Java核心技术(应对面试)


面试的精华都在这本书
目录
第二章 基本语法
==和equals
-
基本数据类型int和封装类Integer
-
对于基本数据类型,
==比较的是值;
对于封装类,==比较的是地址,equals比较的是值。
重要的String对象
-
常量和变量:对于值相同的常量,共享内存空间;对于变量,放在不同的堆空间。
-
内存值不可变:对字符串修改时,不是在原变量上修改,而是把修改后的值放在另一块内存空间,用指针指向它,原变量成为内存垃圾。
如图:
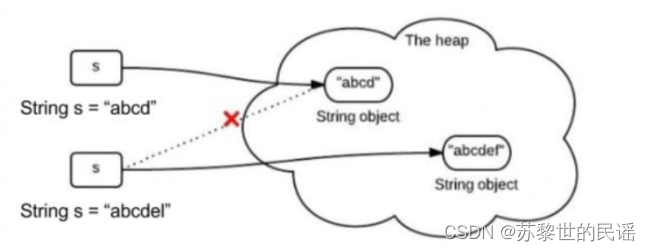
- StringBuilder与StringBuffer:二者都可以直接更改变量,但出于性能考虑,单线程用前者,多线程用后者。
论封装
- 方法的参数是副本:调用方法时,自动对实参创建副本,即另一块内存空间。方法内对副本进行修改,方法结束副本删除。要解决此问题,用
return - 静态方法:不用创建对象,由类直接调用;静态成员被所有类的实例共享,只要类被加载,就可以调用。
- 构造函数:没有返回类型;
论继承
-
抽象类和接口
抽象类是对概念的抽象(人类):abstract
接口是对功能的抽象(发电)
都没有方法体。
-
子类方法不能缩小父类方法的访问权限:否则“父类方法失传”
子类方法不能抛出比父类方法更多的异常
-
一般情况下,必须重写
equals()方法,否则会继承Object类的方法,判断地址是否相同,不是我们想要的。 -
final关键字:- 作用在类上,不能被继承
- 作用在方法上,不能被重写
- 作用在属性上,不能改变它的值
-
finalize方法:类被回收时调用
论多态
-
重载(Overload)和覆盖(Override)的区别
重载是在同一类中,参数列表不同;
覆盖是在子类中,重写了父类的方法。
-
构造函数:可以重载,不能被覆盖。
-
this指向本类,super指向父类。
第三章 集合类和常用数据结构
集合类
- 集合:是容器,不仅可以存储基本数据类型,还可以存储自定义的数据类型。
- 以Collection为基类的线性表类
- 数组
- List
- Set类集合
- Vector
- Queue
- Stack
- HashSet
- 以Map为基类的键值对类
- HashMap
- HashTable
- 以Collection为基类的线性表类
线性表类
- ArrayList和LinkedList
前者基于数组实现,后者基于双向链表实现。二者都是线程不安全的。
线程安全:如果多线程同时向集合对象中插入元素,会不会冲突。
-
ArrayList和Vector
前者线程不安全,后者线程安全,但需要一定的开销来维护,所以单线程下选择ArrayList。
数组越界时,前者扩充50%,后者扩充100%,所以大多数选前者
-
泛型
ArrayList list = new ArrayList() ArrayList<String> list = new ArrayList<String>();//指定ArrayList只能存放String类型的数据 -
Set如何对自定义的类避免重复?
自定义类继承Comparable接口,重写compareTo 和 equals 方法
-
HashSet、LinkedHashSet和TreeSet
向HashSet插入对象时,会调用该对象的hashCode方法,根据hashCode确定存放位置,如果已有,不再插入,插入顺序与遍历顺序不一致。
向LinkedHashSet插入对象时,会调用该对象的hashCode方法,根据hashCode确定存放位置,插入顺序与遍历顺序一致。
TreeSet用二叉树存储数据,保证有序。
-
迭代器
- 不用考虑集合类型和集合存储的对象类型,直接遍历
- 如果边遍历边修改,会报错。这是一个优点。
键值对类
-
Hash算法
- 通过Hash函数将元素放入不同的索引位置
- Hash值冲突:链地址法
-
重写hashCode方法
- 原因:如果不重写,会调用Object固有的hashCode方法,相同id的对象不能取到对应的值,会返回NULL,这不是我们所期望的。
-
重写equals方法
- 原因:重写了hashCode方法后,可以找到相同的Hash索引位置了,但由于Hash值冲突,这个索引上挂了很多链结点,这时需要重写equals方法判断key是否相等。
-
HashMap和HashTable
- 前者线程不安全,后者安全。
第四章 异常处理与IO
异常的基础知识
-
异常处理的原因:希望发生异常后,尽可能保证业务流程正常进行,不要因为异常的出现而终止程序;如果实在无法保证,也应当用用户可以看懂的方式告诉他下一步怎么做。
-
Error和Exception都继承Throwable类。
- Error:eg.内存不足,方法调用栈溢出
- 运行时异常:不会强制用try-catch捕获,一旦发生,程序终止。所以程序员要手动捕获。eg.除0,数组越界,空指针
- 非运行时异常:强制用try从句捕获。
-
throw和throws
- throws在声明方法的位置,throw在函数体中
- 如果函数体中有throw,声明时必须使用throws
- 如果方法声明时有throws,调用该方法时必须用try-catch包含。
