如何使用spacy工具包实现词性标注

目录
1 问题描述:
1.1 基础知识介绍:
2 问题解决:
2.1 使用spacy,拆分单词的标注
2.2 使用spacy,不拆分单词的标注
1 问题描述:
1.1 基础知识介绍:
spaCy 是一个 Python 和 CPython 的 NLP 自然语言文本处理库,可满足一些常见的自然语言处理任务。
spacy工具包的使用,请参见另一篇博客:Click Here
如何使用spacy工具包,实现将单词拆分,以及不拆分单词的标注(以tag或pos为例)
2 问题解决:
spacy工具包可以满足中文、英文等语言的词性标注,此处仅以英文为样例
2.1 使用spacy,拆分单词的标注
使用spacy工具包,实现英文词性标注的代码实现:
import spacynlp = spacy.load("en_core_web_sm")# 给定一个英文句子
sentence = "This is a test sentence for POS tagging X-T ."# 对句子进行分析
doc = nlp(sentence)# 遍历每个 token,并输出它的文本和词性标注
for token in doc:print(token.text, token.pos_, token.tag_)
上述代码运行结果为:

结果分析:
token.text, token.pos_, token.tag_分别表示句子中的单词,单词对应的词性,单词对应的标签。从运行结果来看,spacy工具包自带分词工具,虽然英文文本是以空格为分隔符,但是spacy会使用自带的分词规则,将“X-T”单词拆分成“X”,“-”和“T”。
2.2 使用spacy,不拆分单词的标注
使用spacy工具包,实现英文以空格为分隔符,不将单词额外再进行拆分的标注,代码实现如下:
import spacy# 加载英文模型
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])# 定义一个不对单词进行拆分的Tokenizer
class WhitespaceTokenizer:def __init__(self, vocab):self.vocab = vocabdef __call__(self, text):words = text.split(' ')return spacy.tokens.Doc(self.vocab, words=words)nlp.tokenizer = WhitespaceTokenizer(nlp.vocab)# 输入英文句子
text = 'This is a test sentence for POS tagging X-T .'# 创建一个Doc对象
doc = nlp(text)# 获取每个单词的词性
for token in doc:print(token.text, token.pos_, token.tag_, )
上述代码运行结果为:
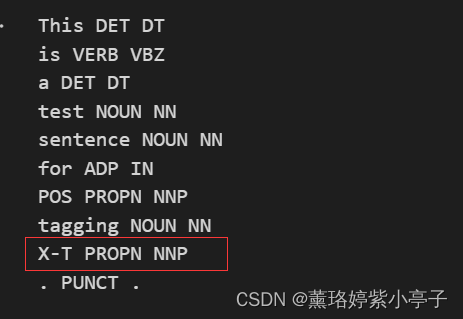
可以看出,仅以空格为分隔符实现标注,并未将单词再额外拆分。