文本三剑客之grep和正则表达式

一、grep
grep [选项]… 查找条件 目标文件 选项:
-m # 匹配#次后停止 //grep -m 1 root /etc/passwd #多个匹配只取第一个
-v 显示不被pattern匹配到的行,即取反 //grep -Ev '^[[:space:]]*#|^$' /etc/fstab
-i 忽略字符大小写 #可有可无
-n 显示匹配的行号
-c 统计匹配的行数 grep -c root /etc/passwd #统计匹配到的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行 grep -A3 root /etc/passwd #匹配到的行的后3行也显示出来
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
-w 匹配整个单词 grep -w root /etc/passwd
-E 使用ERE,相当于egrep,使用扩展正则
-F 不支持正则表达式
-f file根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接
[root@localhost opt]# grep -f 123.txt 456.txt //匹配两个文件中内容相同的部分
a b c ee
[root@localhost opt]# grep -r a /opt //递归过滤目录中的文件 匹配到二进制文件
/opt/.yonghu.sh.swp /opt/123.txt:a /opt/456.txt:a
[root@localhost opt]# ln -s 123.txt b
[root@localhost opt]# grep -R a /opt //匹配到二进制文件
/opt/.yonghu.sh.swp /opt/123.txt:a /opt/456.txt:a /opt/b:a
[root@test1 opt]# cat 123.txt |grep -v '^$' >test.txt //将非空行写入到test.txt文件
[root@test1 opt]# grep "^b" 123.txt //过滤已b开头
[root@test1 opt]#grep '/$' 123.txt //过滤已/结尾
二、正则表达式的概述
1、概念
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
2、作用
通常用于判断语句中,用来检查某一字符串是否满足某一格式
• 正则表达式是由普通字符与元字符组成
