浏览器自动化(一)
.jpg)
目录
介绍
下载地址
安装教程
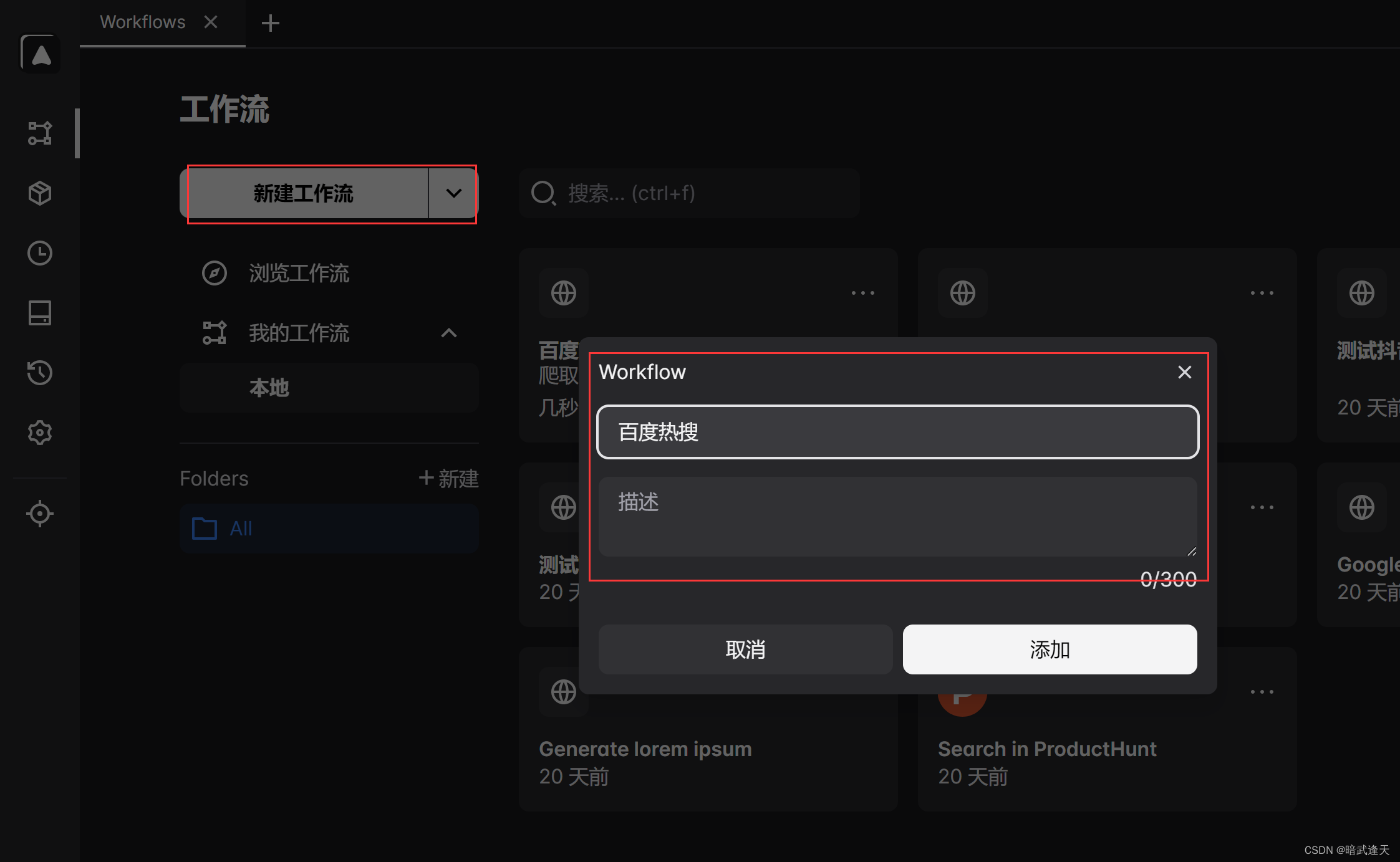
爬取百度热搜
介绍
Automa 是一个免费、开源的 Chrome 扩展,它通过目前流行的 No Code 无代码方式,只需要拖拽模块就实现了浏览器自动化,比如自动填写表格、执行重复性任务。
