CHAPTER 6: 《DESIGN A KEY-VALUE STORE》 第6章 《设计一个键值存储》

CHAPTER 6: DESIGN A KEY-VALUE STORE
键值存储(也称为键值数据库)是一种非关系数据库。每一个唯一标识符存储为与其关联值的键。这种数据配对称为“键-值”对。
在一个键-值对中,键必须是唯一的,与该键相关联的值可以是通过密钥访问。键可以是纯文本或散列值。出于性能考虑,短键效果更好。
钥匙看起来像什么?下面是一些例子:
- 纯文本密钥:“last_logged_in_at”
- 散列密钥:253DDEC4
键值对中的值可以是字符串、列表、对象等。该值通常被视为键值存储中的不透明对象,如Amazon dynamo [1], Memcached [2], Redis[3]等。
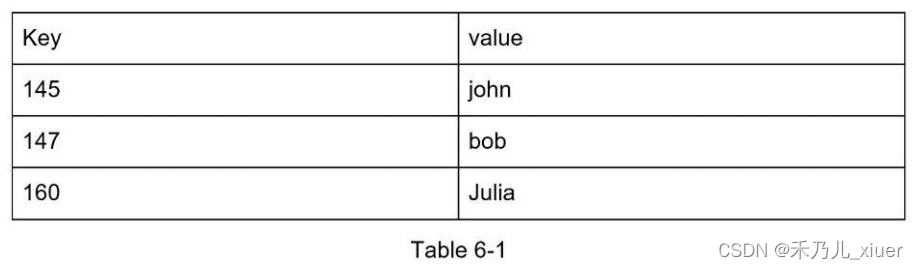
下面是键-值存储中的数据片段:
在本章中,要求您设计一个支持以下功能的键值存储操作:
- put(key, value) //插入与key相关的value
- get(key) //获取与“key”相关的“value”
了解问题并确定设计范围
没有完美的设计。每一种设计都达到了一个特定的平衡读、写和内存使用情况。另一个需要权衡的是一致性和可用性。在本章中,我们设计了一个包含以下内容的键值存储特点:
- 键值对大小较小,一般小于10kb。
- 具备大数据存储能力。
- 高可用性:即使在故障期间,系统也能快速响应。
