【linux】:进程控制

文章目录
- 前言
- 一、什么是写时拷贝
- 二、进程控制
- 1.进程终止
- 2.进程等待
- 三丶进程程序替换
- 总结
前言
了解上一篇文章中的进程地址空间后,我们再来说说进程控制的概念,进程控制我们需要搞清楚三个问题:如何进程终止,如何解决僵尸进程问题以及写时拷贝的问题。
一、什么是写时拷贝
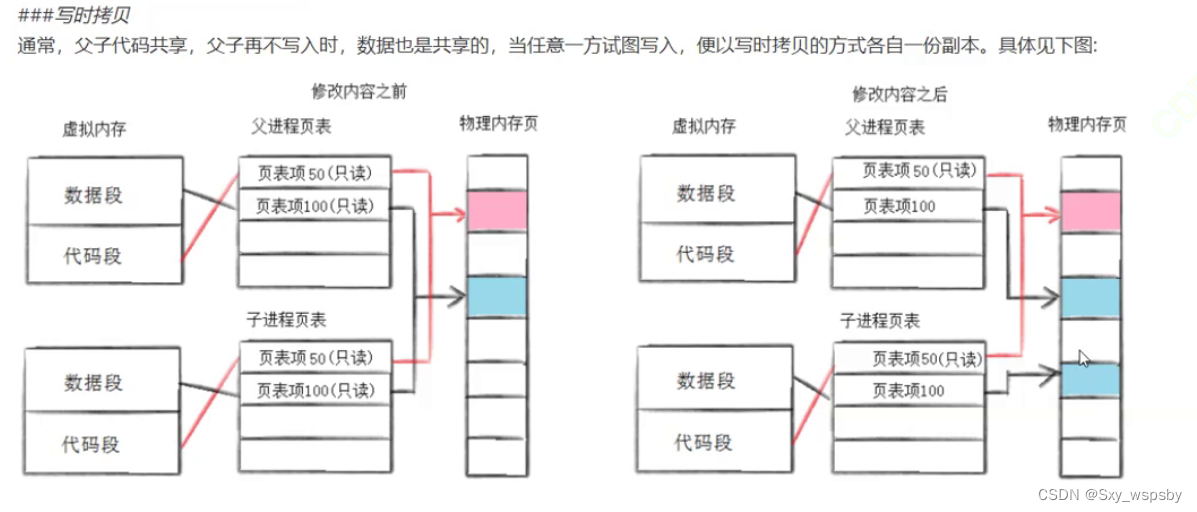
如果我们要在linux中创建进程,就需要利用fork函数,fork函数有两个返回值,父进程返回子进程pid,给子进程返回0,如果fork失败了就返回-1,当我们函数开始return的时候,函数的主体部分已经做完了,也就是说fork创建子进程,在fork返回的时候子进程已经创建好了甚至已经被操作系统调度了,代码本身是要被父子进程共享的,return也是语句所以也会被共享,这就会出现为什么会出现两个返回值,当我们用if else分流可以发现两个判断条件同时进行,那么为什么会有一个大于0的ID值和一个等于0的ID值呢,因为当创建子进程时,操作系统会给子进程创建相应的进程地址空间,创建对应的地址空间的时候我们对应的数据等经过虚拟地址通过页表映射到物理内存的本质就是写入,这个时候谁先返回谁就发生写时拷贝问题,这样就出现了返回两个不同的ID值。
通常父子代码共享,父子进程在不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份拷贝,如下图:
fork的常规用法:
1.一个父进程希望复制自己,使父子进程同时执行不同的代码段,例如:父进程等待客户端请求,生成子进程来处理请求。
2.一个父进程要执行一个不同的程序,例如子进程从fork返回后, 调用exec函数。
fork调用失败的原因:
1.系统中有太多的进程
2.实际用户的进程超出了限制
注意:创建进程是会消耗资源的。
我们上一篇已经充分了解了写时拷贝,下面我们进行进程控制的学习:
二丶进程控制
1.进程终止
进程退出一共有三个场景:
1.代码运行完毕,结果正确
2.代码运行完毕,结果不正确
表示代码运行正确与否可以通过main函数的返回值来判断,返回值也叫进程的退出码。如下图:
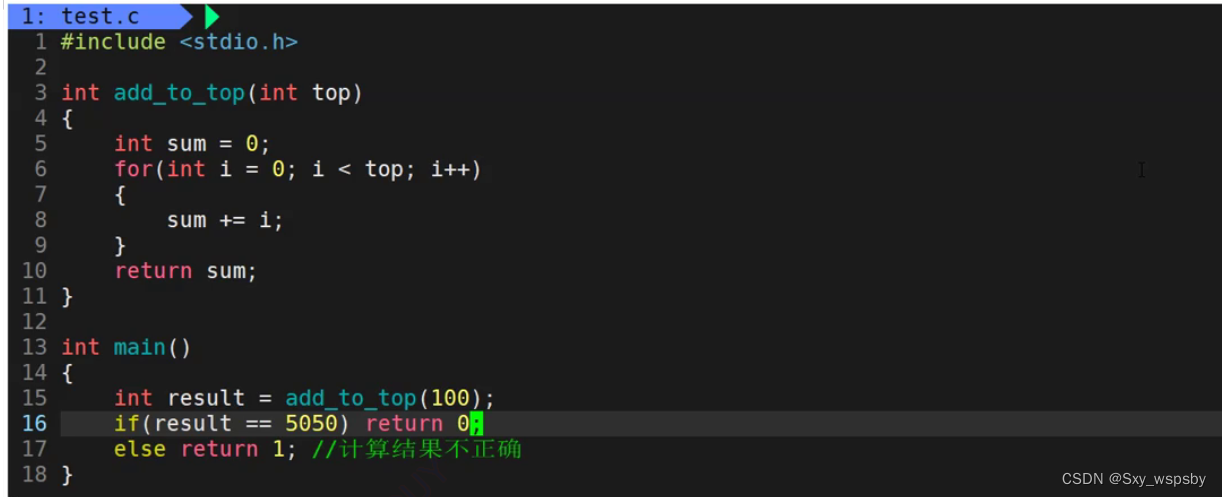
我们写了一个累加函数,当函数返回值等于5050就返回0也就是代码运行完毕,结果正确的情况。当返回值不是5050就是代码运行完毕结果不正确的情况,然后我们通过$?来获取进程的返回值用echo去打印这个返回值。

我们用echo打印返回值,$?只会保留最近一次进程的退出码,也就是说我们看第一个打印的结果即可,为什么结果不正确呢?因为我们在循环中写错了我们应该写成i<=top才对。如下图:
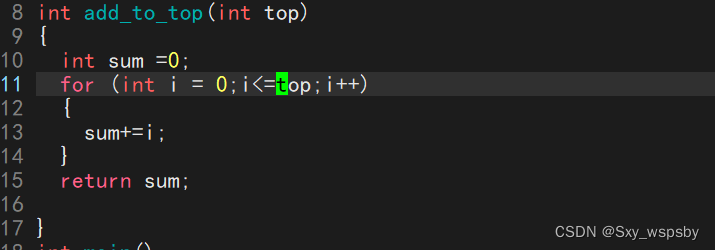

这个时候我们发现结果对了确实给我们返回了正确的结果,接下来我们看看系统中有哪些退出码:
 在这里需要包含头文件#include <string.h>然后我们利用strerror函数打印退出码:
在这里需要包含头文件#include <string.h>然后我们利用strerror函数打印退出码:
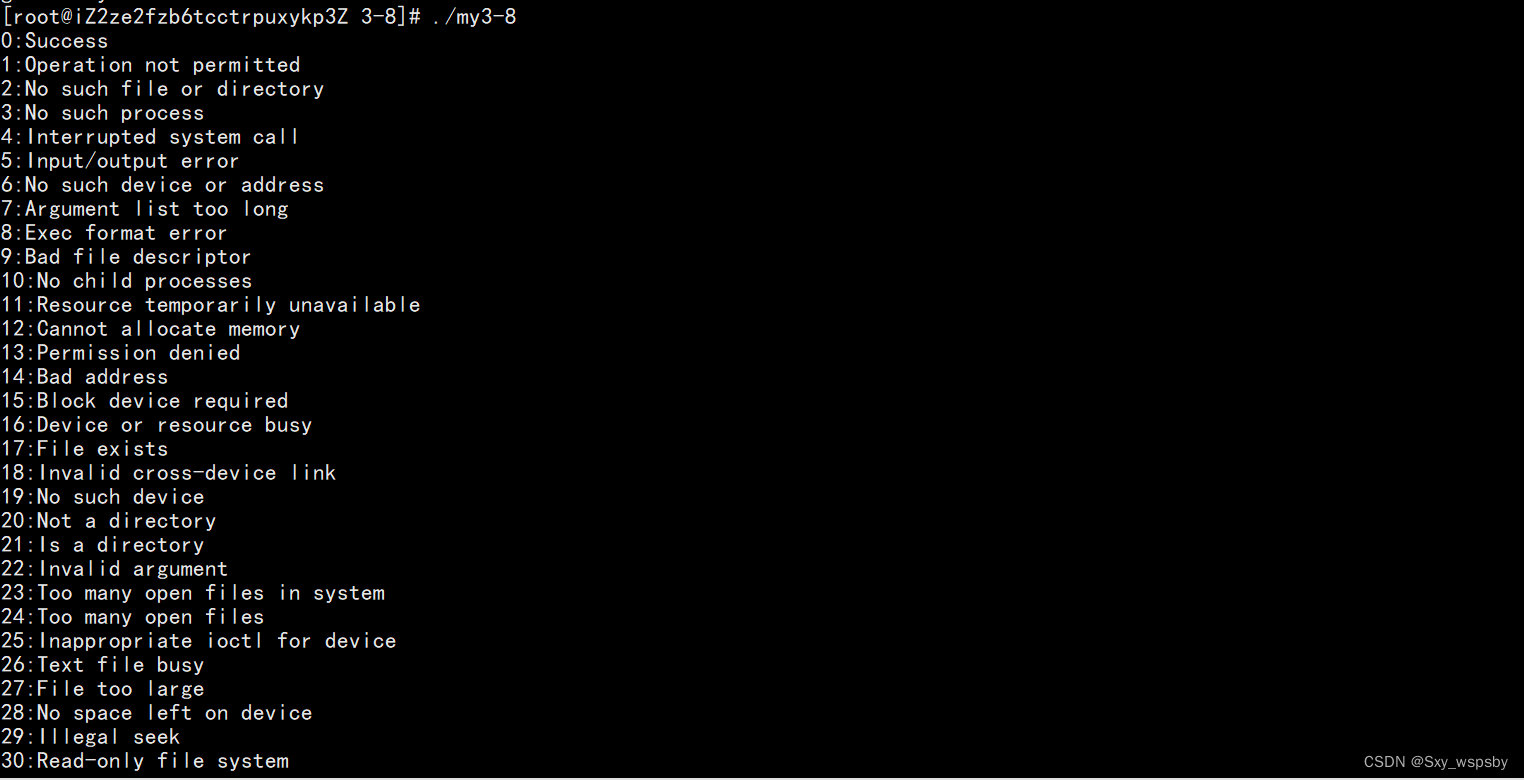
由于太多我们只取一部分即可,比如0就是运行成功,2就是没有这个文件或目录,下面我们验证一下:

当我们试图查看一个不存在的文件或目录时,报错与退出码2一致这就说明了程序的运行结果确实可以通过返回值来判断。
3.代码异常终止,比如进程崩溃等等
进程退出就是操作系统少了一个进程,操作系统要释放进程对应的内核数据结构+代码和数据。那么进程退出有哪些方式呢?
1.通过main函数return(其他函数return仅仅代表该函数返回)
2.exit函数退出,如下图:

 exit(int code):code就代表进程退出码,等价于main函数return。
exit(int code):code就代表进程退出码,等价于main函数return。
当然_exit也可以退出,如下图:
_exit()需要包含头文件#include <unistd.h>,我们将程序运行起来:

是否感觉exit与_exit没有区别呢?其实不是,这两个函数是有区别的我们看下图:
 我们用同一份代码,打印hello的时候不要带\\n。
我们用同一份代码,打印hello的时候不要带\\n。

在经过2秒后hello刷出来了,我们在用_exit试试:
 当我们用_exit结束进程我们发现数据没有被缓冲区刷新出来,所以这两个函数的区别在于_exit是直接结束进程不刷新缓冲区。我们也可以理解为exit就是多加了个冲刷缓冲区功能的_exit,如下图:
当我们用_exit结束进程我们发现数据没有被缓冲区刷新出来,所以这两个函数的区别在于_exit是直接结束进程不刷新缓冲区。我们也可以理解为exit就是多加了个冲刷缓冲区功能的_exit,如下图:

2.进程等待
我们之前的文章说过,当子进程退出,父进程如果不管不顾,就可能造成僵尸进程的问题,进而造成内存泄漏。另外,进程一旦变成僵尸状态,那就无法杀掉进程,因为谁也没有办法杀掉一个死去的进程。最后,父进程派给子进程的任务完成的如何我们需要知道,比如:子进程运行完成,结果对还是不对,或者是否正常退出。父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息。
我们通过man 2 wait命令查看wait的使用:
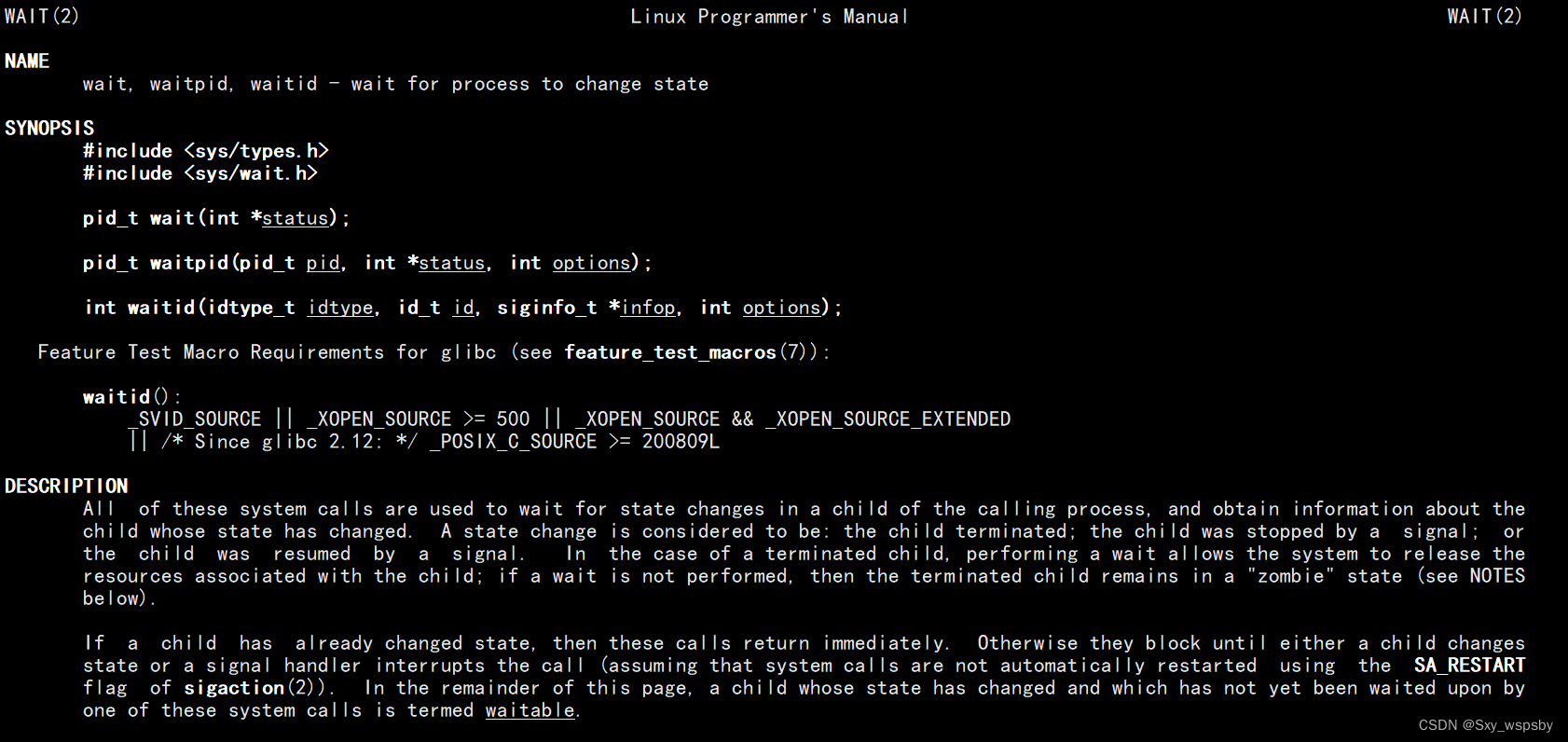
我们可以看到wait的返回值是pid_t通过手册我们知道wait返回的是接收到的子进程的pid,下面通过代码我们使用一下wait函数:
 我们先包含相应的头文件,然后重新写一份代码:
我们先包含相应的头文件,然后重新写一份代码:
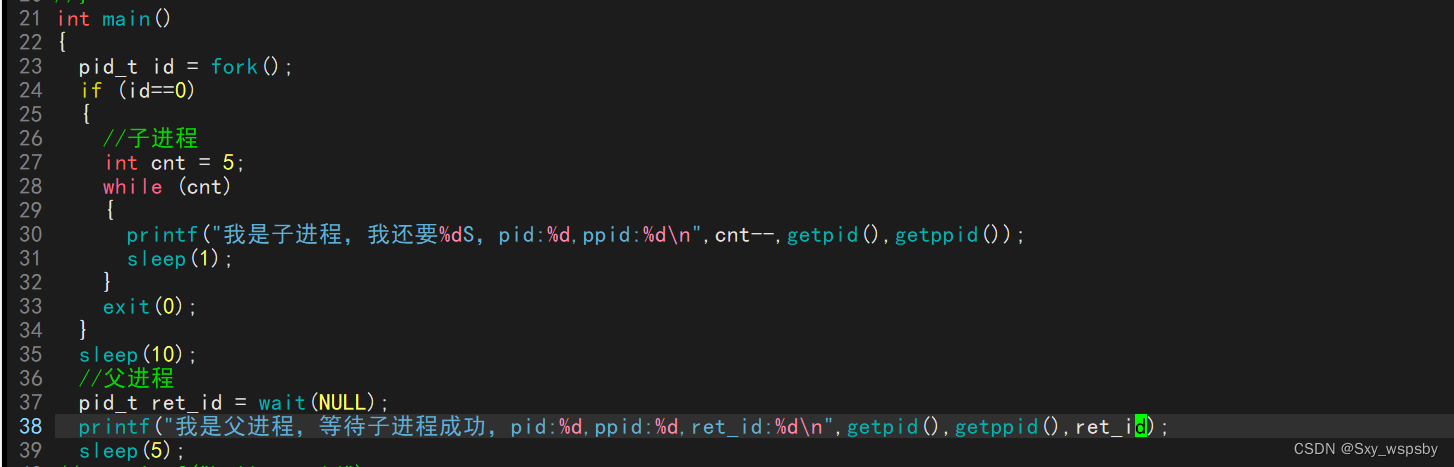
此代码的意思是让子进程活5s然后父进程睡眠10秒在这期间子进程是僵尸状态,然后父进程苏醒接收子进程。然后我们运行起来:

