Python机器学习:评价指标

昨天 和前天带着大家看了比较简单的线性回归、逻辑回归、最大熵模型,基本上把原理搞清楚了,但是,对这些模型的计算效果,我们怎么去平均呢,这是个很大的问题,模型的好坏,的确是需要用评价指标去评价的,所以,我们今天来学习一些常用的模型评价指标:
一、混淆矩阵:
混淆矩阵时理解大多数评价指标的基础,直接给出一个表格:
| 真实值 | 预测值 | |
|---|---|---|
| 0 | 1 | |
| 0 | True、Negative(TN) | Fales、Positive(FP) |
| 1 | False、Negative(FN) | True、Positive(TP) |
真阴率(TN):实际是负样本预测成负样本的样本数
假阳率(FP):实际是负样本预测成正样本的样本数
假阴率(FN):实际是正样本预测成负样本的样本数
真阳率(TP):实际是正样本预测成正样本的样本数
实际上,FN、FP,都是预测错了的,TN、TP都是预测对了的,大部分的评价指标都是建立在混淆矩阵上的,包括准确率、精确率、召回率、F1score、AUC等。
二、准确率:
这是最常见的一项指标,就是预测正确的结果占总样本的百分比,:
准确率可以判断总的准确率,但是在样本不平衡的情况下,并不能够作为很好的指标来衡量结果,如果我们仅仅是使用准确率这一单个指标进行评价,模型可以“偷懒”获得很高的评分,所以,也就需要其他的评价策略来进行:
三、精确率和召回率:
精确率(Procession)又叫查准率,时针对预测结果而言的,精确率标志在所有被预测为正的样本中实际为正的样本的概率:
召回率(Recall)又叫查全率,表示在实际为正的样本中被预测为正样本的概率:
召回率一般应用于漏检后果严重的场景下,召回率越高,代表着负样本被预测出来的概率越高
四、PR曲线:
分类模型对每个样本点都会输出一个置信度,通过设置置信度的阈值,就可以完成分类,不同的置信度阈值对应着不用的精确率和召回率,一般来说,置信度阈值较低时,大量样本被预测为政治,召回率较高;精确度较低的时候,置信度阈值较高,大量样本被预测为负例,召回率较低,精确率较高,PR曲线以精确率为纵坐标,以召回率为横坐标。
五、ROC曲线、AUC曲线
我们假设,有一个二分类分类器,输出结果标签(0\\1)往往取决于置信度有一集预定的置信度阈值,实际上,这种阈值的选择一定程度上反映了分类器的分类性能,我们期望的时,无论选取所打的阈值,分类都尽可能的正确,为了衡量这种能力,ROC曲线进行了表征:
横轴:假阳率:
纵轴:真阳率:
很显然,ROC曲线的横纵坐标都在[0,1]之间,面积不大于1。
(0,0):分类器全部预测成负样本
(0,1):全部完美预测正确
(1,0):全部完美预测错误
(1,1):分类器全部预测成正样本
随机分类器的效果:TPR=FPR,就是一条斜对角线,如果ROC曲线在对角线以下,表明该分类器效果差于随机分类器,繁殖就是好于随即分类器,我们最希望的就是ROC曲线尽量位于斜对角线上,即左上角(0,1)凸。
好了,昨天的课后例子可以看到,模型在训练集上的准确率是0.947253,在测试集上的准确率是0.9386596,为了进一步分析模型效果,书后有给出了模型在测试集上的准确率、召回率、精确率:
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
y_pred=model.predict(x_test)
accuracy_score_value=accuracy_score(y_test,y_pred)
recall_score_value=recall_score(y_test,y_pred)
precision_score_value=precision_score(y_test,y_pred)
classification_report_value=classification_report(y_test,y_pred)
print("准确率:",accuracy_score_value)
print("召回率:",recall_score_value)
print("精确率:",precision_score_value)
print(classification_report_value)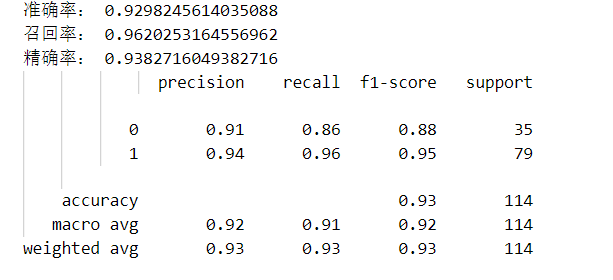
注意,刚才第一次汉字输出成了乱码,emm,我查了查,可以在代码前面加上这三行代码,就不会出错了:
import sys
import io
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')ok,今天就到这里吧,消化消化,明天开始K-邻近算法。