机器学习 探索性数据分析

文章目录
数据探索性分析(EDA)目的主要是了解整个数据集的基本情况(多少行、多少列、均值、方差、缺失值、异常值等);通过查看特征的分布、特征与标签之间的分布了解变量之间的相互关系、变量与预测值之间的存在关系;为特征工程做准备。
1. 数据总览
使用的数据是广告点击率预估挑战赛数据集
读取数据集:
path = r'E:\\数据集\\竞赛数据\\广告点击率预估挑战赛.csv'
df = pd.read_csv(path, encoding='utf-8')
1.1 查看数据的维度
df.shape# (391825, 13)
共有391825条数据,13个列
1.2 查看列的数据类型
查看所有列的数据类型
# 查看所有列的数据类型
df.dtypes
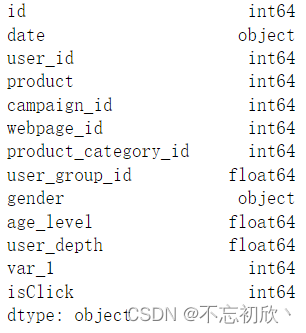
查看某一列的数据类型
# 查看某一列的数据类型
df['gender'].dtype, df['id'].dtype# (dtype('O'), dtype('int64'))
1.3 查看索引
查看行索引:
df.index# RangeIndex(start=0, stop=391825, step=1)
查看列索引:
df.columns"""
Index(['id', 'date', 'user_id', 'product', 'campaign_id', 'webpage_id','product_category_id', 'user_group_id', 'gender', 'age_level','user_depth', 'var_1', 'isClick'],dtype='object')
"""
1.4 获取数据值
# 两者均返回numpy类型数组
df.values 或者 df.to_numpy()"""
array([[0, '07-02 00:00', 0, ..., 3.0, 0, 0],[1, '07-02 00:00', 1, ..., 2.0, 0, 0],[2, '07-02 00:00', 1, ..., 2.0, 0, 0],...,[391822, '07-06 23:59', 135658, ..., 3.0, 1, 0],[391823, '07-06 23:59', 39562, ..., 3.0, 0, 0],[391824, '07-06 23:59', 39562, ..., 3.0, 0, 0]], dtype=object)
"""
1.5 数据集相关信息概览
# 包含了所有列的列名及其数据类型,以及每列中非空值的数量,数据大小,索引等
df.info()"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 391825 entries, 0 to 391824
Data columns (total 13 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 id 391825 non-null int64 1 date 391825 non-null object 2 user_id 391825 non-null int64 3 product 391825 non-null int64 4 campaign_id 391825 non-null int64 5 webpage_id 391825 non-null int64 6 product_category_id 391825 non-null int64 7 user_group_id 376082 non-null float648 gender 376082 non-null object 9 age_level 376082 non-null float6410 user_depth 376082 non-null float6411 var_1 391825 non-null int64 12 isClick 391825 non-null int64
dtypes: float64(3), int64(8), object(2)
memory usage: 38.9+ MB
"""
1.6 查看数据的统计信息
查看表中数值列的最大值,最小值,均值,标准差, 四分位数,中位数等
查看所有列的数据统计信息:
