大数据3 -Hadoop HDFS-分布式文件系统

目录
1.为什么需要分布式存储?
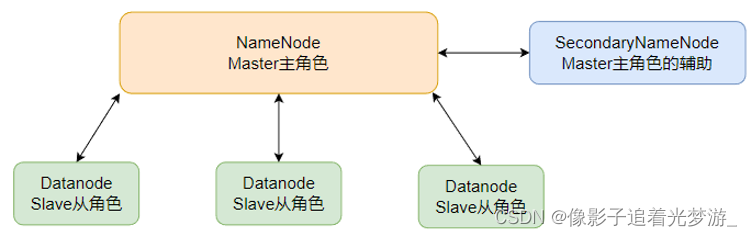
2. HDFS的基础架构
3. HDFS存储原理
4. NameNode是如何管理Block块的
5. HDFS数据的读写流程
1.为什么需要分布式存储?
大数据体系中,分布式的调度主要有2类架构模式:
•中心化模式
去中心化模式,没有明确的中心。
众多服务器之间基于特定规则进行同步协调。
大数据框架,大多数的基础架构上,都是符合:中心化模式的。
即:有一个中心节点(服务器)来统筹其它服务器的工作,统一指挥,统一调派,避免混乱。
这种模式,也被称之为:一主多从模式,简称主从模式(Master And Slaves)
主从模式(中心化模式)在现实生活中同样很常见:
Hadoop框架,就是一个典型的主从模式(中心化模式)架构的技术框架。
总结:
1. 分布式系统常见的组织形式?
2. 什么是主从模式?
主从模式(Master-Slaves)就是中心化模式,表示有一个主节点来作为管理者,管理协调下属一批从节点工作。
3. Hadoop是哪种模式?
主从模式(中心化模式)的架构
2. HDFS的基础架构
HDFS是Hadoop三大组件(HDFS、MapReduce、YARN)之一
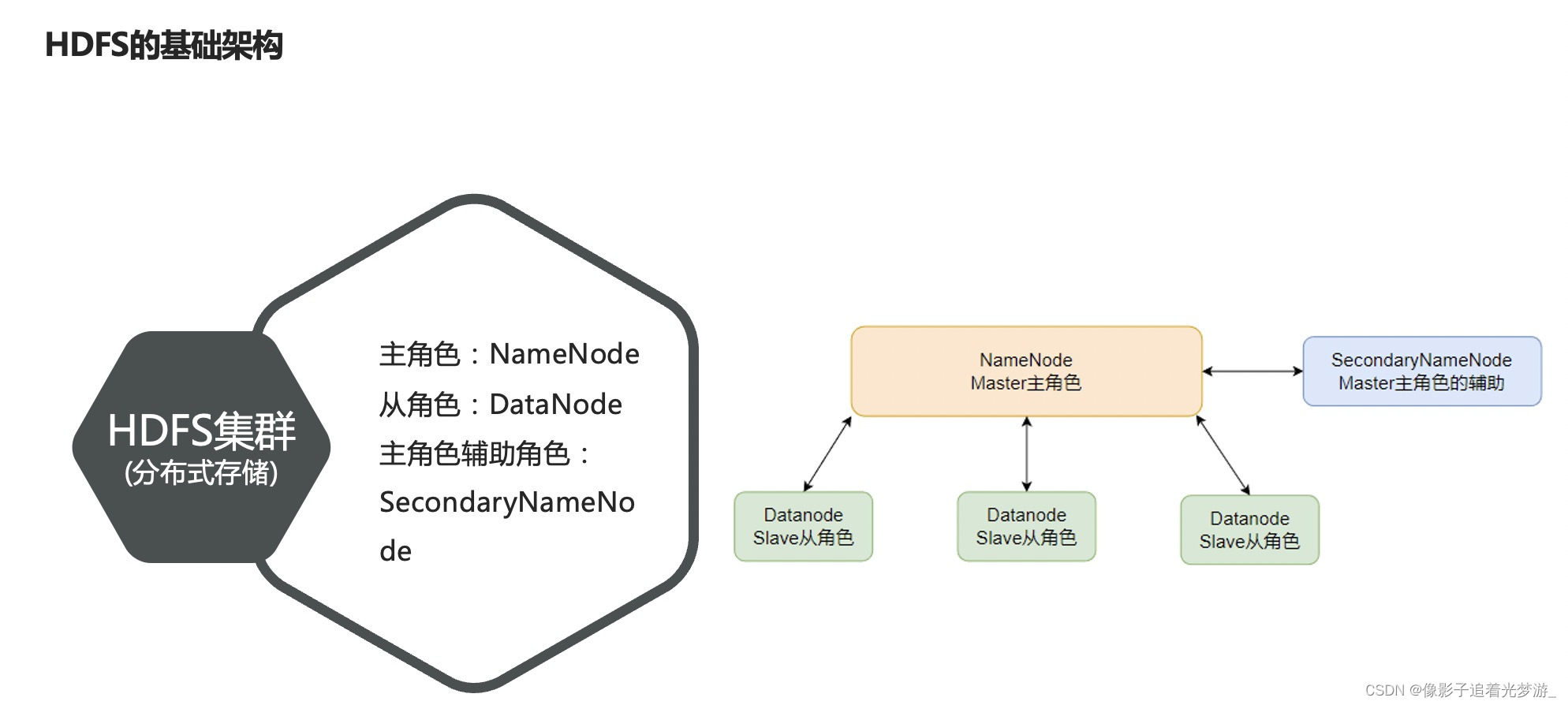