- 高可扩展性:系统可扩展以支持大型数据集。
- 自动扩展:服务器的添加/删除应该基于流量自动。
- 可调一致性。
- 低延迟
单服务器键值存储
开发驻留在单个服务器中的键值存储很容易。一个直观的方法是在哈希表中存储键值对,哈希表将所有内容保存在内存中。尽管内存访问速度很快,由于空间的原因,可能无法将所有内容装入内存约束。为了在单个服务器上容纳更多数据,可以进行两种优化:
- 数据压缩
- 仅将频繁使用的数据存储在内存中,其余数据存储在磁盘上
即使进行了这些优化,单个服务器也可以很快达到其容量。一个支持大数据需要分布式键值存储。
分布式键值存储
分布式键值存储也称为分布式哈希表,它将键值对分布在许多服务器上。在设计分布式系统时,重要的是
理解CAP(C一致性、A可用性、P分区容错性)定理。
CAP定理
CAP定理指出,分布式系统不可能同时提供更多的服务这三个保证中的两个:一致性、可用性和分区容忍度。让我们建立一些定义。
C 一致性:一致性是指所有客户端在同一时间看到相同的数据它们连接到哪个节点。
A 可用性:可用性意味着任何请求数据的客户端都能得到响应,即使是一些响应所有的节点都关闭了。
P 分区容忍:一个分区表示两个节点之间的通信中断。分区容忍意味着系统在网络分区的情况下继续运行。
CAP定理指出,必须牺牲三个属性中的一个来支持三个属性中的两个如figure6-1所示。
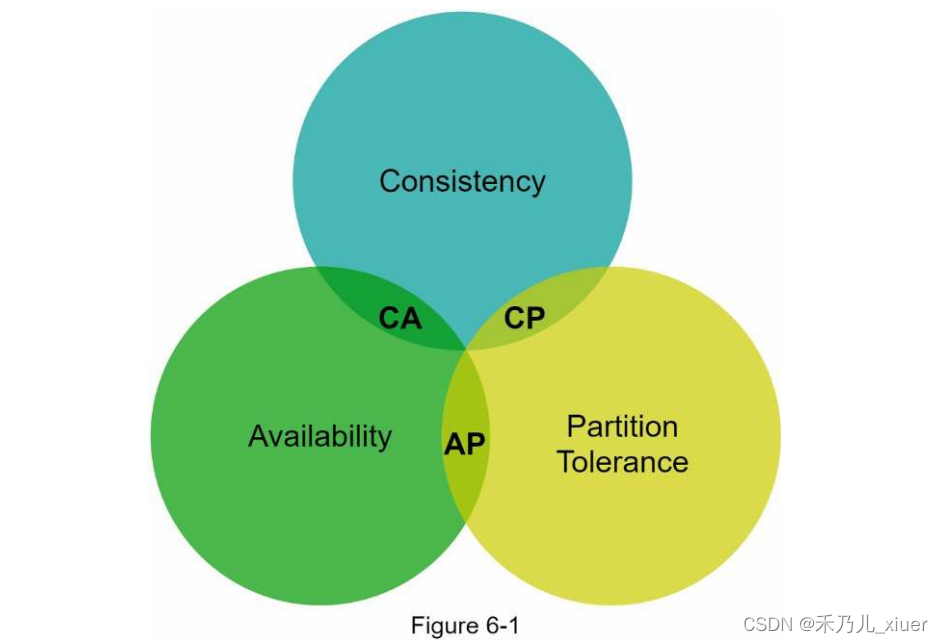
现在,键值存储是根据它们支持的两个CAP特征进行分类的:
CP(一致性和分区容忍)系统:支持CP键值存储一致性和分区容忍度,同时牺牲可用性。
AP(可用性和分区容忍度)系统:支持AP键值存储可用性和分区容忍度,同时牺牲一致性。
CA(一致性和可用性)系统:CA键值存储支持一致性和可用性可用性,同时牺牲分区容忍度。由于网络故障是不可避免的分布式系统必须容忍网络分区。因此,CA系统不能存在于真实的世界应用程序中。
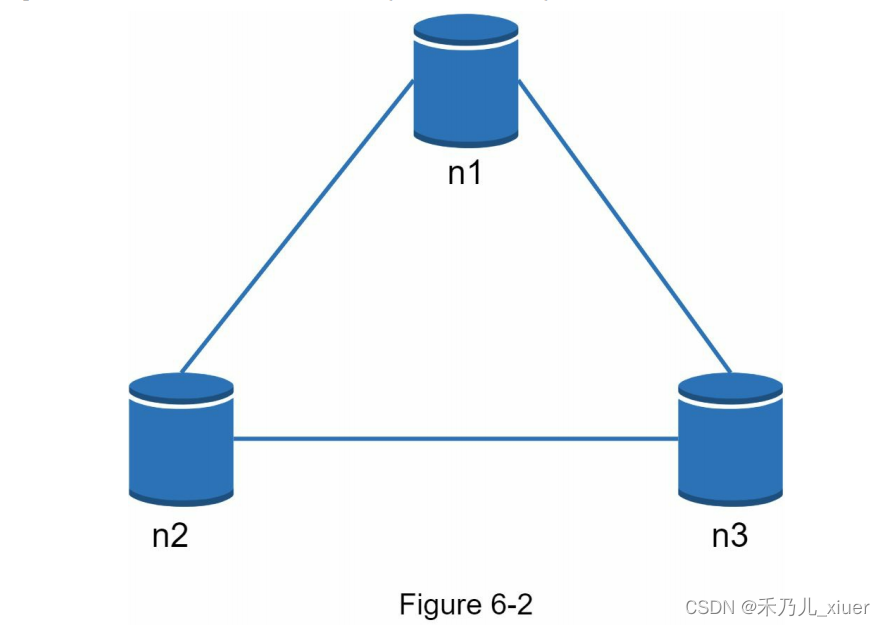
你在上面读到的大部分是定义部分。为了更容易理解,让我们用看一些具体的例子。在分布式系统中,数据通常被多次复制次了。假设在三个复制节点n1、n2和n3上复制数据,如figure6-2所示
理想的情况下
在理想情况下,永远不会发生网络分区。数据自动写入n1复制到n2和n3。一致性和可用性都得到了实现。
真实的分布式系统
在分布式系统中,分区是无法避免的,当分区发生时,我们必须避免在一致性和可用性之间进行选择。在figure6-3中,n3下电,无法与n1和n2通信。如果客户端写数据到n1或n2,数据将无法传播到n3。如果数据被写入n3,但还没有传播到n1和n2, n1和n2就会存储一些过时数据。
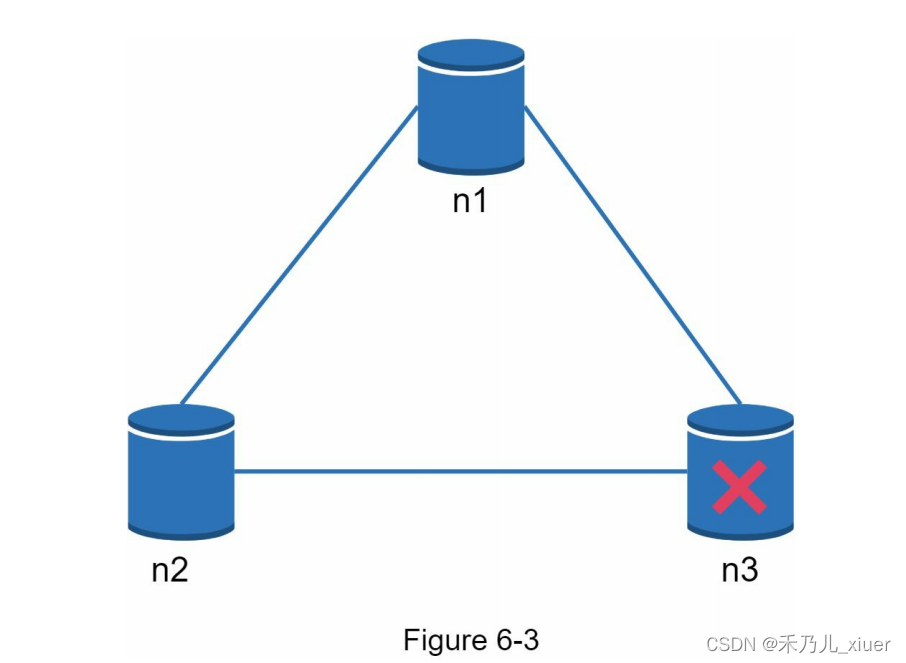
如果我们选择一致性而不是可用性(CP系统),我们必须阻塞n1和n2的所有写操作,以避免三台服务器之间的数据不一致,从而使系统不可用。银行系统通常具有极高的一致性要求。