df.describe()
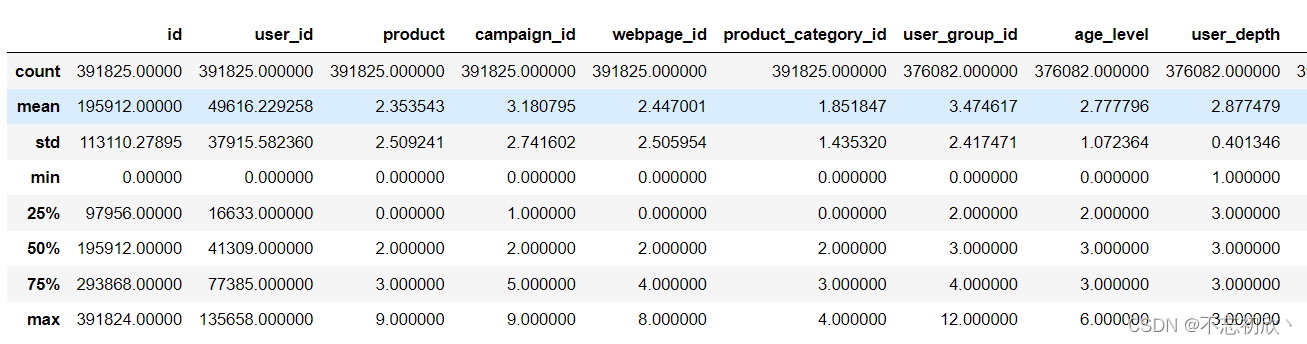
查看age_level列的数据统计信息:
df.age_level.describe()"""
count 376082.000000
mean 2.777796
std 1.072364
min 0.000000
25% 2.000000
50% 3.000000
75% 3.000000
max 6.000000
Name: age_level, dtype: float64
"""
查看指定列,指定占比的统计信息:
# percentile list
perc =[.20, .40, .60, .80] df.age_level.describe(percentiles = perc, include = include) """
count 376082.000000
mean 2.777796
std 1.072364
min 0.000000
20% 2.000000
40% 2.000000
50% 3.000000
60% 3.000000
80% 4.000000
max 6.000000
Name: age_level, dtype: float64
"""
1.7 查看前3行数据
# 默认显示前5行数据
df.head(3)# 后5个样本
df.tail(5)# 随机抽取5个样本
df.sample(5)

2. 缺失值查看与处理
2.1 缺失值查看
缺失值查看:
# 查看整个数据集的值是否为缺失值
df.isnull() # 查看某一列的值是否为缺失值
df['age_level'].isnull()
查看每列缺失值的个数:
# 查看每列的空值,并根据空值个数进行大小排序
data.isnull().sum().sort_values(ascending=False)"""
user_group_id 15743
gender 15743
age_level 15743
user_depth 15743
id 0
date 0
user_id 0
product 0
campaign_id 0
webpage_id 0
product_category_id 0
var_1 0
isClick 0
dtype: int64
"""
查看每列的缺失值占比:
# 统计不同类别的缺失值占比
((df.isnull().sum())/df.shape[0]).sort_values(ascending=False).map(lambda x:"{:.2%}".format(x))"""
user_group_id 4.02%
gender 4.02%
age_level 4.02%
user_depth 4.02%
id 0.00%
date 0.00%
user_id 0.00%
product 0.00%
campaign_id 0.00%
webpage_id 0.00%
product_category_id 0.00%
var_1 0.00%
isClick 0.00%
dtype: object
"""
可视化含有缺失值的列的缺失占比:
missing = df.isnull().sum()/len(df)
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
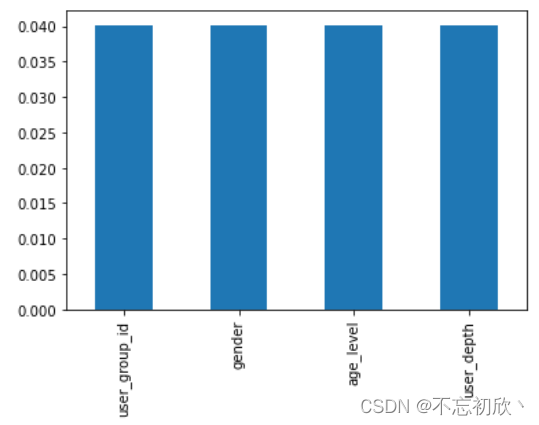
获取缺失值占比大于4%的列:
missing_df = ((df.isnull().sum())/df.shape[0])
missing_columns = (list(missing_df[missing_df >0.04].index))
missing_columns# ['user_group_id', 'gender', 'age_level', 'user_depth']
2.2 缺失值处理
pandas.DataFrame.fillna(value = None,method = None,inplace = False)
- value:用于填充的值,可以是具体值、字典和数组,不能是列表;
- method:填充方法,有 ffill 和 bfill 等;ffill:填充上一个值;bfill :填充下一个值
- inplace:默认无False,如果为True,则将修改此对象上的所有其他视图。
