Python数据结构与算法-数据结构(列表、栈、队列、链表)

一、数据结构
1、数据结构定义
数据结构是指相互之间存在这一种或者多种关系的数据元素的集合和该集合中元素之间的关系组成。
简单来说,数据结构就是设计数据以何种方式组织并存储在计算机中。
比如:列表、集合与字典等都是一种数据结构。
N.Wirth:“程序=数据结构+算法”
2、数据结构的分类
数据结构按照其逻辑结构可分为线性结构、树结构和图结构。
(1)线性结构:数据结构中的元素存在一对一的相互关系。
(2)树结构:数据结构中元素存在一堆多的相互关系。
(3)图结构:数据结构中的元素存在多对多的相互关系。
二、列表(数组)
1、列表定义
列表(其他语言称数组)是一种基本数据类型。
2、关于列表的问题:
(1)列表是如何存储的?
按顺序存储,且存储的内容为该值的地址而非值。
(2)列表(Python)和数组(C语言等)的区别?
a.数组元素类型要相同。如果数组的元素类型不同就不能根据地址查找元素列表。地址=第一个元素的位置+索引*元素字节数量。
b.数组长度固定。创建数组需要提前给出数组的长度。
c.C语言数组按顺序存储的是值,Python的列表是按顺序存储的值的地址。
(3)列表的基本操作:按下标查找、插入元素、删除元素.......一系列操作,这些操作的时间复杂度是多少?
1)按下标查找操作的时间复杂度:O(1)
查找操作:一个整数所占字节数与一个地址所占字节数相同,在32位机器上是4字节。所以列表查找需要先通过列表第一个元素的位置+ 4 * 索引,得到该元素的地址,再通过地址找到对应的元素值。
2)插入、删除的时间复杂度:O(n)
插入或删除操作:找到需要对应位置后,插入一个元素,后续的元素都需要往后移动,因此操作了n次。在删除了某个元素后,列表后面的值都需要往前移动,也是进行了n次操作。
三、栈
1、栈的定义
栈(Stack)是一个数据集合,可以理解为只能在一端进行插入或删除操作的列表。
1)栈的特点:先进后出(后进先出)LIFO(last-in,first-out)
2)栈的概念:栈顶、栈底;
示意图如下:
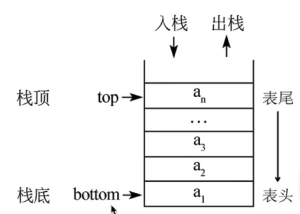
3)栈的基本操作:
进栈(压栈):push
出栈:pop
取栈顶:gettop
2、栈的实现
使用一般的列表结构即可实现栈。
a.进栈:li.append()
b.出栈:li.pop()
c.取栈顶:li[-1]
(1)代码实现
# 栈的基本操作stack
class Stack():def __init__(self):self.stack = [] #初始为空列表def push(self,element): #压栈 element:压入的值self.stack.append(element) #往空列表中添加值。# 不需要return是因为append添加后,需要输出的是现列表,而现列表不需要特意使用return来输出def pop(self): # 出栈 return self.stack.pop() # 用列表的删除函数pop(),并返回删除的值,得到出栈的数def get_top(self): # 取栈顶if len(self.stack) > 0: # 判断列表是否有数值return self.stack[-1] # 返回列表的最后一个值else:Nonestack = Stack() #类实例化
# 1.进栈
stack.push(2)
stack.push(6)
stack.push("hello")# 2.出栈
print(stack.pop())# 3.取栈顶
print(stack.get_top())结果输出:
hello
63、栈的应用:括号匹配问题
(1)括号匹配问题
1)问题
给一个字符串,其中包括小括号、中括号、大括号,求该字符串中的括号是否匹配。
2)工作原理
将左边的括号存入栈中,当遇到下一个右边括号与栈顶的左边括号匹配则出栈,不匹配留下。当最后栈内是空的时候,说明括号都匹配。
(2)代码实现
class Stack():def __init__(self):self.stack = [] #初始为空列表def push(self,element): #压栈 element:压入的值self.stack.append(element) #往空列表中添加值。# 不需要return是因为append添加后,需要输出的是现列表,而现列表不需要特意使用return来输出def pop(self): # 出栈 return self.stack.pop() # 用列表的删除函数pop(),并返回删除的值,得到出栈的数def get_top(self): # 取栈顶if len(self.stack) > 0: # 判断列表是否有数值return self.stack[-1] # 返回列表的最后一个值else:Nonedef is_empty(self): # 栈为空return len(self.stack) == 0 # 列表长度为0,为空栈# 括号匹配问题