例如,银行系统显示最新的余额信息是至关重要的。如果由于网络分区出现不一致,银行系统在此之前返回一个错误解决了不一致。
如果我们选择可用性而不是一致性(AP系统),系统将继续接受读取,即使它可能返回过时的数据。对于写,n1和n2将继续接受写,当网络分区被解析后,数据将同步到n3。选择适合您的用例的正确的CAP保证是构建web应用程序的重要步骤分布式键值存储。你可以和你的面试官讨论并设计这个系统相应的行动。
系统组件
在本节中,我们将讨论用于构建web服务的以下核心组件和技术键值存储:
- 数据分区
- 数据复制
- 一致性
- 不一致解决
- 故障处理
- 系统架构图
- 写路径
- 读路径
下面的内容主要基于三个流行的键值存储系统:Dynamo b[4],Cassandra [6], BigTable[6]。
数据分区
对于大型应用程序,在单个服务器中容纳完整的数据集是不可行的。实现这一点的最简单方法是将数据分割成更小的分区并存储在其中多个服务器。在对数据进行分区时存在两个挑战:
- 将数据均匀地分布在多个服务器上。
- 在增加或删除节点时尽量减少数据移动。
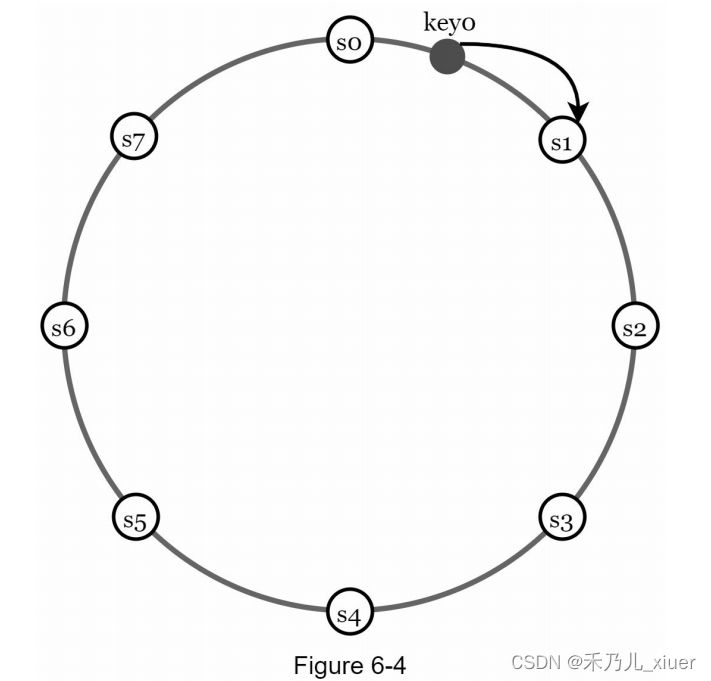
在第5章中讨论的一致性哈希是解决这些问题的一个很好的技术。让我们回顾一下一致性哈希在高层次上是如何工作的。 - 首先,服务器被放置在哈希环上。在figure6-4中,有8台服务器,用s0表示。S1,…,s7放在哈希环上。
- 接下来,将密钥散列到同一个环上,并将其存储在遇到的第一个服务器上同时顺时针方向移动。例如,key0使用这种逻辑存储在s1中。