# 填充上一个值
df['gender'].fillna(method="ffill", inplace=True) # 填充下一个值
df['gender'].fillna(method="bfill", inplace=True) # 填充具体值
df['gender'].fillna(value="Female", inplace=True) # 众数填充
df['age_level'].fillna(df['age_level'].mode(), inplace=True)# 均值填充
df['age_level'].fillna(df['age_level'].mean(), inplace=True)# 中位数填充
df['age_level'].fillna(df['age_level'].median(),inplace=True)# 将负值(-10)替换为空值,然后空值替换为均值
data['age_level'].replace(-10, np.nan, inplace=True)
data['age_level'].replace(np.nan, data['age_level'].mean(), inplace=True)
pandas.DataFrame.dropna(axis, how= None, thresh, subset, inplace)
- axis: default 0指行,1为列
- how: {‘any’, ‘all’}, default ‘any’指带缺失值的所有行;'all’指清除全是缺失值的
- thresh: int,保留含有int个非空值的行
- subset: 对特定的列进行缺失值删除处理
- inplace: 这个很常见,True表示直接在原数据上更改
# 删除所有空值对应的行
df.dropna(inplace=True)# 删除指定列空值对应的行
df['age_level'].dropna(inplace=True)# 删除特定列的空值对应的行
subset = ['age_level', 'gender']
df.dropna(subset=subset, inplace=True)
pandas.DataFrame.drop(labels,axis=0,level=None,columns=None, inplace=False,errors=’raise’)
- labels:接收string或array,代表要删除的行或列的标签(行名或列名)。无默认值
- axis:接收0或1,代表操作的轴(行或列)。默认为0,代表行;1为列。
- level:接收int或索引名,代表标签所在级别。默认为None
- inplace:接收布尔值,代表操作是否对原数据生效,默认为False
- errors:errors='raise’会让程序在labels接收到没有的行名或者列名时抛出错误导致程序停止运行,errors='ignore’会忽略没有的行名或者列名,只对存在的行名或者列名进行操作。默认为‘errors=‘raise’’。
# 删除 age_level列
df = df.drop(labels='age_level', axis=1)# 删除 第一行
df = df.drop(labels=0)# 同时删除多列
df = df.drop(labels=['age_level', 'gender'], axis=1)# 同时删除多行:删除第一行和第二行
df = df.drop(labels=range(2)) # 等价于df.drop(labels=[0,1]# 使用del 删除一列,且只能删除一列,不能同时删除多列
del df['age_level']# 删除缺失值占比大于70%的所有列
missing_df = ((df.isnull().sum())/df.shape[0])
missing_columns = (list(missing_df[missing_df >0.7].index))
df= df.drop(columns = list(missing_columns))
3. 异常值检测与处理
3.1 异常值检测
类别型字段
# 查看类别型字段的取值情况,根据经验判断取值是否合理
for i in df:print(i+": "+str(df[i].unique())) # 查看某一列的唯一值