在工作中,如果我们遇到重复性工作,或者说是浏览器自动完成的一些操作,我们为了避免重复工作,就可以利用这个免费实用的工具帮我完成。
下载地址
链接:https://pan.baidu.com/s/1RYbmr6zgmQ52GwFZkWxTfA?pwd=ojem
提取码:ojem
安装教程
下载后是crx文件直接拖入浏览器的程序扩展页面即可
爬取百度热搜(循环数字)
这里进行一个百度热搜列表的简易爬取
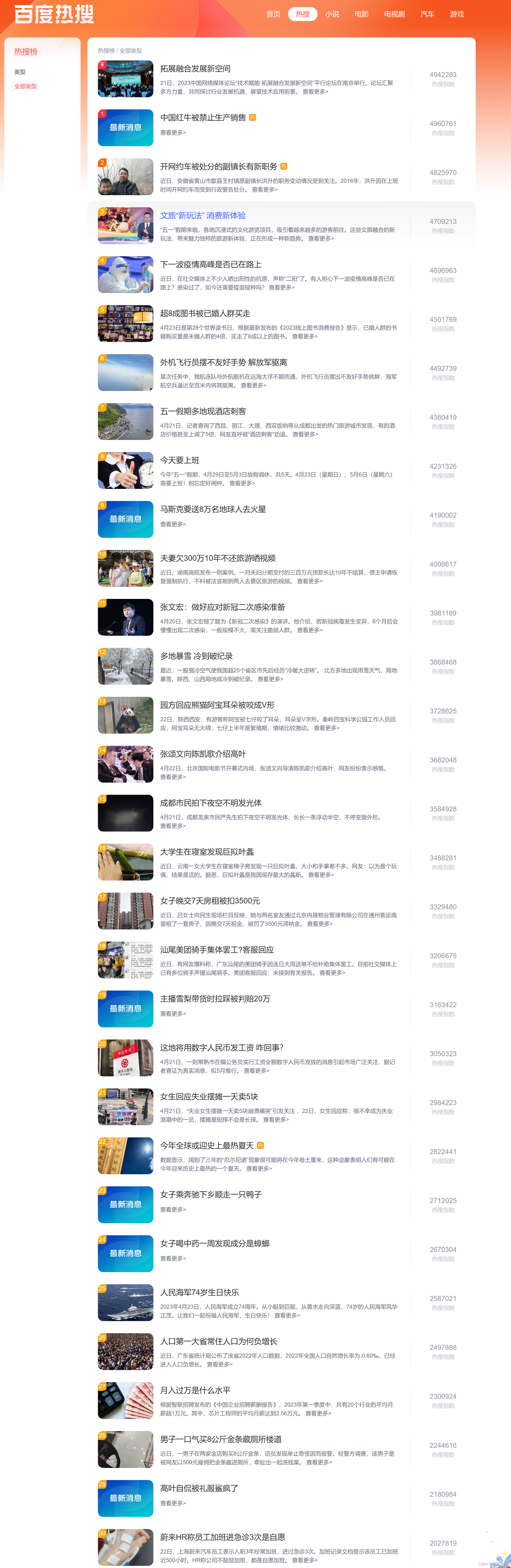
这个列表数据有30条数据,我们爬取列表数据里的标题,简介,以及右边的热搜指数数据
首先打开automa主页,直接在安装好的浏览器插件列表里点击automa
在主页添加新工作流
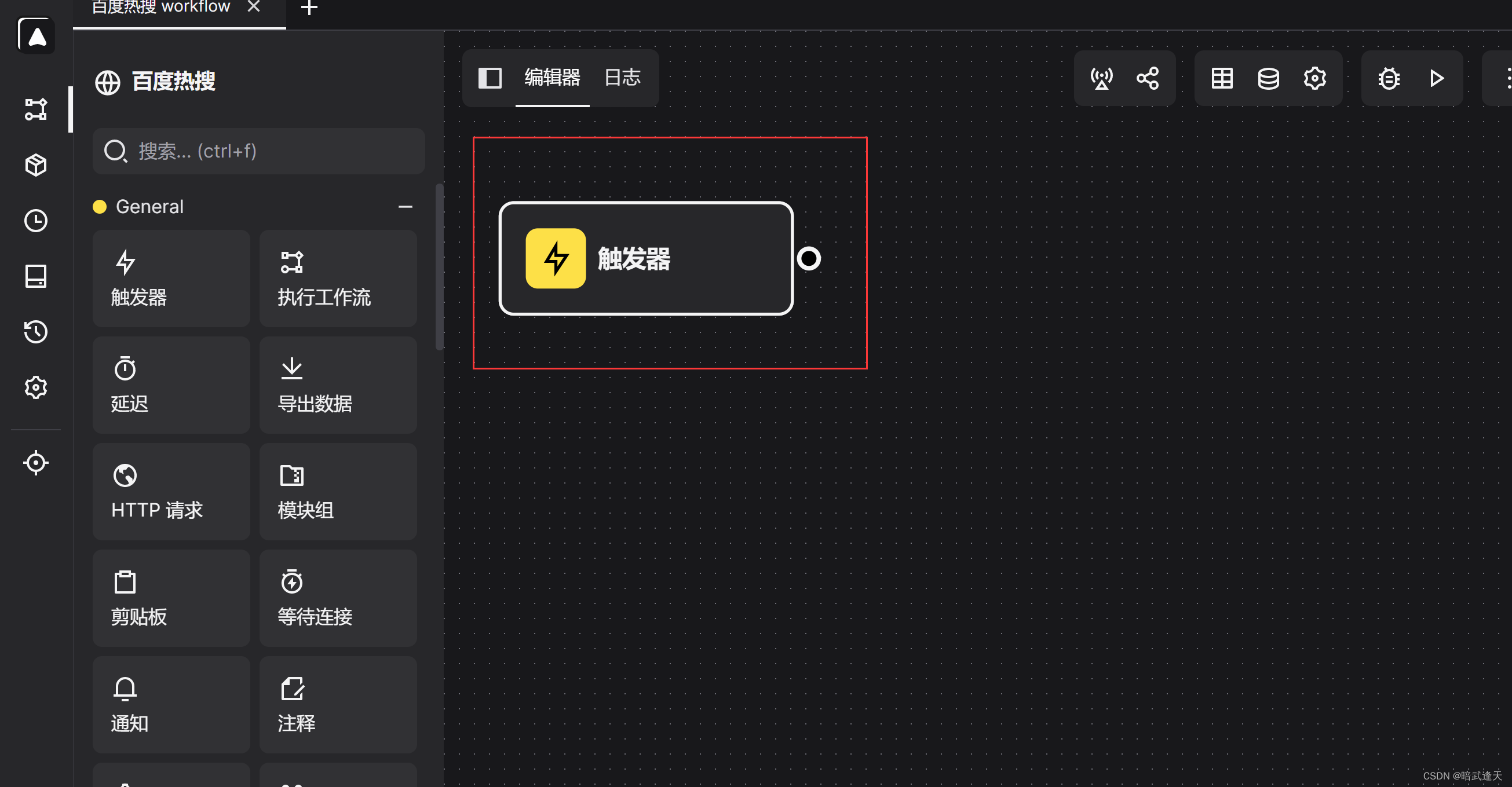