HDFS的基础架构:

NameNode:
SecondaryNameNode:
DataNode:
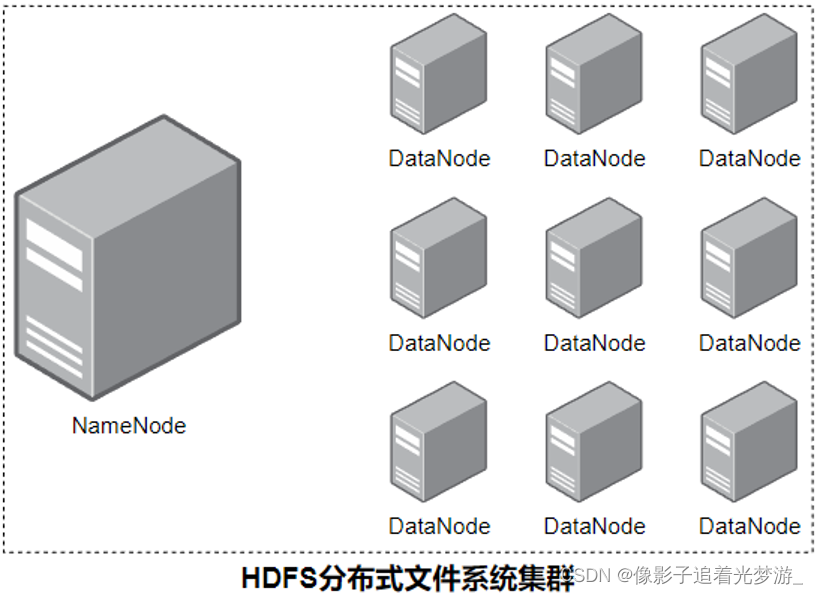
3. HDFS存储原理
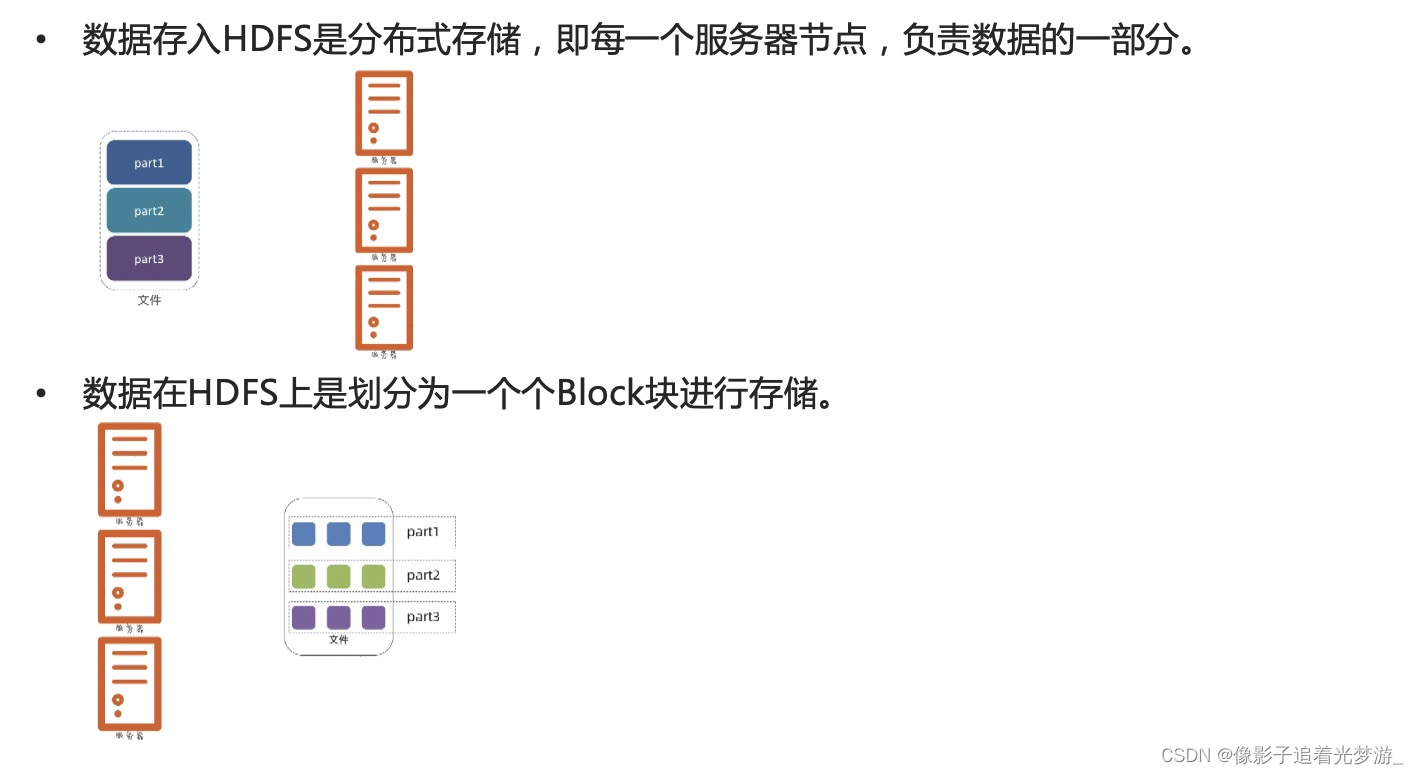
4. NameNode是如何管理Block块的
edits文件
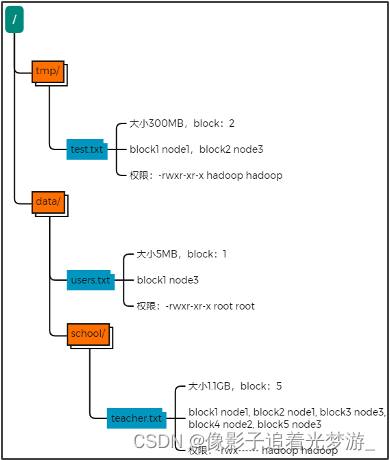
在hdfs中,文件是被划分了一堆堆的block块,那如果文件很大、以及文件很多,Hadoop是如何记录和整理文件和block块的关系呢?