上面是我们写的一个shell脚本用来监视进程,现在我们将程序运行起来:

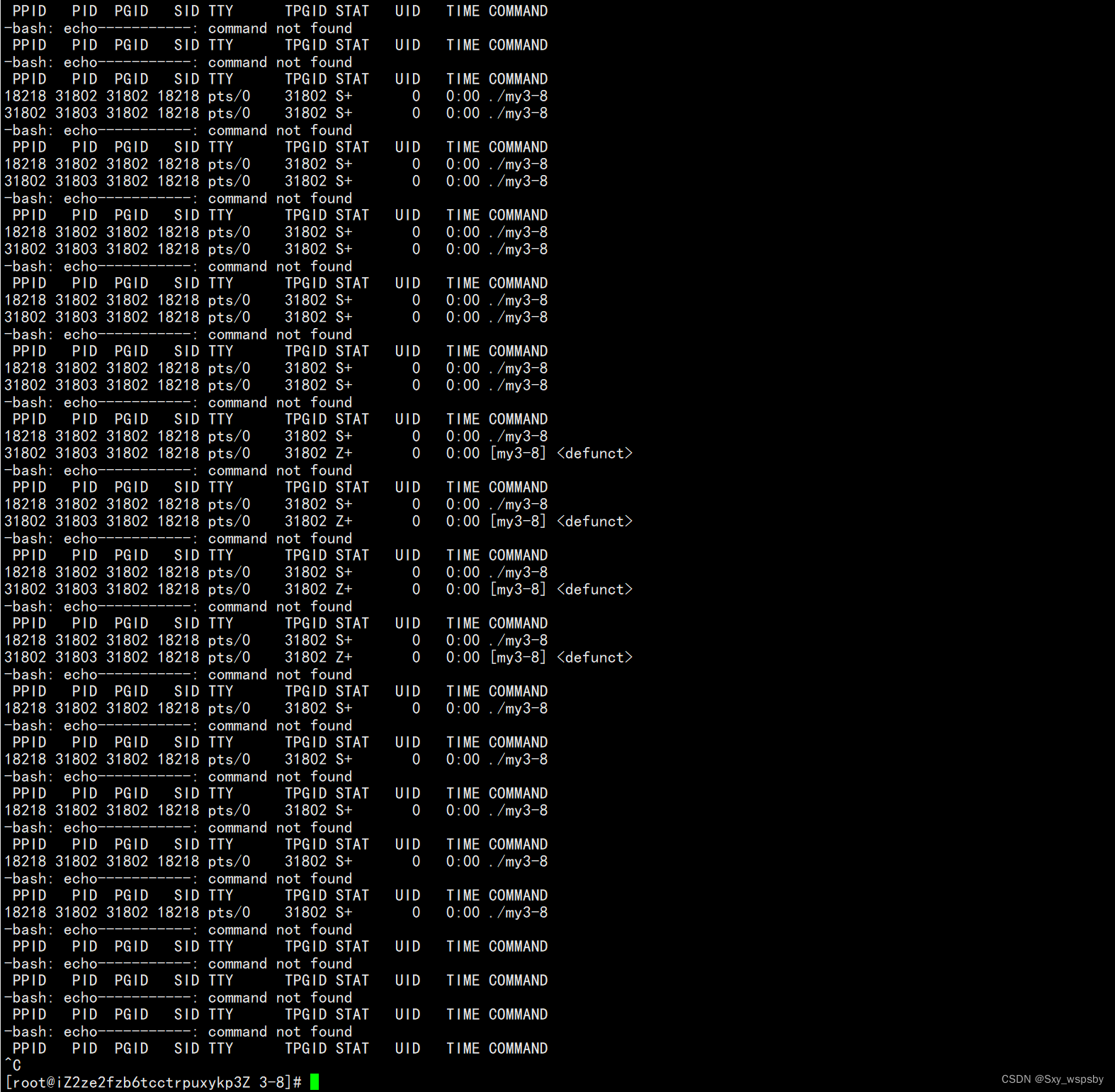 我们发现和我们想的一样,刚开始父子进程都在运行,当子进程结束后进入僵尸状态,然后父进程沉睡了10秒后醒来将子进程回收,然后两个进程一起退出。
我们发现和我们想的一样,刚开始父子进程都在运行,当子进程结束后进入僵尸状态,然后父进程沉睡了10秒后醒来将子进程回收,然后两个进程一起退出。
如果父进程在wait的时候,如果子进程没退出,父进程在干什么?其实很简单,父进程还是在等子进程,等子进程结束了父进程才会退出。在子进程没有退出的时候,父进程只能一直在调用waitpid进行等待,这种等待被称为阻塞等待
下面我们看看waitpid函数:

第一个参数:如果pid大于0就表示等待指定的进程,如果pid等于-1,等待任意一个子进程,与wait等效,而第二个参数status是一个输出型参数,也就是信号比如下面这样:
第三个参数一般不管输入0即可,而这个status我们一般看做位图结构,如下图:
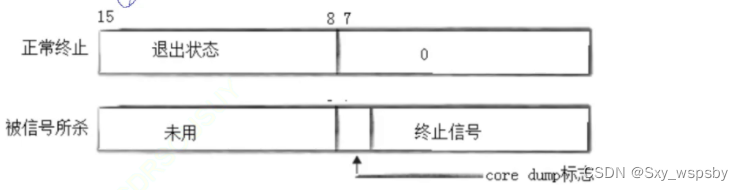
int有32个比特位但是只要后16位,次低8位当做退出状态,最后7位为终止信号。还有1位我们先不做讲解。
下面我们用waitpid演示一下:

status右移8位按位与全1就能得到次低8位的值,status按位与上0x7F就得到了最低7位的值,这个时候我们再来运行:

这个时候我们发现确实拿到了子进程的退出码38,signal为0代表成功,下面我们故意弄一个异常看看:
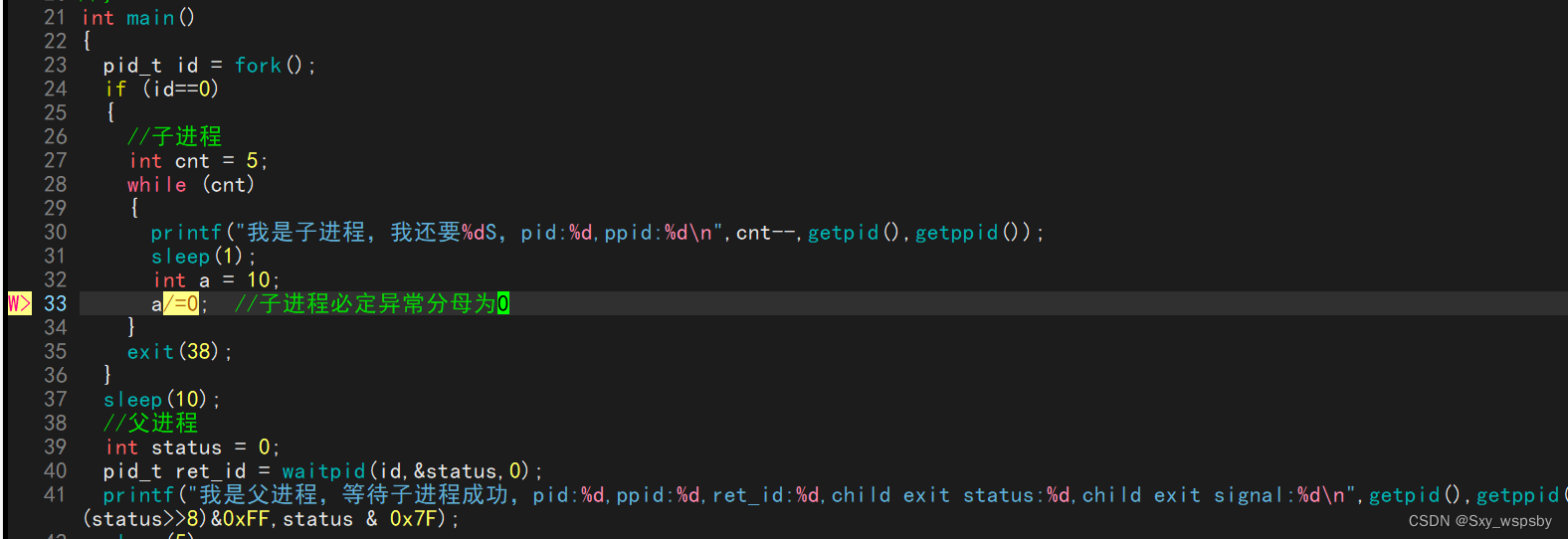
 虽然编译器提示但我们依旧运行,最终收到的异常信号为8,代表子进程出现异常,这种情况退出码是多少就不重要了因为已经异常了。
虽然编译器提示但我们依旧运行,最终收到的异常信号为8,代表子进程出现异常,这种情况退出码是多少就不重要了因为已经异常了。
下面我们验证一下waitpid的三种不同返回情况:
 我们通过返回值去判断父进程等待失败,正在等待以及等待成功三种情况。
我们通过返回值去判断父进程等待失败,正在等待以及等待成功三种情况。
下面我们写个程序让父进程在等待子进程的时候可以干一些其他有用的事情:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
//const char* err_string[] = {
// "success",
// "error"
//}
//int add_to_top(int top)
//{
// int sum =0;
// for (int i = 0;i<=top;i++)
// {
// sum+=i;
// }
// return sum;
//
//}
#define Task_Num 10
//预设一批任务
void sync_disk()
{printf("这是一个刷新数据的任务!\\n");
}
void sync_log()
{printf("这是一个同步日志的任务!\\n");
}
void net_send()
{printf("这是一个进行网络发送的任务!\\n");
}
//要保存的任务相关的
typedef void (*func_t)(); //将一个函数指针重定义为void,也就是定义了一个函数指针类型
func_t other_task[Task_Num] = {NULL}; //函数指针数组
int LoadTask(func_t func)
{int i = 0;for (;i<Task_Num;i++){if (other_task[i]==NULL){break;}}if (i==Task_Num){return -1;}else{other_task[i]==func;}return 0;
}
void InitTask()
{for (int i = 0;i<Task_Num;i++) other_task[i]==NULL;LoadTask(sync_disk);LoadTask(sync_log);LoadTask(net_send);
}
void RunTask()
{for(int i = 0;i<Task_Num;i++){if (other_task[i]==NULL){continue;}other_task[i]();}
}
int main()
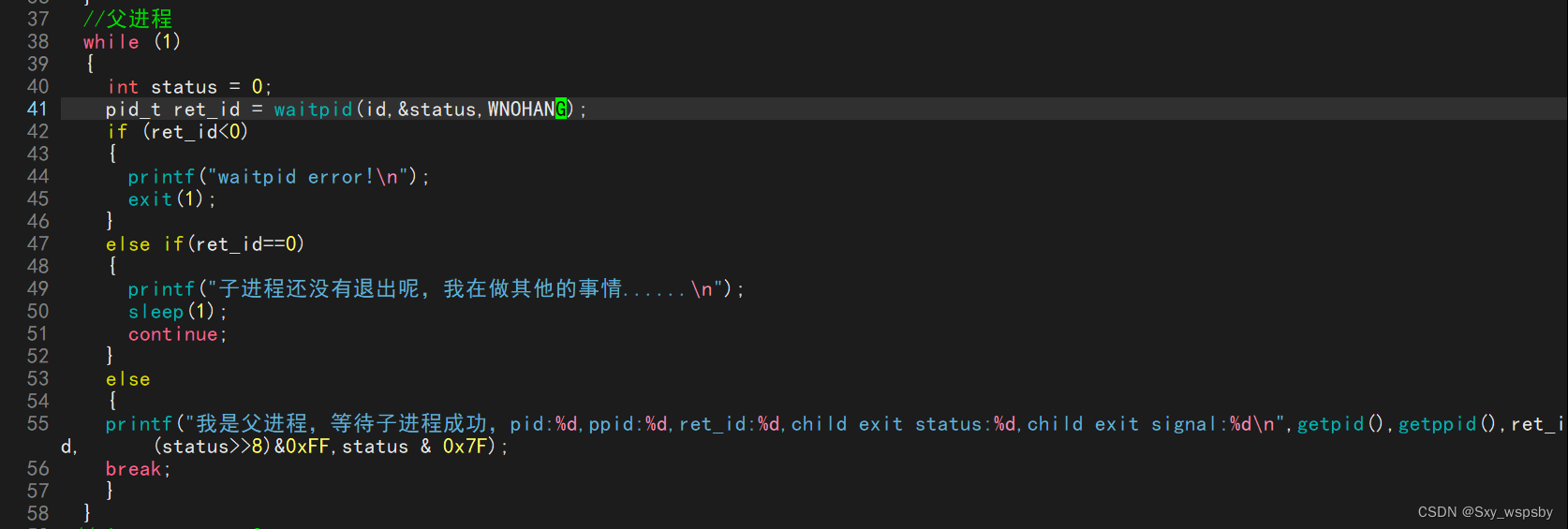
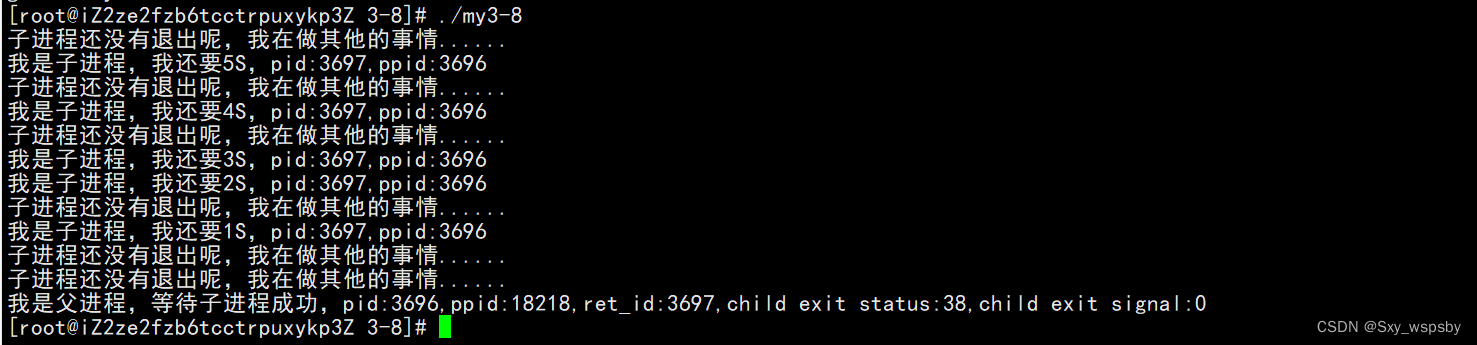
{pid_t id = fork();if (id==0){//子进程int cnt = 5;while (cnt){printf("我是子进程,我还要%dS,pid:%d,ppid:%d\\n",cnt--,getpid(),getppid());sleep(1);// int a = 10;// a/=0; //子进程必定异常分母为0}exit(38);}InitTask();//父进程while (1){int status = 0; pid_t ret_id = waitpid(id,&status,WNOHANG);if (ret_id<0){printf("waitpid error!\\n");exit(1);}else if(ret_id==0){RunTask();sleep(1);continue;}else{printf("我是父进程,等待子进程成功,pid:%d,ppid:%d,ret_id:%d,child exit status:%d,child exit signal:%d\\n",getpid(),getppid(),ret_id, (status>>8)&0xFF,status & 0x7F); break;}}// int status = 0;// pid_t ret_id = waitpid(id,&status,0);// printf("我是父进程,等待子进程成功,pid:%d,ppid:%d,ret_id:%d,child exit status:%d,child exit signal:%d\\n",getpid(),getppid(),ret_id,(status>>8)&0xFF,status & 0x7F);// sleep(5);
// printf("hello world");
// sleep(2);
// _exit(39);
// int result = add_to_top(100);
// if (result==5050)
// {
// return 0;
// }
// else{
// return 1;
// }
// for (int i = 0;i<=200;i++)
// {
// printf("%d:%s\\n",i,strerror(i));
// //exit(123);
// _exit(123);
// }return 0;
}
接下来我们运行起来:
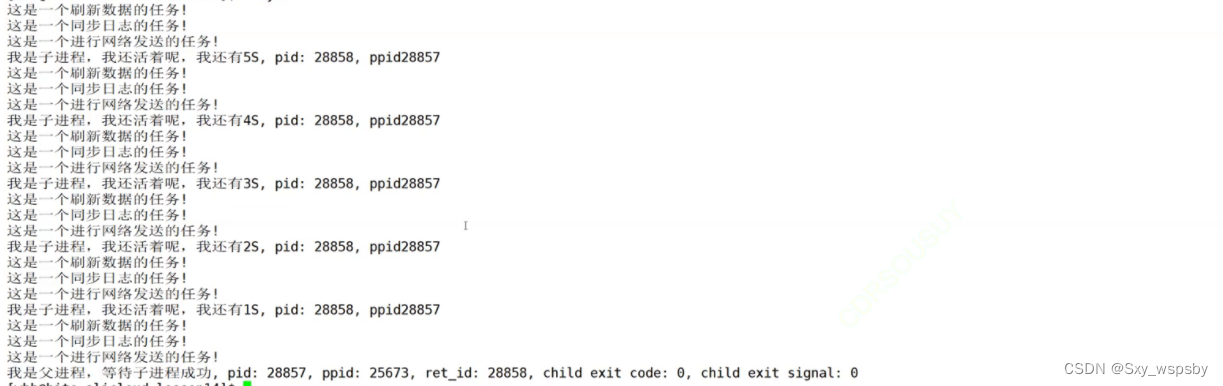
通过上图我们发现父进程在等待子进程退出的时候确实可以干一些事情。
下面我们将代码修改一下,用WIFEXITED宏获取是否接收信号
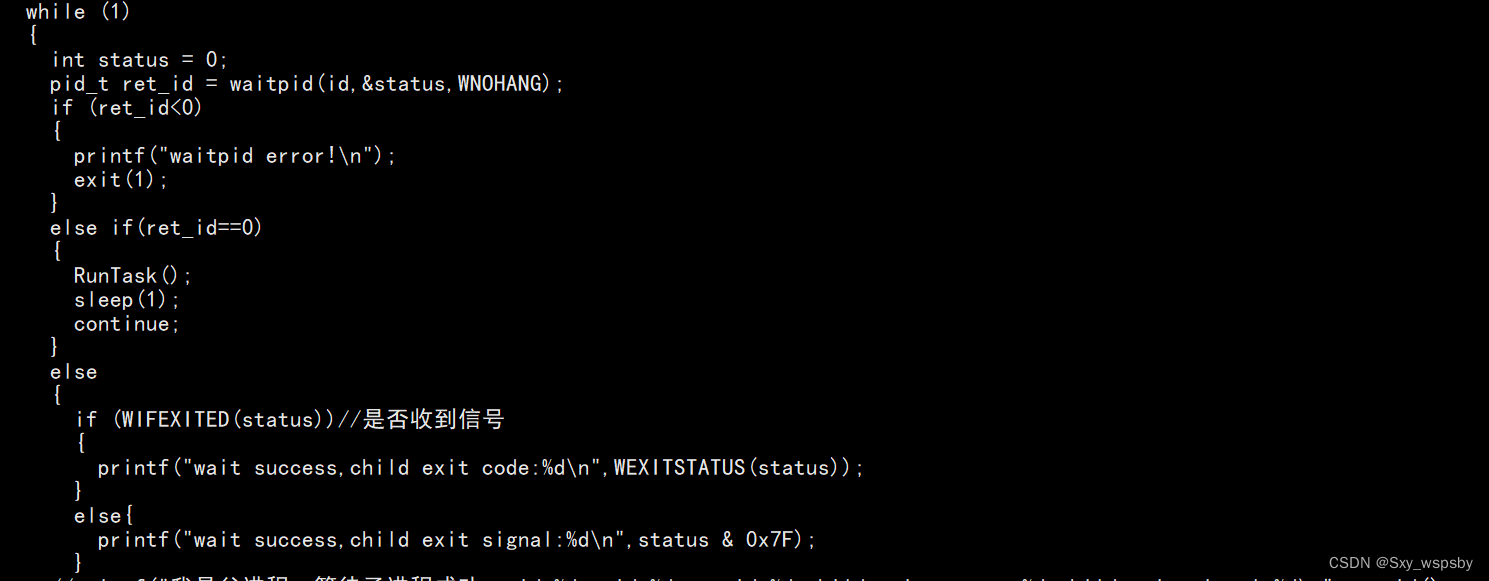

