SLAM中后端优化的技术细节总结与回答

SLAM中后端优化的技术细节
本文档主要收集总结了一些SLAM大佬们讲解后端优化中偏理论的技术细节的博客和回答以及一些学习教材。
Written by wincent
位姿估计以及李群相关的概述
Lie theory is by no means simple ———— 谎言理论绝不简单doge
- 《A micro Lie theory for state estimate on robotics》 written by Joan Sola,可以说这篇教材是为SLAM量身定做的李群李代数学习资料,本热阅读过后茅塞顿开,对后端优化和位姿估计的学习有巨大帮助,强烈推荐。他的另一篇力作《quaternion kinematics for the error-state Kalman filter》则是VO、VIO位姿估计的必读经典。
- 《Lie Groups 2D and 3D Tramsformations》
- 《机器人学中的状态估计》三维空间运动机理部分。讲述了李群李代数的引入动机、基本运算,并且引入概率论的思想,介绍了高斯过程中的位姿融合、位姿插值以及采样。后续的应用部分介绍了如何利用lie theory做位姿估计。
- 知乎shuyong.chen https://www.zhihu.com/people/shuyong-chen-31 。他讲解的关于位姿估计使用李群的动机和理论依据以及与卡尔曼滤波器结合的一系列文章非常细致深入。我认为这些阅读博客文章可以进一步加深对以上论文材料的学习理解。这里例举一篇文章:姿态估计引入李群和流形的动机与直觉
- 博客园JingeTUhttps://www.cnblogs.com/JingeTU 清华涂金戈 他有不少讲解位姿估计的博客,比较偏理论和公式推导 可以自己跟着推到一边用来对应SLAM框架中的代码实现。例举一文:Adjoint of SE(3) - JingeTU - 博客园 (cnblogs.com)
这里引用shouyoung.chen的总结做结尾
对姿态估计问题的理解,是一步步深入理解和发展的。最早,当卡尔曼滤波器被发明出来后,是直接估计的表示姿态的四元数的,这类卡尔曼滤波器,被称为加性滤波器。很快,NASA里的聪明人发现不对,旋转是群而不是向量,于是他们发明了乘性滤波器,就是误差状态卡尔曼滤波器,又称间接卡尔曼滤波器。但是长久以来,加性滤波器和乘性滤波器在实际项目中都工作正常。不得不说卡尔曼滤波器真是神奇的东西,够能容纳异类的。
这也因此没人说得清到底谁对谁错,直到本世纪初,Dr. F. Landis Markley 这位白胡子老爷爷用几篇论文明确地揭示了问题所在,才在姿态估计问题中确立了误差状态卡尔曼滤波器的正统地位。在姿态估计问题里,又是乘法又是群的,李群的应用自然浮出水面。过了一些年,就有人用李群重新解释和推导了误差状态卡尔曼滤波器。再过些年,Joan Solà 在写博士论文时,顺带写了一份教材,这就是有名的《Quaternion kinematics for the error-state Kalman filter》。如今他再战江湖,挑战李理论难懂不会用的困难,写出了最短小最易懂的入门教材,就是参考文献[1],A micro Lie theory for state estimation in robotics。本文就是他的教材的学习笔记。
近些年,对姿态估计问题的研究又有新的发展,或者说有新的灌水田地。前面应用李群,偏向应用群方面的知识,现在开始偏向应用流形方面的知识。参考文献[4]就是代表。
但是,姿态估计问题,包括卡尔曼滤波器,本质上是工程问题。工程上的一个小问题,就能轻易地让数学上的努力变得毫无作用。而加性滤波器似乎也没那么不堪。PX4 项目里的 ECL2 姿态估计器,就是对姿态四元数直接用EKF做估计,估计精度不输于其它间接的估计器,也成功地在成千上万个无人机里得到应用。卡尔曼滤波器既神奇又有黑暗的角落,例如Q & R矩阵,调参似乎比数学更重要。所以在这个世界里,始终还是调参侠的天下。