def brace_match(str): # str为字符串stack = Stack() # 创建空栈match = {')': '(', ']': '[', '}': '{'} # 符号匹配字典for ch in str: # 遍历字符串里的每个字符if ch in {'(','[','{'}: # '(','[','{'的集合stack.push(ch) # 进栈else: # 符号不是'(','[','{'if stack.is_empty(): # 栈是空的,没有左边的括号入栈return False #报错elif stack.get_top() == match[ch]: #栈顶值对比stack.pop() # 出栈else: #栈顶值与括号不匹配 stack.get_top != match[ch]return Falseif stack.is_empty(): #遍历结束字符串,栈为空return True else: #栈不为空return Falseprint(brace_match('{([[]({}[]())])}'))
print(brace_match('[]{}([})'))输出结果:
True
False四、队列
1、队列的定义
队列(Queue)是一个数据集合,仅允许在列表的一端进行插入,另一端进行删除。
a.进行插入的一端为队尾(rear),插入动作称为进队或入队。
b.进行删除的一端称为队头(front),删除动作称为出队。
c.队列的性质:先进先出(First-in,First-out)。
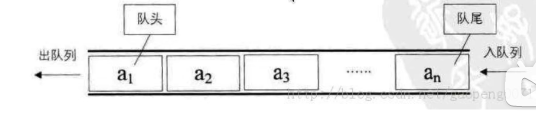
2、队列的实现
(1)队列的实现方式-环形队列
1)使用环形队列,如下图:
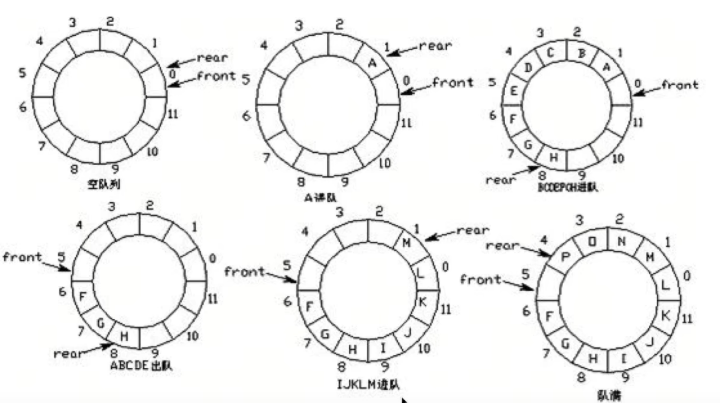
其中,rear(队尾)和front(队头)初始位置都是0,队满的时候为了区分与初始队空的区别,牺牲一小点点内存,其中一小格无数据。每次有数据插入,则队尾rear指针往前移动,每次数据出队时,队头front往前移动。
2)实现环形队列的内部关系
环形队列:当队尾指针front == Maxsize + 1时,再前进一个位置就自动到0。(Maxsize是队列的大小)
-
队首指针前进1:front = (front + 1)%Maxsize
-
队尾指针前进1:rear = (rear +1)%Maxsize
-
队空条件:rear == front
-
队满条件:(rear +1)%Maxsize == front
(2)队列代码实现
# 实现简单的队列
class Queue(): # 队列,类的括号里填的是继承关系def __init__(self,size): #初始化属性设置self.queue = [0 for i in range(size)] # 创建初始列表,列表长度确定且都为0self.size = size # 队列规模self.rear = 0 # 队尾指针初始位置self.front = 0 # 队首指针初始位置def push(self, element): # 入队if not self.is_filled(): # 队列不满才能入队self.rear = (self.rear + 1) % self.size # 找到插入队列的位置self.queue[self.rear] = element # 填入元素else:# 报错,raise()函数,手动设置异常,IndexError异常指列表索引超出范围raise IndexError("Queue is filled.") def pop(self): # 出队if not self.is_empty(): # 队列不空才能出队self.front = (self.front + 1) % self.size # 找到队尾最后一个元素要删除的位置,最开始front指针指向空位return self.queue[self.front] # 返回这个值,不需要pop操作,后续插入的数值可直接覆盖,pop的时间复杂度较高else:raise IndexError("Queue is empty.")def is_empty(self): # 队列是否为空return self.rear == self.front # 队尾与队首的位置相同时,队列为空,即两者相同时,返回Truedef is_filled(self): # 队满return self.front == (self.rear + 1) % self.size # 队尾往前一步是队首的时候,将返回Truequeue = Queue(10) #队列实例化# 1.入队