数值型字段
describe函数
# 可以通过describe函数,查看数值列的统计信息,根据经验判断取值是否合理,例如人的年龄不可能是负数
df.describe()
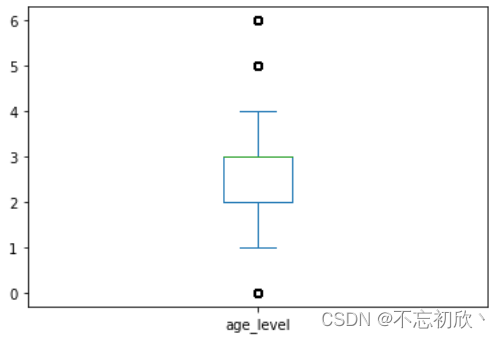
箱线图(四分位法)
# 查看age_level字段的箱线图
df.age_level.plot.box()
3.2 异常值处理
在数据处理时,异常值的处理方法,需视具体情况而定。有时,异常值也可能是正常的值,只不过异常的大或小,所以,很多情况下,要先分析异常值出现的可能原因,再判断如何处理异常值。
- 删除含有异常值的记录;
- 插补,把异常值视为缺失值,使用缺失值的处理方法进行处理,好处是利用现有数据对异常值进行替换,或插补;
- 不处理,直接在含有异常值的数据集上进行数据分析;
4. 特征分析
4.1 查看数值型和类别型特征
特征一般都是由类别型特征和数值型特征组成,而数值型特征又分为连续型和离散型。
- 类别型特征有时具有非数值关系,有时也具有数值关系。比如‘grade’中的等级A,B,C等,是否只是单纯的分类,还是A优于其他要结合业务判断。
- 数值型特征本是可以直接入模的,但往往风控人员要对其做分箱,转化为WOE编码进而做标准评分卡等操作。从模型效果上来看,特征分箱主要是为了降低变量的复杂性,减少变量噪音对模型的影响,提高自变量和因变量的相关度。从而使模型更加稳定。
数值型特征:
# 数值型特征
numerical_fea = list(data_train.select_dtypes(exclude=['object']).columns)"""
['id','user_id','product','campaign_id','webpage_id','product_category_id','user_group_id','age_level','user_depth','var_1','isClick']
"""
类别型特征:
# 类别型特征
category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns)))# ['date', 'gender']
数值型中的离散型变量
#过滤数值型类别特征
def get_numerical_serial_fea(df,feas):numerical_serial_fea = []numerical_noserial_fea = []for fea in feas:temp = df[fea].nunique()if temp <= 10:numerical_noserial_fea.append(fea)continuenumerical_serial_fea.append(fea)return numerical_serial_fea,numerical_noserial_fea
numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(df,numerical_fea)# 数值型连续特征
numerical_serial_fea
# ['id', 'user_id', 'user_group_id']# 数值型类别特征
numerical_noserial_fea
"""
['product','campaign_id','webpage_id','product_category_id','age_level','user_depth','var_1','isClick']"""# product离散型变量
df['product'].value_counts()
"""
0 143195
3 93340
1 52374
5 33125
4 19043
7 18261
9 11877
8 8045
2 6621
6 5944
Name: product, dtype: int64
"""# campaign_id离散型变量
df['campaign_id'].value_counts()
"""
0 92769
2 87450
3 47741
5 29383
6 26042
4 24816
7 23943
8 22417
1 19569
9 17695
Name: campaign_id, dtype: int64
"""...
