Improved Knowledge Distillation via Teacher Assistant小陈读paper系列


算是经典了吧哈哈
 1.他们发现了学生性能下降了,什么时候呢?就是老师模型和学生模型差的太多的时候有了很大gap(一个学生不能请一个维度跨越巨大的老师)(老师可以有效地将其知识转移到一定大小的学生,而不是更小的。)
1.他们发现了学生性能下降了,什么时候呢?就是老师模型和学生模型差的太多的时候有了很大gap(一个学生不能请一个维度跨越巨大的老师)(老师可以有效地将其知识转移到一定大小的学生,而不是更小的。)
2.为了缓解这个Gap,采用了多步的蒸馏框架
which employs an intermediate-sized network (teacher assistant) to bridge the gap between the student and the teacher.
它请了中间大小的网络(教师助理)来弥合学生和教师之间的Gap
3.研究了教师助理大小的影响,并将该框架扩展到多步蒸馏。
...substantiate the effectiveness of our proposed approach.证实了我们方法的有效性
读到这里算是摘要读完啦
 额 ,这里分的有点不太一样
额 ,这里分的有点不太一样
模型压缩,参数剪枝和共享 , 低阶因式分解, 知识蒸馏
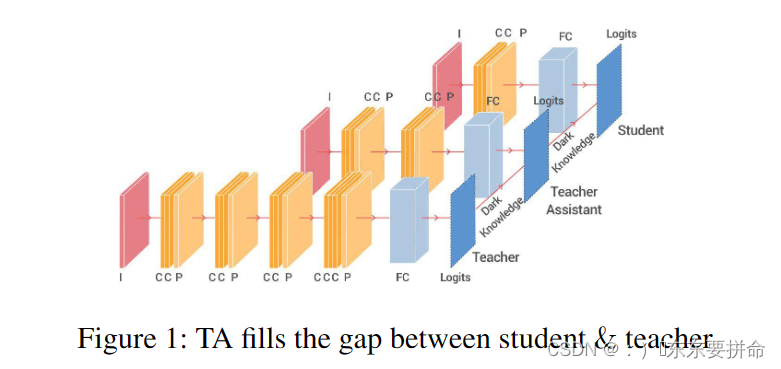
图挺好看的

被误认为是一个美丽的传递关系

架桥喽 这个感觉上去就很work

算是读完了introduction (没感觉啊)
这个paper读的有点水啊

明天仔细看看 晚上下班啦