for i in range(9):queue.push(i)# 2.出队
print(queue.pop())# # 3.队空或队满判断
print(queue.is_empty())
queue.push(9)
print(queue.is_filled())结果输出:
0
False
True3、队列的内置模块
(1)双向队列
双向队列的两端都支持进队和出队操作。
双向队列的基本操作:
a.队首进队
b.队首出队
c.队尾进队
d.队尾出队
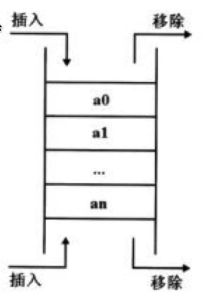
(2)python队列内置模块的基本函数
模块:from collections import deque
-
创建队列:queue = deque(),空队列。
-
deque(列表,size):可以传入两个参数,第一个是用于创建非空队列,传入列表数据;size是指定列表的规模大小。
-
其中,deque()队满的不会报错,而是前面的数据将自动出队。
-
队尾进队:append()
-
队首出队:popleft()
-
队首进队:appendleft()
-
队尾出队:pop()
(3)内置模块实现队列代码
from collections import deque # 双向队列模块# 单向队列
que = deque() # 创建空队列
que.append(1) # 队尾进队
print(que.popleft()) # 队首出队# 用于双向队列
que.appendleft(2) # 队首进队
print(que.pop()) # 队尾出队# deque()参数应用
que2 = deque([0,1,2,3,4], 5) # 创建非空队列,且定义队列的规模为5
que2.append(5) # 队满,仍进队
print(que2.popleft()) # 队满进队后,原队首数据自动出队,现出队数据为1.输出结果:
1
2
1(4)读取文件的最后几行——队列模块的队满性质
读取文件的后几行的普通操作是先读取整个文件,再切片后几行,这样操作的内存占比大。可以使用deque()模块的性质,队满后入队,前面数据自动出队,可以更高效快捷的获取文件后面的内容。但是读取文件前面的内容,直接使用readline()函数即可。
如果需要读取txt文件的中文进队列,需要更改中文的编码为字节类型,否则无法读取GBK格式。
代码实现:
# deque()队满性质-另一端自动出队
# 读取文件的后几行,普通操作,读取整个文件,切片后几行,内存占比大
def tail(n): # n是需要读取的数量with open('p52_test.txt', 'r') as f: # with语句自动化关闭资源,不需要手动关闭q = deque(f, n) # 队列内容为文件f,队列规模为n,获取队尾的n列return qfor line in tail(4):print(line, end = "")结果输出:
My pillow is my best friend,
it makes me feel comfortable when I sleep.
My bed is also very comfortable,
it's where I spend most of my time.(5)队列模块代码总结
1)with语句的应用
with语句是 Python 中的一种常用语法,用于自动化地管理对象的生命周期。它通常用于打开资源,例如文件、数据库连接等,并在代码块结束时自动关闭这些资源。
with的语法结构:
with object [as variable] [try-except-finally]: code_block # 代码块解释:
object:管理的资源对象,例如,文件、数据库连接等。
Variable:自定义存储资源对象的变量。可以理解为 Variable = object。
try-except-finally:是 with 语句的可选部分,用于处理在代码块中发生错误的情况。