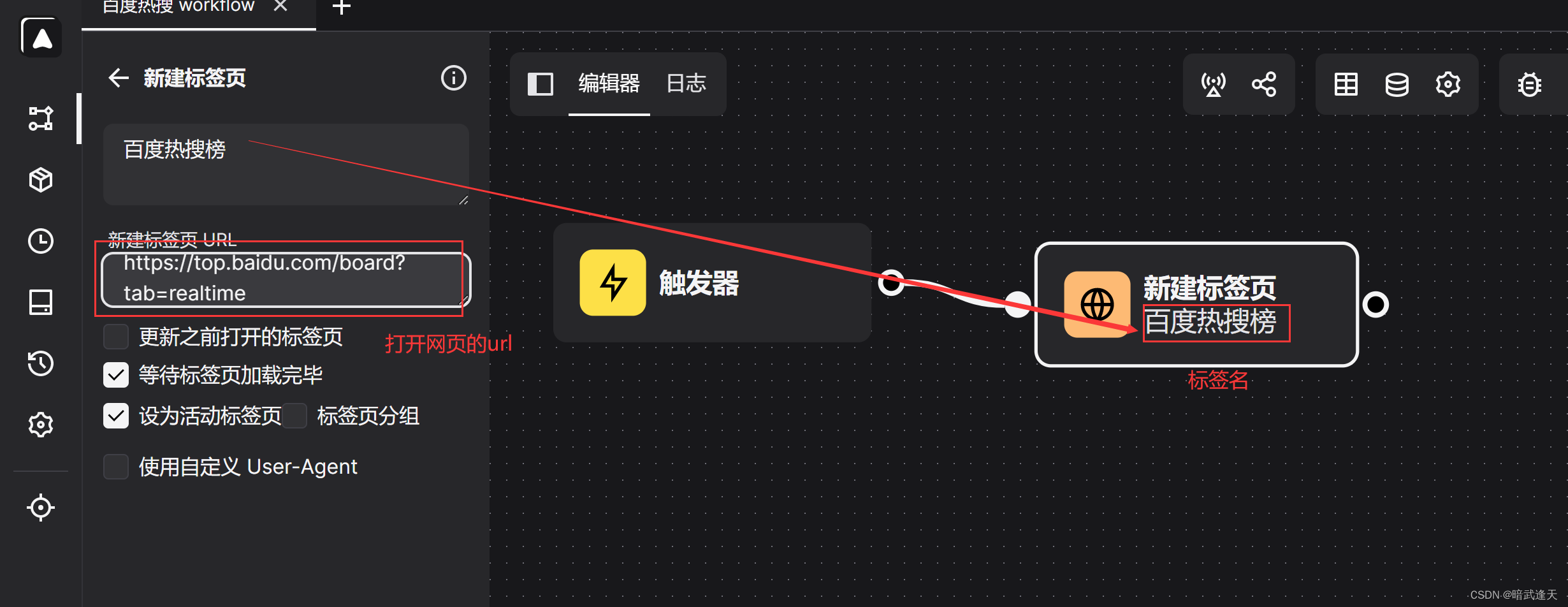
每个工作流都是需要触发器进行触发的,默认新建工作流后就会新建一个触发器
添加触发器打开的网页
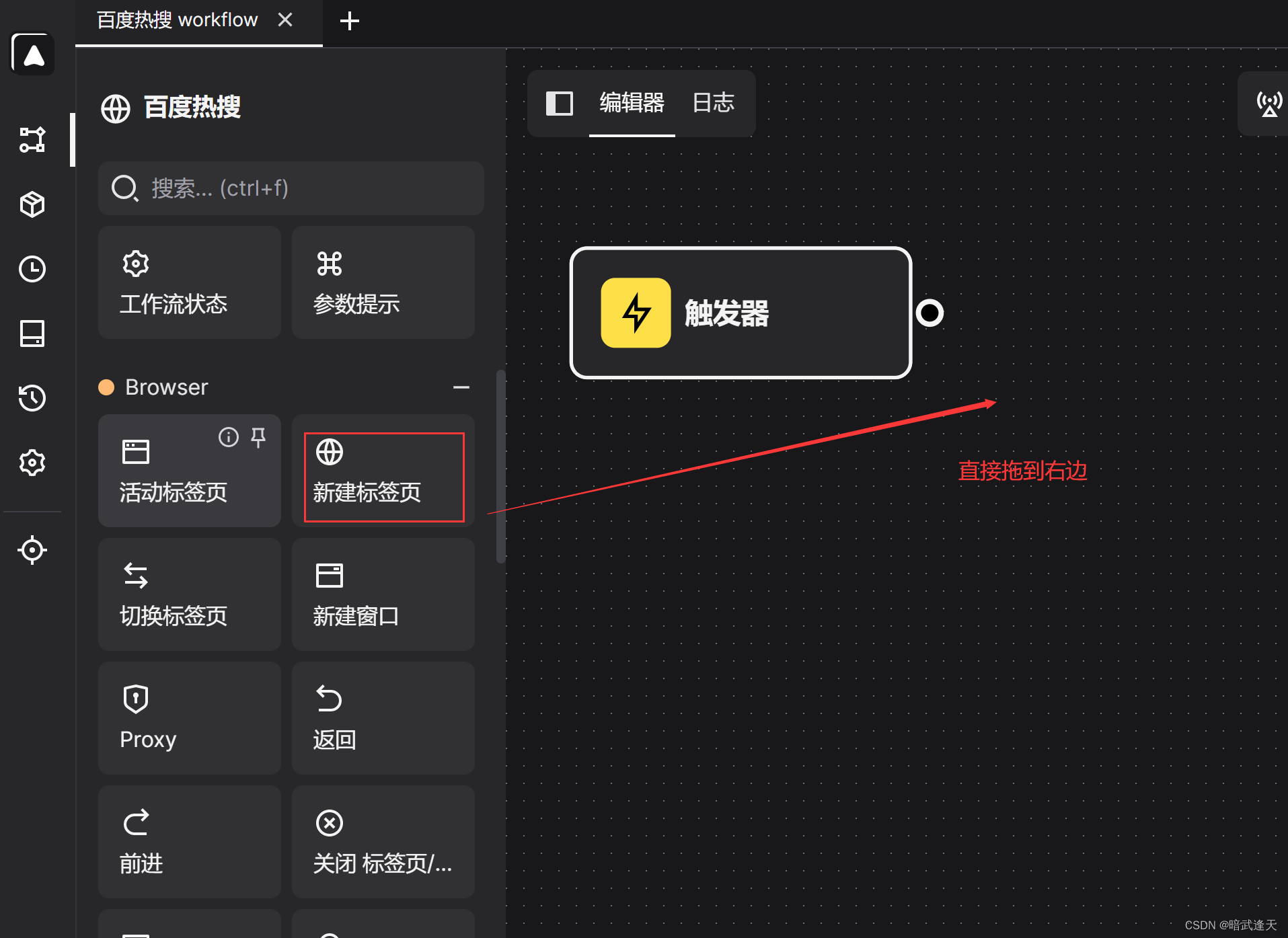
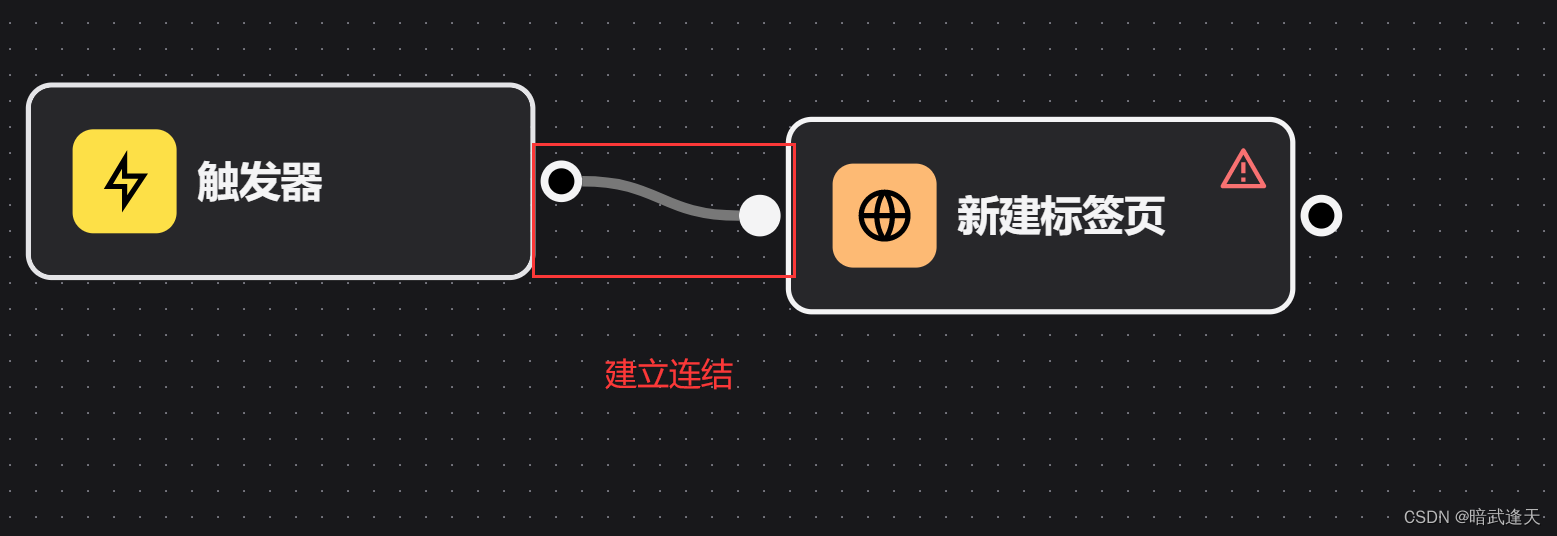
