8、Diffusion Models Beat GANs on Image Synthesis

简介
论文研究了当前diffusion最新技术与GANs对比,多方面展示了diffusion 模型的效果
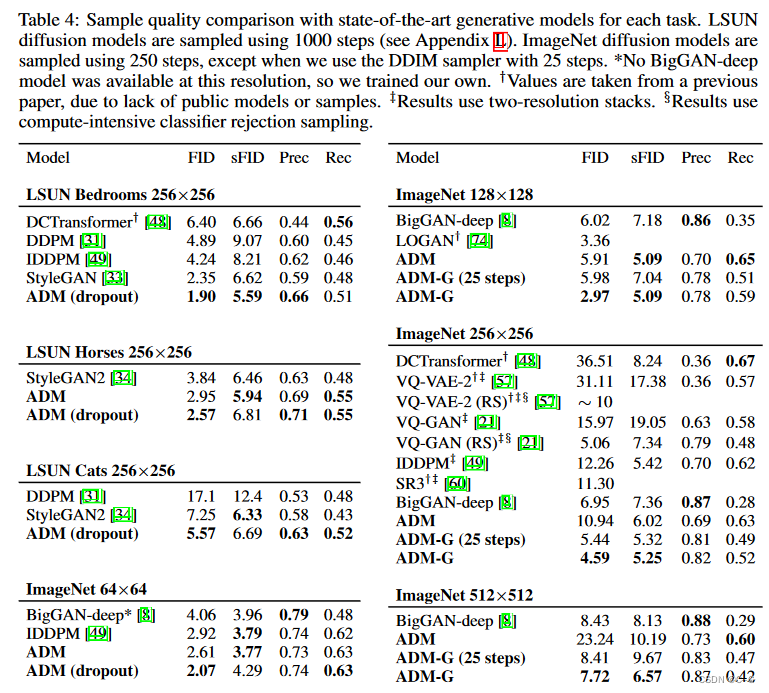
在ImageNet 128⇥128上实现了2.97的FID,在ImageNet 256⇥256上实现了4.59,在ImageNet 512⇥512上实现了7.72,即使每个样本只有25个前向传递,也能匹配BigGAN-deep,同时保持更好的分布覆盖。
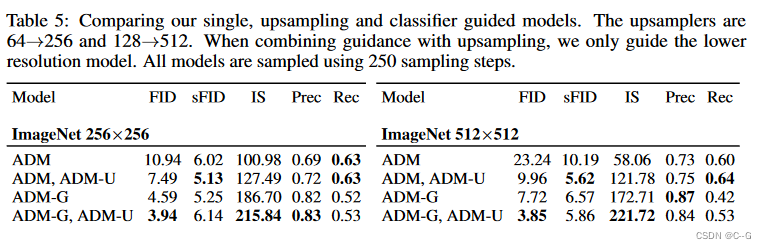
分类器指导与上采样扩散模型结合得很好,进一步将ImageNet 256⇥256上的FID提高到3.94,ImageNet 512⇥512上的FID提高到3.85。

Architecture Improvements
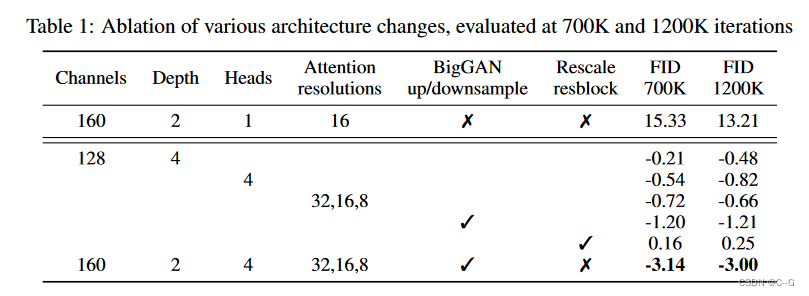
diffusion 模型改进方向:
- 增加深度和宽度,保持模型大小相对不变
- 增加注意力头的数量
- 使用32⇥32,16⇥16和8⇥8分辨率的注意力,而不是仅在16⇥16
- 使用BigGAN残差块对激活进行上采样和下采样
- 重新缩放残差连接到 12\\frac{1}{\\sqrt{2}}21
除了重新调整剩余连接,所有其他修改都可以提高性能并产生积极的复合效应,同时增加深度对训练时间的影响最大,因此不考虑这方面
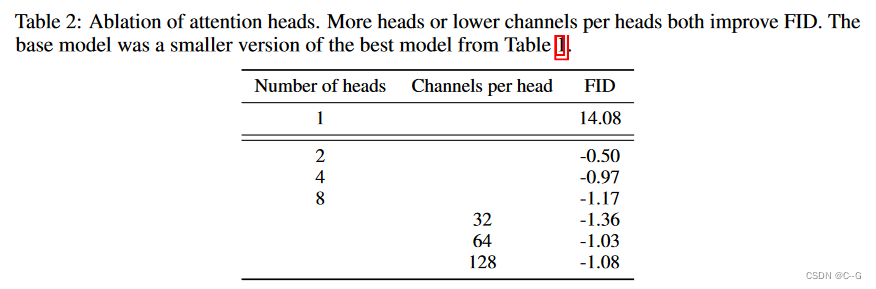
更多的头或更少的每个头通道可以提高FID,实验表明 64个通道数是最好的
还实验了一个层,称之为自适应组归一化(AdaGN),在组归一化操作后将时间步长和类嵌入到每个残差块中,定义为 AdaGN(h,y) = ysy_sys GroupNorm(h) + yby_byb
h是第一次卷积之后剩余块的中间激活,y=[ys,yb]y =[y_s,y_b]y=[ys,yb] 是从时间步长和类嵌入的线性投影中获得的
后续研究基于以下结构的模型:
- 可变宽度,每个分辨率有2个剩余块
- 多个头部,每个头部有64个通道
- 注意力在32、16和8分辨率
- BigGAN残差块用于上采样和下采样
- 自适应组归一化用于将时间步长和类嵌入注入残差块