with的简单例子,with语句能支持打开多个文件:
with open('file1.txt', 'w') as f1, open('file2.txt', 'w') as f2: f1.write('Hello, file1!') f2.write('Hello, file2!') 五、栈和队列的应用:迷宫问题
1、迷宫问题
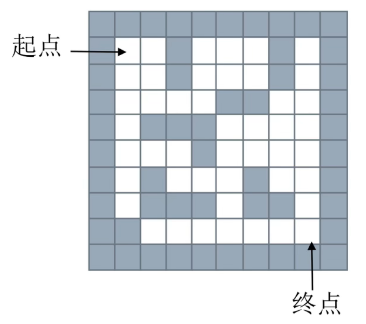
给一个二维列表,表示迷宫(0表示通道,1表示围墙)。给出算法,求一条走出迷宫的路径。
如下图所示:
 |
 |
2、栈的解题
(1)栈的思路——深度优先搜索
深度优先搜索,又称为回溯法。
解题思路:
-
从一个节点开始,任意找到下一个能走的点,当找不到能走的点时,退回上一个点寻找是否有其他方向的点。(回退前走过的点将会标记为不能走的点。)
-
使用栈存储当前路径。
优劣:
优点:代码简单;
缺点:不一定得到的是最短路径。
(2)代码实现
# 迷宫问题
#迷宫
maze = [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]dirs = [lambda x, y: (x+1, y),lambda x, y: (x, y+1),lambda x, y: (x-1, y),lambda x, y: (x, y-1)
] # lambda函数,匿名函数,是简单函数的简写版本# 向下,右,向上,左顺序寻找# 迷宫求解
def maze_path(x1,y1,x2,y2): #(x1,y1)表示初始起点,(x2,y2)表示终点坐标stack = [] # 创建空栈,栈内存储元组,即各点坐标stack.append((x1, y1)) #起点位置进栈,(x1,y1)为起点坐标的元组while len(stack) > 0: #栈不空时,栈空没有路curNode = stack[-1] #栈顶位置,当前节点的坐标(x,y)if curNode[0] == x2 and curNode[1] == y2: # 当前节点为终点for p in stack: #遍历输出坐标点print(p)return True# 当前坐标的四个方向,(x+1,y)/(x-1,y)/(x,y+1)/(x,y-1),坐标移动for dir in dirs: # dir为一个lambda式,输出为元组nextNode = dir(curNode[0],curNode[1]) # dir的lambda式需要x,y两个参数,curNode[0]=x,curNode[1]=y# 下一个节点能走,即值为0if maze[nextNode[0]][nextNode[1]] == 0: #二维列表取数用maze[x][y],x=nextNode[0],y=nextNode[1]stack.append(nextNode) # 进栈maze[nextNode[0]][nextNode[1]] = 2 # 表示该点走过了break # 只要找到一个可以走的位置就结束for循环else:stack.pop() # 出栈# while循环中没有return,则未找到路 print("没有路")return Falsemaze_path(1,1,8,8)输出结果:
(1, 1)
(2, 1)
(3, 1)
(4, 1)
(5, 1)
(5, 2)
(5, 3)
(6, 3)
(6, 4)
(6, 5)
(7, 5)
(8, 5)
(8, 6)
(8, 7)
(8, 8)(3)代码说明
1)与视频中代码对比,做了2点修改:
-
遍历for循环后,不需要再运行 maze[nextNode[0]][nextNode[1]] = 2 这一步,因为无法找到出路,说明四周可能都是墙以及走过的路,走过的路已经是2了,墙没必要改成2。
-
结束while循环后,不需要写else,本身就是不达到while循环条件才结束的循环,运行下面的代码。若在满足while循环中就已经得到结果,会直接return输出,不会在继续运行代码。
2)for....else...语法
for 临时变量 in 序列:重新执行代码块return
else:for循环正常结束未执行return,则执行的代码所谓else指的是循环正常结束后要执行的代码,即如果是break终止循环或者return结束循环的情况,else下方缩进的代码将不执行。
3)lambda表达式的运用
