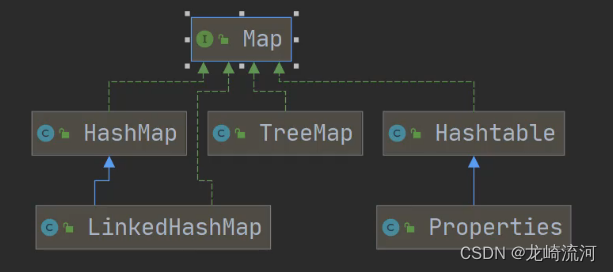
一篇文章让你面试畅谈HashMap,Hashtable,TreeSet,TreeMap

HashMap
- Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value
- Map中的key和value可以是任何引用类型,会封装到HashMap$Node对象中
- Map中的key不允许重复,原因和HashSet一样,前面分析过源码
- Map中的value可以重复
- Map的key可以是null,value也可以为null,注意key为null只能有一个,value为null可以多个
- 常用String类作为Map的key
- key和value之间存在单向一对一关系,即通过指定的key总能找到对应的value
- 和HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储
- HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有synchronized
Map接口的特点:
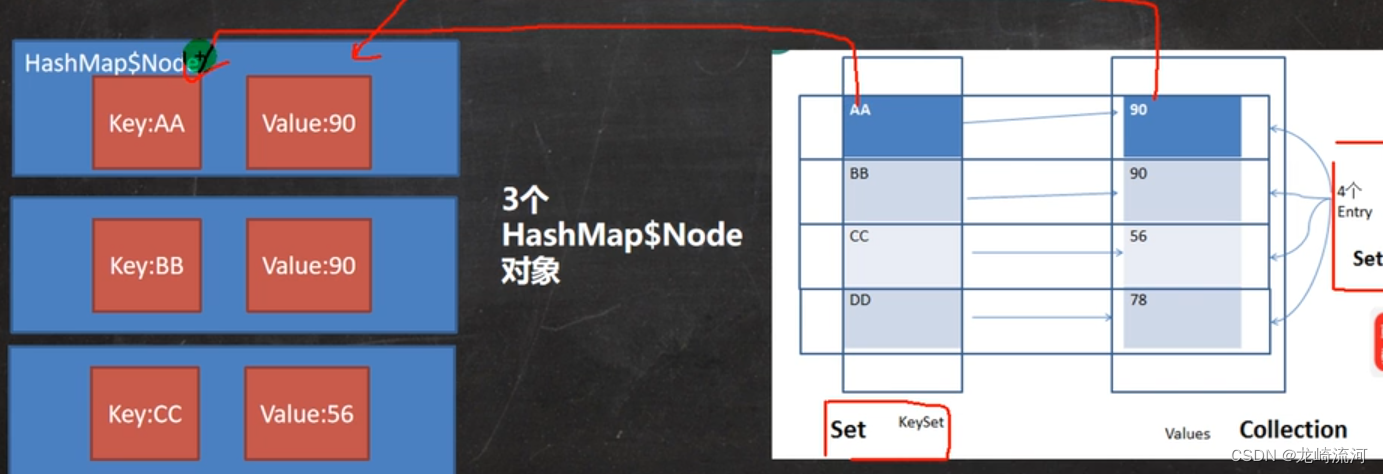
Map存放数据的key-value示意图,一对k-v是放在HashMap$Node的,又因为Node实现了Entry接口,有些书也说一对k-v就是一个Entry。
k-v最后是
HashMap$Node node = newNode(hash, key, value, null);
k-v为了方便程序员的遍历,还会创建EntrySet集合,该集合存放的元素的类型Entry,而一个Entry对象就有k,v,EntrySet<Entry
<K,V>>
transient Set<Map.Entry<K,V>> entrySet;
entrySet中,定义的类型是Map.Entry,但是实际上存放的还是HashMap$Node,这是因为
static class Node<K,V> implements Map.Entry<K,V>
当把HashMap$Node对象存放到entrySet就方便我们的遍历,因为Map.Entry提供了重要方法
public final K getKey() public final V getValue()
Map的六大遍历方式:
package map;import java.util.Collection;
import java.util.HashMap;
import java.util.Set;public class HashMapDemo {public static void main(String[] args) {HashMap<String, String> map = new HashMap<String, String>();// 键不能重复,值可以重复map.put("san", "张三");map.put("si", "李四");map.put("wu", "王五");map.put("wang", "老王");map.put("wang", "老王2");// 老王被覆盖map.put("lao", "老王");System.out.println("-------直接输出hashmap:-------");System.out.println(map);/* 遍历HashMap*/// 1.获取Map中的所有键System.out.println("-------foreach获取Map中所有的键:------");Set<String> keys = map.keySet();for (String key : keys) {System.out.print(key+" ");}System.out.println();//换行// 2.获取Map中所有值System.out.println("-------foreach获取Map中所有的值:------");Collection<String> values = map.values();for (String value : values) {System.out.print(value+" ");}System.out.println();//换行// 3.得到key的值的同时得到key所对应的值System.out.println("-------得到key的值的同时得到key所对应的值:-------");Set<String> keys2 = map.keySet();for (String key : keys2) {System.out.print(key + ":" + map.get(key)+" ");}/* 如果既要遍历key又要value,那么建议这种方式,因为如果先获取keySet然后再执行map.get(key),map内部会执行两次遍历。* 一次是在获取keySet的时候,一次是在遍历所有key的时候。*/// 当我调用put(key,value)方法的时候,首先会把key和value封装到// Entry这个静态内部类对象中,把Entry对象再添加到数组中,所以我们想获取// map中的所有键值对,我们只要获取数组中的所有Entry对象,接下来// 调用Entry对象中的getKey()和getValue()方法就能获取键值对了Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();for (java.util.Map.Entry<String, String> entry : entrys) {System.out.println(entry.getKey() + "--" + entry.getValue());}/* HashMap其他常用方法*/System.out.println("after map.size():"+map.size());System.out.println("after map.isEmpty():"+map.isEmpty());System.out.println(map.remove("san"));System.out.println("after map.remove():"+map);System.out.println("after map.get(si):"+map.get("si"));System.out.println("after map.containsKey(si):"+map.containsKey("si"));System.out.println("after containsValue(李四):"+map.containsValue("李四"));System.out.println(map.replace("si", "李四2"));System.out.println("after map.replace(si, 李四2):"+map);}}源码分析:
- HashMap底层维护了Node类型的数组table,默认为null
- 当创建对象时,将加载因子初始化为0.75
- 当添加key val,通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,继续判断该元素的key是否和准备加入的key相等,如果相等,则直接替换val;如果不相等需要判断时树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
- 第一次添加,则需要扩容table容量为16,临界值为12
- 以后再扩容,则需要扩容table容量为原来的2倍,临界值为原来的2倍,即24,依次类推
- 在java8中,如果一条链表的元素个数超过8(默认),并且table的大小大于等于64(默认),就会进行树化(红黑树)