- 这么说来,优先级:throw > throws > try ,有前者必须有后者
异常的进阶知识
-
finally回收
- 如果连接了数据库,后面不再用到这个连接对象,要在finally中关闭连接
- 如果用IO对象进行了读写,要关闭这些IO对象
- 如果用到了集合对象,要用clear方法清空这些集合
- 如果有一个对象obj指向一块比较大的内存空间,要obj=null
-
子类方法不能抛出比父类方法范围更广的异常,因为父类方法要遵循“应当充分考虑运行环境的险恶程度”这个原则。
-
异常处理的使用要点
- 尽量用finally回收内存资源
- 尽量减少try监控的代码块
- 尽量先用专业的异常作处理,最后用Exception
- 尽量处理异常,而不是简单抛出
- 尽量降低异常造成的影响,如每次插入的动作分别用try包围,而不是包围所有插入动作
常见的IO操作
- 流对象是处理所有IO对象的载体,它不仅封装了用于保存输入或输出信息的缓存空间,也包含了针对这个缓存空间的操作方法。
- 流对象分为输入流(InputStream)和输出流(OutputStream),分别包含read和write方法。
- IO流标准的输入/输出设备分别是键盘和显示屏,也可以通过system.setIn和system.setOut方法进行重定向。
- 在对缓冲区进行操作时,需要在合理的位置加上flush方法强制输出缓冲区的内容。
第五章 SQL,JDBC
SQL优化
这个问题先搞清楚:什么是索引?
B+树:层数很少,每层结点很多,目的是减少IO次数
- 尽量别用SELECT *,使用具体字段名
- 用
UNION ALL代替OR,使用OR可能导致索引失效,造成全局扫描 - 用varchar代替char,变长字段
- 用数值代替字符串,性别01
- 使用explain分析SQL执行计划
SQL优化方法
优化数据库的代码
-
对项目:
- 将JDBC的参数写到配置文件中,方便重用;
- 项目的生产和测试环境参数不同,通过输入不同的参数来读取不同的配置文件。
-
PreparedStatement
-
以批处理方式执行SQL语句,提升性能;
-
占位符编号从1开始;
-
不要一次性执行太多,不然会“撑爆”缓冲区导致出错;
-
通过调用setString方法避免SQL注入,防止非法用户绕过授权
思考:能否用避免SQL注入,优化我的项目?
-
-
C3P0连接池
- 连接对象使用完毕后,连接池会继续保持它们处于“可用”状态,避免频繁连接和释放导致性能损耗;
- 关闭连接后,物理上不会释放连接对象
数据库优化的技能点
-
索引
- 适合建索引
- 主键自动建立唯一索引
- 与其他表关联的外键
- 频繁作为查询条件的字段
- 排序、统计、分组字段
- 不适合建索引
- 表记录太少
- 频繁增删改
- 数据重复且分布平均
- 适合建索引
-
批处理
-
连接池
-
使用数据表的监控工具:SQL语句执行时间过长,连接数过多
第七章 多线程与并发编程
线程的基本概念
-
进程:资源分配的基本单位,是实现独立功能的程序;
线程:CPU调度的基本单位,是实现单一功能的一个指令序列;
线程间可以共享资源,进程间不能。
-
Java中,线程的生命周期有4种状态:初始化、可执行、阻塞和死亡。
new() -> 进入初始化状态
调用start()方法,自动调用run()方法 -> 进入可执行状态,此时如果分配到CPU时间就可以运行
sleep()或wait()方法 -> 进入阻塞状态,将线程挂起
notify() -> 将wait()的线程变成可执行
run()结束/stop()/destroy() -> 进入死亡进程
-
实现多线程的两种方法:
extends Thread和implements Runnable -
可以通过setPriority()方法设置线程优先级,共1-10,默认5。但并不是高优先级一定先执行,而是先执行的概率大。
多线程的竞争与同步
-
main函数也在一个线程中,也可以调用sleep()方法让它睡眠;
sleep()时间一到,会自动执行后续的代码。
-
Synchronized作用在方法上
并不是对这个方法加了锁,对这个方法加锁表示在一个时间段内只有一个线程访问这个方法,不合理;
正确的说法是给调用该方法的对象加了锁,表示在一个时间段内只有一个线程拥有该对象的访问和控制权。
-
Synchronized还可作用在代码块上,锁包含的代码块能避免多个线程的抢占。
-
wait和notify方法需要放置在synchronized作用域中。一旦一个线程执行wait方法,会释放锁,进入阻塞状态,直到其他线程调用notify方法唤醒它。
-
避免死锁的方法:
- 尽量缩小synchronized代码块的范围
- 多线程场景下注意方法的调用顺序
-
通过锁
lock(),unlock(),trylock()管理业务层面的并发性 -
Condition可以为生产者和消费者分别创建不同的阻塞队列,避免无效线程竞争,使用
await和signal方法。阻塞队列详解
暂时学到这里吧!
已经拿到了满意的offer
读书最高效的方式是带着目的去读。所以,是时候抛弃这本速成攻略,系统学习了!
下一步 系统学习设计模式、Git
至于书中剩下的内容,有缘再见吧