数据的清洗与准备

目录
一、处理缺失数据
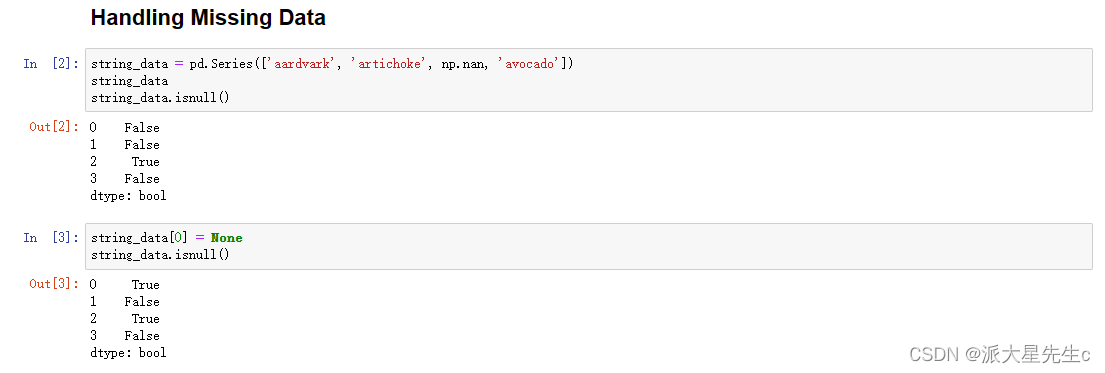
1、查找缺失值
string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
string_data
string_data.isnull()

2、滤除缺失值
过滤掉缺失数据的办法有很多种。你可以通过pandas.isnull或布尔索引的手工方法,但dropna可能会更实用一些。对于一个Series,dropna返回一个仅含非空数据和索引值的Series:
from numpy import nan as NA
data = pd.Series([1, NA, 3.5, NA, 7])
data.dropna()
data[data.notnull()]
上述的两种方法的结果都是 (他们等价)

而对于DataFrame对象,事情就有点复杂了。你可能希望丢弃全NA或含有NA的行或列。
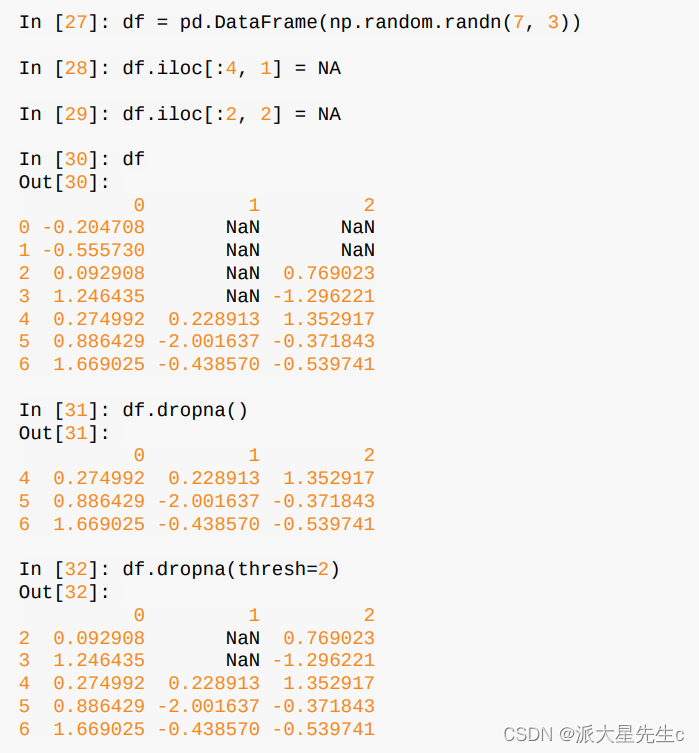
dropna默认丢弃任何含有缺失值的行:

传入how='all’将只丢弃全为NA的那些行:


另一个滤除DataFrame行的问题涉及时间序列数据。假设你只想留下一部分观测数据,可以用thresh参数实现此目的:
3、填充缺失数据
你可能不想滤除缺失数据(有可能会丢弃跟它有关的其他数据),而是希望通过其他方式填补那些“空洞”。对于大多数情况而言,fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为那个常数值:
df.fillna(0)
#若是通过一个字典调用fillna,就可以实现对不同的列填充不同的值:
df.fillna({1: 0.5, 2: 0})
#illna默认会返回新对象,但也可以对现有对象进行就地修改:
_ = df.fillna(0, inplace=True)
df = pd.DataFrame(np.random.randn(6, 3))
df.iloc[2:, 1] = NA
df.iloc[4:, 2] = NA
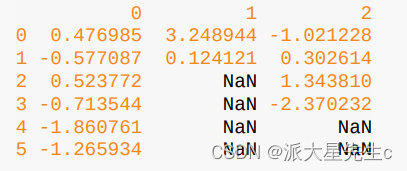
df.fillna(method='ffill')
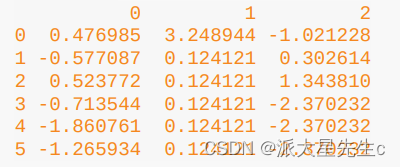
df.fillna(method='ffill', limit=2)



二、数据转换
1、移除重复数据
data = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'],'k2': [1, 1, 2, 3, 3, 4, 4]})
data.duplicated()
data.drop_duplicates()

2、利用函数或映射进行数据转换
一个有关肉类的数据集
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon','Pastrami', 'corned beef', 'Bacon','pastrami', 'honey ham', 'nova lox'],'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
data
meat_to_animal = {'bacon': 'pig','pulled pork': 'pig','pastrami': 'cow','corned beef': 'cow','honey ham': 'pig','nova lox': 'salmon'
}
#我们还需要使用Series的str.lower方法,将各个值转换为小写
lowercased = data['food'].str.lower()
lowercased
data['animal'] = lowercased.map(meat_to_animal)
data

data['food'].map(lambda x: meat_to_animal[x.lower()])