从上图运行结果来看我们发现确实成功拿到了退出码0。
总结:
三.进程程序替换
替换原理:
用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec并不创建新进程,所以调用exec前后该进程的id并未改变。
那么我想问问一下,创建子进程的目的是什么呢?就是为了让子进程帮我做特定的任务。而这里分为两种情况:
1.让子进程执行父进程的一部分代码
2.如果子进程向指向一个全新的程序代码,就称为进程的程序替换。
下面我们先看一下什么是程序替换:
首先我们要知道程序替换的接口execl,我们用man手册打开可以看到:
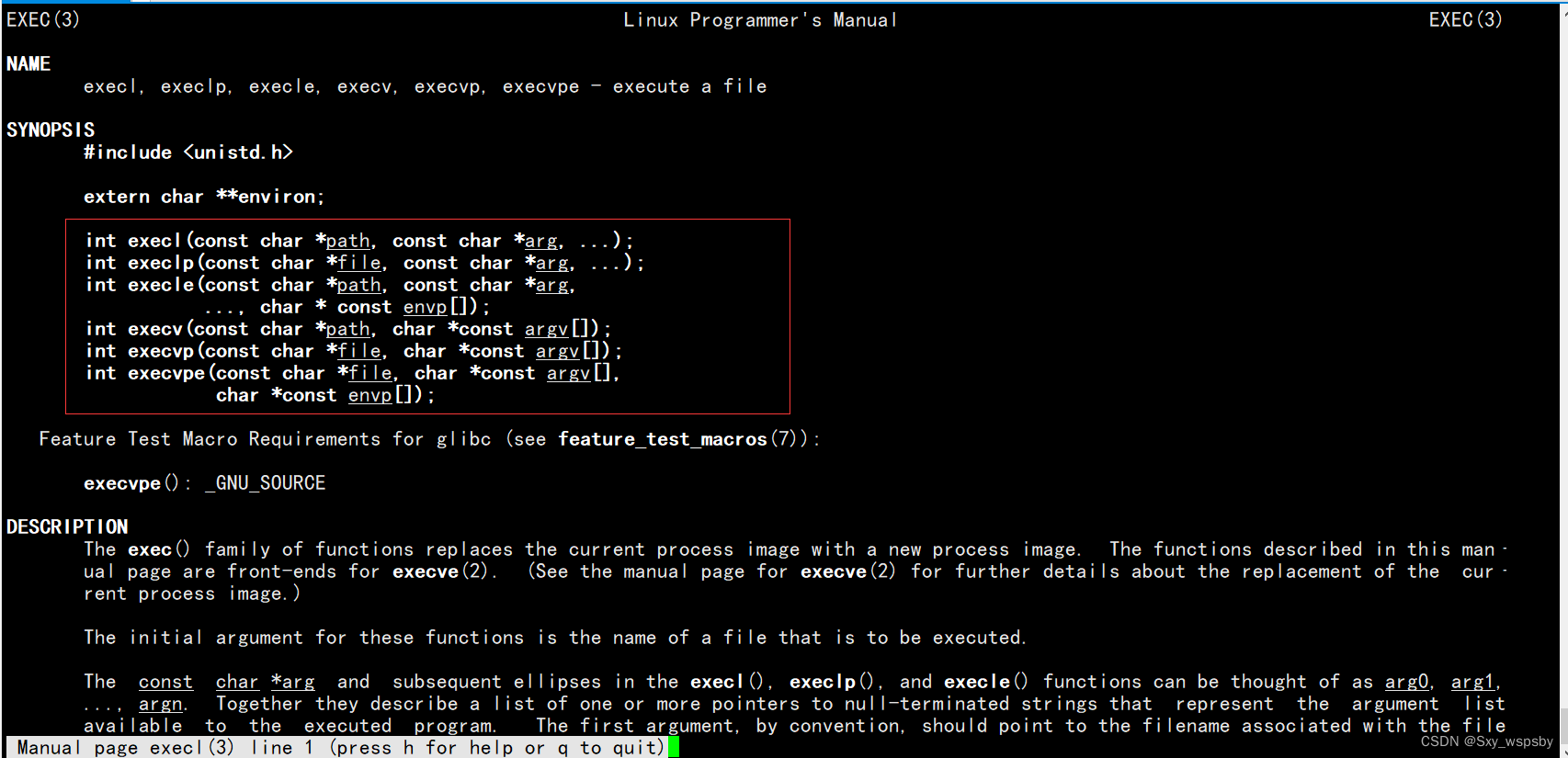
第一个函数后面参数...这里是可变参数列表,第一个参数是你要执行谁,这里是个路径,如果我们将参数传完了必须以NULL结尾。接下来我们先使用一下,然后详细的讲解这个函数。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{printf("begin.........\\n");printf("begin.........\\n");printf("begin.........\\n");printf("begin.........\\n");execl("/bin/ls","ls","-a","-l",NULL);printf("end..........\\n");printf("end..........\\n");printf("end..........\\n");printf("end..........\\n");return 0;
}
上图是我们所用的演示代码,我们可以看到execl这个函数的第一个参数是个路径,表示你要执行谁,第二个参数是指令,表示你要执行什么命令,而后面就是指令的选项了,记住参数传完后一定要以NULL结尾。
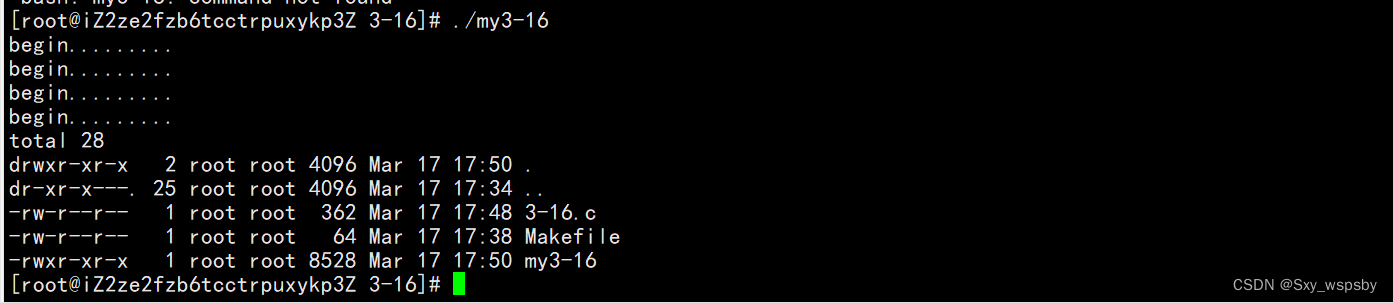
运行后我们发现原先打印的begin end中只剩下begin了,这是什么原因呢?如下图:
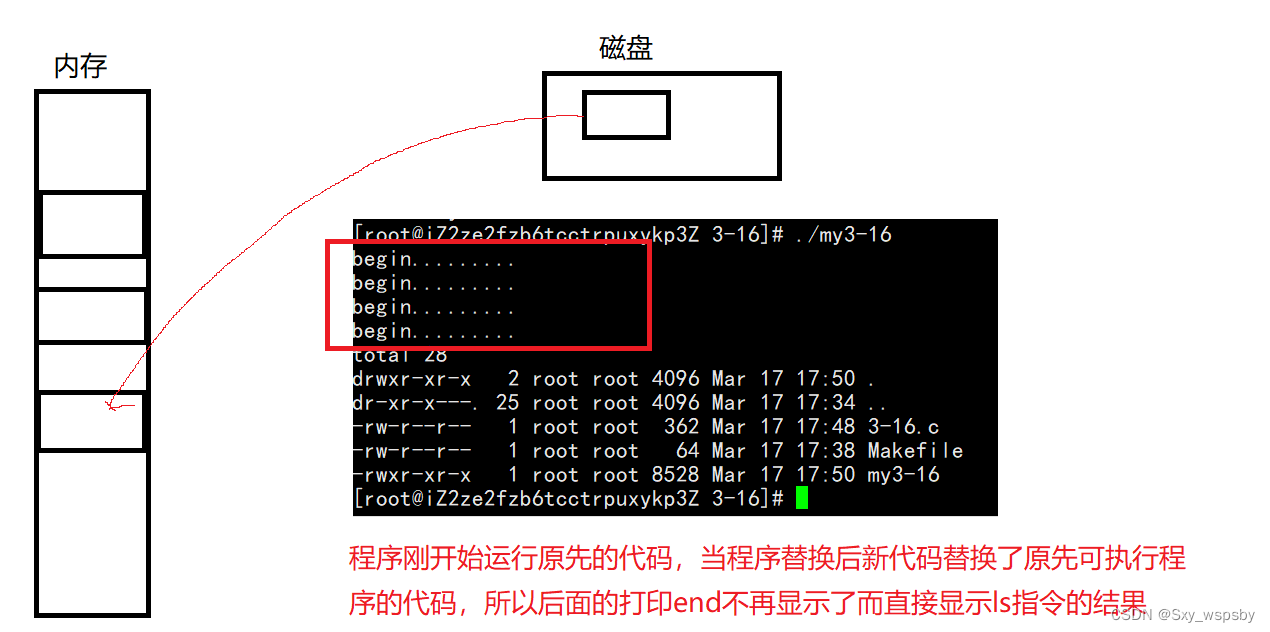
也就是说程序替换会直接将原先可执行程序的代码和数据替换为新的代码和数据。下面我们来看一下程序替换的基本原理:
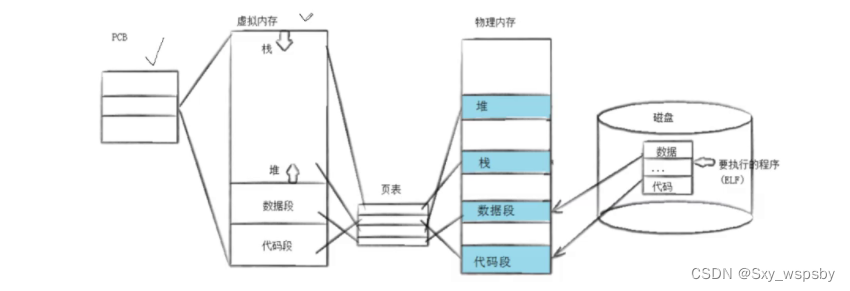
那么通过上图我想问一下,进程的程序替换,有没有创建新的进程呢?答案是没有,这里的替换还是原先的进程。那么当创建进程的时候,先有进程数据结构,还是先加载代码和数据呢?这个问题的答案其实我们之前回答过,一定是先有进程数据结构,因为有数据结构才能管理相应的代码和数据。
上面的演示代码我们是用一个进程进行演示的,下面我们用父子进程来演示一下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
//int main()
//{
// printf("begin.........\\n");
// printf("begin.........\\n");
// printf("begin.........\\n");
// printf("begin.........\\n");
// execl("/bin/ls","ls","-a","-l",NULL);
// printf("end..........\\n");
// printf("end..........\\n");
// printf("end..........\\n");
// printf("end..........\\n");
// return 0;
//}
int main()
{pid_t id = fork();if (id==0){//子进程printf("我是子进程:%d\\n",getpid());execl("/bin/ls","ls","-a","-l",NULL);}sleep(5);//父进程printf("我是父进程:%d\\n",getpid());waitpid(id,NULL,0);return 0;
}
我们让子进程去进行程序替换,父进程等待子进程,下面是运行结果:

父进程依旧还是运行了,说明了程序替换只会影响调用的那个进程。这又验证了进程具有独立性这句话。
那么程序替换会不会失败呢?如果失败了该怎么办?
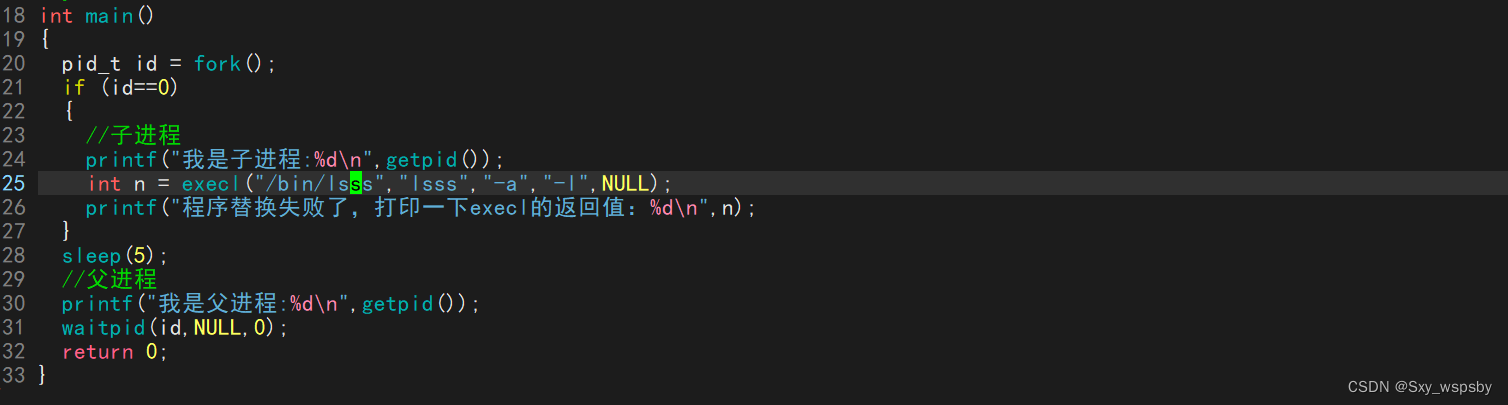
我们将execl里的参数修改为错误的,然后我们运行一下:

可以看到如果程序替换失败了会继续执行之前的代码和数据,并且如果失败execl的返回值为-1,如下图:
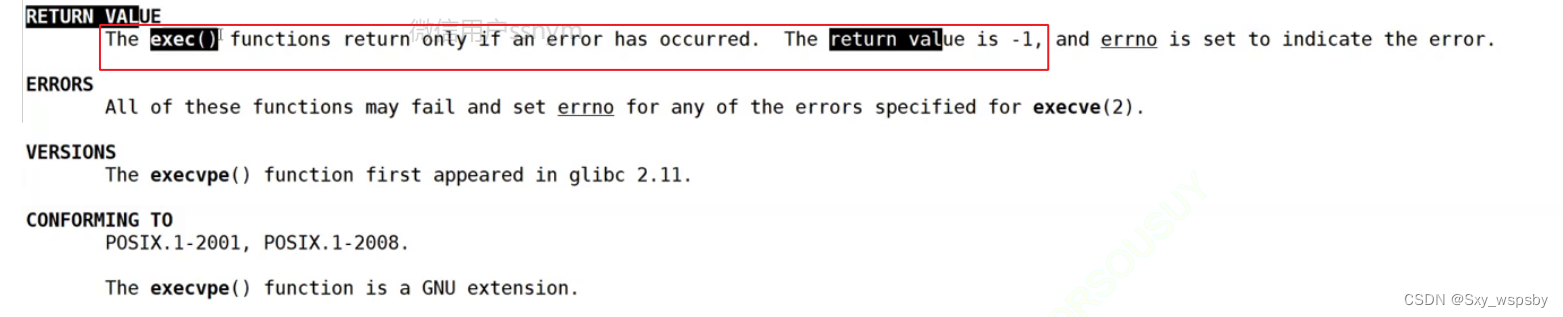
我们也可以这样理解,execl只要有返回值就失败了,不用判断返回值。
当然我们照样可以拿到子进程的退出码,如下图:
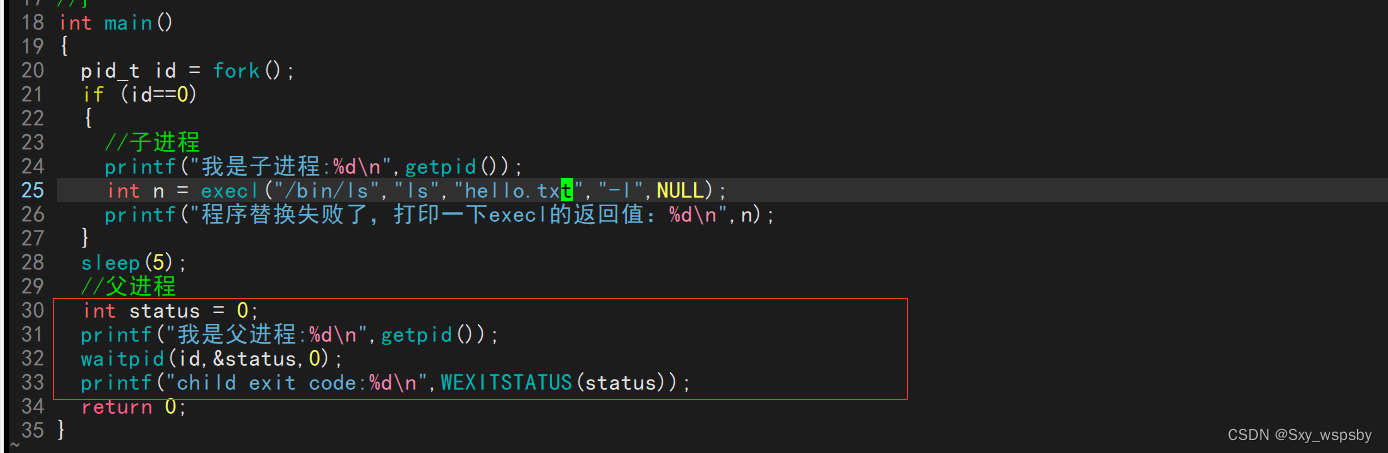