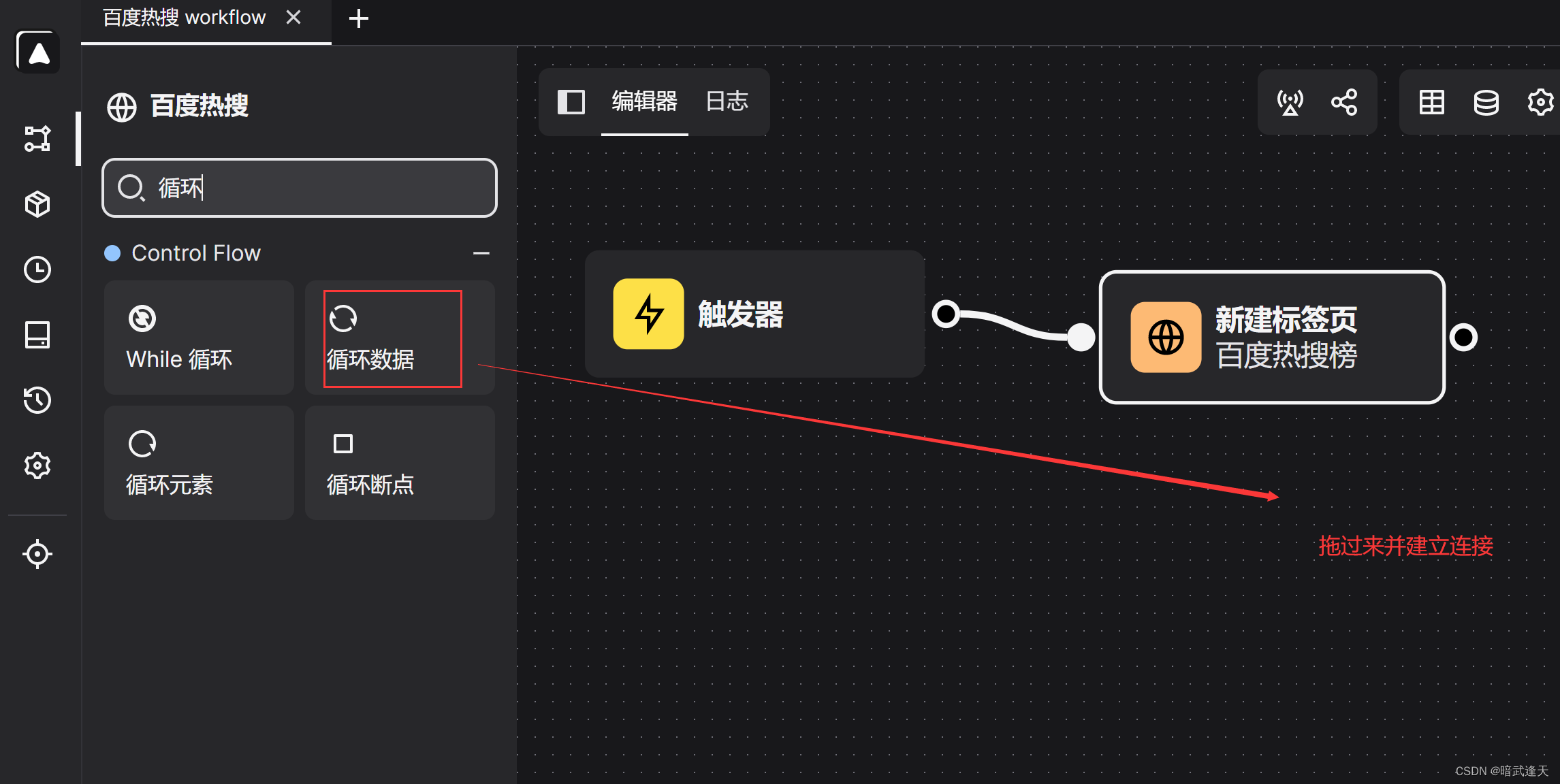
由于我们看到需要爬取的百度热搜榜是一个列表数据,这里我们就需要建立循环进行爬取
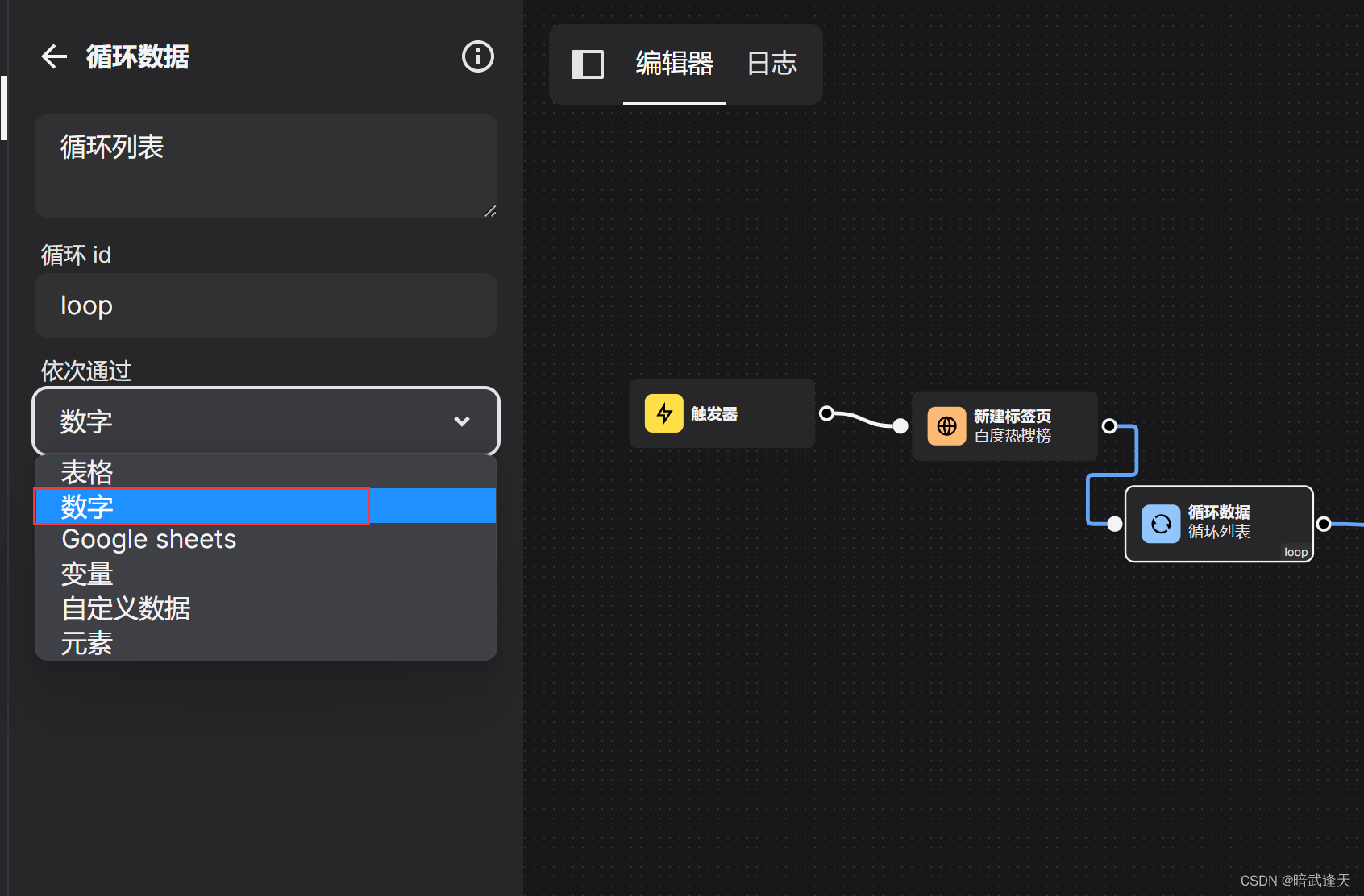
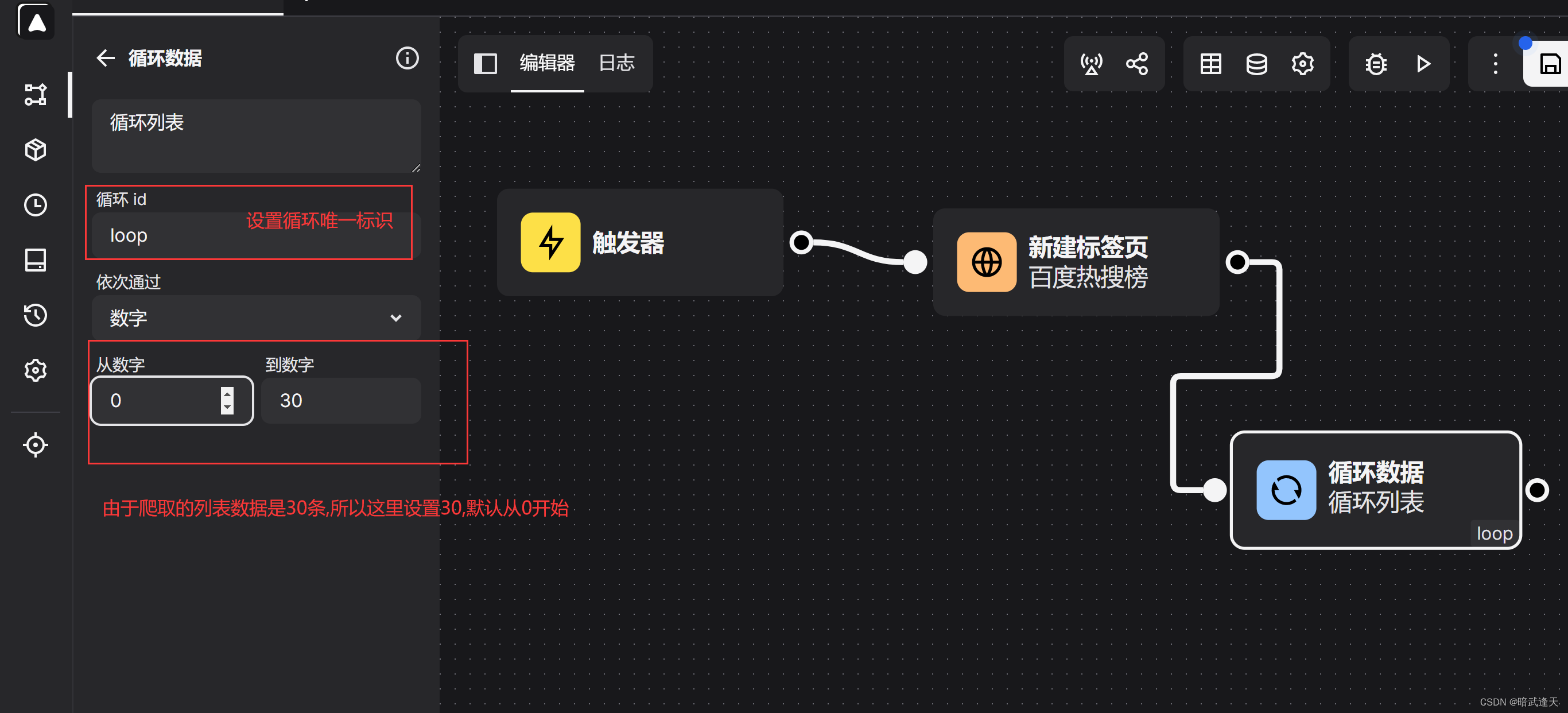
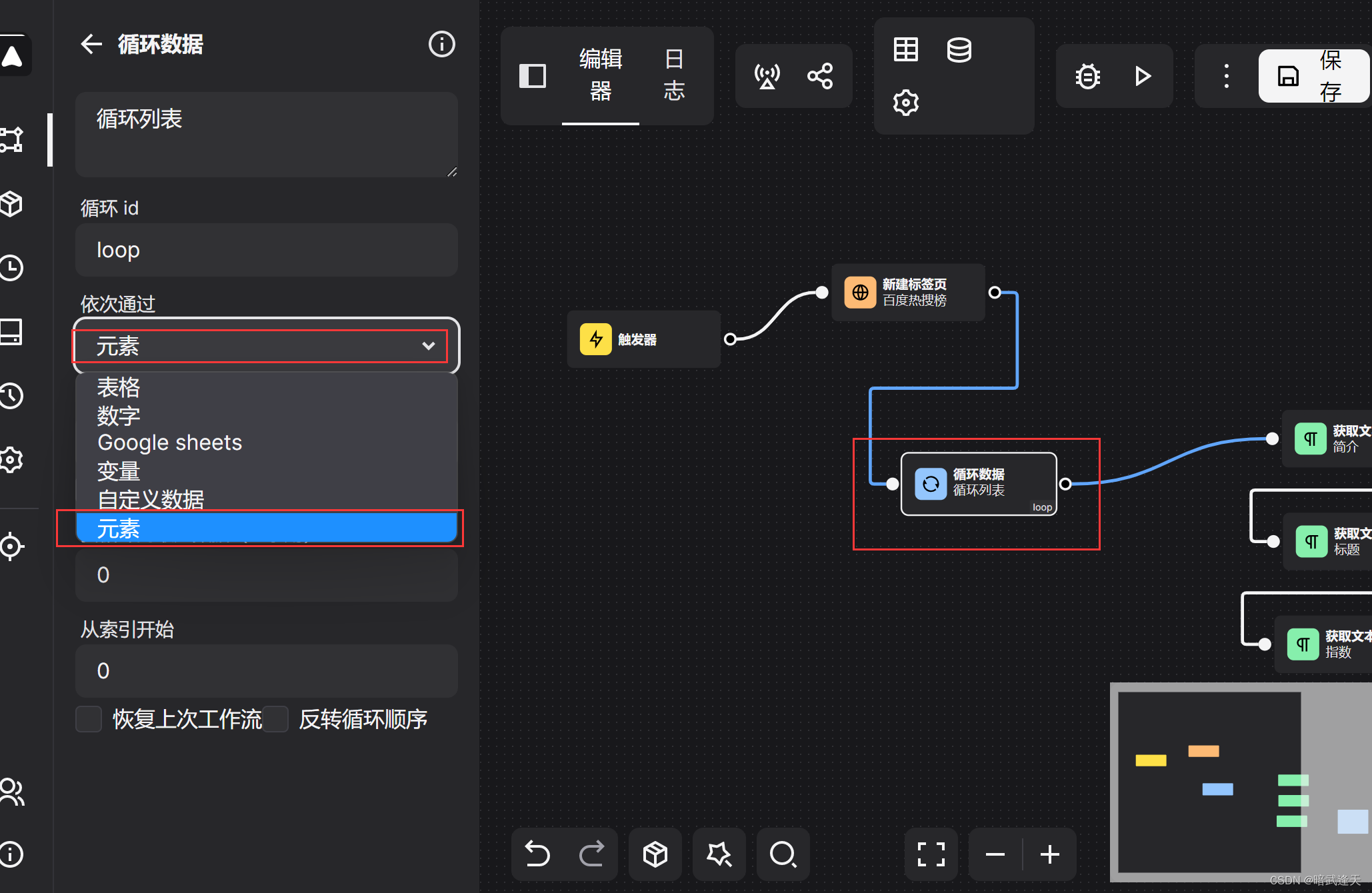