使用map是一种实现元素级转换以及其他数据清理工作的便捷方式。
3、替换值
- 对于数据中的缺失值,如果要使用NA来替代这些值,可以使用replace方法生成新的Series(除非传入了inplace = True);
- 如果想要一次替代多个值,可以传入一个列表和替代值;
- 要将不同的值替换为不同的值,可以传入替代值的列表;
- 参数也可以通过字典传递。
4、重命名轴索引
和Series中的值一样,可以通过函数或某种形式的映射对轴标签进行类似的转换,生成新的且带有不同标签的对象,也可以在不生成新的数据结构的情况下修改轴。下面是简单的示例:
data = pd.DataFrame(np.arange(12).reshape((3, 4)), index = ['Ohio', 'Colorado', 'New York'], columns = ['one', 'two', 'three', 'four'])
[out]
dataone two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
New York 8 9 10 11
与Series类似,轴索引也有一个map方法:
transform = lambda x: x[:4].upper()
data.index.map(transform)
[out]
Index(['OHIO', 'COLO', 'NEW '], dtype='object')
data.index = data.index.map(transform)
[out]
dataone two three fourOHIO 0 1 2 3COLO 4 5 6 7NEW 8 9 10 11
如果想要创建数据集转换后的版本,并且不修改原有的数据集,一个有用的方法是rename:
data.rename(index = str.title, columns = str.upper)
[out]ONE TWO THREE FOUROhio 0 1 2 3Colo 4 5 6 7New 8 9 10 11
rename可以结合字典型对象使用,为轴标签的子集提供新的值:\\
data.rename(index={'OHIO': 'INDIANA'},columns={'three': 'peekaboo'})
#如果想要修改原有的数据集,传入inplace = True:
data.rename(index={'OHIO': 'INDIANA'}, inplace=True)
data
5、离散化和面元划分 (比较重要)
连续值经常需要离散化,或者分离成“箱子”进行分析。
可以使用pandas中的cut对数据进行分组:
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
bins = [18, 25, 35, 60, 100]
# 接下来将这些数据划分为“18到25”、“26到35”、“35到60”以及“60以上”几个面元。
# 要实现该功能,你需要使用pandas的cut函数:
cats = pd.cut(ages, bins)
cats
pandas返回的对象是一个特殊的Categorical对象,可以将它当作一个表示箱名的字符串数组,它在内部包含了一个categories(类别)数组,它指定了不同的类别名称以及codes属性中的数据标签:
cats.codes
[out]
array([0, 0, 0, 1, 0, 0, 2, 3, 2, 2, 1], dtype=int8)
cats.categories
[out]
IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]],closed='right',dtype='interval[int64]')
注意:pd.values_counts(cats)是对pandas.cut的结果中的箱数量的计算:
pd.value_counts(cats)
[out]
(18, 25] 5
(35, 60] 3
(25, 35] 2
(60, 100] 1
dtype: int64
与区间的数学符号一样,小括号表示开,中括号表示闭,可以通过传递right = False 来改变哪一边是封闭的:
pd.cut(ages, [18, 26, 36, 61, 100], right = False)
[out]
[[18, 26), [18, 26), [18, 26), [26, 36), [18, 26), ..., [36, 61), [61, 100), [36, 61), [36, 61), [26, 36)]
Length: 11
Categories (4, interval[int64]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)]
可以通过向labesl选项传递一个列表或数组来传入自定义的箱名:
group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
pd.cut(ages, bins, labels=group_names)
[out]
['Youth', 'Youth', 'Youth', 'YoungAdult', 'Youth', ..., 'MiddleAged', 'Senior', 'MiddleAged', 'MiddleAged', 'YoungAdult']
Length: 11
Categories (4, object): ['Youth' < 'YoungAdult' < 'MiddleAged' < 'Senior']
如果传给cut整数个的箱来代替显式的箱边,pandas将根据数据中的最大值和最小值计算出等长的箱(precision:十进制精度):
data = np.random.rand(20)
pd.cut(data, 4, precision = 2)
[out]
[(0.24, 0.46], (0.69, 0.91], (0.46, 0.69], (0.0094, 0.24], (0.46, 0.69], ..., (0.0094, 0.24], (0.69, 0.91], (0.69, 0.91], (0.0094, 0.24], (0.0094, 0.24]]
Length: 20
Categories (4, interval[float64]): [(0.0094, 0.24] < (0.24, 0.46] < (0.46, 0.69] < (0.69, 0.91]]qcut是一个与分箱密切相关的函数,它基于样本分位数进行分箱。取决于数据的分布,使用cut通常不会使每个箱具有相同数据量的数据点,由于qcut使用样本的分位数,所以可以通过qcut获得等长的箱:
data = np.random.randn(1000)
cats = pd.qcut(data, 4) # 切成四份
[out]
cats
[(0.676, 3.786], (0.0152, 0.676], (-3.283, -0.653], (-3.283, -0.653], (0.676, 3.786], ..., (0.676, 3.786], (-3.283, -0.653], (-3.283, -0.653], (0.0152, 0.676], (0.0152, 0.676]]
Length: 1000
Categories (4, interval[float64]): [(-3.283, -0.653] < (-0.653, 0.0152] < (0.0152, 0.676] < (0.676, 3.786]]pd.value_counts(cats)