Classifier Guidance
利用分类器 p(y|x) 来改进扩散生成器。使用分类器的梯度来调节预训练的扩散模型,在噪声图像 xtx_txt 上训练分类器 pϕ(y∣xt,t)p_\\phi (y|x_t,t)pϕ(y∣xt,t),然后使用梯度∇logpϕ(y∣xt,t)\\nabla \\log p_\\phi (y|x_t,t)∇logpϕ(y∣xt,t) 来指导向任意类标签 y 的扩散采样过程
用于引导的最终采样算法分别为算法1和算法2。这两种算法通过将分类器的梯度添加到每个采样步骤,并采用适当的步长来合并类信息。


其中,为了简洁,采用pϕ(y∣xt,t)=pϕ(y∣xt),ϵϕ(xt,t)=ϵϕ(xt)p_\\phi(y|x_t,t) = p_\\phi(y|x_t),\\epsilon_\\phi(x_t,t) = \\epsilon_\\phi(x_t)pϕ(y∣xt,t)=pϕ(y∣xt),ϵϕ(xt,t)=ϵϕ(xt)
分类器架构只是UNet模型的下采样主干,在8x8层上有一个注意力池以产生最终输出。将这些分类器训练在与相应扩散模型相同的噪声分布上,并添加随机作物以减少过拟合
在对无条件ImageNet模型的初始实验中,发现有必要将分类器梯度缩放一个大于 1 的常数因子。
当分类器梯度为1时,分类器为最终样本的期望类别分配了合理的概率(约50%),扩大分类器的梯度可以解决这个问题,分类器的类概率增加到接近100%

其中分类器梯度 s⋅∇xlogp(y∣x)=∇xlog1zp(y∣x)ss\\cdot\\nabla_x logp(y|x) = \\nabla_xlog \\frac{1}{z}p(y|x)^ss⋅∇xlogp(y∣x)=∇xlogz1p(y∣x)s,Z是一个任意常数
调节过程理论上仍然基于与 p(y∣x)sp(y|x)^sp(y∣x)s 成比例的重新归一化分类器分布,当s>1时,这个分布比 p(y|x) 更清晰,因为较大的值会被指数放大,使用更大的梯度尺度更关注分类器的模式,这对于产生更高质量(但多样性较少)的样本可能是可取的
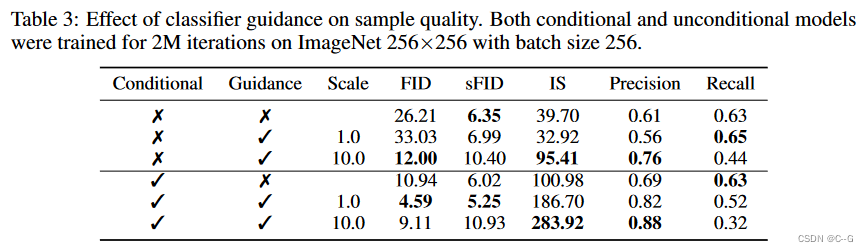
通过分类器引导,无条件模型和条件模型的样本质量都可以得到很大的提高,在足够大的规模下,引导无条件模型可以非常接近无引导条件模型的FID,尽管直接使用类标签进行训练仍然有帮助。指导条件模型进一步改善FID。