我们这里使用automa提供的loopData循环的数字循环形式
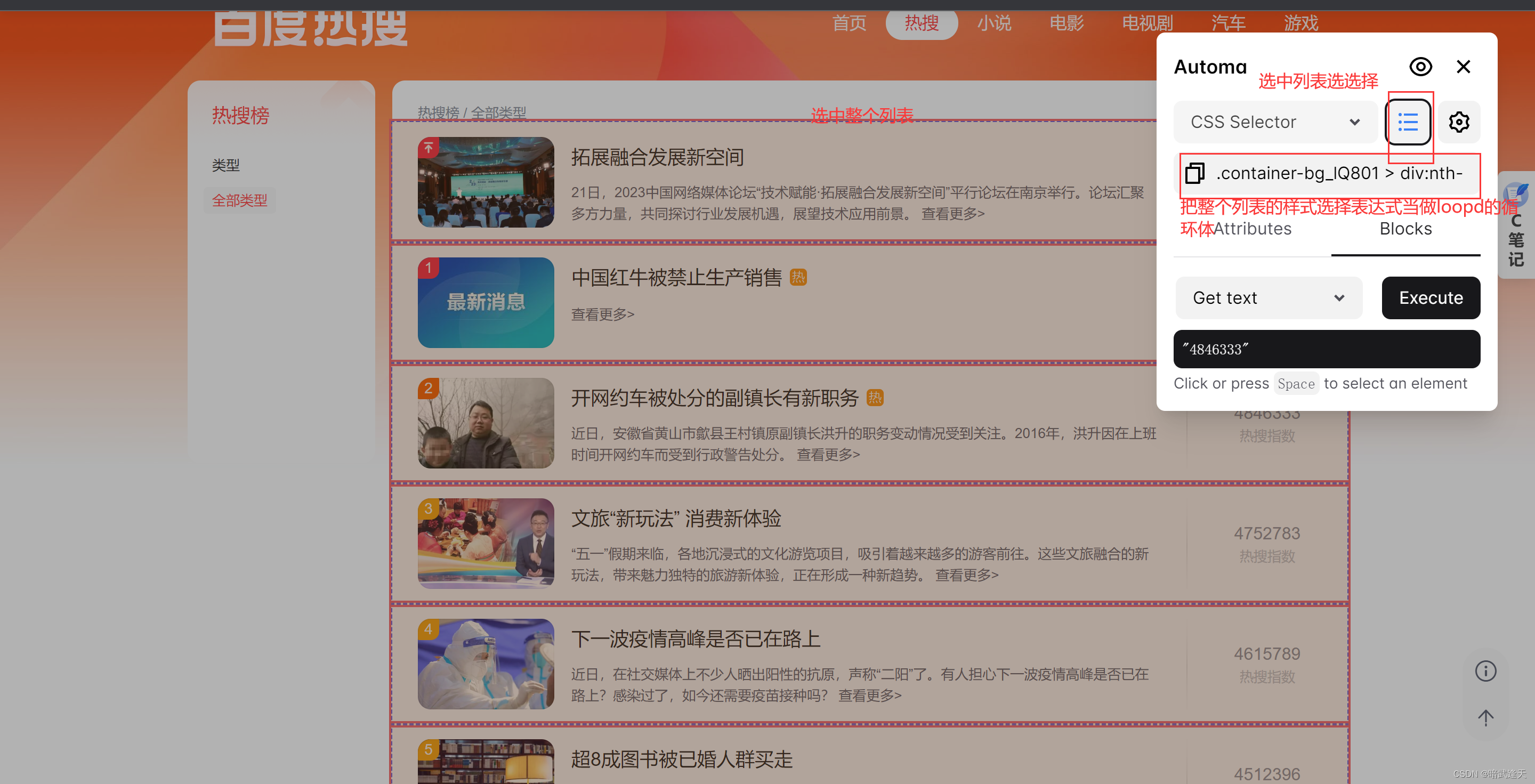
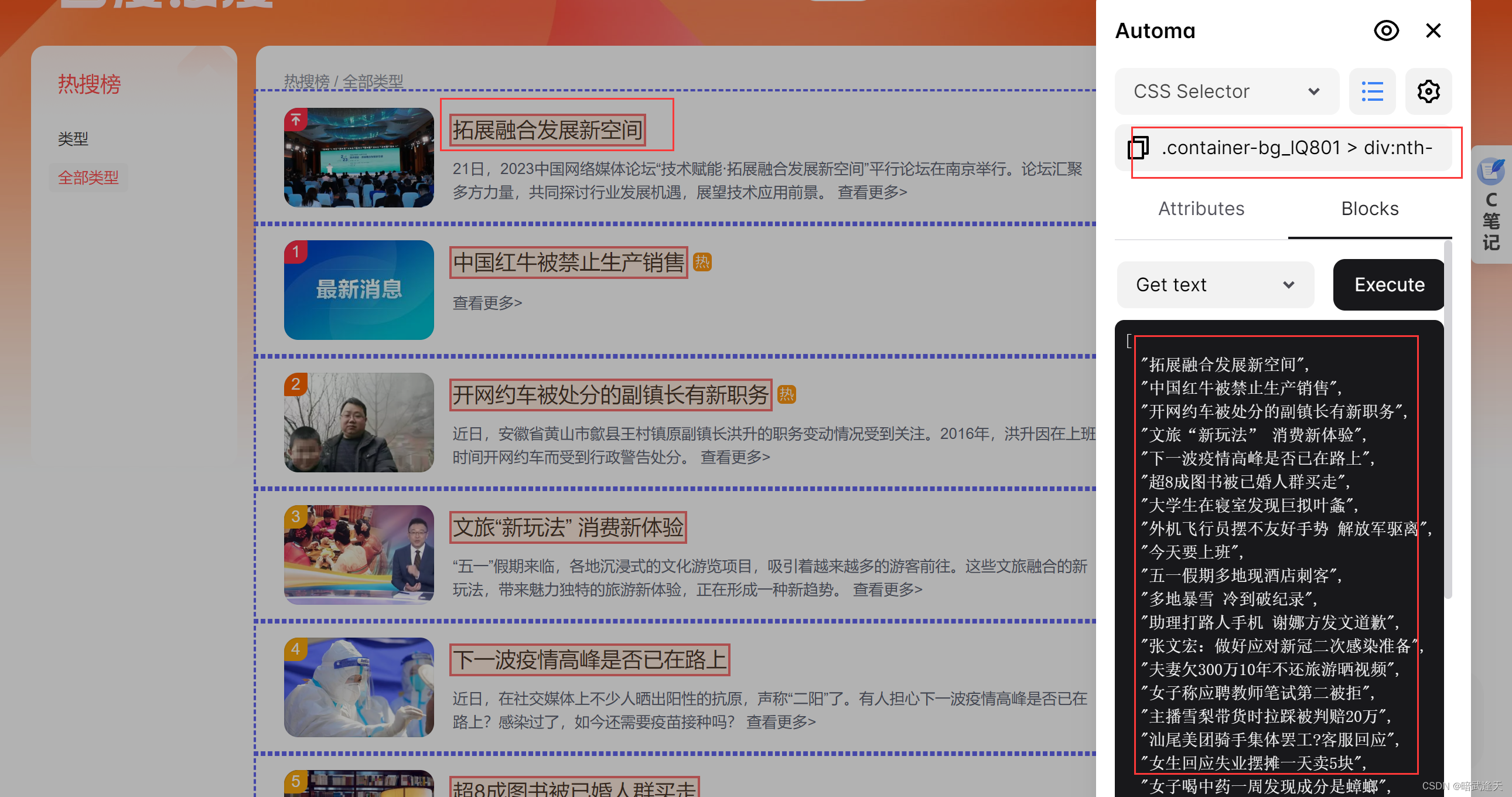
返回百度热搜页面,点击automa插件,选择元素选择器
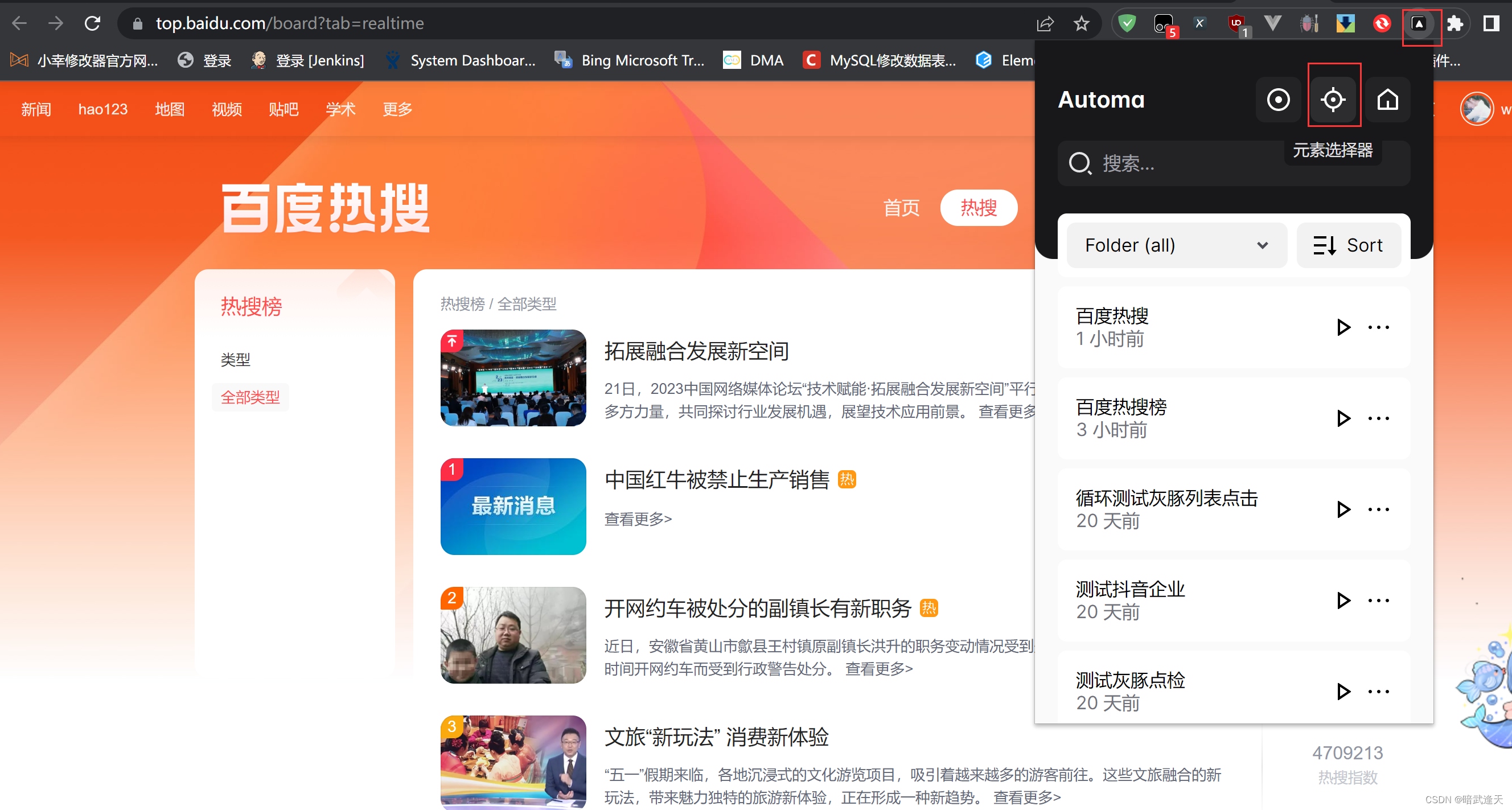