lambda 表达式,又称匿名函数,常用来表示内部仅包含 1 行表达式的函数。如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。
lambda表达式:
name = lambda [list]:表达式[list]表示可选参数,等同于定义函数的参数;name为该表达式的名称。
对比普通写法与lambda表达式:
# 简单函数写法
def add(x, y):return x + y#转化为lambda表达式
add = lambda x, y: x + y3、用队列解决迷宫问题
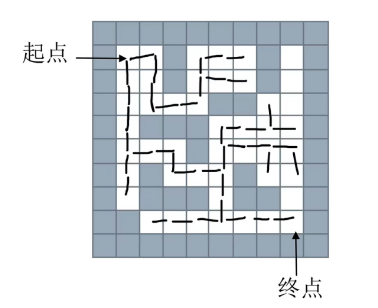
(1)队列的思路—广度优先搜索
1)基本思路
从一个节点开始,寻找所有接下来能继续走的点,继续不断寻找,直到找到出口。
使用队列存储当前正在考虑的节点。
2)实现思路的操作
转换为具体的位置示意图:
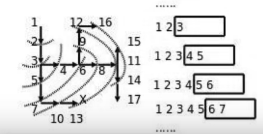
-
找到1,入队,[1];
-
找到2,1出队,2入队, [2];
-
找到3,2出队,3入队,[3];
-
找到4和5,3出队,4和5入队,[4,5];
-
4找到6,4出队,6入队,[5,6];
-
5找到7,5出队,7入队,[6,7];
-
.........依次类推,队列中存储正在考虑的节点。
-
直到找到终点位置的坐标,再倒回去根据存储在另一个列表的索引找到对应之前的值。如下图,
第一行为队列中依次出队的数字,第二队为当前数字的前一个数字在列表中的索引。
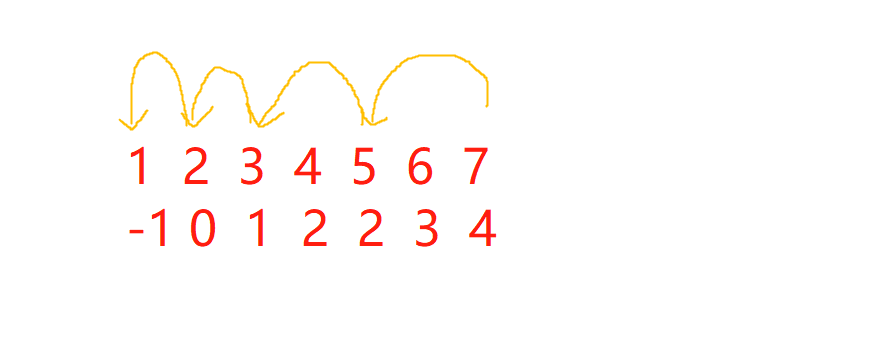
(2)代码实现
# 用队列求解迷宫问题
from collections import deque # 调用队列模块
#迷宫
maze = [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]dirs = [lambda x, y: (x+1, y),lambda x, y: (x, y+1),lambda x, y: (x-1, y),lambda x, y: (x, y-1)
] # lambda函数,匿名函数,是简单函数的简写版本# 向下,右,向上,左顺序寻找def print_r(path): # 根据元组最后一位索引值,找到前一个点元素,依次输出点的坐标。path为含有三维元组的列表curNode = path[-1] # 当前的元素为列表的最后一个元素,可以理解为终点为最后一个元素realpath = [] # 存储找到的路径所经过的点坐标while curNode[2] != -1: # 当前不是起点坐标,则循环,从终点开始往回倒。realpath.append(curNode[0:2]) # 循环最开始的curNode是终点,将其坐标添加到路径列表中,后续的元素为根据终点倒推的点curNode = path[curNode[2]] #curNode[2]是经过现在点的上一个点在path列表中的下标,根据下标找到该点的值,并替换curNoderealpath.append(curNode[0:2]) # 结束while循环,当需要将起点加入到路径列表中,起点即为curNode[2]==-1的点realpath.reverse() # 列表中数据的反转for n in realpath: #遍历打印路径的各点print(n) def maze_path_queue(x1,y1,x2,y2): # 输入起点和终点queue = deque() # 创建空队列queue.append((x1,y1,-1)) # 起点坐标进队,最后一位存储的是上一个点坐标在列表中的下标,起点前没有元素,指定为-1path = [] # 存储所有出队的点坐标while len(queue) > 0: # 队列不为空,队列空了就没路了curNode = queue.popleft() # 目前的点坐标为队列的队首,并出队path.append(curNode) # 出队的点加入到列表中if curNode[0] == x2 and curNode[1] == y2: # 现坐标点与终点坐标一致,找到终点print_r(path) # 自定义函数,输出path列表中相应的值return Truefor node in dirs: # 遍历上下左右找下一个可以走的点nextNode = node(curNode[0],curNode[1]) #下一个点的坐标if maze[nextNode[0]][nextNode[1]] == 0: # 下一个点坐标对应的值为0,路可以走queue.append((nextNode[0], nextNode[1], len(path)-1)) # 每次循环的curNode位于path的最末尾maze[nextNode[0]][nextNode[1]] = 2 # 标记该点已走else:print("no path")return False maze_path_queue(1,1,8,8)输出结果:
(1, 1)
(2, 1)
(3, 1)
(4, 1)
(5, 1)
(5, 2)
(5, 3)
(6, 3)
(6, 4)
(6, 5)
(7, 5)
(8, 5)
(8, 6)
(8, 7)
(8, 8)(3)代码说明
1)对视频中的2处错误做了修正:
-
第44行,队列是从队首出队,所以是popleft()函数。
-
第30行,curNode[2] != -1,表示到达起点后不循环,视频中用的==是错误的。
2)reverse()函数
python中列表的一个内置方法(在字典、字符串和元组中没有这个内置方法),用于列表中数据的反转。
代码示例:
li = [4, 3, 2, 1]
li.reverse()
print(li)#输出结果
[1, 2, 3, 4]六、链表
1、定义
(1)概念
链表是由一系列节点组成的元素集合。每个节点包含两部分,数据域item和指向下一个节点的指针next。通过节点之间的相互连接,最终串联成一个链表。

(2)链表节点基本写法
class Node(object):def __init__(self, item):self.item = itemself.next = None(3)手动链表简单实现
# 链表实现
class Node():def __init__(self, item): # 初始化self.item = itemself.next = None # 最初不存在# 传入节点数据
a = Node(1) #类实例化为对象
b = Node(2)
c = Node(3)# 创建链接
a.next = b # a的下一个是b
b.next = c # b的下一个是cprint(a.item) #输出为1
print(a.next.item) # 输出为b点,2
print(a.next.next.item) # 输出为c点,3
print(b.item)
print(b.next.item) #输出为c点,3输出结果:
1
2
3
2
32、链表的创建和遍历
创建链表的方法有头插法和尾插法。
(1)创建链表-头插法

首先,如上图所示,需要有一个head指针,head指向头节点,当前面再插入新的元素时,head指针更新,重新指向新的头节点,而新插入的节点与前一个节点建立链接,结果如下图。
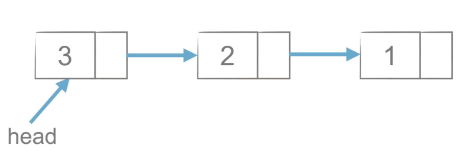
(2)创建列表-尾插法
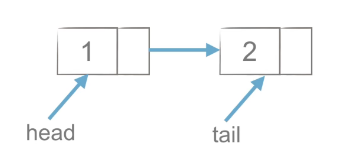
如上图所示,尾插法需要有head和tail两个指针,当有新元素插入是,从链表的尾部插入,且tail指针向后移动,结果如下图。
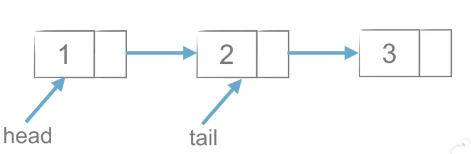
(3)头插法-代码实现
# 链表的创建与遍历
class Node():def __init__(self, item):self.item = itemself.next = None# 头插法
def creat_linklist_head(li): # 传入参数为列表head = Node(li[0]) # 最开始的head指针,指向列表第一个元素for element in li[1:]: # 从列表的第2个元素开始插入到列表中node = Node(element) # 列表元素传入链表节点node.next = head # 将该节点与前一个点链接head = node # 指针head指向新插入的元素return head # 返回链表的第一个元素# 遍历链表
def print_lk(lk): # 参数lk:链表while lk: # lk.next不为noneprint(lk.item, end = " ") # 打印值lk = lk.next # 进入下一个点lk = creat_linklist_head([1,2,3])
print_lk(lk)输出结果:
3 2 1 (4)尾插法-代码实现
# 链表的创建与遍历
class Node():def __init__(self, item):self.item = itemself.next = None#尾插法
