【Java 数据结构与算法】-TopK+Map题前K个高频单词+PriorityQueue

作者:学Java的冬瓜
博客主页:☀冬瓜的主页🌙
专栏:【Java 数据结构与算法】
内容:TopK+Map题前K个高频单词+PriorityQueue的问题
文章目录
-
- 前K个高频单词
-
-
- 1、有缺陷的代码:
- 2、代码的步骤整理:
- 3、PriorityQueue的poll源码分析
- 4、正确的代码
-
前K个高频单词
1、有缺陷的代码:
链接:【LeetCode692.前K个高频单词】
class Solution {public List<String> topKFrequent(String[] words, int k) {// 1、统计每个单词出现的次数Map<String, Integer> map = new HashMap();for(String s : words) {if(map.get(s) == null){map.put(s,1);}else{int val = map.get(s);map.put(s, val+1);}}// 注意:需要给minHeap传一个比较器,因为entry本身不可比较PriorityQueue<Map.Entry<String,Integer>> minHeap =new PriorityQueue<>(new Comparator<Map.Entry<String, Integer>>() {@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {// 注意:要把下面这段代码放出来才能正确运行:// entry和topHeap的value相等时,以key从小到大排序,是大堆的方式。//if (o1.getValue().compareTo(o2.getValue()) == 0){//return o2.getKey().compareTo(o1.getKey());//}return o1.getValue().compareTo(o2.getValue());}});// 注意:题目要求先以次数(value)从大到小打印,次数相等的以字母(key)从小到大打印// 2、遍历Map,把key和value打包成entry,然后把前k个放入小堆priorityQueue中,// 之后的元素entry的value就和小堆中堆顶元素的value比较,比topHeap大,就让topHeap出堆,entry入堆// 如果value相等,那就用key比较,比topHeap的key小的entry入堆(相当于在value相等的元素使用大堆排序)Set<Map.Entry<String,Integer>> set = map.entrySet();for (Map.Entry<String,Integer> entry : set) {if(minHeap.size() < k){minHeap.offer(entry);}else {Map.Entry<String,Integer> topHeap = minHeap.peek();if (entry.getValue().compareTo(topHeap.getValue()) > 0){minHeap.poll();minHeap.offer(entry);} else if (entry.getValue().compareTo(topHeap.getValue()) == 0) {if (entry.getKey().compareTo(topHeap.getKey()) < 