Mysql架构初识
MySql架构:连接池与性能优化的趣味指南
MySql就像一个高效的大管家,数据库连接池就是他的“服务员团队”。遇到大量并发访问时,传统的每次请求都创建新连接的做法,就像每来一位客人就雇一位新的服务员,不仅费时还费钱。而连接池则是让这些服务员循环复用,大大提升效率。
在线程处理上,MySql有自己的一套“生产线”,接收请求、解析SQL、优化执行路径,就像工厂里的传送带一样高效运转。特别是查询优化器,它就像一位聪明的采购经理,总能找到最优的采购路线,保证库存及时补货。
存储引擎部分,InnoDB支持事务和外键,就像一个严谨的仓库管理员,确保库存数据的安全可靠。而缓存池就像冷库,提前准备好热门商品,让顾客能快速拿货,提升整体服务速度。掌握这些,你也可以成为数据库性能优化的小达人!

🥲 🥸 🤌 🫀 🫁 🥷 🐻❄️🦤 🪶 🦭 🪲 🪳 🪰 🪱 🪴 🫐 🫒 🫑 🫓 🫔 🫕 🦤 🪶 🦭 🪲 🪳 🪰 🪱 🐻❄️ 🫐 🫒 🫑 🫓 🫔 🫕
♔博主昵称:�欢快↑㎡
🕍博客主页:�欢快↑㎡的博客_CSDN博客-学习注意点杂记,BUG集,安装教程领域博主
⚇很方便的在线编辑器:Lightly
🥗感谢点赞🤞🏻评论🤞🏻收藏
相信吧!🤜🏻我们很优秀,还可以更加优秀,加油!🌼让我们一起在写作中记录巩固学习吧!
目录
java和mysql整体概览
MySql驱动
数据库连接池
java系统连接池
mysql数据库的连接池
网络线程连接谁来负责连接
sql接口
查询解析器
查询优化器
执行器
更新怎么执行
InnoDB缓存池
undo日志
redo日志
事务未提交
binlog
binlog刷盘策略
常见刷盘策略
完成事务提交
刷新脏数据
java和mysql整体概览
java的系统连接Mysql的系统
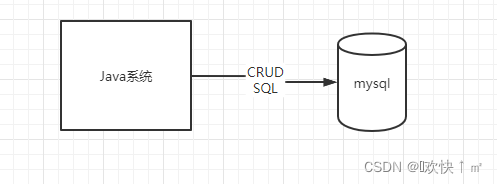
只知道大概在遇到问题不能更好的解决问题。比如死锁,sql性能,异常报错等问题。所以需要我们了解逻辑,才能更好,更快的解决问题。
MySql驱动
我们需要在依赖中增加一个mysql驱动,才能与mysql建立连接。
