Java Map集合使用

Map接口专门处理键值映射数据的存储,可以根据键实现对值的操作。
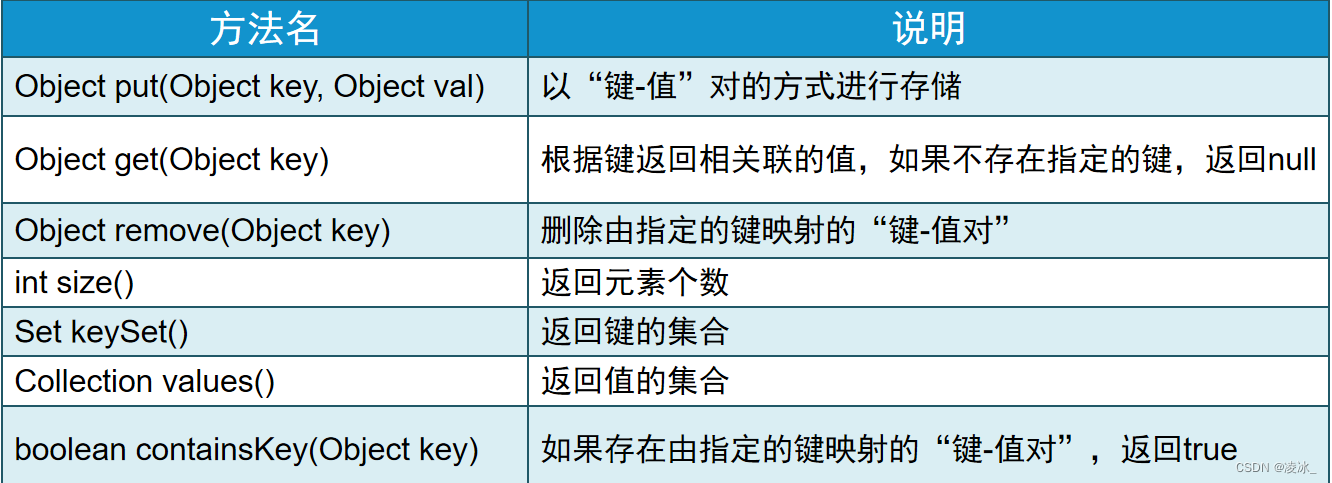
一、Map集合常用方法
二、Map集合简单操作
//Map集合Map map = new HashMap();System.out.println("集合大小:" + map.size());//添加 key=valuemap.put("CN", "中国");map.put("FR", "法国");map.put("US", "美国");map.put("JP", "日本");System.out.println("集合大小:" + map.size());System.out.println(map.toString());//通过key 找到数据System.out.println(map.get("CN"));//通过key 删除数据map.remove("US");System.out.println(map.toString());//是否包含这个key,包含是true;System.out.println(map.containsKey("HK"));System.out.println(map.containsKey("CN"));System.out.println(map.containsValue("香港"));//遍历数据//所有的keySet keys = map.keySet();System.out.println(keys.toString());//所有的valueCollection values = map.values();System.out.println(values.toString());System.out.println("通过key找到value");for (Object key :keys) {System.out.println(key + "=>" + map.get(key));}System.out.println("直接获取key和value");Set sets = map.entrySet();//迭代器对象Iterator it=sets.iterator();while(it.hasNext()){System.out.println(it.next());}
三、HashMap类实现的Map集合遍历方式及其性能对比
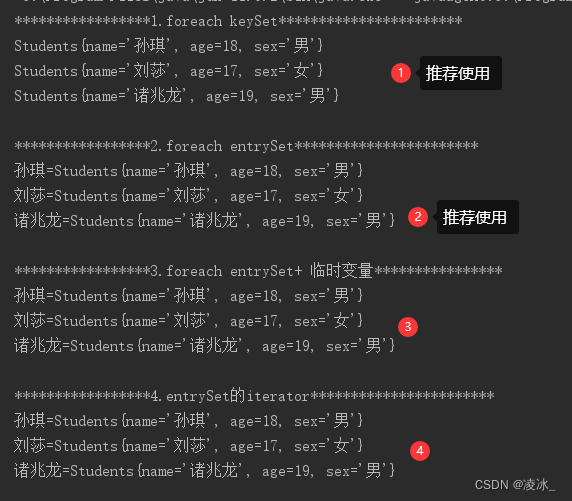
//泛型集合Map<String, Students> map = new HashMap();//学生对象Students stu1 = new Students("孙琪", 18, "男");Students stu2 = new Students("刘莎", 17, "女");Students stu3 = new Students("诸兆龙", 19, "男");//key 是学生名,value 是对象名map.put(stu1.getName(), stu1);map.put(stu2.getName(), stu2);map.put(stu3.getName(), stu3);// for-each map.keySet() -- 只需要K值的时候System.out.println("*1.foreach keySet*");for (String key:map.keySet()) {System.out.println(map.get(key));}//:for-each map.entrySet() -- 当需要k和V的时候System.out.println("\\n*2.foreach entrySet*");for (Map.Entry<String, Students> entry:map.entrySet()) {System.out.println(entry.getKey()+"="+entry.getValue());}//: for-each map.entrySet() + 临时变量System.out.println("\\n*3.foreach entrySet+ 