0){minHeap.poll();minHeap.offer(entry);}}}}// 3、把minHeap中的entry出堆同时把的key逐个存入listList<String> list = new ArrayList<>();while(minHeap.size() > 0){String key = minHeap.poll().getKey();list.add(key);}// 4、因为此时key集合是从小堆中拿出的,在list中的顺序次数是从小到大// 调用Collections的reverse方法转置key集合,让key集合变成大到小Collections.reverse(list);return list; }
}
2、代码的步骤整理:
-
我们来理一理上面代码的思路:
首先这道题要求前k个高频单词,很明显是TopK问题,需要特别注意的是当频率相同时,则按照字典排序这个要求。 -
TopK问题就可以使用小堆来实现,
TopK的思路:把数组的前K个元素逐个插入小堆中,在插入后面n-k个元素时,让该元素和堆顶元素(堆中最小的元素)比较,如果比堆顶元素大,那就把堆顶元素出队,把这个元素入队,然后堆向下调整,变成小堆。当数组中的元素全部遍历完成时并且该插入的插入小堆后,这个小堆中存放的就是前k个大的元素。 -
在这道题中比较的是单词频率,即单词次数,那么我们可以使用HashMap来存储key为单词,value为次数。所以接下来我们理一下代码步骤,是怎么使用Map和TopK的思想的。
步骤:
第一步:使用Map统计单词出现的次数,Map的key为这个单词,value为次数。
第二步:遍历Map中的元素,具体是使用Set<Map.Entry<String,Integer>> set = map.entrySet();将map的key和value打包成entry装进Set,然后遍历set同时把前k个entry放入小堆minHeap中,当minHeap.size() == k时,就开始让剩下的entry和堆顶元素topHeap的value比较,如果entry的value比topHeap的value大,那就让堆顶的topHeap出堆,当前entry入堆同时堆自己向下调整变成新的小堆。当遍历完set集合时,minHeap这个堆中留下的就是出现频率前k个entry。
需要格外注意的一点是,如果当前entry和topHeap的value相等,就按照字典排序,即字母从小到大。当前entry和topHeap的value相等,所以这时候用key比较,如果当前entry比topHeap的key小,topHeap出堆,entry入堆(相当于value相等的元素使用大堆排序,使用key比较)。
总的来说就是:value不等时,用value作比较,建小堆;value相等时,在前面小堆的基础上,以key作比较,value相等的元素建立大堆。
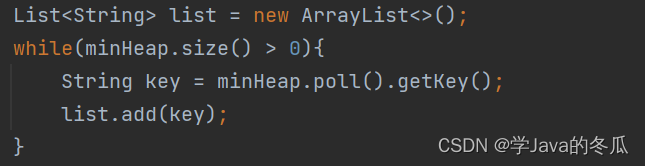
第三步:把minHeap的每个entry元素出堆,同时把entry的key存入list中。
第四步:使用Collections.reverse()方法把list转置,因为第三步中的出堆时这个堆是小堆,value小的元素先弹出来,在list中就是value小的entry的key先装进list了,而题目要求从大到小,所以需要逆置。
这道题你以为到这里就完了?那就大错特错了,这里还差最重重要的部分,这个问题非常的隐蔽,非常难发现。
在LeetCode上测试时,下面这个用例过不了,那么我们接着往下看,看看这是为什么?
// 输入
words =
["i","love","leetcode","i","love","coding"]