• 普通字符包括大小写字母、数字、标点符号及一些其他符号
• 元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
3、可达到的目的
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”)
- 可以通过正则表达式,从字符串中获取我们想要的特定部分
4、通配符和正则表达式的区别
通配符只用于匹配文件名、目录名等,不能用于匹配文件内容。(而且是已存在的文件或者目录)通配符主要是为了方便用户对文件或者目录的描述, 例如用户仅仅需要以".sh"结尾的文件时,使用通配符就能很方便地实现。 各个版本的shell都有通配符,这些通配符是一些特殊的字符, 用户可以在命令行的参数中使用这些字符,进行文件名或者路径名的匹配。 shell将把与命令行中指定的匹配规则符合的所有文件名或者路径名作为命令的参数, 然后执行这个命令。
*:通配符匹配任意一个或多个字符 ls *.txt
?:通配符 匹配一个任意字符 [root@localhost opt]# ls ?.txt
[ ] 通配符 [list] 匹配list中任意单个字符 ls [a-z].txt
三、基础正则
1、基础正则常见元字符:(支持的 工具: grep、 egrep、 sed、awk)
\\ : 转义字符,用于取消特殊符号的含义
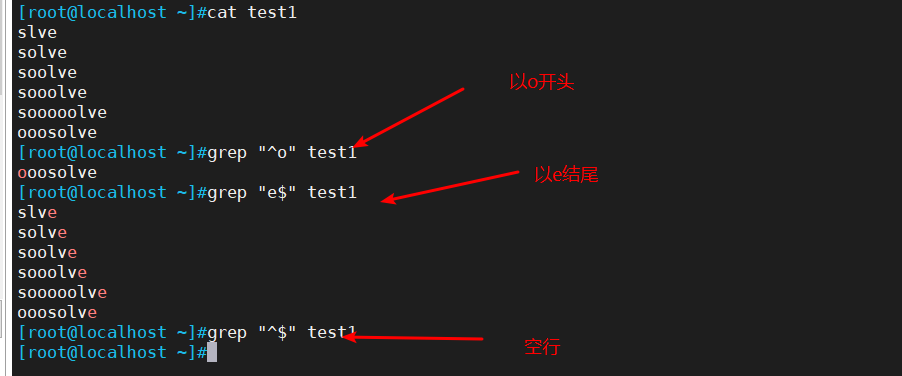
^ : 匹配字符串开始的位置
$ : 匹配字符串结束的位置
. : 匹配除\\n之外的任意的一个字符
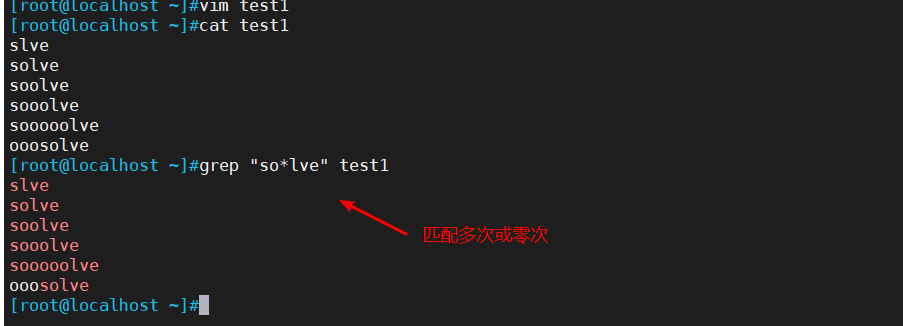
* : 匹配前面子表达式0次或者多次
[list] : 匹配list列表中的一个字符
[^list] : 匹配任意非list列表中的一个字符
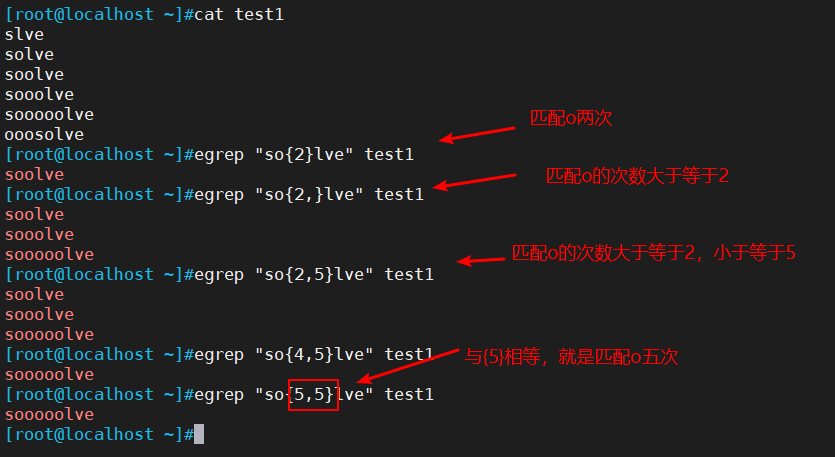
{n} : 匹配前面的子表达式n次
{n,} : 匹配前面的子表达式不少于n次
{n,m} : 匹配前面的子表达式n到m次
注: egrep、 awk使用{n}、{n,}、 {n, m}匹配时“{}"前不用加“\\”
2、实例操作
2.1 * 匹配前面子表达式0次或者多次
2.2 . 匹配除\\n之外的任意的一个字符

2.3 {n} : 匹配前面的子表达式n次;{n,} : 匹配前面的子表达式不少于n次;{n,m} : 匹配前面的子表达式n到m次
注: egrep、 awk使用{n}、{n,}、 {n, m}匹配时“{}"前不用加“\\”
grep -E 相当于 egrep
2.4 ^ 匹配字符串开始的位置;$ 匹配字符串结束的位置;^$匹配空行