如果离散型变量中全部都是一个值,可以直接舍弃这个变量;如果不同类别的比例相差较大,需要根据业务分析原因,考虑是否需要使用
数值型连续变量可视化分析:
在这里为了演示,把id相关的列当做数值型连续变量进行分析
# 每个数字特征得分布可视化,根据上面计算只有三个变量:['id', 'user_id', 'user_group_id']
f = pd.melt(data_train, value_vars=numerical_serial_fea)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
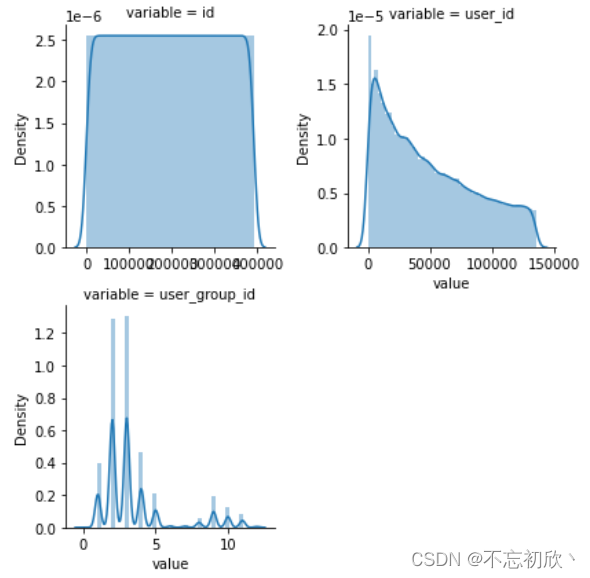
- 查看某一个数值型变量的分布,查看变量是否符合正态分布,如果不符合正太分布的变量可以log化后再观察下是否符合正态分布。
如果想统一处理一批数据变标准化 必须把这些之前已经正态化的数据提出
正态化的原因:一些情况下正态非正态可以让模型更快的收敛,一些模型要求数据正态(eg. GMM、KNN),保证数据不要过偏态即可,过于偏态可能会影响模型预测结果。
# 三种log转换
df['log'] = df['user_group_id'].transform(np.log)
df['log+1'] = (df['user_group_id'] +1).transform(np.log)
df['log(x- min(x)+1)'] = (df['user_group_id']-df['user_group_id'].min() +1).transform(np.log)# 归一化
df['normalized'] = (df['user_group_id'] - df['user_group_id'].min())/(df['user_group_id'].max()-df['A'].min())# 标准化
df['standardized'] = (df['user_group_id'] - df['user_group_id'].mean())/df['user_group_id'].std()
非数值型类别型变量分析
根据上面计算,此部分变量有 ['date', 'gender']
df['gender'].value_counts()
"""
Male 332376
Female 43706
Name: gender, dtype: int64
"""
分析方法和数值型离散变量一致
4.2 单一变量分布可视化
类别型变量:采用柱状图可视化频次
sns.countplot(df["gender"])
plt.show()
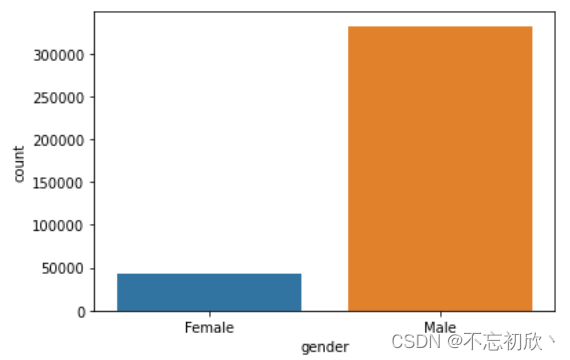
数值型中的连续型变量分布可以参考上面数值型连续变量可视化分析,也可以采用如下方法:
plt.figure(figsize=(9, 8))
sns.distplot(df['user_group_id'], color='g', bins=100, hist_kws={'alpha': 0.4})# 若图像偏离正态分布,取 log之后观察
plt.figure(figsize=(9, 8))
sns.distplot(np.log(train['user_group_id']), color='g', bins=100, hist_kws={'alpha': 0.4})
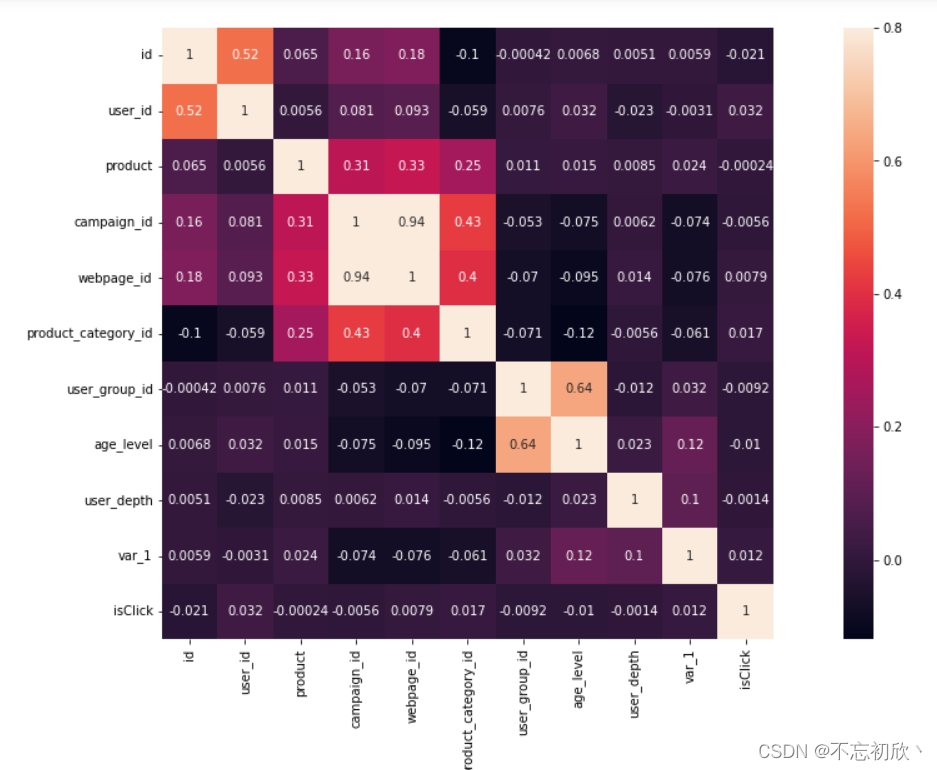
4.3 相关性分析
相关性分析只能比较数值特征,因此字母、字符串特征需先进行编码并转换为数值,才能查看特征间的关联。相关性分析可以很好地过滤掉与标签没有直接关系的特征。若两标签之间完全正相关(多重共线性),则两特征包含几乎相同的信息,可对其进行删除。
# 通过热力图观察变量之间的相关性
corrmat = df.corr()
f, ax = plt.subplots(figsize=(20, 9))
sns.heatmap(corrmat, vmax=0.8, square=True,annot=True)
5. 生成数据分析报告
!pip install pandas_profiling
import pandas_profiling
pfr = pandas_profiling.ProfileReport(df)
pfr.to_file("./example.html")