大数据技术之Kafka集成

一、集成Flume
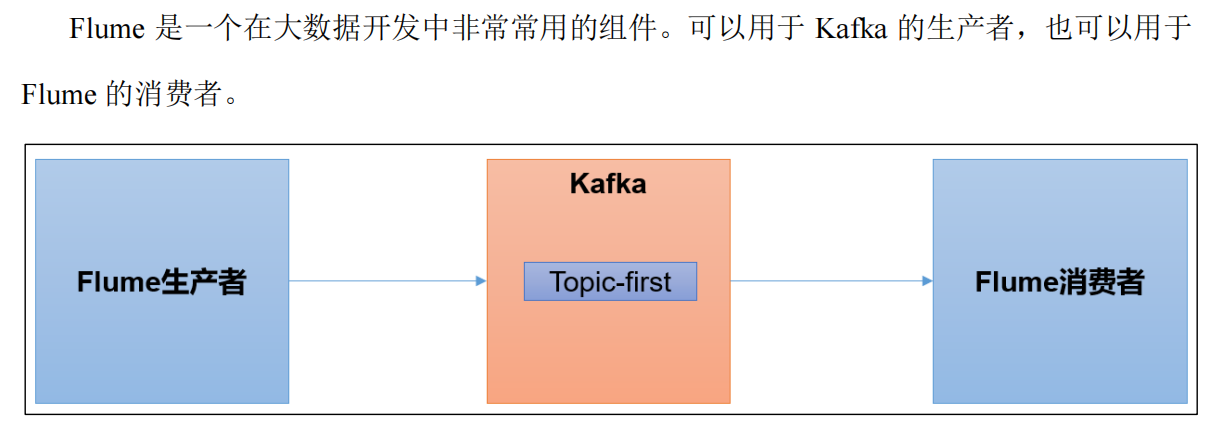
1.1 Flume生产者
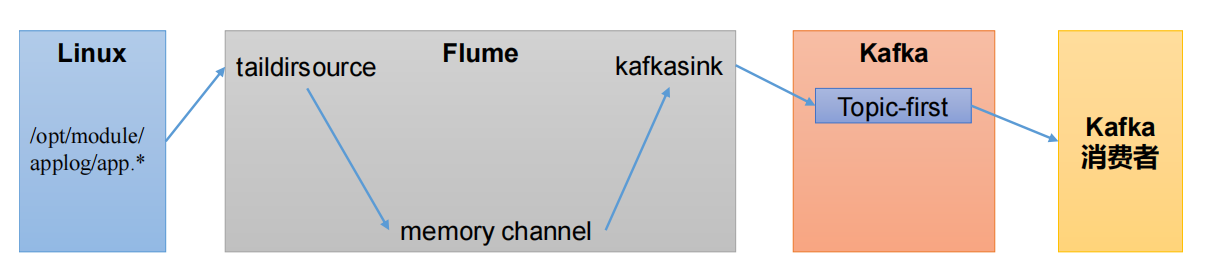
(1)启动Kafka集群
zkServer.sh startnohup kafka-server-start.sh /opt/soft/kafka212/config/server.properties &(2)启动Kafka消费者
kafka-console-consumer.sh --bootstrap-server 192.168.153.139:9092 --topic first(3)配置flume
配置flume
(4)启动flume
mkdir /opt/soft/kafka212/conf/jobs
vim /opt/soft/kafka212/conf/jobs/file_to_kafka.conf# 1. 定义组件
a1.sources = r1
a1.sink2 = k1
a1.channels = c1# 2. 配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json# 3. 配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 4. 配置sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers
hadoop101:9092,hadoop102:9092,hadoop103:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1# 5. 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1(5)启动flume
cd /opt/soft/flume190/
./bin/flume-ng agent --name a1 --conf ./conf --conf-file ./conf ./jobs/file_to_kafka.conf(6)追加数据,查看Kafka消费者消费情况
1.2 Flume消费者
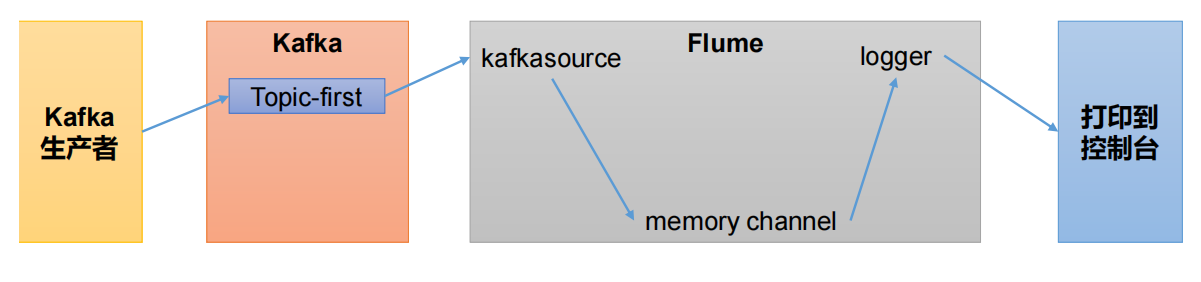
(1)配置flume
mkdir /opt/soft/kafka212/conf/jobs
vim /opt/soft/kafka212/conf/jobs/kafka_to_file.conf# 1. 定义组件
a1.sources = r1
a1.sink2 = k1
a1.channels = c1# 2. 配置source
a1.sources.r1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sources.r1.batchSize = 50
a1.sources.r1.batchDurationMillis = 200
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092
a1.sources.r1.kafka.topics = first
a1.sources.r1.kafka.consumer.group.id = custom.g.id# 3. 配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 4. 配置sink