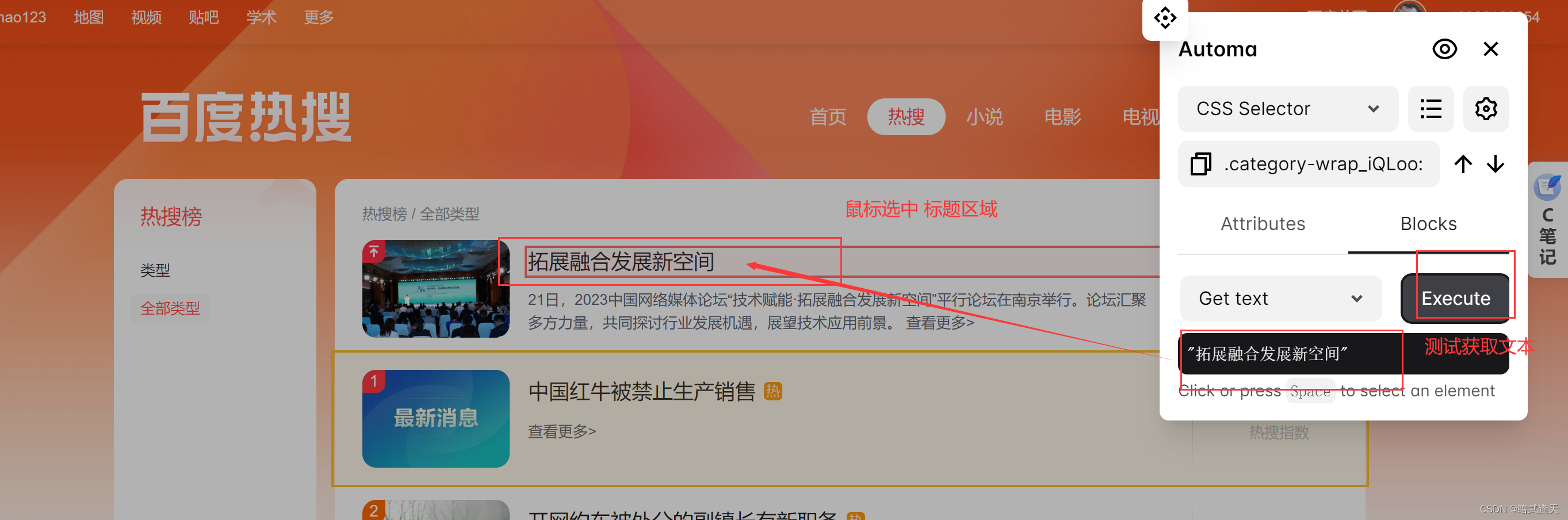
选中第一个标题,观察样式选择器
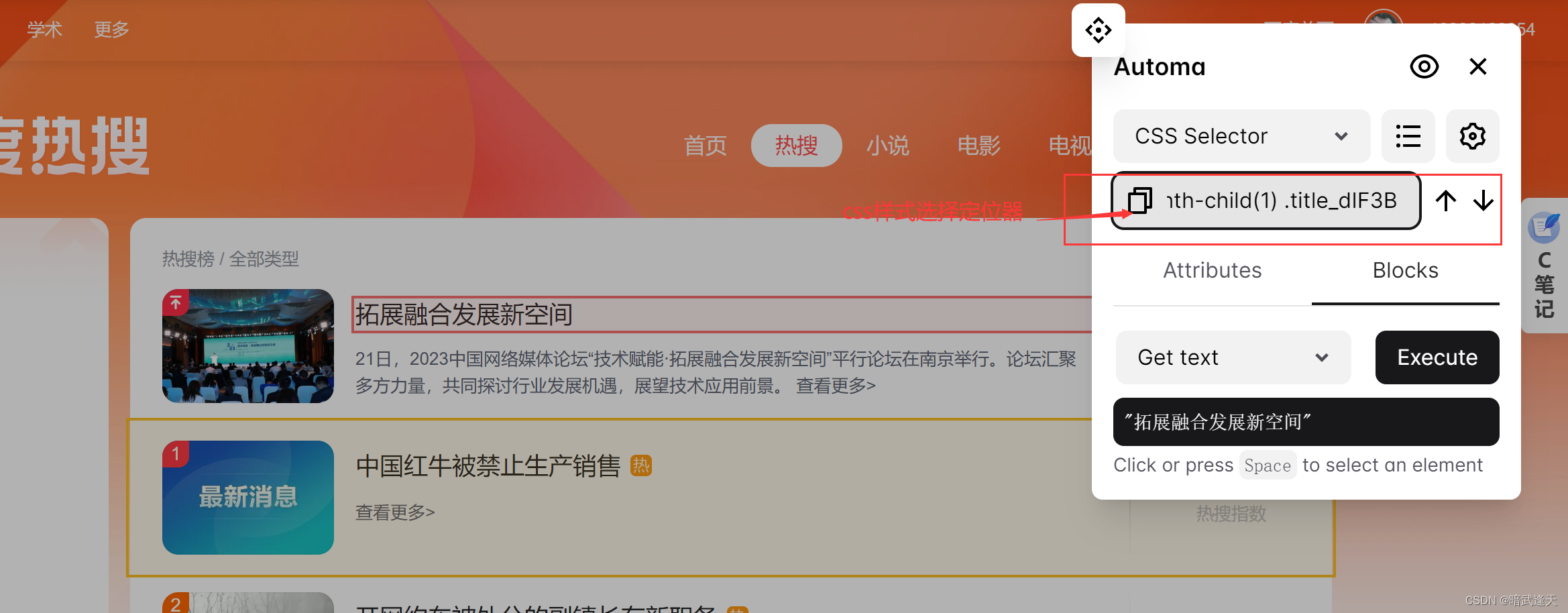
再选中第二个和第三个观察它们的样式选择器变化
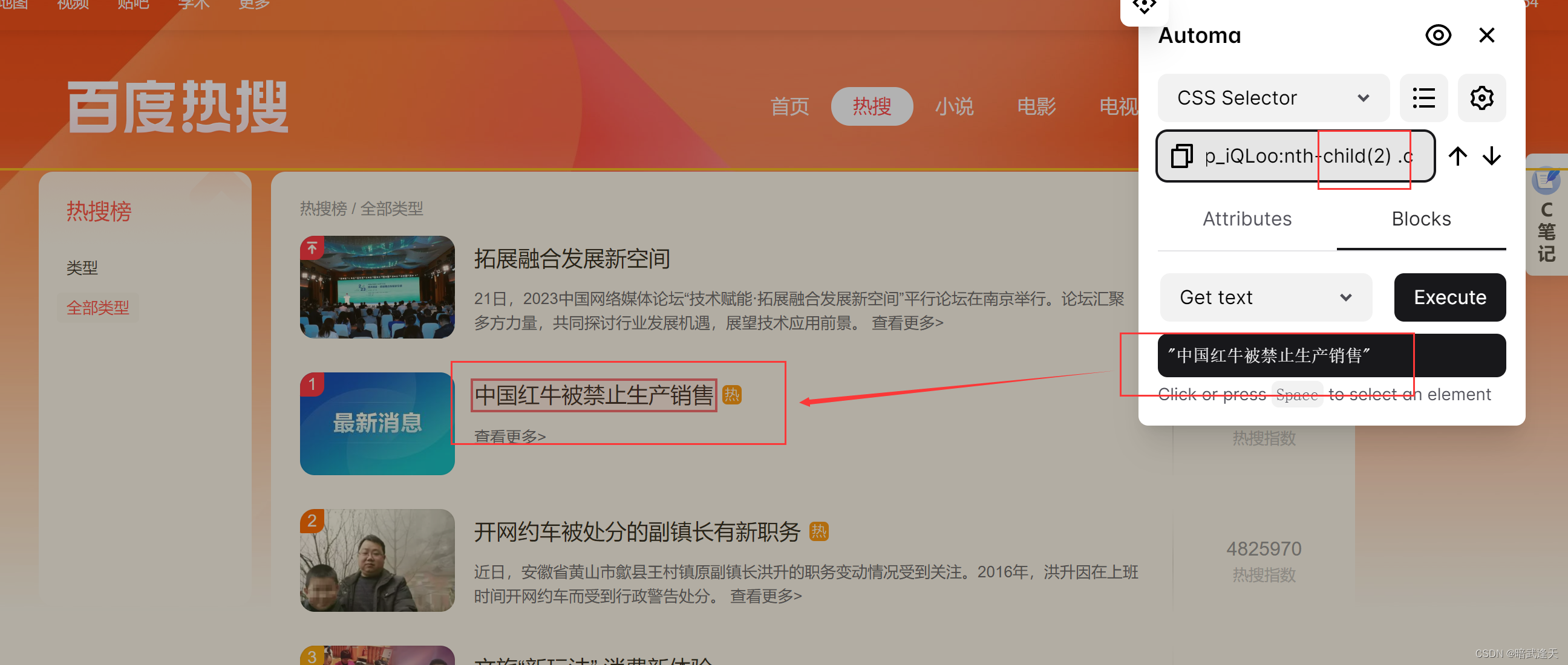
