Python 算法交易实验48 表字段设计

说明
虽然说的是表,实际上用的是Mongo集合
基于ADBS(APIFunc DataBase Service)可以构造一个供后续研究、生产长时间使用的数据基础,这个基础包括了:
- 1 队列服务。通过队列,数据可以通过API实现零担和批量两种模式的快速存储。
- 2 灵活ETL。通过AETL,使用者可以实现高复杂性的操作,但从设计和实现上又非常灵活,这是一种基于图的分解和构建。
- 3 监控与可视化。可以实时看到数据的流入和流转。
ADBS通过简单的设置就可以不断扩展。
内容
其实也是权衡了一下,还是决定按照标准的步骤来推进量化,而不是通过离线代码、松散的实验来推进。
最初在设计ADBS的时候,除了功能性的考虑,也加入了规范性的考虑。一旦操作可以按流程进行,那么工作效率就会提升,可靠性也会提高。
搭建量化研究、生产体系的过程应该也是和搞架构一样,是一个结构性很强,耗时也很长的过程,所以最好按严谨的结构推进。至于核心的方法,在一开始反而可以简单,以跑通为目标。
架构中的算法(方法),或者算法(方法)中的架构总是互相交杂,缠绕在一起的。
本次的目的很简单,就是确定入库原始数据的表字段结构。
本质上,ADBS的数据库使用Mongo,并不会对字段进行太多约束,这里的表字段结构仅仅是从逻辑上约束。
这种约束是具有意义的,后续会有一系列的处理程序,如果能够对输入有所预期,那么在处理时也会比较容易设计。正如APIFunc中的设计经验:从样例数据开始设计总是方便、可靠的,而这里的表字段,也是这个大项目的样例数据表头。
Step1 DataETL 原始数据与基本衍生
Step1: In
| 序号 | 字段名 | 解释 |
|---|---|---|
| 1 | rec_id | 是整个项目的主键,由下面的若干字段联合而成 ( market , code , data_slot) |
| 2 | data_slot | int, 数据时隙,是以分钟为单位的计时法,是记录数据的时间 |
| 3 | data_dt | str, 数据时间,是 YYYY-MM-DD HH:MM:SS 格式的字符时间,起到校验作用 |
| 4 | code | str, 证券代码,应该是唯一的 |
| 5 | market | str, 市场,与code联合形成绝对唯一的代码 |
| 6 | open | float, 开盘价 |
| 7 | close | float,收盘价 |
| 8 | high | float, 高点 |
| 9 | low | float, 低点 |
| 10 | vol | int, 成交量 |
| 11 | amt | float, 成交金额 |
| 12 | trades | int, 成交笔数 |
| 13 | float_capital | int, 流通值 |
第一步入库后,ADBS允许执行ETL,在这个时候允许做通用的特征项,这个特征项是与回顾周期相关的。
初始阶段,我打算手工指定若干个周期。
- 1 短期: 60,120, 240(一个交易日)
- 2 中期:600,1200,2400(十个交易日)
- 3 长期:6000,12000, 24000(一百个交易日)
Step1: Out
这些周期会形成一波新的变量,以下用T指代某个周期(原始的变量会同步被转存)
| 序号 | 字段名 | 解释 |
|---|---|---|
| 1 | open_T | T的开盘价 |
| 2 | high_T | T的最高价 |
| 3 | low_T | T的最低价 |
| 4 | close_T | T的收盘价 |
| 5 | vol_T | T的成交量 |
| 6 | amt_T | T的成交金额 |
| 7 | trades_T | T的交易笔数 |
| 8 | vol_T_mean | T的平均(每时隙)成交量 |
| 9 | amt_T_mean | T的平均成交金额 |
| 10 | trades_T | T的平均成交笔数 |
Step2 Signals 信号生成
这个比较有意思,出现了第二个ADBS。
Step2.In = Step1.Out
通常来说,AETL允许对平面化的数据进行足够复杂的操作,但是,但需要的操作是深度式的时候,就需要进行级联了。
在设计ADBS时,为了确保复用性、稳定性,所以约定了每个ADBS只管一个step。第一个step中已经完成了原始数据,以及若干周期的简单衍生。
在这个step中,主要根据上一个step中生成的基本变量,生成交易信号。
这里探讨一个小问题:有没有可能在step1中同时完成交易信号?