答案就在于NameNode
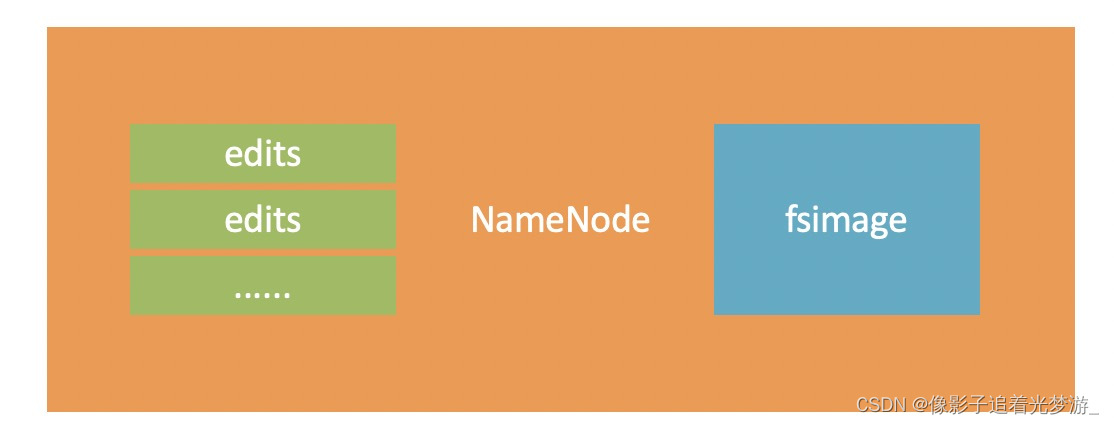
NameNode基于一批edits和一个fsimage文件的配合
完成整个文件系统的管理和维护

edits记录每一次HDFS的操作
逐渐变得越来越大
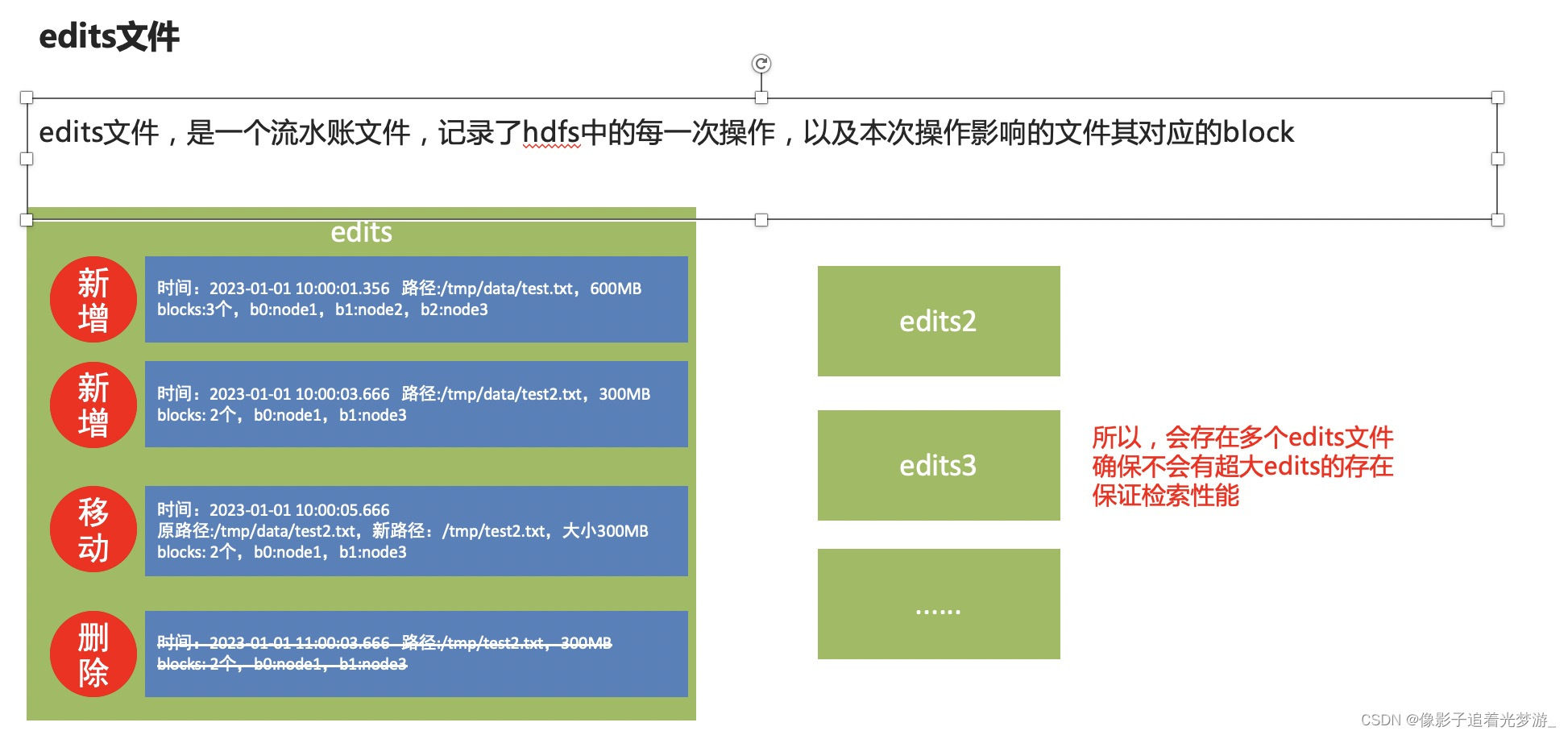
问题在于,当用户想要查看某文件内容
如:/tmp/data/test.txt
就需要在全部的edits中搜索
(还需要按顺序从头到尾,避免后期改名或删除)
效率非常低
需要合并edits文件,得到最终的结果
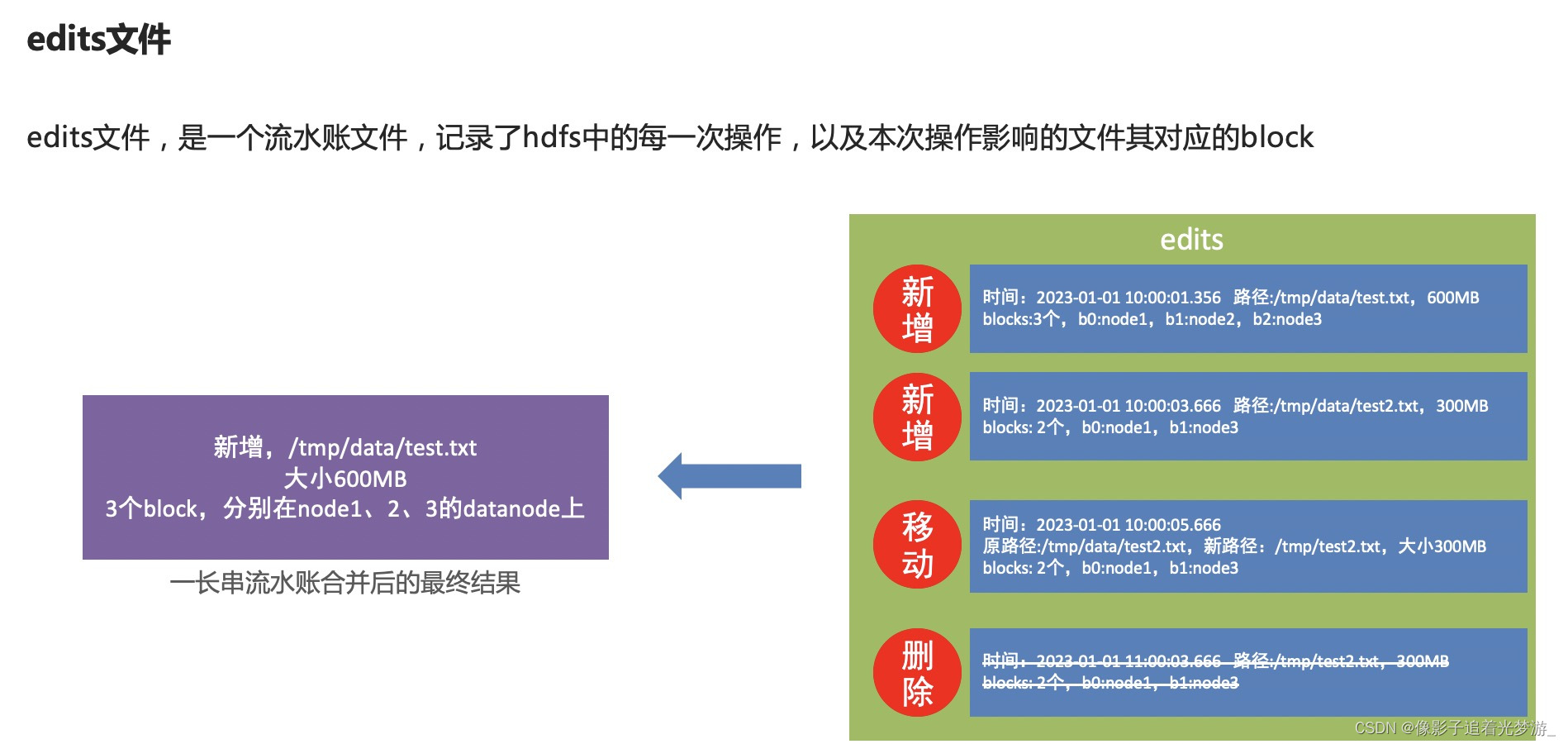
fsimage文件

NameNode元数据管理维护
NameNode基于edits和FSImage的配合,完成整个文件系统文件的管理。