具体分析和HashSet源码相同,链接在此
Hashtable
- 存放的元素时键值对:即 K-V
- hashtable的键和值都不能为null,否则会抛出空指针异常
- hashTable使用方法基本上和HashMap一样
- hashTable是线程安全的,hashMap是线程不安全的
public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, Cloneable, java.io.Serializable
public synchronized V put(K key, V value)
底层有数组 Hashtable $ Entry[] 初始化为11
private static class Entry<K,V> implements Map.Entry<K,V>
threshold 8 = 11 * 0.75
分析扩容源码:
public synchronized V put(K key, V value) {// Make sure the value is not nullif (value == null) {throw new NullPointerException();}// Makes sure the key is not already in the hashtable.Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;@SuppressWarnings("unchecked")Entry<K,V> entry = (Entry<K,V>)tab[index];for(; entry != null ; entry = entry.next) {if ((entry.hash == hash) && entry.key.equals(key)) {V old = entry.value;entry.value = value;return old;}}
//添加K-V 封装到EntryaddEntry(hash, key, value, index);return null;}
private void addEntry(int hash, K key, V value, int index) {modCount++;Entry<?,?> tab[] = table;if (count >= threshold) {// Rehash the table if the threshold is exceeded//扩容rehash();tab = table;hash = key.hashCode();index = (hash & 0x7FFFFFFF) % tab.length;}// Creates the new entry.@SuppressWarnings("unchecked")Entry<K,V> e = (Entry<K,V>) tab[index];tab[index] = new Entry<>(hash, key, value, e);count++;}
protected void rehash() {int oldCapacity = table.length;Entry<?,?>[] oldMap = table;// overflow-conscious code//关键点:新的容量 11 * 2 + 1 = 23int newCapacity = (oldCapacity << 1) + 1;if (newCapacity - MAX_ARRAY_SIZE > 0) {if (oldCapacity == MAX_ARRAY_SIZE)// Keep running with MAX_ARRAY_SIZE bucketsreturn;newCapacity = MAX_ARRAY_SIZE;}Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];modCount++;threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);table = newMap;for (int i = oldCapacity ; i-- > 0 ;) {for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {Entry<K,V> e = old;old = old.next;int index = (e.hash & 0x7FFFFFFF) % newCapacity;e.next = (Entry<K,V>)newMap[index];newMap[index] = e;}}}
HashMap与Hashtable的对比:

Properties
- 继承自Hashtable类并且实现了Map接口,也是使用键值对的形式来保存数据
- 使用特定和Hashtable类似
- 还可用于从 xxx.properties 文件通常作为配置文件,这个知识点在IO流举例
TreeSet
当我们使用无参构造器创建TreeSet时,仍然时无序的
老师希望添加的元素按照字符串大小来排序
使用TreeSet提供的一个构造器,可以传入一个比较器
new TreeSet<>(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {return ((String)o1).compareTo((String) o2);}});
构造器把传入的比较器对象,赋给了TreeSet的底层的TreeMap的属性this.comparator
public TreeMap(Comparator<? super K> comparator) {this.comparator = comparator;}
Comparator<? super K> cpr = comparator;if (cpr != null) {//cpr就是我们的匿名内部类do {parent = t;//匿名内部类方法cmp = cpr.compare(key, t.key);//动态绑定我们的匿名内部类(对象)if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;else//如果相等,即返回0,这个key就加入不了return t.setValue(value);} while (t != null);
按长度排从小到大排
new TreeSet<>(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {return ((String)o1).length() - ((String) o2).length();}});
TreeMap
调用put方法,第一次添加,把k-v封装到Entry对象,放入root
Entry<K,V> t = root;if (t == null) {//检查是不是null,并给比较器赋一个自己重写的比较器compare(key, key); // type (and possibly null) checkroot = new Entry<>(key, value, null);size = 1;modCount++;return null;}
第二次以及以上次数提交
Comparator<? super K> cpr = comparator;if (cpr != null) {do {//遍历所有的key,给当前key找到适当位置parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;else//如果遍历过程中,发现准备添加Key和当前已有的Key相等就不添加return t.setValue(value);} while (t != null);}