机器学习实战:Python基于PCA主成分分析进行降维分类(七)

文章目录
1 前言
1.1 主成分分析的介绍
主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维技术,通过线性变换将高维数据映射到低维空间中。其原理是寻找最能代表原始数据的几个主成分,并保留大部分的数据方差。
PCA的目的是通过线性变换将原始数据转化为一组新的变量,这些新变量是原始变量的线性组合,且互相独立。这些新变量称为主成分,第一个主成分方差最大,第二个主成分方差次大,以此类推。通过PCA,我们可以将高维数据转化为低维数据,从而实现数据的降维处理。
优点:
-
数据降维:PCA可以将高维数据转化为低维数据,从而减少了数据的维度,使得数据更容易分析和处理。
-
特征提取:PCA可以提取出数据的主要特征,抛弃噪声和冗余信息,从而提高了数据的准确性。
-
数据可视化:PCA可以将高维数据映射到低维空间,从而使得数据可以被可视化。
-
计算简单:PCA的计算简单,可以应用于大规模数据处理。
缺点:
-
可能信息损失:PCA通过抛弃一部分信息实现降维,可能会损失一些重要信息。
-
主成分解释难度:PCA得到的主成分是原始变量的线性组合,其含义不一定很明确,可能需要更深入的领域知识才能解释。
-
敏感度:PCA对数据的分布比较敏感,当数据的分布不是正态分布时,可能会得到不理想的结果。
-
计算复杂度:在处理大规模数据时,PCA的计算复杂度可能会很高。
1.2 主成分分析的应用
-
金融分析:PCA被广泛应用于股票组合优化、风险管理等方面。通过PCA分析股票之间的相关性,可以得到一些具有代表性的因子,从而构建有效的股票组合。
-
图像处理:在图像处理领域,PCA可以应用于人脸识别、图像压缩等方面。通过PCA分析图像数据的主成分,可以得到图像的主要特征,从而实现图像压缩和特征提取等功能。
-
生物信息学:在生物信息学领域,PCA可以应用于基因表达分析、蛋白质结构分析等方面。通过PCA分析基因表达数据的主成分,可以发现基因表达的规律和特征,从而进一步研究基因的功能和调控机制。
-
信号处理:在信号处理领域,PCA可以应用于语音信号处理、图像噪声处理等方面。通过PCA分析信号数据的主成分,可以减少信号中的噪声和冗余信息,从而提高信号的质量和准确性。
-
模式识别:在模式识别领域,PCA可以应用于手写数字识别、语音识别等方面。通过PCA分析数据的主成分,可以提取数据的主要特征,从而实现数据分类和识别等功能。
2 Mushroom分类数据演示
2.1 导入函数
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings("ignore")
2.2 导入数据
下载数据网址:https://www.kaggle.com/datasets/uciml/mushroom-classification?resource=download&select=mushrooms.csv,直接download即可