a1.sinks.k1.type = logger# 5. 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1(2)启动flume
cd /opt/soft/flume190/
./bin/flume-ng agent --name a1 --conf ./conf --conf-file ./conf ./jobs/kafka_to_file.conf(3)启动Kafka生产者
bin/kafka-console-producer.sh --bootstrap-server hadoop02:9092 --topic first(4)输入数据并监控
二、集成SpringBoot
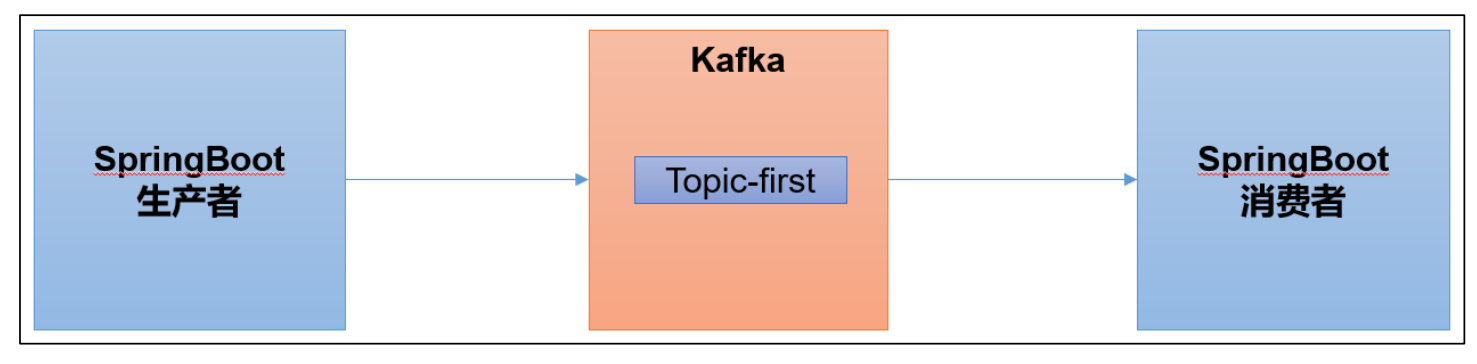
1)在IDEA中安装lombok插件
2)SpringBoot环境准备
(1)创建一个Spring Initializr
(2)添加项目依赖
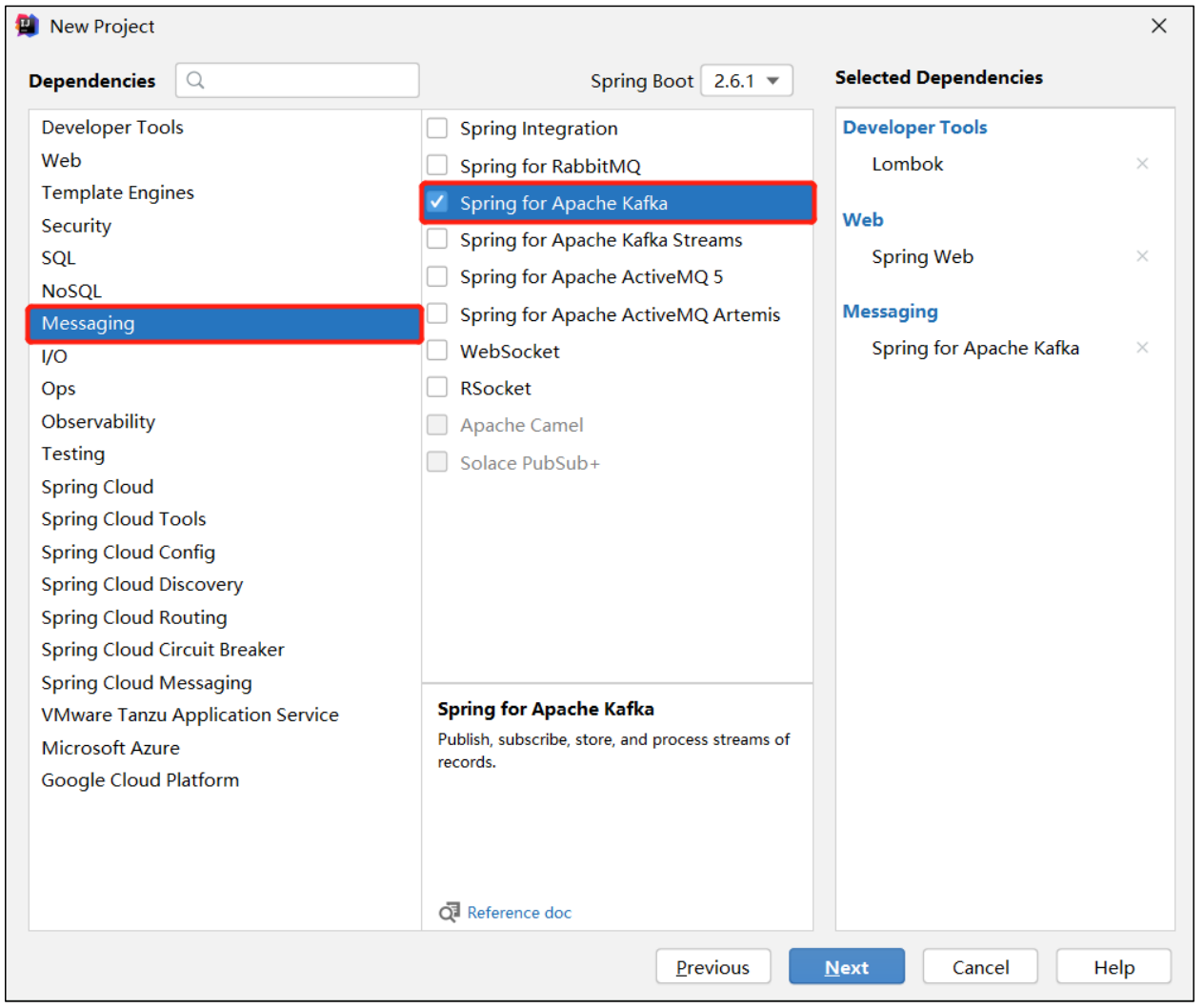
(3)检查自动生成的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.1</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.atguigu</groupId><artifactId>springboot</artifactId><version>0.0.1-SNAPSHOT</version><name>springboot</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build>
</project>3.1 SpringBoot生产者
(1)修改SpringBoot核心配置文件application.properties,添加生产者相关信息
# 应用名称spring.application.name=atguigu_springboot_kafka# 指定 kafka 的地址spring.kafka.bootstrap-servers=hadoop102:9092,hadoop103:9092,hadoop104:9092#指定 key 和 value 的序列化器spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializerspring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer(2)创建controller从浏览器接收数据,并写入指定的topic
package com.atguigu.springboot;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class ProducerController {// Kafka 模板用来向 kafka 发送数据@AutowiredKafkaTemplate<String, String> kafka;@RequestMapping("/atguigu")public String data(String msg) {kafka.send("first", msg);return "ok";}
}(3)在浏览器中给/atguigu接口发送数据
http://localhost:8080/atguigu?msg=hello3.2 SpringBoot消费者
(1)修改SpringBoot核心配置文件application.properties