1. 每次对HDFS的操作,均被edits文件记录
2. edits达到大小上线后,开启新的edits记录
3. 定期进行edits的合并操作
5. 重复123流程
元数据合并控制参数
对于元数据的合并,是一个定时过程,基于:
只要有一个达到条件就执行。
检查是否达到条件,默认60秒检查一次,基于:
SecondaryNameNode的作用
对于元数据的合并,还记得HDFS集群有一个辅助角色:SecondaryNameNode吗?
没错,合并元数据的事情就是它干的
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage)
然后合并完成后提供给NameNode使用。
1. NameNode基于
维护整个文件系统元数据
2. edits文件会被合并到fsimage中,这个合并由:
SecondaryNameNode来操作
3. fsimage记录的内容是:
5. HDFS数据的读写流程
1. 客户端向NameNode发起请求
2. NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
3. 客户端向指定的DataNode发送数据包
4. 被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode
5. 如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给Datanode3和DataNode4
6. 写入完成客户端通知NameNode,NameNode做元数据记录工作
读: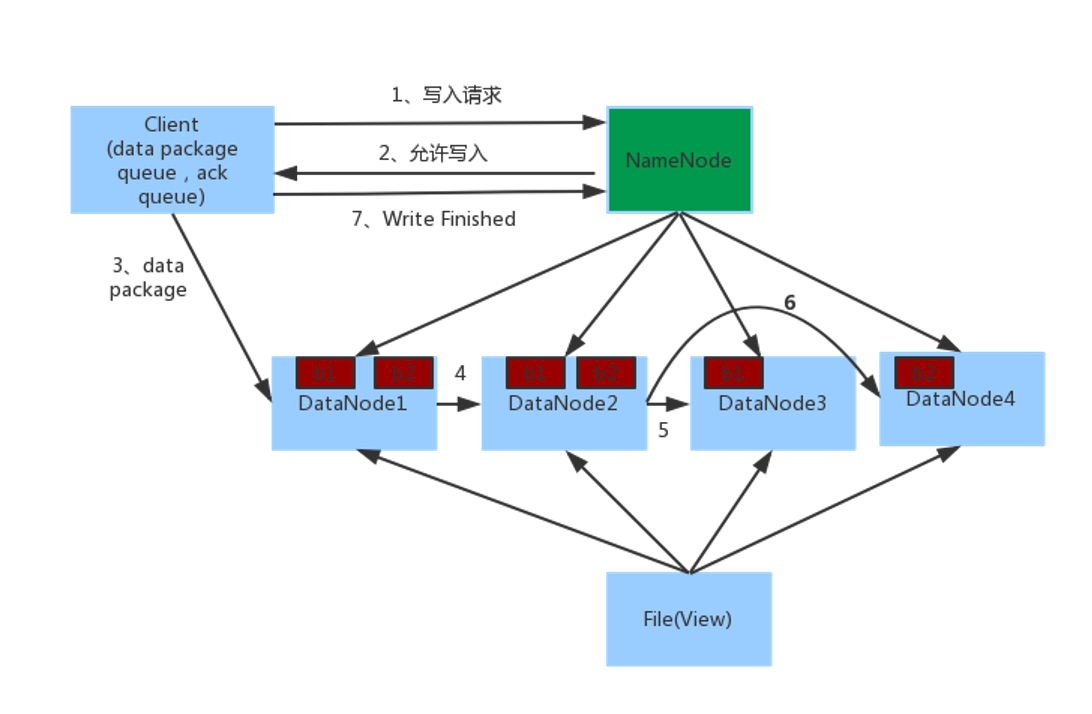
关键信息点:
写:
关键点:
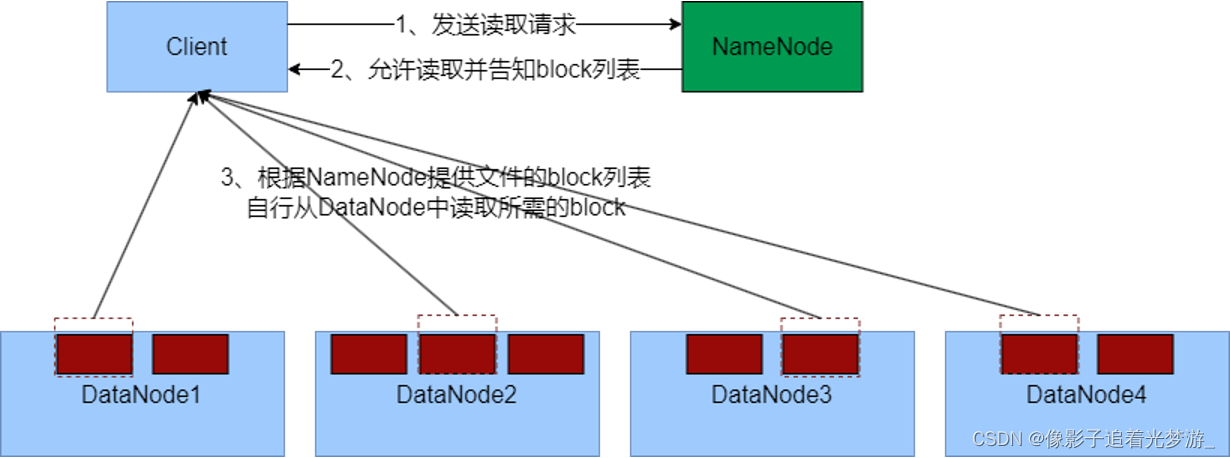
1、数据同样不通过NameNode提供
2、NameNode提供的block列表,会基于网络距离计算尽量提供离客户端最近的
这是因为1个block有3份,会尽量找离客户端最近的那一份让其读取
1、客户端向NameNode申请读取某文件
2、 NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
3、客户端拿到block列表后自行寻找DataNode读取即可
1、对于客户端读取HDFS数据的流程中,一定要知道
不论读、还是写,NameNode都不经手数据,均是客户端和DataNode直接通讯
不然对NameNode压力太大
2、写入和读取的流程,简单来说就是:
3、网络距离
HDFS内置网络距离计算算法,可以通过IP地址、路由表来推断网络距离