[out]
(-3.283, -0.653] 250
(-0.653, 0.0152] 250
(0.0152, 0.676] 250
(0.676, 3.786] 250
dtype: int64与cut类似,可以传入自定义的分位数(注意,qcut是没有right这个参数的):
pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
[out]
[(1.295, 3.786], (0.0152, 1.295], (-1.304, 0.0152], (-1.304, 0.0152], (1.295, 3.786], ..., (0.0152, 1.295], (-3.283, -1.304], (-3.283, -1.304], (0.0152, 1.295], (0.0152, 1.295]]
Length: 1000
Categories (4, interval[float64]): [(-3.283, -1.304] < (-1.304, 0.0152] < (0.0152, 1.295] < (1.295, 3.786]]
6、检测和过滤异常值
考虑一个具有正态分布数据的DataFrame:
data = pd.DataFrame(np.random.randn(1000, 4))
data.describe()
[out]0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.004252 -0.068202 0.018967 -0.023168
std 1.041946 0.990577 1.000506 0.977232
min -3.225913 -3.268806 -2.780122 -2.758672
25% -0.712939 -0.708957 -0.716310 -0.685308
50% 0.025723 -0.049111 -0.010828 -0.035590
75% 0.694367 0.589943 0.664508 0.628488
max 3.448641 2.741577 3.309812 3.456869假设要找出一列中绝对值大于三的值:
col = data[2]
col[np.abs(col) > 3]
[out]
87 3.309812
109 3.151158
568 3.157156
Name: 2, dtype: float64
要选出所有值大于3或小于-3的行,可以对布尔值DataFrame使用any方法:
data[(np.abs(data) > 3).any(axis=1)] #axis = 1表示的是以列为轴向
[out]0 1 2 3
39 -0.809281 -0.392603 1.801699 3.057056
72 3.057684 1.445641 0.125901 0.091375
87 -0.584990 1.009517 3.309812 0.156830
101 3.110218 0.265354 -0.305812 -0.427352
109 -2.998249 0.335766 3.151158 0.233610
295 -0.266134 0.672752 -0.634659 3.276163
516 -1.152287 -3.268806 -0.855634 0.647719
568 0.138585 0.654785 3.157156 1.968288
664 -3.225913 -1.925428 0.605383 -0.265089
676 -3.054581 -0.462598 0.831141 0.513706
692 3.015440 -0.807693 0.262138 -0.287005
712 3.448641 0.761175 -0.027719 1.074143
781 1.258356 -0.375759 -1.183974 3.456869
805 0.100815 -3.035329 -0.170239 -0.205602
888 3.078300 -0.157611 1.156965 0.496205值可以根据这些标准来设置,下面代码限制了-3到3之间的数值(语句np.sign(data)根据数据中的值的正负分别生成1和-1):
data[np.abs(data) > 3] = np.sign(data) * 3
data.describe()
[out]0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.003822 -0.067898 0.018349 -0.023958
std 1.038955 0.989638 0.998589 0.974634
min -3.000000 -3.000000 -2.780122 -2.758672
25% -0.712939 -0.708957 -0.716310 -0.685308
50% 0.025723 -0.049111 -0.010828 -0.035590
75% 0.694367 0.589943 0.664508 0.628488
max 3.000000 2.741577 3.000000 3.0000007、置换和随机抽样
使用numpy.random.permutation对DataFrame中的Series或行进行置换(随机重排序),在调用permutation时根据想要的轴长度可以产生一个表示新顺序的整数数组,整数数组可以用在基于iloc的索引或等价的take函数中。
df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4)))
sampler = np.random.permutation(5)
sampler
array([3, 1, 4, 2, 0])
# sampler 随即重排序后
df.take(sampler)
0 1 2 3
3 12 13 14 15
1 4 5 6 7
4 16 17 18 19
2 8 9 10 11
0 0 1 2 3
# sample 随机选3组
df.sample(n=3)
0 1 2 3
3 12 13 14 15
4 16 17 18 19
2 8 9 10 11
# 要通过替换的方式产生样本(允许重复选择),可以传递replace=True到sample:
choices = pd.Series([5, 7, -1, 6, 4])
draws = choices.sample(n=10, replace=True)
draws
4 4
1 7
4 4
2 -1
0 5
3 6
1 7
4 4
0 5
4 4
dtype: int64
8、计算指标/虚拟变量
将分类变量转换为“虚拟”或“指标”矩阵是另一种用于统计建模或机器学习的转换操作。如果DataFrame中的一列有k个不同的值,则可以衍生一个k列的值为1或0的矩阵或DataFrame。pandas有一个get_dummies函数用于实现该功能。
三、字符串操作
pandas允许将字符串和正则表达式简洁地应用到整个数据数组上,此外还能处理数据缺失带来的困扰。
1、字符串对象方法
Python内建字符串方法
| 方法 | 描述 |
|---|---|
| count | 返回子字符串在字符串中的非重叠出现次数 |
| endswith | 如果字符串以后缀结尾则返回True |
| startswith | 如果字符串以前缀开始则返回True |
| join | 使用字符串作为间隔符,用于粘合其他字符串的序列 |