# =========消费者配置开始=========
# 指定 kafka 的地址
spring.kafka.bootstrap-servers=hadoop102:9092,hadoop103:9092,hadoop104:9092# 指定 key 和 value 的反序列化器
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer#指定消费者组的 group_id
spring.kafka.consumer.group-id=atguigu
# =========消费者配置结束=========(2)创建类消费Kafka中指定topic的数据
package com.atguigu.springboot;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaListener;@Configuration
public class KafkaConsumer {// 指定要监听的 topic@KafkaListener(topics = "first")public void consumeTopic(String msg) { // 参数: 收到的 valueSystem.out.println("收到的信息: " + msg);}
}(3)向first主题发送数据
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --bootstrap=server hadoop102:9092 --topic first三、集成Spark
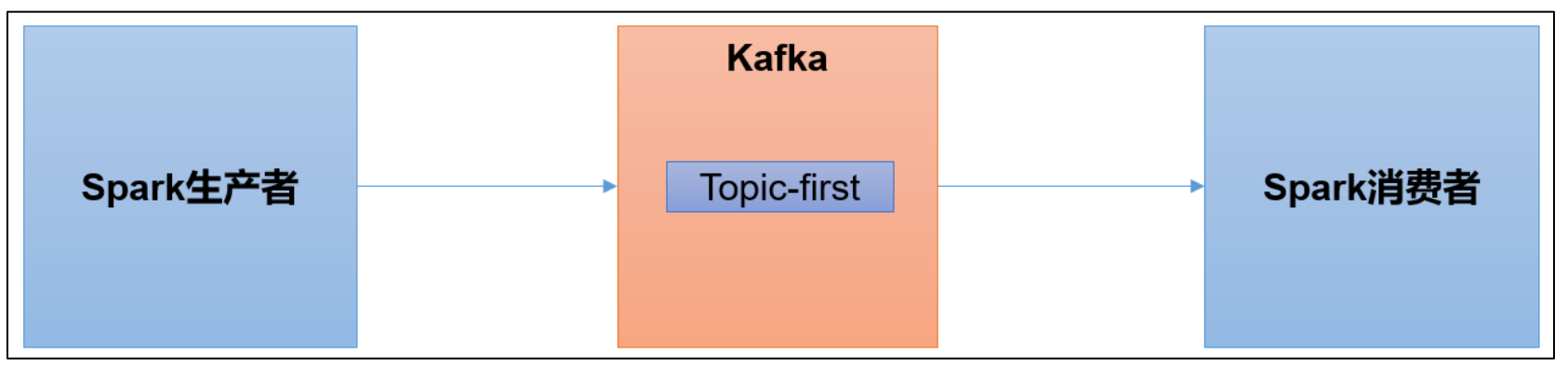
1)scala环境准备
2)spark环境准备
(1)创建一个maven项目spark-kafka
(2)在项目spark-kafka上添加框架支持Add Framework Support,选择sacla
(3)在main下创建scala文件夹,添加为源码包
(4)添加配置文件
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version></dependency>
</dependencies>(5)将log4j.properties文件添加到resources中,更改打印日志级别为error
log4j.rootLogger=error, stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%nlog4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../log/agent.log
log4j.appender.R.MaxFileSize=1024KB
log4j.appender.R.MaxBackupIndex=1log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n3.1 spark生产者
(1)在当前包下创建scala object:SparkKafkaProducer
package com.atguigu.sparkimport java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}object SparkKafkaProducer {def main(args: Array[String]): Unit = {// 0 kafka 配置信息val properties = new