINT COMMENT 'unique id',data STRING
)
partitioned by (data);
Iceberg 支持隐藏分区,但Flink 不支持在列上通过函数进行分区,因此Flink DDL中无法支持隐藏分区。
3、CREATE TABLE LIKE 复制表结构
create table sample_pt_like like sample_pt;
2.3.3、ALTER TABLE
1、修改表属性
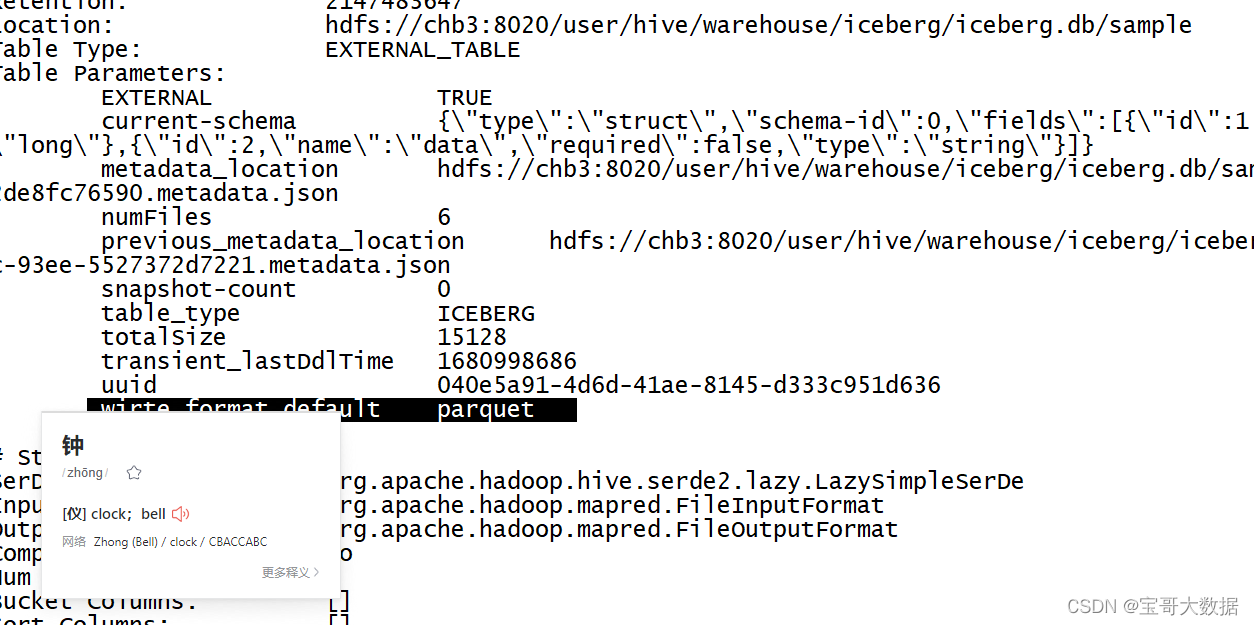
alter table sample set('wirte.format.default'='avro');
在 FlinkSQL Client 无法查看表的详细信息,对于hive_catalog中的表,可以在Hive Client 查看
hive> desc formatted sample;
2、重命名
alter table sample_pt rename to sample_pt_new;
2.3.4、删除表
drop table sample_pt_like;
2.4、写数据
2.4.1、Insert into
insert into sample values(1, 'chb'),(2, 'ling');
insert into sample_like select * from sample;
2.4.2、INSERT OVERWRITE (仅支持 Flink 的 Batch 模式)
streaming 模式不支持

Batch 模式

指定分区插入数据
-- 指定分区
insert overwrite sample_pt partition(data='b') select 4; -- 动态分区
insert overwrite sample_pt select * from sample_like;
2.4.3、UPSERT (format-verion=2必须是v2版本才支持upsert)
当 数据写入 v2 版本的Iceberg 表, Iceberg 支持 基于主键的 Upsert。有两种方式启动 Upsert
1、创建表时,指定表版本v2, write.upsert.enabled = true
CREATE TABLE `sample_v2` (`id` INT UNIQUE COMMENT 'unique id',`data` STRING NOT NULL,PRIMARY KEY(`id`) NOT ENFORCED
) with ('format-version'='2', 'write.upsert.enabled'='true');
插入数据
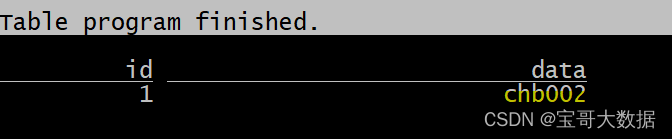
insert into sample_v2 values(1, 'chb001');
insert into sample_v2 values(1, 'chb002');
2、Hints
INSERT INTO tableName /*+ OPTIONS('upsert-enabled'='true') */
插入数据
CREATE TABLE `sample_v2_hints` (`id` INT UNIQUE COMMENT 'unique id',`data` STRING NOT NULL,PRIMARY KEY(`id`) NOT ENFORCED
) with ('format-version'='2');-- 插入数据
insert into sample_v2_hints /*+ OPTIONS('upsert-enabled'='true') */ values(2, 'chb002');
insert into sample_v2_hints /*+ OPTIONS('upsert-enabled'='true') */ values(2, 'chb003');

注意: OVERWRITE 和 UPSERT 不可同时设置。在 UPSERT 模式下,如果是分区表,分区字段必须是主键。
小文问题
2.5、使用SQL查询
Iceberg 在 Flink 中支持流式和批量读取。
2.5.1、批式读
SET execution.runtime-mode = batch;
SELECT * FROM sample;
2.5.2、流式读
-- 指定流模式
-- Submit the flink job in streaming mode for current session.
SET execution.runtime-mode = streaming;-- Enable this switch because streaming read SQL will provide few job options in flink SQL hint options.
SET table.dynamic-table-options.enabled=true;-- Read all the records from the iceberg current snapshot, and then read incremental data starting from that snapshot.
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;-- Read all incremental data starting from the snapshot-id '3821550127947089987' (records from this snapshot will be excluded).
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
2.5.3、FLIP-27 source for SQL
-- Opt in the FLIP-27 source. Default is false.
SET table.exec.iceberg.use-flip27-source = true;