| index | 如果在字符串中找到,则返回子字符串中第一个字符的位置,如果找不到则引发valueError |
| find | 返回字符串中第一个出现子字符串的位置,类似index,但如果没有找到则返回-1 |
| rfind | 返回子字符串在字符串中最后一次出现时第一个字符的位置,没有找到则返回-1 |
| replace | 使用一个字符串替代另一个字符串 |
| strip, rstrip, lstrip | 修建空白,包括换行符split使用分隔符将字符串拆分为子字符串的列表lower |
| upper | 将小写字母转换为大写字母 |
| casefold | 将字符转化为小写,并将任何特定于区域的变量字符组合转换为常见的可比较形式 |
| ljust, rjust | 左对齐或右对齐,用空格(或其他一些字符)填充字符串的相反侧以返回具有最小宽度的字符串 |
2、正则表达式
单个表达式通常被称为regex,是根据正则表达式语言形成的字符串,Python内建的re模块就是与之相关的库。
- re模块主要有三个主题:模式匹配、替代、拆分,这三个主题是相关联的,一个正则表达式描述了在文本中需要定位的一种模式,可以用于多个目标;
- 可以使用re.compile(正则表达式)自行编译,形成一个可复用的正则表达式对象;
import re
text = "foo bar\\t baz \\tqux"
re.split('\\s+', text)
['foo', 'bar', 'baz', 'qux']
# 或者是
regex = re.compile('\\s+')
regex.split(text)
- 如果想得到一个所有匹配正则表达式的模式的列表,可以使用findall方法;
- 为了在正则表达式中避免转义符\\的影响,可以使用原生字符串语法;
- findall返回的是字符串中所有的匹配项:
text = """Dave dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
Ryan ryan@yahoo.com
"""
pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\\.[A-Z]{2,4}'
# re.IGNORECASE makes the regex case-insensitive
regex = re.compile(pattern, flags=re.IGNORECASE)
regex.findall(text)
['dave@google.com', 'steve@gmail.com', 'rob@gmail.com', 'ryan@yahoo.com']
search返回的仅仅是第一个匹配项,匹配对象只能告诉我们模式在字符串中起始和结束的位置:
m = regex.search(text)
m
[out]
<re.Match object; span=(5, 20), match='dave@google.com'>text[m.start():m.end()]
[out]'dave@google.com'match更为严格,它只在字符串的起始位置进行匹配,如果没有匹配到,返回None:
print(regex.match(text))
[out]
None
sub会返回一个新的字符串,原字符串中的模式会被一个新的字符串替代:
print(regex.sub('REDACTED', text))
[out]
Dave REDACTED
Steve REDACTED
Rob REDACTED
Ryan REDACTED
用括号将模式包括起来,修改后的正则表达式产生的匹配对象的groups方法,返回的是模式组件的元组:
pattern = r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\\.([A-Z]{2,4})'
regex = re.compile(pattern, flags = re.IGNORECASE)
m = regex.match('wesm@bright.net')
m.groups()
[out]
('wesm', 'bright', 'net')
当模式可以分组时,findall返回的是包含元组的列表:
print(regex.sub(r'Username: \\1, Domain: \\2, Suffix: \\3', text))
[out]
Dave Username: dave, Domain: google, Suffix: com
Steve Username: steve, Domain: gmail, Suffix: com
Rob Username: rob, Domain: gmail, Suffix: com
Ryan Username: ryan, Domain: yahoo, Suffix: com正则化表达方式
| 方法 | 描述 |
|---|---|
| findall | 将字符串中所有的非重叠匹配模式以列表形式返回 |
| finditer | 与findall类似,但返回的是迭代器match在字符串起始位置匹配模式,也可以将模式组建匹配到分组中;如果模式匹配上了,返回匹配对象,否则返回None |
| search | 扫描字符串的匹配模式,如果扫描到了返回匹配对象,与match方法不同的是,search方法的匹配可以是字符串的任意位置,而不仅仅是字符串的起始位置 |
| split | 根据模式,将字符串拆分为多个部分 |
| sub, subn | 用替换表达式替换字符串中所有的匹配(sub)或第n个出现的匹配串(subn);使用\\1、\\2…来引用替换字符串中的匹配组元素 |
3、pandas中的向量化字符串函数
清理杂乱的数据集用于分析通常需要大量的字符串处理和正则化,包含字符串的列有时会含有缺失数据,使得情况变得复杂:
data = {'Dava': 'dave@google.com', 'Steve': 'steve@gmail.com', 'Rob': 'rob@gmail.com', 'Wes': np.nan}
data = pd.Series(data)
data
[out]
Dava dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
Wes NaN
dtype: objectdata.isnull()
[out]
Dava False
Steve False
Rob False
Wes True
dtype: bool可以使用data.map将字符串和有效的正则表达式方法(以lambda或其他函数的方式传递)应用到每个值上,但是在NA(null)值上会失败。为了解决这个问题,Series有面向数组的方法用于跳过NA值的字符串操作。这些方法通过Series的str属性进行调用:
data.str.contains('gmail')
[out]
Dava False
Steve True
Rob True
Wes NaN
dtype: object
正则表达式也可以结合任意的re模块选项使用:
pattern
[out]
'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\\\\.([A-Z]{2,4})'data.str.findall(pattern, flags = re.IGNORECASE)
[out]
Dava [(dave, google, com)]
Steve [(steve, gmail, com)]
Rob [(rob, gmail, com)]
Wes NaN
dtype: object