Properties()properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092,hadoop104:9092")properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])// 1 创建 kafka 生产者var producer = new KafkaProducer[String, String](properties)// 2 发送数据for (i <- 1 to 5){producer.send(new ProducerRecord[String,String]("first","atguigu" + i))}// 3 关闭资源producer.close()}
}(2)启动Kafka消费者
[atguigu@hadoop104 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first(3)执行SparkKafkaProducer程序,观察Kafka消费者控制台情况
3.2 spark消费者
(1)添加配置文件
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.0.0</version></dependency>
</dependencies>(2)在当前包下创建scala object:SparkKafkaConsumer
package com.atguigu.sparkimport org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}object SparkKafkaConsumer {def main(args: Array[String]): Unit = {//1.创建 SparkConfval sparkConf: SparkConf = new SparkConf().setAppName("sparkstreaming").setMaster("local[*]")//2.创建 StreamingContextval ssc = new StreamingContext(sparkConf, Seconds(3))//3.定义 Kafka 参数:kafka 集群地址、消费者组名称、key 序列化、value 序列化val kafkaPara: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguiguGroup",ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])//4.读取 Kafka 数据创建 DStreamval kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent, //优先位置ConsumerStrategies.Subscribe[String, String](Set("first"), kafkaPara)// 消费策略:(订阅多个主题,配置参数))//5.将每条消息的 KV 取出val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())//6.计算 WordCountvalueDStream.print()//7.开启任务ssc.start()ssc.awaitTermination()}
}(3)启动SparkKafkaConsumer消费者
(4)启动Kafka生产者
[atguigu@hadoop103 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first