理论上可能,但是真要这么做会非常麻烦,甚至会因为新的尝试而破坏旧的,运行中的东西。在上一步中,已经根据过去若干个周期进行了统计。在很多传统的新号计算方法里,会对若干周期的统计值,再进行若干周期统计。从阶数上来说是 T2T^2T2, 从计算的顺序来说肯定也是计算两次。
对具体的计算指标我回头再翻翻书,正好没带在身边。
| 序号 | 字段名 | 解释 |
|---|---|---|
| 1 | SOME_buy_T_t | 使用T周期对 t周期进行计算生成的买入信号 |
| 2 | SOME_sell_T_t | 使用T周期对 t周期进行计算生成的卖出信号 |
后续生成买入信号可能会有很多很多组,从周期上来说分为短期、长期等,从原理来说分为回归、周期以及动量。
Step2.Out 输出买卖的信号
到这一步,故事显然还没有结束。
Step3 Decision 交易信号与指令
Step3.In = Step2.Out 注意,交易信号与原始的价格无关(Step1.Out)
生成买入信号并不能允许直接交易,仅从决策角度看,就需要进行纵向和横向的参考。
例如,信号经常会出现毛刺噪声,如果仅仅一次买入信号就买入的话很容出错,所以会从纵向上进行持续观察,我称之为冷静时间。
除此之外,从宏观角度,我们还需要知道长周期趋势。这样的目的是为了避免在低概区交易,以及避免系统风险(断崖式、持续下跌)。
除了纵向,还要考虑横向的其他维度
未来肯定是多种方法的信号并存的,所以除了自身维度的信号判断之外,也可以考虑一种投票机制,来辅助作出交易决策。
决策作出之后,在真实的交易之前,还有一些小的步骤需要完成,就是交易指令。可以简单理解为加滑点进行买卖交易的策略,这个可以暂时略过。
不同的策略可能会基于同样的信号操作,所以要增加策略名来区别。策略名也可以按三级命名来操作。
Step3.Out 输出买卖的决定,以及交易信号
Step4 Trade 交易的撮合与记录
基于上一刻的决定和这一刻的数据进行操作
这里的输入有两个:
Step4.In = Step1.Out ~ 标的的时隙数据( open, close, high, low) &
Step3.Out ~ 在上个时隙作出交易决策 (target_price, amt, buy/sell)