def creat_linklist_tail(li): # 参数li:列表head = Node(li[0]) # head节点指针,传入链表的第一个元素tail = head # 起始的tail指针也是第一个元素# tail = Node(li[0]) 这么写会创建两个不同的对象,导致后面的for循环只在tail上执行。for element in li[1:]: # 从列表的第2位开始加入到链表node = Node(element) # 节点的值tail.next = node # 从链表尾部节点链接到该点tail = node # 移动tail指针,指向新加入链表的nodereturn head # 从链表的头到尾输出,首先仍需返回head# 遍历链表
def print_lk(lk): # 参数lk:链表while lk: # lk.next不为noneprint(lk.item, end = " ") # 打印值lk = lk.next # 进入下一个点lk_tail = creat_linklist_tail([1,4,8,6,3])
print_lk(lk_tail)输出结果:
1 4 8 6 3 注意:第11行代码,之所以不用tail = Node(li[0]),而是tail = head,虽然其表达的意义相同,但是由于Node是类,因此tail = Node(li[0])是创建了新的对象,和head不是同一个对象,后续的操作只会在tail这个对象上进行与head对象无关,导致链表链接过程中,head指针是脱离了后续创建的链表。
(5)链表的遍历
1)基本思想
先找到链表的第一个元素,根据lk.next往下找到链表的下一个元素,知道lk.next= none,即该点为最后一个元素。可以使用while循环实现。
2)代码实现
# 遍历链表
def print_lk(lk): # 参数lk:链表while lk: # lk.next不为noneprint(lk.item, end = " ") # 打印值lk = lk.next # 进入下一个点3、链表的插入与删除
(1)链表的插入
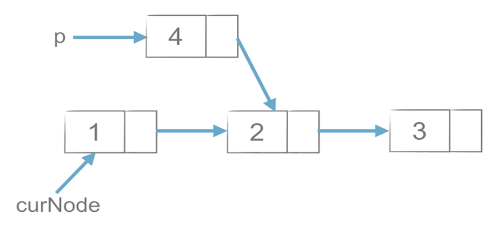
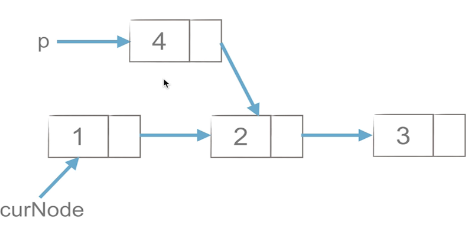
1)工作思路
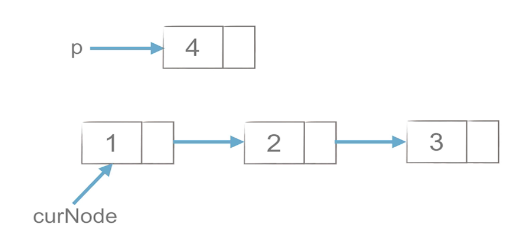 |
 |
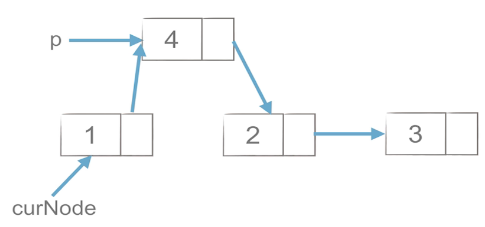 |
如上图所示,p元素需要插入到链表中,需要先将p元素与curNode.next元素连接,否则一旦curNode与后面的连接断开,那么curNode与后面的一系列链表就失去联系了,再将curNode与p元素连接。可以理解为:插入p,先p尾,后p头。
2)代码实现思路
p.next = curNode.next # 先连尾
curNode.next = p #再连头(2)链表的删除
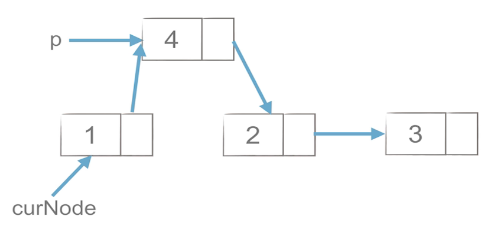
1)工作思路
 |
 |
如上图所示,删除p点元素,首先将curNode与p.next链接上,再删除p点。因为先删除p点会导致curNode与后面的链表失联。
2)代码实现思路
curNode.next = p.next #或 curNode = curNode.next.next 与curNode与p点后面的值连接
del p #删除p点(3)链表的插入与删除代码示例
# 链表的创建与遍历
class Node():def __init__(self, item):self.item = itemself.next = None# 头插法
def creat_linklist_head(li): # 传入参数为列表head = Node(li[0]) # 最开始的head指针,指向列表第一个元素for element in li[1:]: # 从列表的第2个元素开始插入到列表中node = Node(element) # 列表元素传入链表节点node.next = head # 将该节点与前一个点链接head = node # 指针head指向新插入的元素return head # 返回链表的第一个元素# 尾插法