可以看到我们确实拿到了ls指令失败的2号退出码。
下面我们详细的讲解一下execl接口:

第一个参数path是要执行指令的路径,后面的参数就是如何加载执行这个指令,比如ls命令有ls -l ls-l -n等等,也就是说我们在命令行怎么执行这个命令就将这个指令一个个的传递给execl即可,只是当我们将所有的指令传完后后面必须加上NULL结尾。
接下来我们讲解一下execv这个函数接口:
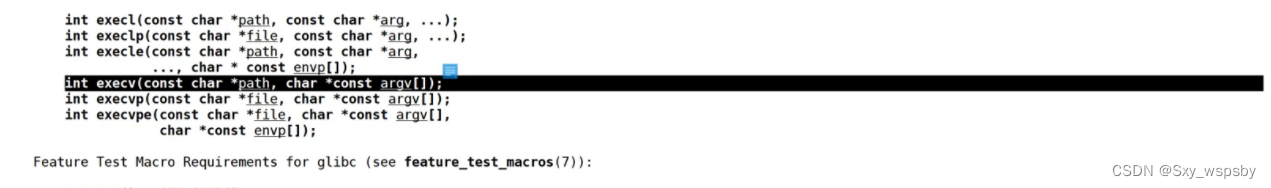 这个接口的第一个参数还是path路径,第二个参数argv[]是什么呢?最后一个V其实是vector的意思是一个数组,意思就是以数组的方式去传指令,下面我们演示一下:
这个接口的第一个参数还是path路径,第二个参数argv[]是什么呢?最后一个V其实是vector的意思是一个数组,意思就是以数组的方式去传指令,下面我们演示一下:
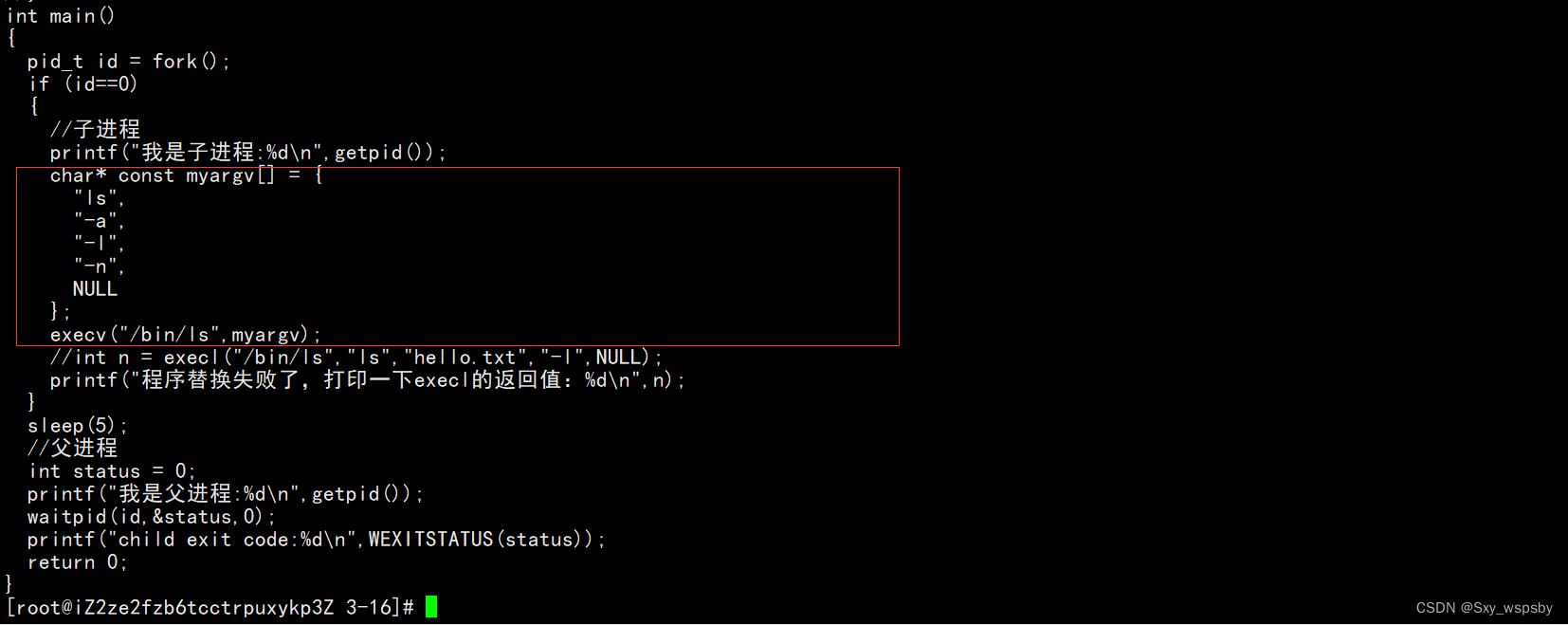
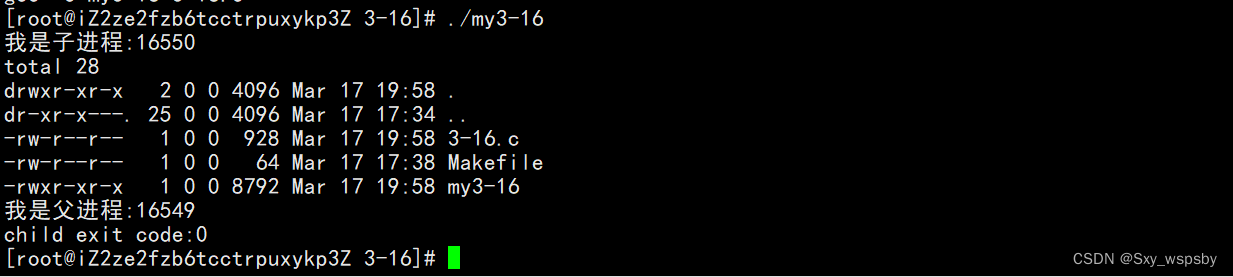 通过结果我们可以看到execv的结果与execl是一样的。这个就相当于c++的函数重载
通过结果我们可以看到execv的结果与execl是一样的。这个就相当于c++的函数重载
下面再讲一下execlp接口,此接口与execl的不同是第一个参数:

我们可以看到第一个参数是file,这是什么意思呢?其实这个接口就是不需要你在传路径了,你直接传你的指令然后系统会帮助你找到路径不需要你在传了,用这个接口你的环境变量必须在PATH中或者在PATH中设置过,下面我们演示一下:
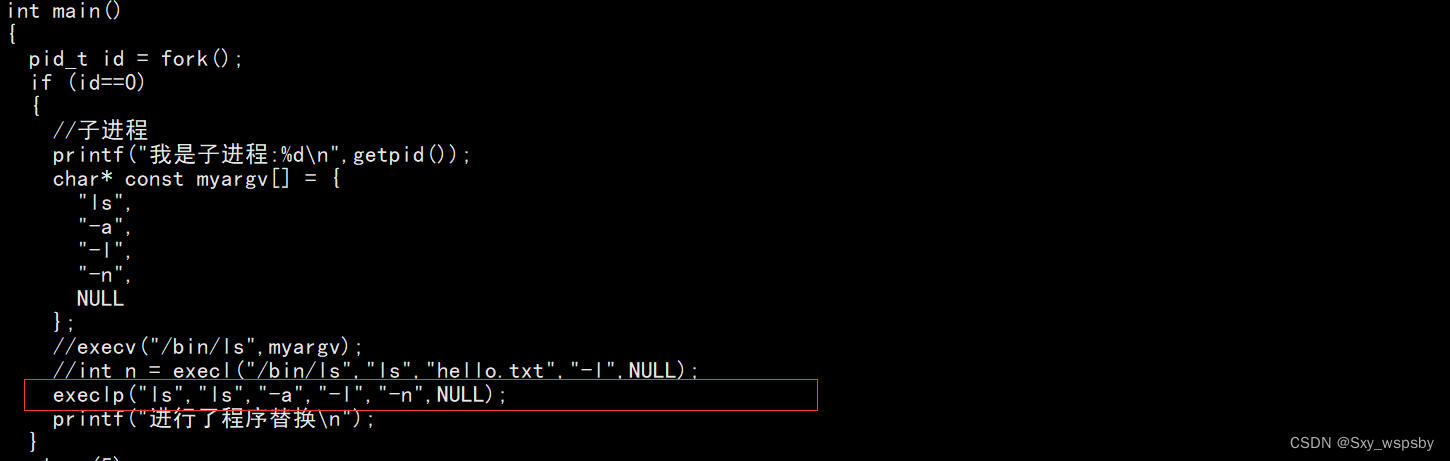
可以看到我们直接传第一个参数ls,现在我们运行一下:

可以看到运行是没问题的。
接下来我们再讲解一下execle接口:
 这个接口的第三个参数envp[]是什么意思呢?这个参数是自定义环境变量,有什么用呢?比如上面我们的父子进程,子进程的环境变量是继承父进程的,而这个参数的意思是如果我们不想要继承父进程的环境变量我们可以自己传环境变量。下面我们演示一下:
这个接口的第三个参数envp[]是什么意思呢?这个参数是自定义环境变量,有什么用呢?比如上面我们的父子进程,子进程的环境变量是继承父进程的,而这个参数的意思是如果我们不想要继承父进程的环境变量我们可以自己传环境变量。下面我们演示一下:
我们先创建一个.cc文件,然后随便写一段代码:
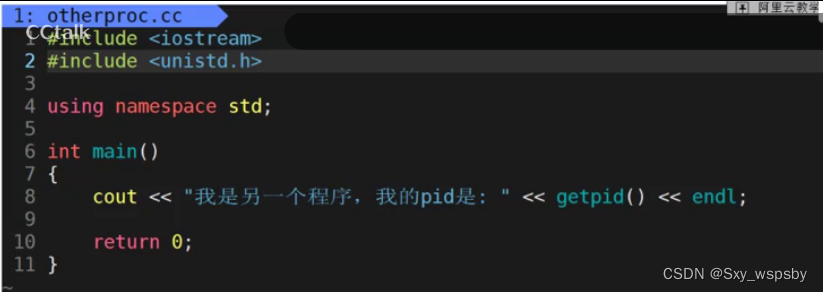 然后我们再进入刚刚3-16的文件,将环境变量的参数写为刚刚的.cc生成的可执行文件:
然后我们再进入刚刚3-16的文件,将环境变量的参数写为刚刚的.cc生成的可执行文件:
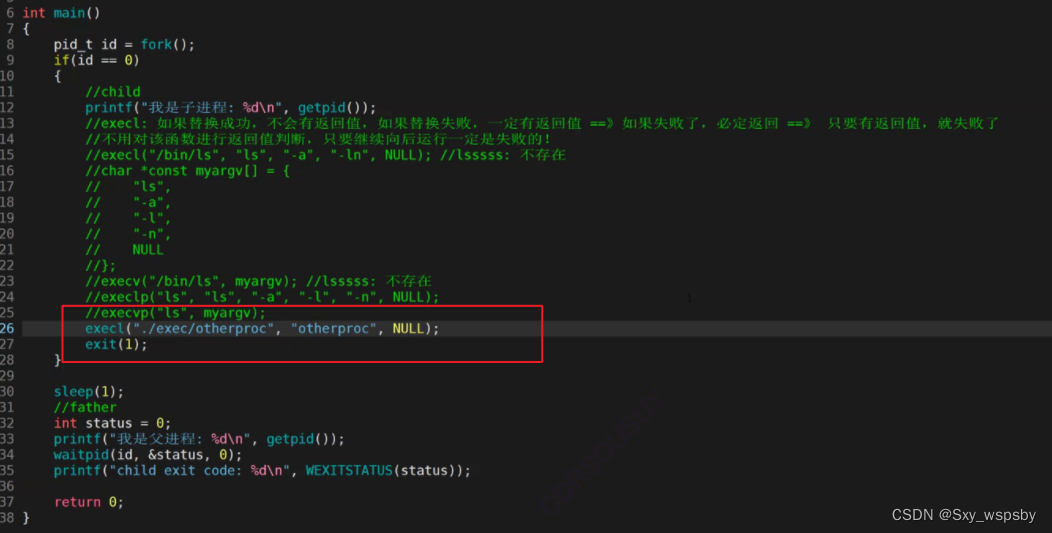
然后我们运行起来,如果能成功的运行other 的代码的话就说明execle这个接口可以将程序替换为自己写的程序:

我们可以看到pid相同运行的程序确实不同并且运行了我们刚刚写的程序。接下来我们再演示一下传环境变量:

首先将other中的代码修改为取得一个环境变量MYENV,如果返回值为NULL说明没取到,否则就是取到了

当我们运行起来发现为NULL,这是因为并没有MYENV这个环境变量,然后我们在刚刚3-16的文件中设置一下这个环境变量:
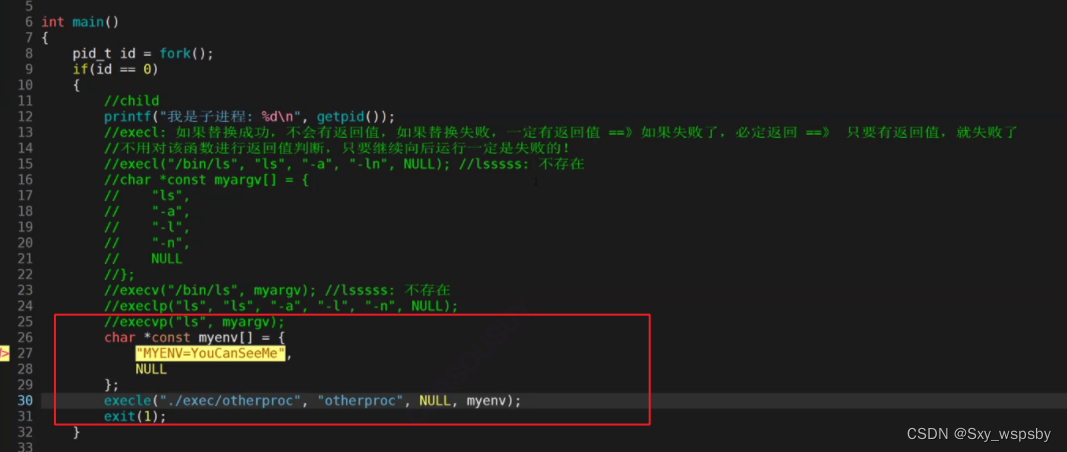 可以看到我们将MYENV设置为youcanseeme,然后我们运行起来:
可以看到我们将MYENV设置为youcanseeme,然后我们运行起来:
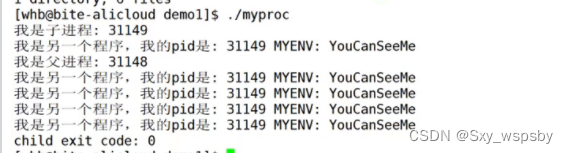
这个时候我们看到确实把环境变量传进去了,下面我们看看最后一个接口:
 为什么这个接口不在刚刚那个里面而被单独列出来呢?因为这个是真正的系统调用,而上面我们讲的都是这个接口的封装,这是为了满足各种场景。
为什么这个接口不在刚刚那个里面而被单独列出来呢?因为这个是真正的系统调用,而上面我们讲的都是这个接口的封装,这是为了满足各种场景。
下面我们编写一个极简版本的shell(bash),目的是为了较为深刻的理解shell的运行原理。

我们先创建一个shell.sh的文件,然后写一段简单的代码:

 然后我们就可以运行了。
然后我们就可以运行了。
下面我们写一个自动切割字符串的shell:
我们先写一个.c文件,然后代码如下:
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <unistd.h>
#include <stdlib.h>
#define MAX 1024
#define SEP " "
int split(char* commandstr,char*argv[])
{assert(conmandstr);assert(argv);argv[0] = strtok(commandstr,SEP);int i = 1;while (1){argv[i] = strtok(NULL,SEP);if (argv[i]==NULL) break;i++;}return 0;
}
void debugprint(char* argv[])
{for (int i = 0;argv[i];i++){printf("%d:%s\\n",i,argv[i]);}
}
int main()
{char commandstr[MAX] = {0};while (1){char commandstr[MAX] = {0};char* argv[ARGC] = {NULL};printf("lisi@mymachine currpath]# ");fflush(stdout);char* s = fgets(commandstr,sizeof(commandstr),stdin);assert(s);(void)s; //保证在release方式发布后,因为去掉assert了,所以s就没有被使用,而带来的编译告警,什么都没做但是充当依次使用commandstr[strlen(commandstr)-1] = '\\0';int n = split(commandstr,argv);if (n!=0) continue;debugprint(argv);pid_t id = fork();assert(id>=0);(void)id;if (id==0){//子进程exit(0);}int status = 0;waitpid(id,&status,0);}return 0;
}

通过结果我们可以看到确实完成了字符串的切割,通过这两个极简版本的shell,我们也确实可以深刻的理解了shell 的运行原理。
总结
对于Linux操作系统的学习我们其实已经进入了一个入门的阶段,从进程开始的学习是相对比较困难与枯燥的,但是我们只要闯过了这一关我们就见到真正的阳光。下一篇是Linux文件描述符相关的学习,希望得到大家的支持!