临时变量");Set<Map.Entry<String, Students>> sets= map.entrySet();for (Map.Entry<String, Students> entry:sets) {System.out.println(entry.getKey()+"="+entry.getValue());}//:for-each map.entrySet().iterator()System.out.println("\\n*4.entrySet的iterator*");Iterator<Map.Entry<String, Students>> it= map.entrySet().iterator();while(it.hasNext()){//获取到Entry对象Map.Entry<String, Students> entry=it.next();System.out.println(entry.getKey()+"="+entry.getValue());}效果:
四、HashMap 的工作原理?
HashMap 底层是 hash 数组和单向链表实现,数组中的每个元素都是链表,由 Node 内部类(实现 Map.Entry<K,V>接口)实现,HashMap 通过 put & get 方法存储和获取。
存储对象时,将 K/V 键值传给 put() 方法:
①、调用 hash(K) 方法计算 K 的 hash 值,然后结合数组长度,计算得数组下标;
②、调整数组大小(当容器中的元素个数大于 capacity * loadfactor 时,容器会进行扩容resize 为 2n);
③、i.如果 K 的 hash 值在 HashMap 中不存在,则执行插入,若存在,则发生碰撞;
ii.如果 K 的 hash 值在 HashMap 中存在,且它们两者 equals 返回 true,则更新键值对;
iii. 如果 K 的 hash 值在 HashMap 中存在,且它们两者 equals 返回 false,则插入链表的尾部(尾插法)或者红黑树中(树的添加方式)。(JDK 1.7 之前使用头插法、JDK 1.8 使用尾插法)
(注意:当碰撞导致链表大于 TREEIFY_THRESHOLD = 8 时,就把链表转换成红黑树)获取对象时,将 K 传给 get() 方法:①、调用 hash(K) 方法(计算 K 的 hash 值)从而获取该键值所在链表的数组下标;②、顺序遍历链表,equals()方法查找相同 Node 链表中 K 值对应的 V 值。
hashCode 是定位的,存储位置;equals是定性的,比较两者是否相等

五、HashMap & TreeMap & LinkedHashMap 使用场景?
一般情况下,使用最多的是 HashMap。
HashMap:在 Map 中插入、删除和定位元素时;
TreeMap:在需要按自然顺序或自定义顺序遍历键的情况下;
LinkedHashMap:在需要输出的顺序和输入的顺序相同的情况下。
六、HashMap 和 HashTable 有什么区别?
①、HashMap 是线程不安全的,HashTable 是线程安全的;
②、由于线程安全,所以 HashTable 的效率比不上 HashMap;
③、HashMap最多只允许一条记录的键为null,允许多条记录的值为null,而 HashTable 不允许;
④、HashMap 默认初始化数组的大小为16,HashTable 为 11,前者扩容时,扩大两倍,后者扩大两倍+1;
⑤、HashMap 需要重新计算 hash 值,而 HashTable 直接使用对象的 hashCode
七、HashMap,LinkedHashMap,TreeMap 有什么区别?
相同点:
三者在特定的情况下,都会使用红黑树; 底层的 hash 算法相同; 在迭代的过程中,如果 Map 的数据结构被改动,都会报 ConcurrentModificationException 的错误。
不同点:
HashMap 数据结构以数组为主,查询非常快,
TreeMap 数据结构以红黑树为主,利用了红黑树左小右大的特点,可以实现 key 的排序, LinkedHashMap 在 HashMap 的基础上增加了链表的结构,实现了插入顺序访问和最少访问删除两种策略;