非线性最小二乘算法及滤波算法
正因有大千世界的不确定性才会产生优化
- 对非线性最小二乘法的综述《METHODS FOR NON-LINEAR LEAST SQUARES PROBLEMS》,这篇博客比较通俗易懂得叙述了论文的内容《 METHODS FOR NON-LINEAR LEASTSQUARES PROBLEMS》论文学习_wincent嘻嘻哈哈的博客-CSDN博客
- 《视觉SLAM十四讲》后端优化部分
- 《机器人学中的状态估计》二三四章,主要介绍了滤波方法。虽然是讲解不那么时髦的滤波方法,但是书中的思想以及严格的数学证明是入门后端优化必不可少的学习资料。经过学习也会深刻认识到滤波方法和优化方法千丝万缕的联系以及最本质的区别。
我本人认为学习优化的算法时不仅仅是学习数值优化的方法,更应该用概率的思想来理解各种各样的状态估计算法。比如最小二乘算法实际上就是去最大化我们估计的变量的后验概率
滑动窗口法中的稀疏化和边缘化
如何舍弃也是一门艺术
- 贺一佳论述稀疏化和边缘化:SLAM中的marginalization 和 Schur complement_slam 边缘化_白巧克力亦唯心的博客-CSDN博客
- 贺一佳以DSO为例讲解Sliding Window: DSO 中的Windowed Optimization_白巧克力亦唯心的博客-CSDN博客 。
个人认为以上两篇博客已经比较完整的介绍了marginalization和Schur complement,包含了比较直观的解释以及数学推导。代码部分的话每个框架都有不同的边缘化策略以及先验能量的计算方法,需要具体框架具体分析。
FEJ技术学习资料
SLAM可以不做好边缘化,无非就是丢失一些先验信息,导致优化精度不是那么高。而如果做不好FEJ,SLAM系统一定会随着运行逐渐崩溃。
-
知乎关于FEJ的讨论:如何理解SLAM中的First-Estimates Jacobian? - 知乎 (zhihu.com)
-
黄国权三篇基于EKF-SLAM论述FEJ技术以及分析证明SLAM系统一致性问题。他通过严谨的数学推导证明了不采用FEJ的SLAM系统存在不一致性,不可观的变量可观了,即优化增量会在实际上不存在的"维度"上产生更新并且不影响总的能量项。
- 《A First-Estimates Jacobian EKF for Improving SLAM Consistency》
- 《Analysis and Improvement of the Consistency of Extended Kalman Filter based SLAM》
- 《Generalized Analysis and Improvement of the Consistency of EKF-based SLAM》
事实证明虽然论述FEJ是在EKF-SLAM基础上进行的,但是FEJ同样也适用于优化方法的SLAM。只是两者的Jacobian含义有所不同。
零空间正交化
指向前方真正的路
-
不是那么严谨的以DSO为例子讲解零空间正交化DSO(5)——零空间的计算与推导_a first-estimates jacobian ekf for improving slam _无人的回忆的博客-CSDN博客
-
也是一篇以DSO为例讲解零空间正交化的博客:DSO零空间与尺度漂移_林突破的博客-CSDN博客
-
零空间正交化的集大成博客:一文看尽4种SLAM中零空间的维护方法_无人的回忆的博客-CSDN博客
和老师的交流
这一部分主要是记录我在学习Direct Sparse Odometry时向老师请教问题时老师的回答。由于是在微信上进行交流,所以可能看起来不是那么优雅和严谨。我目前跟随Sen Zhang老师进行SLAM的学习,老师前不久从悉尼大学博士毕业(师从dacheng Tao),2022年一年发表了五篇计算机视觉的顶会,其中两篇为ECCV,所以老师的回答还是有一定的参考价值的,并且回答时非常认真负责。
-
1、零空间正交化和FEJ是怎么回事呢?