我们总是先做好决定,然后再采取行动,无论这个先后差距长或者短,总是如此。量化不过是用更精细,更准确的方法来千百次的替代我们完成这个过程。
如果Step3中没有Open的决策(Open Orders),那么这一步就可以直接略过。反之,如果有决策没有被实现,那么Step4就会看在当前时隙是否可以完成。
这里假设了Step3中已经发出了自动化交易请求,实际上目前对于个人投资者用接口直接交易还是不太方便,但我们可以假定如此。
当target_price处于high和low之间时,交易被完成,否则就轮空。
轮空状态下,会有一些对应的处理方法。例如大量Open Orders是否要发起告警,或者是要调低目标价。
从整体上来看,Step4或者产生1/n个close order,或者什么也不做。
Step4.Out(if any) 输出完结订单
这样结束了吗?显然还不…
Step5 Watch 观察序列变化及干预
Always Watch Back
Step5.In = Step4.Out
Dalio在《原则》里有提到桥水的量化模型,当上线之后人就不干预了,直到触碰规则。所以,量化是一种 Run… Until …的模式。
我们会让策略上线,一定是有我们的期望,这既包括了好的期望,也包括了坏的准备。如同正态分布,我们不认为策略会超过3个西格玛。
因此,我们需要持续的观察,来确保一切尽在掌握。
Step5会在每个时间点进行回看,主要从几方面比较:
- 1 最大回撤是否超标
- 2 最大正收益是否超标(是的,我觉得这个也要看)
- 3 交易周期
- 4 资金敞口
- 5 超额收益
Step5.Out 收益曲线、回撤曲线等
这部分的结果会输出到我portal的dash board里。
Ending
总的说起来,这是一个由5个ADBS构成的处理流。我觉得这样才比较好解释,为啥之前总是半途而废:强行用简单的处理办法去容纳复杂问题就好比用一个杯子去装一壶水。分治其实是唯一的办法,分治核心在于结构。
以下是工作流的基本框架
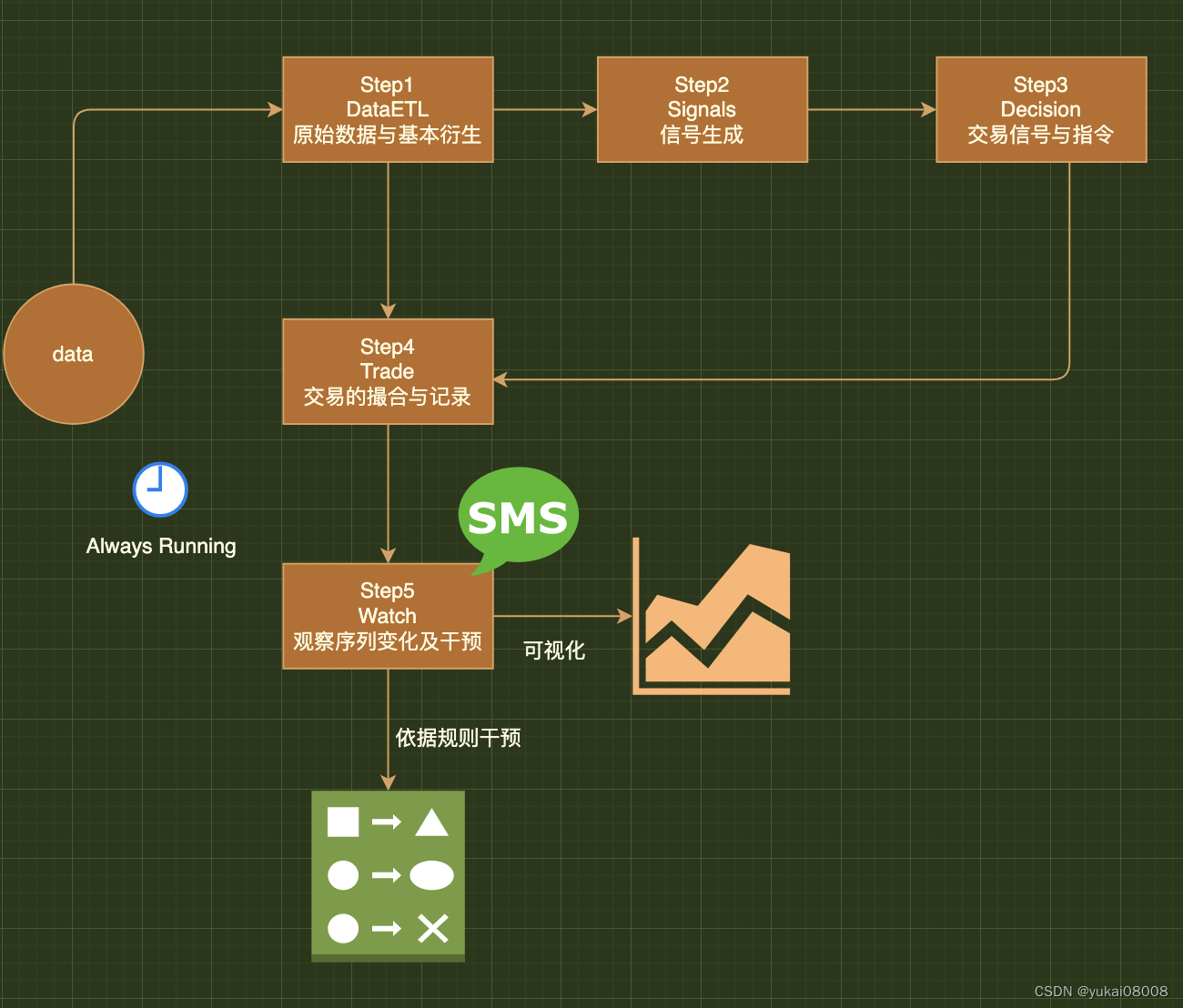
还有许多未尽部分,例如策略的中途叠加、多模型协同、生成式估计、自动优化等,这些在“1”完成了之后会逐步的进行迭代。
本次完成了“0”的突破-转变,算0.1吧。