k = 3// 实际输出
["love","i","coding"]
// 预期输出
["i","love","coding"]
3、PriorityQueue的poll源码分析
为什么实际输出与预期输出不同?我们来慢慢分析。
第二步操作为:示例中前k个元素的k=3。向PriorityQueue中插入元素,第二步完成后可能会有以下两种情况,要想知道具体的结果是以下两种情况的哪一种?那就来分析插入的源码。
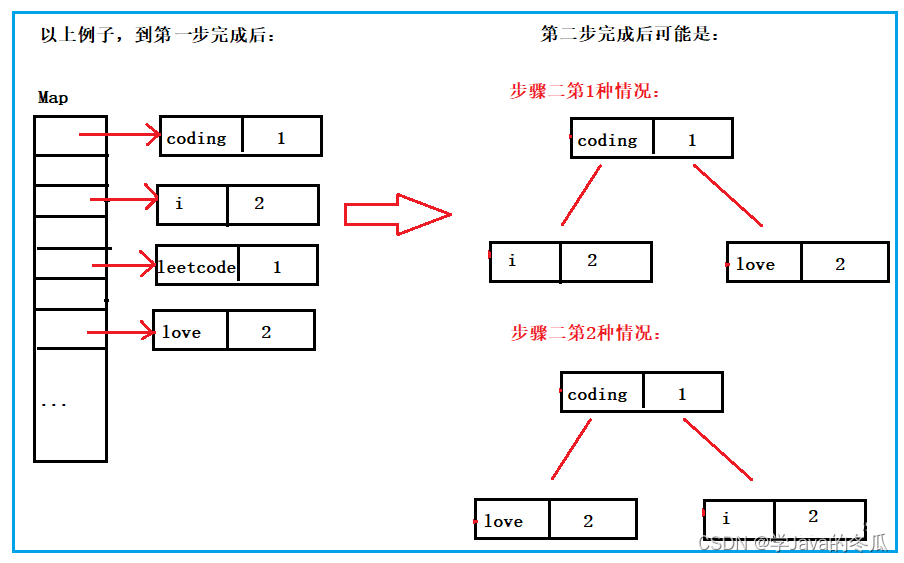
- 我写了很多之后我才发现最开始就出了一个很大的问题!!!就是我误认为的将entry集合放进Map中时是上图中步骤1的情况,实际情况是不确定的!为什么?因为entry通过key哈希到数组中,在数组的哪一个位置上是无法确定的。也就是说,我们无法知道步骤第二步(把entry插入完后),完成后是上面哪种情况。
- 那么为什么说是上面的情况呢?为什么不应该还有可能是"leetcode"、“love”、“i"的情况吗?我们把上面的代码运行得出实际输出为"love”,“i”,“coding"三个entry。由于是小堆,所以我们只知道堆顶是"coding”,但是堆顶的左右是上图中的步骤2中的第一种还是第二种,我们是不知道的。所以只有上面步骤2的两种情况。
- 所以我们只能在步骤第三步中出堆时分析poll(),然后向下调整。而并不能通过分析offer得到步骤第二步的结果。接下来我们看poll()的源码。
在这之前,先看看poll()操作:就是把minHeap的entry拿出来,然后把entry的key存储在list中。
// poll()的源码:public E poll() {if (size == 0)return null;int s = --size;modCount++;E result = (E) queue[0];E x = (E) queue[s];queue[s] = null;if (s != 0)siftDown(0, x);return result;}
-
看源码时,我们要知道E是泛型类,具体在题中就是我们要删除的堆顶元素topHeap,然后返回topHeap。我们可以从第二步骤完成后的两个情况知晓,此时堆顶元素为 entry<“coding”,1>。
从poll源码中可以看出,这里的操作为:记录要删除并返回的节点result,然后把size-1的元素交给x,再把size-1位置置空,然后进入向下调整。我以步骤2的第二种作为分析来做一个示例:此时x就是entry<“i”,2>
-
那接下来我们来看向下调整的代码:这里中间还经过一个是否传入了比较器的判断,因为我们传给了优先级队列minHeap比较器,以value作为比较。
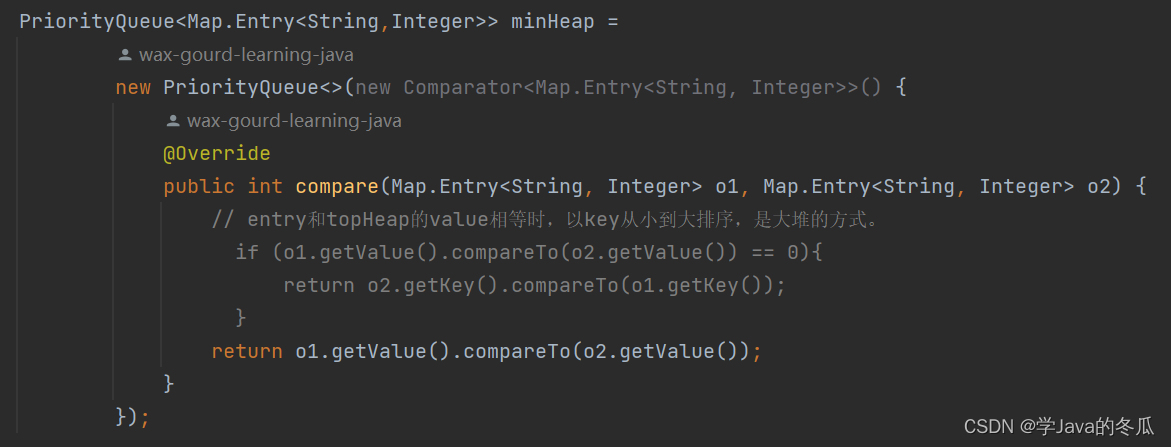
// 比较器判断private void siftDown(int k, E x) {if (comparator != null)siftDownUsingComparator(k, x);elsesiftDownComparable(k, x);}
- 接下来我们继续看
siftDownComparable(k,x),这时k=0,x=entry<“i”,2>。