使用一致性哈希对数据进行分区有以下优点:
自动扩展:服务器可以自动添加和删除取决于负载。
异构:服务器的虚拟节点数量与服务器容量成正比。例如,容量越大的服务器被分配的虚拟节点越多。
数据复制
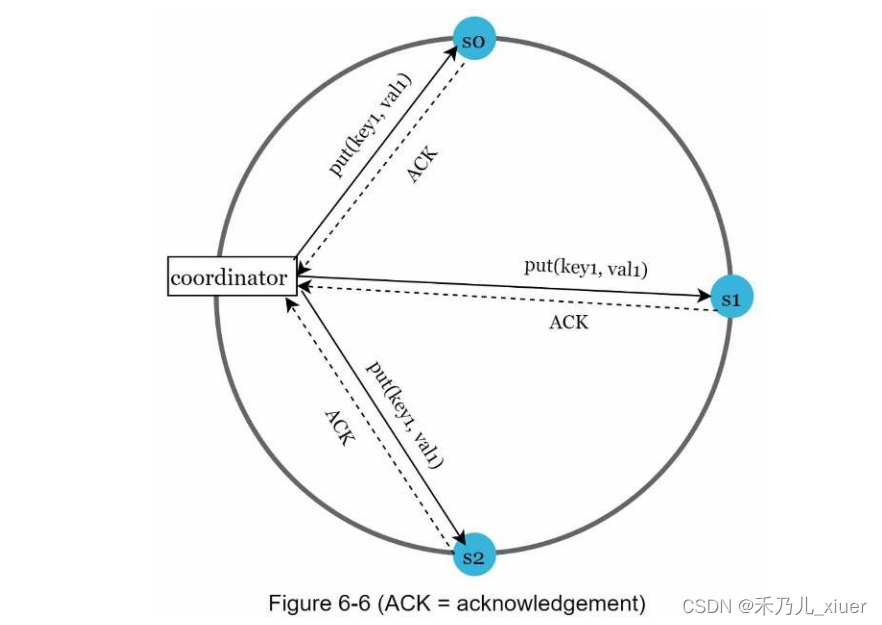
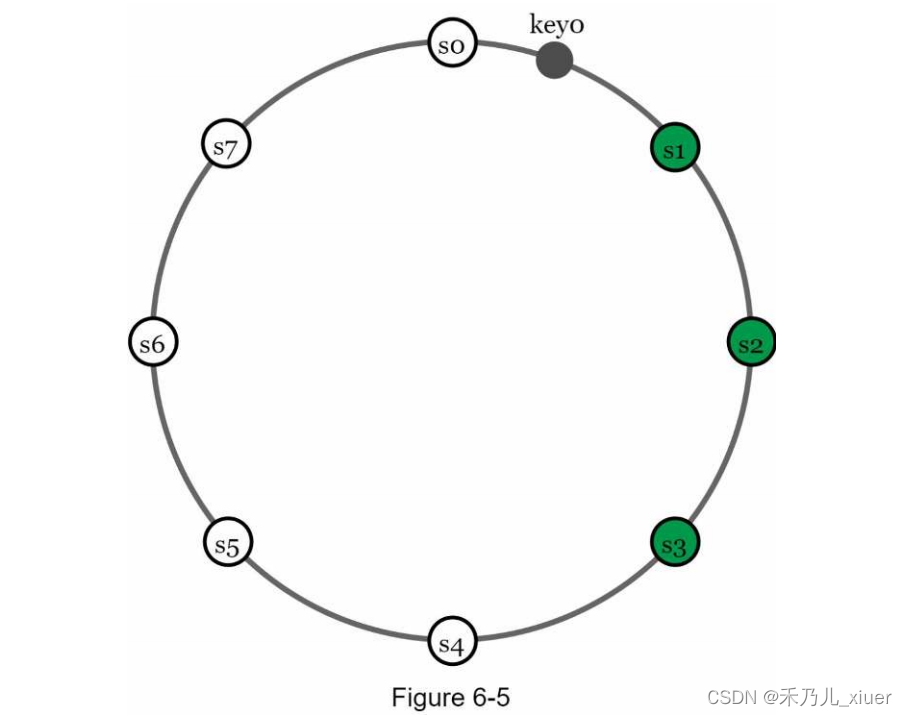
为了实现高可用性和可靠性,数据必须在N上异步复制服务器,其中N是一个可配置参数。使用以下方法选择这N个服务器逻辑:将键映射到哈希环上的某个位置后,从该位置顺时针走并选择环上的前N个服务器来存储数据副本。figure6-5 (N = 3)中,key0为在s1、s2和s3处复制。
对于虚拟节点,环上的前N个节点可能由少于N个物理节点拥有服务器。为了避免这个问题,我们在执行顺时针操作时只选择唯一的服务器逻辑走。同一数据中心内的节点经常由于断电、网络等原因同时发生故障
问题,自然灾害等。为了提高可靠性,副本被放置在不同的数据中心,数据中心通过高速网络连接。
一致性
由于数据是在多个节点上复制的,因此必须跨多个副本同步数据。法定人数一致性可以保证读和写操作的一致性。让我们建立一个首先是一些定义。
N =副本的数量
W =大小为W的写副本。要认为一个写操作成功,需要写操作必须从W个副本中得到确认。
R =大小为R的读仲裁。要认为读操作成功,则读取操作必须等待至少R个副本的响应。
考虑如下figure6-6中N = 3的例子