老师回答:是这样的,零空间主要表示的是优化过程中我们没有唯一解,有一些不可观测的变量会影响最终结果,这些不可观测的变量值可以不断改变,但是最终优化的cost function可以不变,这种解的不确定性会带来问题。具体的说,在对slam做BA的时候,我们要求解变量的增量x,通过Hx=bHx=bHx=b来解,H=JJTH=JJ^TH=JJT, b=−Jfb=-Jfb=−Jf (用Gauss-Newton method)。如果H是不可逆的,那么我们没有唯一解,举个例子,我们求出了一个xxx满足Hx=bHx=bHx=b,但是在HHH不可逆的时候,Hx′=0Hx'=0Hx′=0也有解,假设求出一个解是x′x'x′,那么不止是我们求出的xxx可以满足Hx=bHx=bHx=b, 任意的x+kx′x + kx'x+kx′也可以满足:H(x+kx′)=Hx+kHx′=Hx+0=Hx=bH(x+kx')=Hx + k Hx' = Hx + 0 = Hx = bH(x+kx′)=Hx+kHx′=Hx+0=Hx=b.所以我们实际上有无穷多个解,但优化结果只是随机pick了其中一个解(根据我们给定的优化初始值)。这无穷多个解是因为Hx′=0Hx'=0Hx′=0有非零解,所以这个非零解乘以任意常数加到一个Hx=bHx=bHx=b的任意一个解里,都还是Hx=bHx=bHx=b的一个解。所有Hx′=0Hx'=0Hx′=0的解就构成了所谓的零空间。
这儿就有一个问题,我们每一次优化得到的kx′kx'kx′可能是不一样的,是random的,取决于我们优化的初始值,所以我们要消除这种randomness的影响,具体有两个,其中第一个就是FEJ,就是我们在计算HHH和bbb的时候,其实只需要计算当前state的Jacobian,kx′kx'kx′隐式包含在这个Jacobian里面,所以我们在同一次优化的不同迭代里,会固定这个Jacobian(用初始的,所以叫first-estimate),这样就能保证在这一次优化中,我们所以是随机在无穷多个解中pick了一个x+kx′x+kx'x+kx′,但我们保证了所有迭代用的都是同一个kx′kx'kx′。
还有一个是在边缘化(Marginalization)的时候,我们用要边缘化的变量来最后一次update要保留的变量的值,这儿有一个问题是要边缘化的变量其实有自己的一个random的kx′kx'kx′,当被它的值被用来update其他变量以后,在未来再度对被保留的变量进行优化的时候,新的kx‘kx‘kx‘可能和当时被边缘化的变量的kx’kx’kx’是不一样的,这也会造成误差,这儿处理的方式是,在计算update时,我们先求解零空间(所有可能的kx‘kx‘kx‘),然后我们只update解空间里和零空间正交(orthogonal)的部分,这样不管零空间怎么变,都不会影响到这部分正交的部分。
然后这个零空间对应到slam里是有实际物理意义的,就是为什么H不可逆。比方在单目slam里,我们没有尺度的信息,因为在从三维空间投影到相机的像素平面的时候,我们对深度进行了归一化。来一个具体的例子,这种造成的后果就是我们优化的深度和相机位移是没有尺度信息的,比方在直接法里,我们的cost function是光度损失。
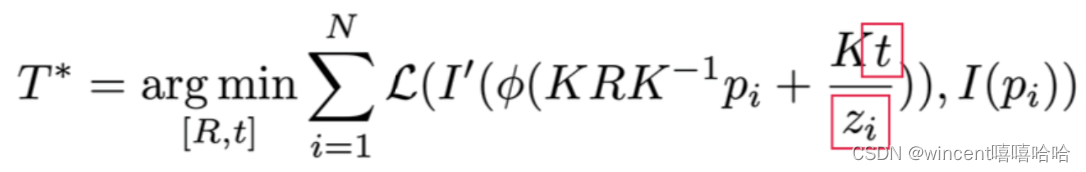
位移ttt和深度ziz_izi在一个除法的分子分母里,意味着分子分母同时乘以一个任意常数,最后的cost function的值都是一样的。所以只要位移和深度的比例是固定的,那么具体是几米几十米那从优化的角度都是一样的,具体的数值取决于你优化时候给的初始值,这是random的。所以在同一次优化的不同迭代里,状态量变了,对应的深度的绝对值可能就变了,原来一个点的深度给了1m,后面的迭代可能对应1.5m,再后面可能0.8m,对于每一步自己来说都没问题,但你不断基于这做迭代的时候前后就不一致了,优化很容易出问题,或是边缘化的时候,对于一个三维位置,你丢掉的变量那时给的深度是1m,后续来了新的变量,它们在优化时随机得到深度是1.5m,各自都是对的,但是前后就不一致了,放在一起优化就会出问题。单目slam除了尺度,还有一组不可观测的量是相机的绝对位姿,我们求的一般是关于第一张相机图像坐标系的相对位姿,所以整个序列同时旋转平移,这个相对位姿都不变,所以单目slam一共有7个不可观测量(3个是旋转,3个是平移,1个是尺度)。
-
2、SLAM中的不可观测量和零空间应该有紧密的联系吧?