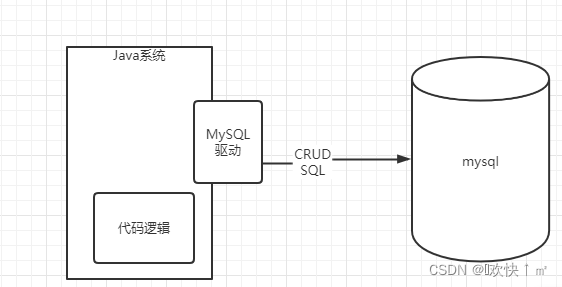
使用Maven管理项目依赖,可以在pom.xml文件中添加以下依赖:
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version>
</dependency>然后,在Java代码中,需要使用JDBC API与MySQL数据库建立连接。以下是一个示例代码片段:
import java.sql.*;public class MysqlConnect {public static void main(String[] args) {Connection conn = null; //Connection 类可以管理和控制连接try {String dburl = "jdbc:mysql://localhost:3306/mydatabase"; //连接地址String user = "myusername"; //用户名String password = "mypassword"; //密码// 建立连接conn = DriverManager.getConnection(dburl, user, password);System.out.println("连接成功");} catch (SQLException e) {System.out.println("连接失败:" + e.getMessage());} finally {if (conn != null) {try {conn.close(); //关闭连接} catch (SQLException e) {System.out.println("关闭连接失败:" + e.getMessage());}}}}
}数据库连接池
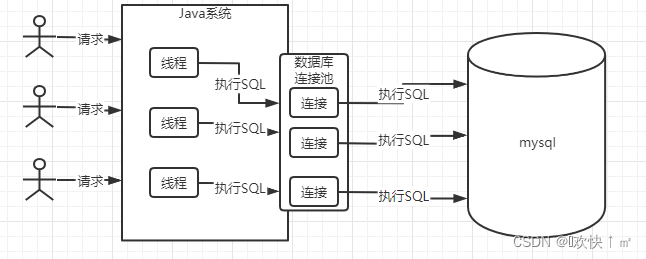
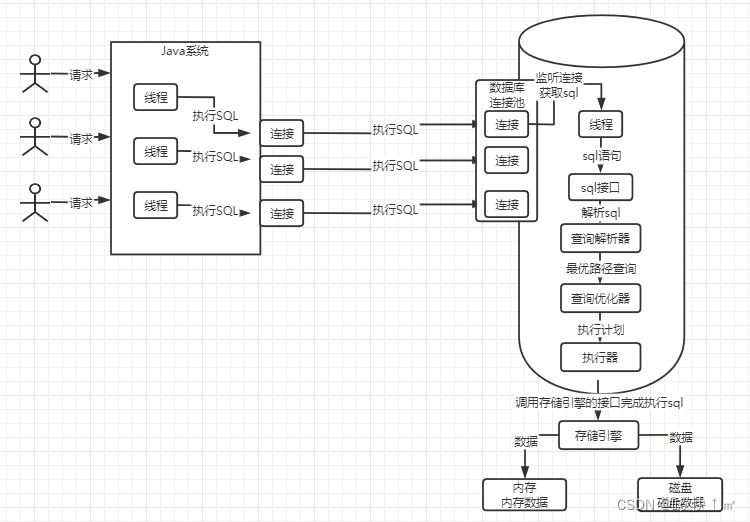