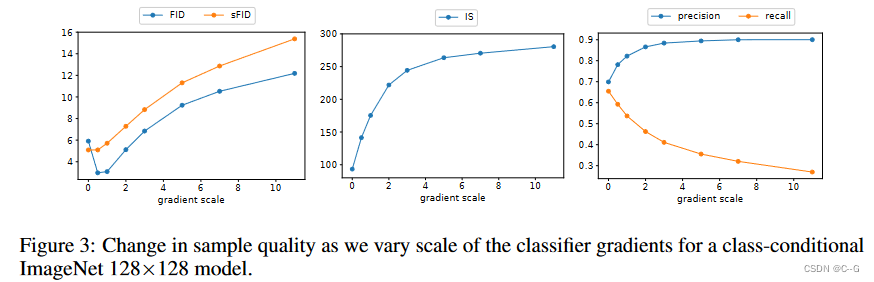
分类器引导以召回率为代价提高了精度,从而引入了样本保真度与多样性之间的权衡。
将梯度扩展到 1.0 以上可以平滑地权衡召回率(多样性的衡量标准),以获得更高的精度和 IS(保真度的衡量标准)
由于FID和sFID同时依赖于多样性和保真度,它们的最佳值是在中间点获得的
与BigGAN的截断技巧进行了比较,在以FID代替Inception Score时,分类器指导严格地优于BigGAN-deep。
精度/召回率的权衡不太清楚,它表明分类器指导只是在一定的精度阈值之前是一个更好的选择,超过这个阈值就不能达到更好的精度
Result
为了评估分类器指导,在ImageNet数据集上训练条件扩散模型,分辨率为128⇥128,256⇥256和512⇥512。
Limitations and Future Work
由于使用了多个去噪步骤(因此是向前传递),它们在采样时仍然比GANs慢
由于扩散模型也比竞争的GAN生成器大,因此每次向前传播所需的时间也要长5-20倍,是减少这种延迟差距的一个方向是一种将DDIM采样过程提取为单步模型的方法
与GANs、flow和vae不同,扩散模型不学习显式的潜在表示。虽然DDIM提供了一种将图像编码到隐式潜在空间的方法,但与其他模型类相比,这种潜在表示的语义意义如何尚不清楚。这会使扩散模型难以用于表示学习或图像编辑应用程序
分类器引导的有效性表明,可以从分类函数的梯度中获得强大的生成模型。用于使用CLIP的噪声版本来调节带有文本标题的图像生成器,类似于最近使用文本提示引导GANs的方法
分类器引导技术目前仅限于标记数据集,在未来,通过聚类样本来生成合成标签或通过训练判别模型来用于指导,从而扩展到未标记的数据,同时,可以利用大型未标记数据集来预训练强大的扩散模型,之后可以通过使用具有理想属性的分类器来改进模型
Conclusion
已经证明,扩散模型,一类具有固定训练目标的基于可能性的模型,可以获得比最先进的GANs更好的样本质量。改进的架构足以在无条件的图像生成任务上实现这一点,而分类器引导技术允许在有类条件的任务上做到这一点。在后一种情况下,发现分类器梯度的规模可以调整,以权衡多样性的保真度。这些引导扩散模型可以减少GANs和扩散模型之间的采样时间间隔,尽管扩散模型在采样过程中仍然需要多次前向传递。最后,通过结合引导和上采样,可以进一步提高高分辨率条件图像合成的样本质量。