// siftDownComparable向下调整有比较器源码。private void siftDownComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>)x;int half = size >>> 1; // loop while a non-leafwhile (k < half) {int child = (k << 1) + 1; // assume left child is leastObject c = queue[child];int right = child + 1;if (right < size &&((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)c = queue[child = right];if (key.compareTo((E) c) <= 0)break;queue[k] = c;k = child;}queue[k] = key;}
-
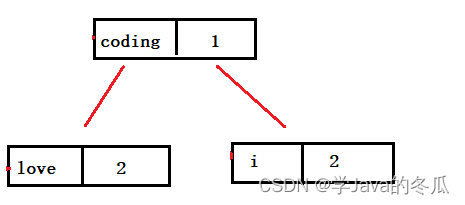
siftDownComparable代码中的k=0,x=entry<“i”,2>,此时x已经不在minHeap中了,因为在分析poll()时size-1的位置已经置空。再根据下面的分析中我们知道,源码中的c就是左子树entry<“love”,2>。
当走到if (key.compareTo((E) c) <= 0)这一步时,问题来了,此时key是x=entry<“i”,2>,c是entry<“love”,2>,二者的value相等。直接就break了,然后把x=entry<“i”,2>放在了0下标位置。
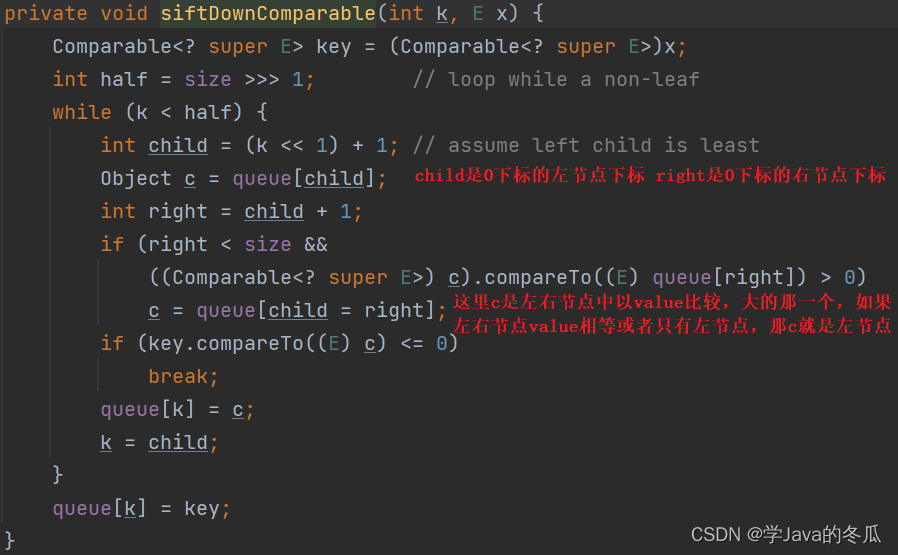
-
现在在minHeap中就变成下图这样:
然后再次poll()堆顶元素entry<“i”,2>,因为剩下的节点只有一个了所以不再需要向下调整。所以在前面的分析步骤2中的第2种情况,minHeap的poll()次序为entry<“coding”,1>,entry<“i”,2>,entry<“love”,2>,存入list后list中的元素是这样排列的:entry<“coding”,1>,entry<“i”,2>,entry<“love”,2>。在第四个步骤时:使用Collections.reverse()方法把list转置得到的答案就是实际的输出[love, i, coding],把最开始的代码拿来测试就可以发现,哈希的结果确实是步骤二的第二步这种情况。
-
那为什么会出现这种情况?最根本的原因其实是在第一次poll()时,删除节点是entry<“coding”,1>,右节点是entry<“i”,2>,左节点是entry<“love”,2>。当走到
if (key.compareTo((E) c) <= 0)这一步时,问题来了,此时key是x=entry<“i”,2>,c是entry<“love”,2>,二者的value相等,就直接就break了,并没有再根据key的从小到大排列。因为题目要求频率不等时,频率从大到小排序,频率相等时,要以字典从小到大排序。这里就是不满足频率相等时,要以字典从小到大排序这个条件。简单来说错误原因就是:出堆操作,向下调整调用compareTo方法时使用比较器,但是我们传给PriorityQueue的比较器不完整。
-
那怎么解决?简单,因为走到当走到
if (key.compareTo((E) c) <= 0)这一步时,会调用我们传入的比较器,而错误产生的原因是当value相等时直接就break了,那我们在比较器中就加上value相等时用key比较的判断,见下图:
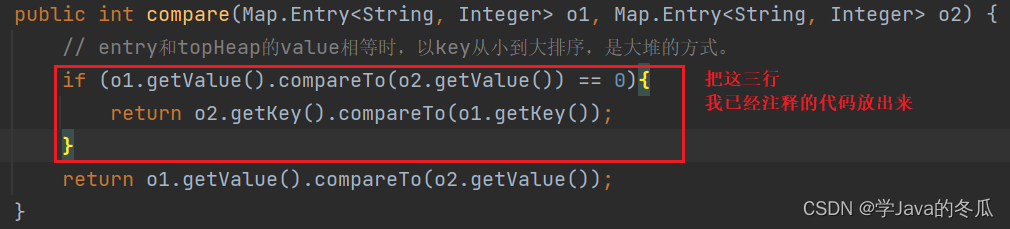
4、正确的代码
- 把有缺陷的代码中的定义优先级队列minHeap时传入比较器的三行注释代码放出,即可正常保证答案正确。