2.5 [list] 匹配list列表中的一个字符;[^list] 匹配任意非list列表中的一个字符

四、扩展正则
1、扩展正则表达式元字符: ( 支持的工具: egrep、 awk,也可用grep -E)
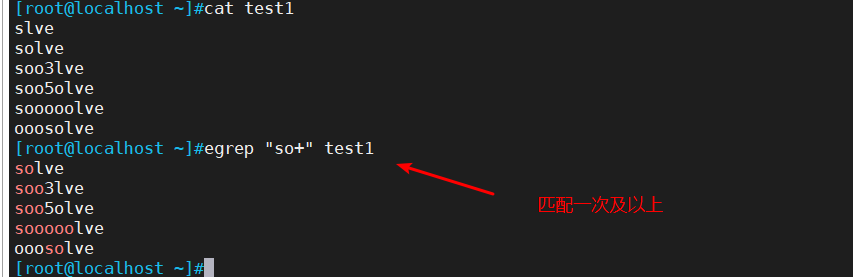
+ : 匹配前面 子表达式1次以上
? : 匹配前面 子表达式0次或者1次() : 将括号中的字符串作为一个整体| : 以或的方式匹配字条串
{} :允许为可重复的正则表达式指定一个上限,这通常称为间隔(interval){n} 重复n次;{n,} 重复n次或更多次;{n,m} 重复n到m次
2、实例操作
2.1、 + 匹配前面 子表达式1次以上
2.2 ? 匹配前面 子表达式0次或者1次
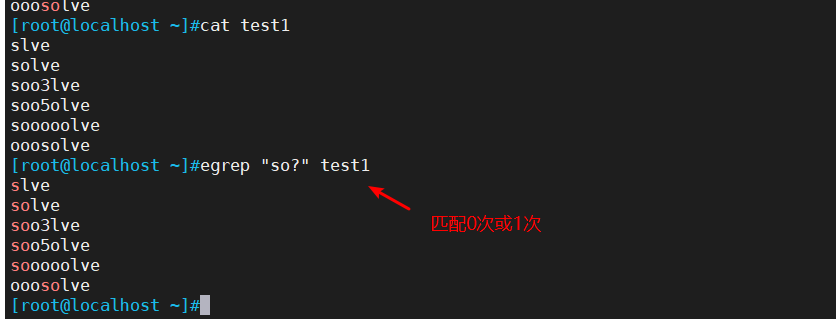
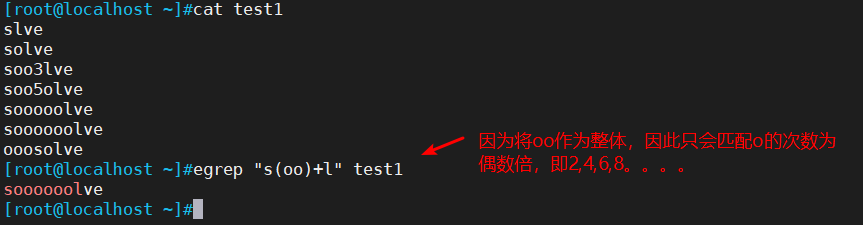
2.3 () 将括号中的字符串作为一个整体
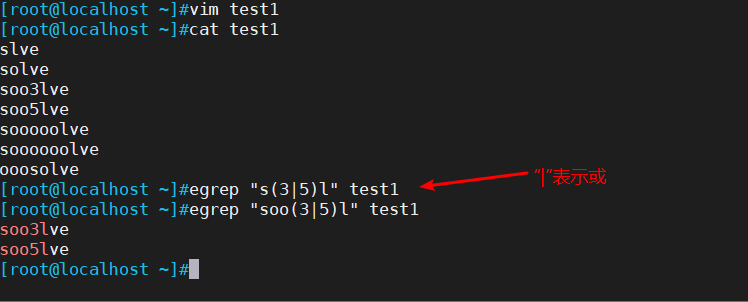
2.4 | 以或的方式匹配字条串
五、练习操作
1.匹配号码
[root@localhost opt]# grep -E "[0-9]+-[0-9]+" number.txt
025-83346023
0510-8776655
0527-9888899
[root@localhost opt]# echo "13770725194"|grep -E "\\b1[3456789][0-9]+\\b"
13770725194
2.表示邮箱
[root@localhost opt]# echo "544564317@qq.com" | grep -E "[0-9]+@[a-z]+.[a-z]+"
[root@localhost opt]# echo "cicifireway@163.com" | grep -E "[a-z]+@[0-9]+.[a-z]+"
cicifireway@163.com
[root@localhost opt]# echo "CICIfireway@163.com" | grep -E "[a-zA-Z]+@[0-9]+.[a-z]+"
CICIfireway@163.com
[root@localhost opt]# grep -E "[a-Z0-9]+@[0-9a-Z]+.[a-Z]+" emal.txt
cicifireway@126.com
544564317@qq.com
CICIfireway@126.com
aabb556644@163.com