m_data = pd.read_csv('mushrooms.csv')# 转换ints
encoder = LabelEncoder()
# 应用到所有列
for col in m_data.columns:m_data[col] = encoder.fit_transform(m_data[col])X_features = m_data.iloc[:,1:23]
y_label = m_data.iloc[:, 0]
(可选)缩放数据:
scaler = StandardScaler()
X_features = scaler.fit_transform(X_features)
2.3 PCA可视化
pca = PCA()
pca.fit_transform(X_features)
pca_variance = pca.explained_variance_plt.figure(figsize=(8, 6))
plt.bar(range(22), pca_variance, alpha=0.5, align='center', label='individual variance')
plt.legend()
plt.ylabel('Variance ratio')
plt.xlabel('Principal components')
plt.show()
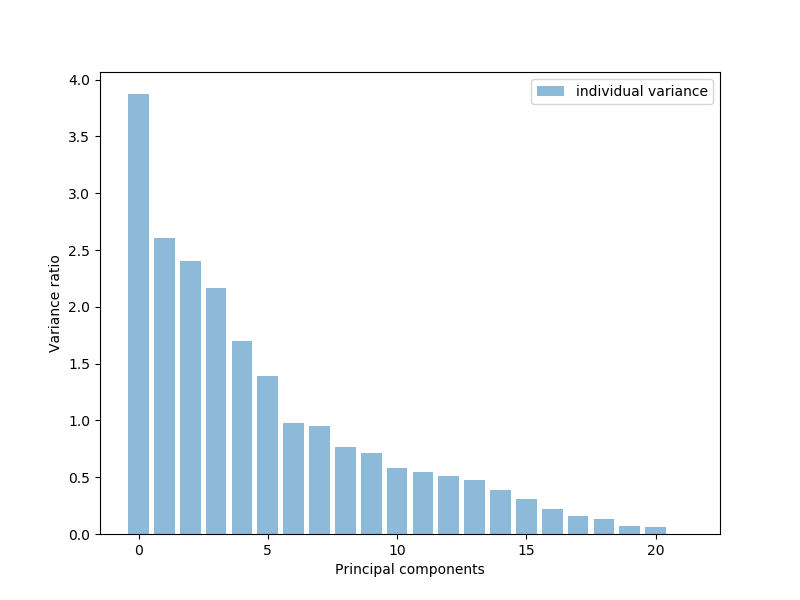
挑选特征性最强的或者方差最大的,依图可见大概是17或18个特征可解释涵盖大部分,几乎95%
2.4 PCA散点图
pca2 = PCA(n_components=18)
pca2.fit(X_features)
x_3d = pca2.transform(X_features)plt.figure(figsize=(8,6))
plt.scatter(x_3d[:,0], x_3d[:,5], c=m_data['class'])
plt.show()

这里根据前18个特征绘制散点图
2.5 PCA散点图
pca3 = PCA(n_components=2)
pca3.fit(X_features)
x_3d = pca3.transform(X_features)plt.figure(figsize=(8,6))
plt.scatter(x_3d[:,0], x_3d[:,1], c=m_data['class'])
plt.show()
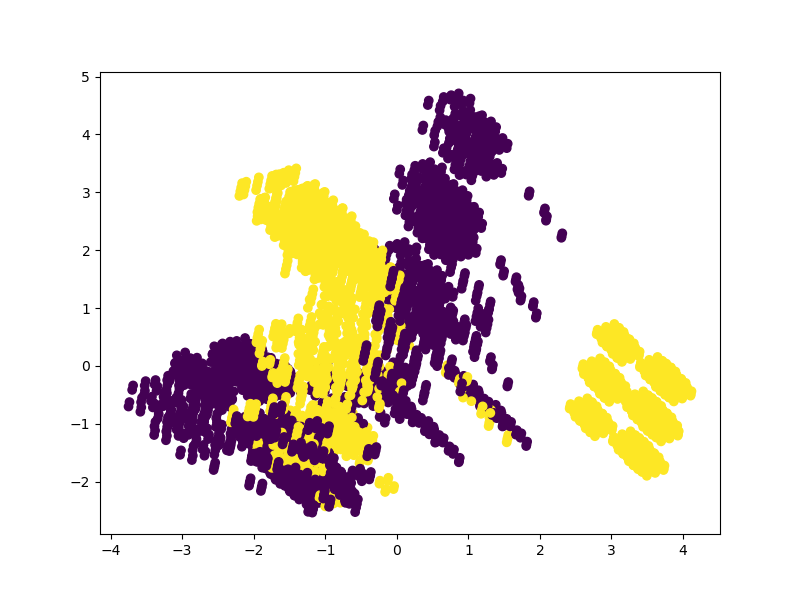
这里是根据前2个特征绘制散点图,可以发现中间部分并没有区分清晰,且右下角聚集的有点奇怪?降维结果显不如依18个特征进行降维的好。
3 讨论
作为一种常用的数据降维技术,主成分分析(PCA)具有很多优点,如降低维数、减少噪声、提高计算效率等。通过PCA分析数据的主要特征,可以实现数据的压缩和特征提取,从而简化数据处理流程和提高计算效率。然而,PCA也有其局限性,如对数据分布假设过于严格、对非线性关系的无法处理等。在实际应用中,需要根据具体问题选择合适的PCA方法和参数,以达到最佳效果。