def creat_linklist_tail(li): # 参数li:列表head = Node(li[0]) # head节点指针,传入链表的第一个元素tail = head # 起始的tail指针也是第一个元素# tail = Node(li[0]) for element in li[1:]: # 从列表的第2位开始加入到链表node = Node(element) # 节点的值tail.next = node # 从链表尾部节点链接到该点tail = node # 移动tail指针,指向新加入链表的nodereturn head # 从链表的头到尾输出,首先仍需返回head# 遍历链表
def print_lk(lk): # 参数lk:链表while lk: # lk.next不为noneprint(lk.item, end = " ") # 打印值lk = lk.next # 进入下一个点#创建链表
lk_head = creat_linklist_head([1,2,3])
lk_tail = creat_linklist_tail([1,4,8,6,3])# 删除链表元素
curNode = lk_tail # 定义目前的节点,是lk_tail的head
p = curNode.next # 要删除的点是curNode后面的元素
curNode.next = curNode.next.next #将curNode与p后面的元素连接
print_lk(lk_tail) # 插入链表
p = Node(6) # 插入的点
curNode = lk_head # curNode的值
p.next = curNode.next # p点尾部与插入位置的后一个元素连接
curNode.next = p # p点与前面的curNode连接
print_lk(lk_head)输出结果:
1 8 6 3 3 6 2 1 (4)时间复杂度
由于链表不是按照顺序存储的,而是通过next连接在一起,因此删除和插入不需要大量的移动列表其他元素的位置,时间复杂度=O(1)。
七、双链表
1、双链表定义
双链表的每个节点有两个指针:一个指向后一个节点,另一个指向前一个节点。示意图如下:
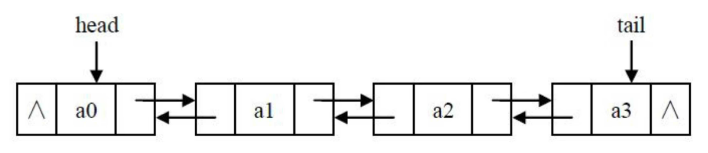
2、创建双链表
class Node(object):def __init__(self,item):self.item =itemself.next = Noneself.prior = None3、双链表的插入和删除
(1)双链表的插入
1)工作思路
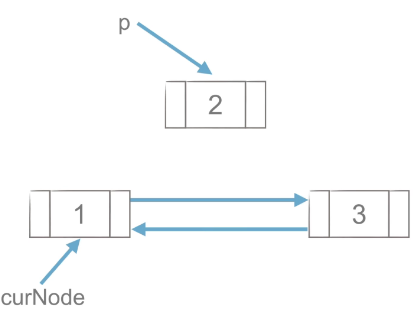 |
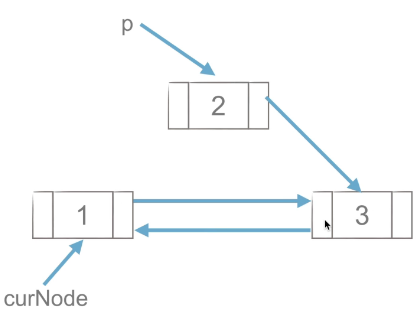 |
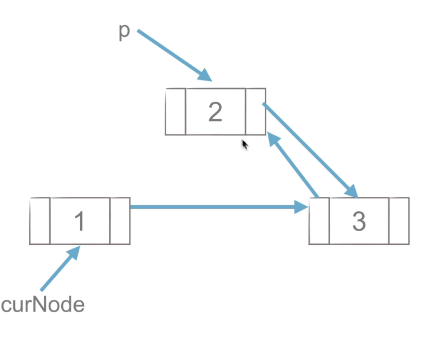 |
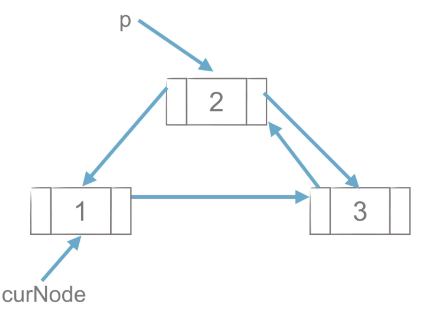 |
 |
工作思路如上图,p点先与后面的节点创建链接,在于前面的点创建链接,与单链表的插入流程类似。
代码实现思路:
p.next = curNode.next
curNode.next.prior = p
p.prior = curNode
curNode.next = p(2)双链表的删除
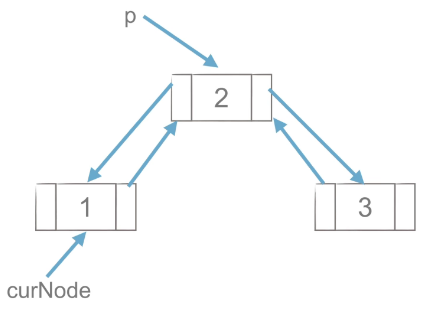
1)工作思路
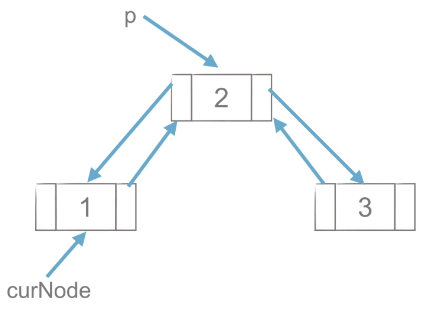 图1 |
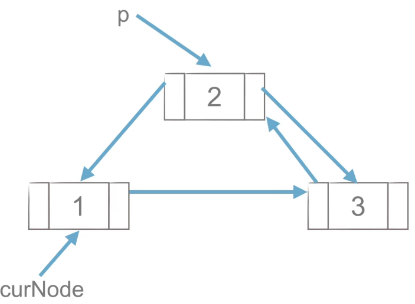 图2 |
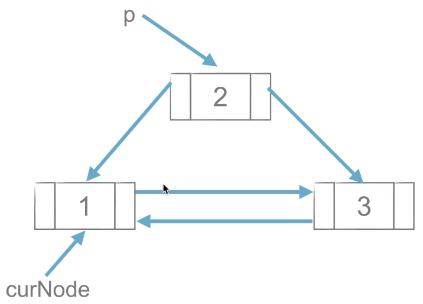 图3 |
如上图所示,先创建CurNode点与p后面的点的双向链接,再删除p点,思路与单链表的删除操作类似。
2)代码实现思路
p = curNode.next # 指定p点
curNode.next = p.next # 或curNode.next.next 创建与后面点的链接
p.next.prior = curNode # 创建与前面的点链接
del p # 删除p八、链表总结
1、链表与列表-复杂度分析
|
项目\\数据结构 |
顺序表(列表/数组) |
链表 |
|
按元素值查找 |
O(n) |
O(n) |
|
按下标查找 |
O(1) |
O(n) |
|
在某元素后插入 |
O(n) |
O(1) |
|
删除某元素 |
O(n) |
O(1) |
2、链表的优点
(1)链表在插入和删除操作上明显快于顺序表;
(2)链表的内存可以更灵活分配;
-
列表在创建初始是固定的规模,扩大规模需要重新开内存。
(3)链表这种链式存储的数据结构对树和图的结构有很大的启发性。