java系统建立连接是建立多个连接的,建立的连接如果频繁的销毁或创建会造成性能低下,所以是采用复用连接的(web应用是部署在tomcat里面的,springboot项目相当于内嵌了tomcat)
java系统连接池
数据库里面的连接时复用的
mysql数据库的连接池
mysql数据库中的连接也是多线程的,并且也是复用的
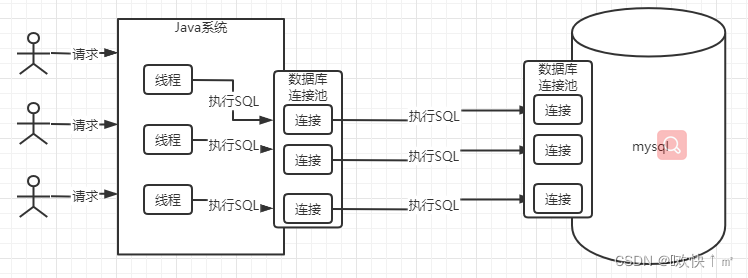
网络线程连接谁来负责连接
是靠线程来负责连接的,可以监听连接,读取连接中的sql
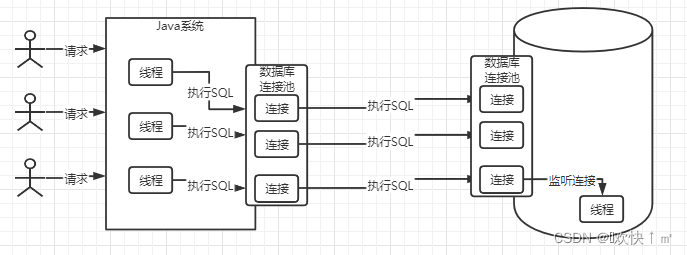
sql接口
线程调用sql接口,并将获取到的sql语句给接口
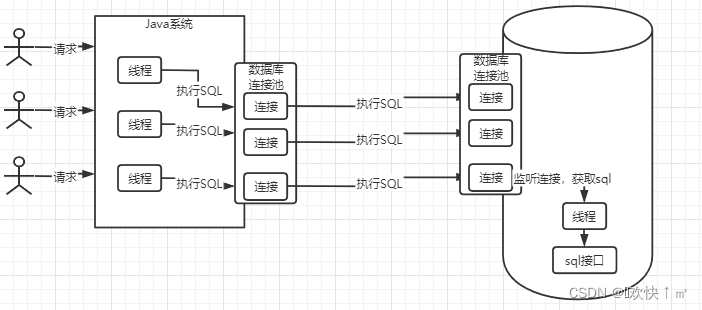
查询解析器
就会解析,让mysql看得懂,比如要从某表做查询动作,条件是什么
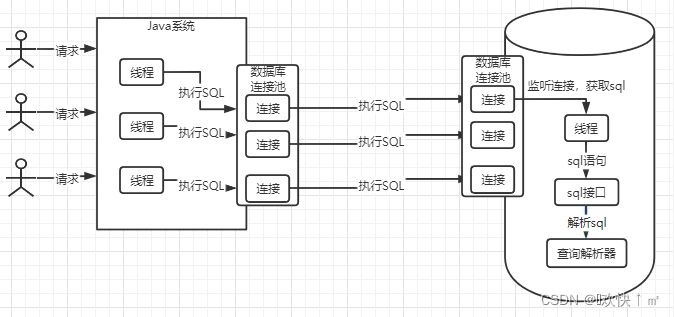
查询优化器
选择一个最有查询路径,比如有两条路径(假设)
路径1:定位到user表id=10,查name,age
路径2:把userr name age 都查询出来,看哪条数据id=10
从路径1和路径2中选出一条最优路径
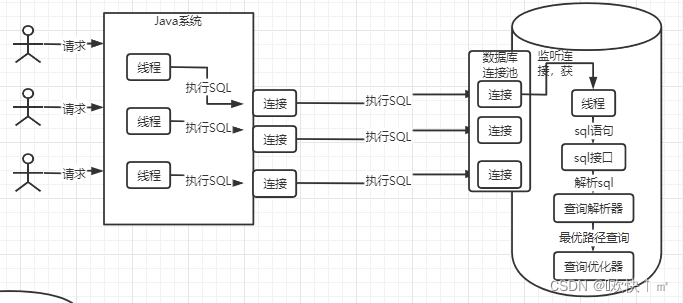
执行器
调用存储引擎,根据优化器生成得执行计划调用存储引擎的接口
mysql中sql接口,sql解析器,查询优化器是同用得
存储引擎有:InnoDB,MyISAM,Memory
更新怎么执行
例子:update user set name = 'aaa' where id = 10;
InnoDB缓存池
它有一个叫Buffeer-pool的缓存池,其中缓存着很多数据,查询的时候,如果缓存池里面有,则不查询磁盘。放在缓存里面可以加快它的访问速度。
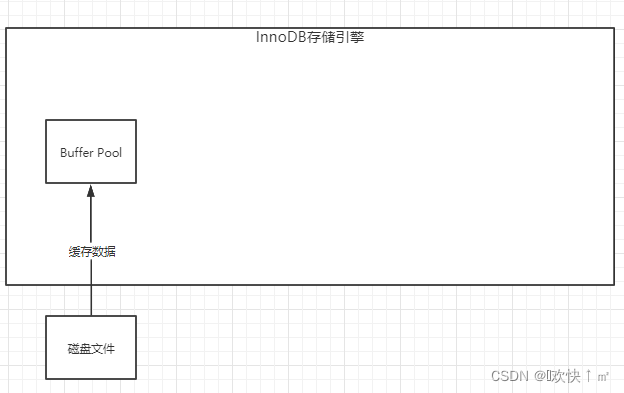
如果缓存池里面没有,则从磁盘加载数据到缓存池,对这条数据加独占锁(更新的时候别人不能同时更新)------排他锁------对应共享锁
<