老师回答:不管这个不可观测的变量可以有很多不同的取值,但最后我们可以得到同样的cost。并且不同的不可观测变量的取值也会影响到可观测变量的取值,因此每一次优化出来的可观测变量都会implicitly pick了一个随机的不可观测变量的值,我们需要在优化过程中保证所有迭代步骤用的是同一个不可观测变量的值,不然数值之间就没有直接的对应的关系了,我们求的增量加上去就不对了。不可观测变量有点像多个自变量对应了一个因变量 不是一对一关系了 从矩阵上来说就是维度降低了 秩小了 如果不严谨的对应一下的话 我感觉这个就和零空间的表现很像。零空间不就是Hx=0有非零解嘛 H不可逆说明H里有线性相关的成分,不是满秩的,也就是维度会变低。
研究发展脉络是大家先研究slam系统里的可观性问题,最早是在filter based system,不需要优化,但需要对每一次运动方程和观测方程进行Gaussian近似,也需要Jacobian,然后针对可观性不可观性提出FEJ。后来方法从filter变成了optimization,这儿的不可观性就对应到Hx=b的零空间,然后类似的因为过程中用了GN或LM来优化只影响Jacobian,所以依然可以用之前的FEJ方法,只是在marginalization的时候需要额外考虑(只更新orthogonal分量)。
零空间问题本质就是状态量的可观性。这里可以参考现代控制理论中的状态空间方程。
-
3、边缘化怎么理解?和Schur Complement的关系又是什么?
额是这样的,schur complement(SC)和marginalization(marg)不是一回事,SC是一种求解Hx=b的运算方法,就像在不同的方法里我们都用到了微积分,但微积分不是某一个方法的别名。
在优化里,为了加速优化和利用H的稀疏性,咱们把稀疏和不稀疏的部分分开来,SC在这里的作用是可以把两个稀疏和不稀疏对应的x分开来求解,这样稀疏的部分求解起来很快,SC的主要作用是可以把含有多个变量的vector x中的变量给拆分开来分别计算,在优化里,是为了把x中稀疏和不稀疏的变量拆分开来。
在marg里,所谓边缘化是,随着相机不断运动,我们会有越来越多的变量(特征点,相机位姿等),系统里要优化的变量太多咱们机器就算不动了,所以我们一般maintain一个sliding window,固定变量的个数上限,超过了就丢弃最早的一些变量,这个变量丢弃的环节叫做边缘化,(把那些要丢的变量的给边缘化了),但是我们不是直接丢弃,因为变量之间是有correlation的,要丢弃的这些变量里也含有我们要保留的变量的信息,我们希望把这些信息给抽取出来,加到我们要保留的变量上。所以我们求解Hx=b,但在marg里我们把x拆分成要丢弃(marg)的变量,和要保留的变量,然后分别计算他们的increment x(其实只需要计算要保留的变量的increment),然后更新要保留的变量的值,相当于把要丢弃的变量的信息给加到要保留的变量里,然后之后优化过程就不考虑这些被边缘化了的变量了。
所以SC只是一个求解Hx=b的方法,拆分x成两个部分,然后分别求解其增量,区分在于怎么根据我们不同目的来拆分x。(1)在正常优化过程中,我们拆分x为稀疏和不稀疏的部分,来加速运算(2)在边缘化过程中,我们拆分x为要丢弃和要保留的部分,从而用要丢弃的信息来最后一次更新要保留的变量。
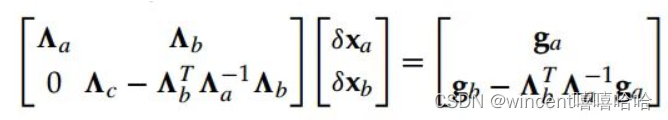
这是SC的形式。从概率分布的角度来看,marginalizaiton也有另一种理解,要丢弃的变量b和要保留的变量a原本我们维护一个他们的joint distribution P(a, b),现在我们希望得到一个把b给marginalize掉之后a的marginal distribution P(a | b)。假设是multivariate Gaussian,我们可以得到
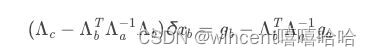
可以发现这个条件概率分布中协方差矩阵的形式和SC分解之后右半边式子形式是一样的,如下图,非常神奇。
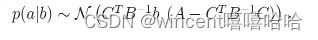
协方差就是两个变量间的关系的一个度量,SC是拆分两个变量,然后先算一个,再用之前的结果算另一个,在后者的过程中肯定要利用两个变量间的关系才能使用起来之前的结果,一般L2的损失都会有Gaussian distribution的对应关系,(btw,L1对应Laplacian distribution),所以这儿两个变量间的关系度量“happen to be” 协方差也说得通。
-
4、为什么L2损失下会有高斯分布的假设呢?
在优化的时候对Gaussian distr求max其实等价exp里面的平方项求min,也就是说最小二乘平方的L2形式实际上是从高斯分布的指数项为二次方推到过来的(详见机器人学中的状态估计)。所以很多形式能对应起来,对用L2的优化问题基本都能找到基于Gaussian的概率分布下的解释和理解。