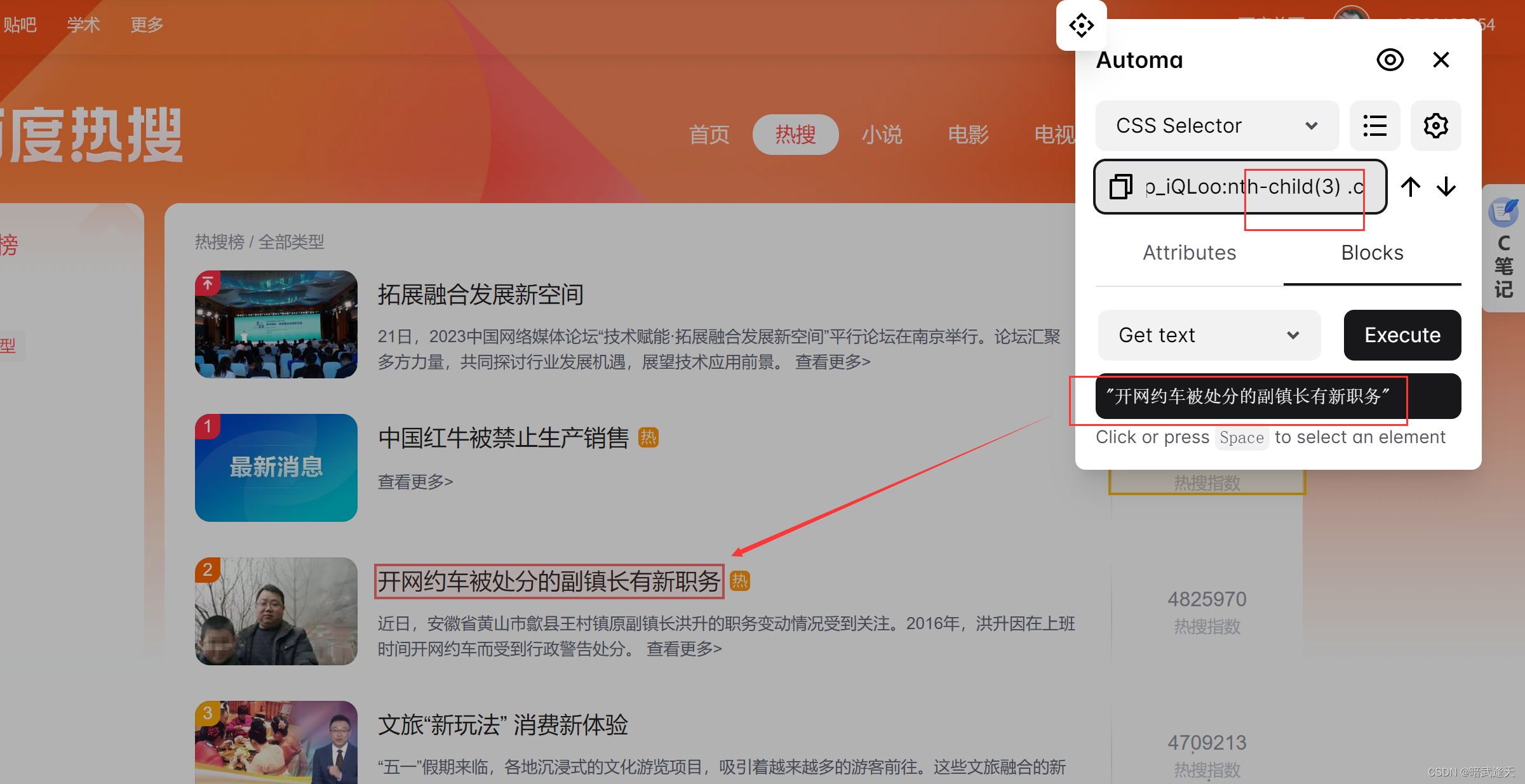
可以观察到,多个标题区域的样式选择器内容是一致的,只有child(数字)中的数字跟随列表行数的index进行变化递增,后面的标题选择也是一样的,有兴趣的可以自己试下,由此我们可以直接拿取这里的样式选择器,并想办法直接将child中的数字进行递增,就可以直接循环拿取整个页面的所有标题,简介,指数等
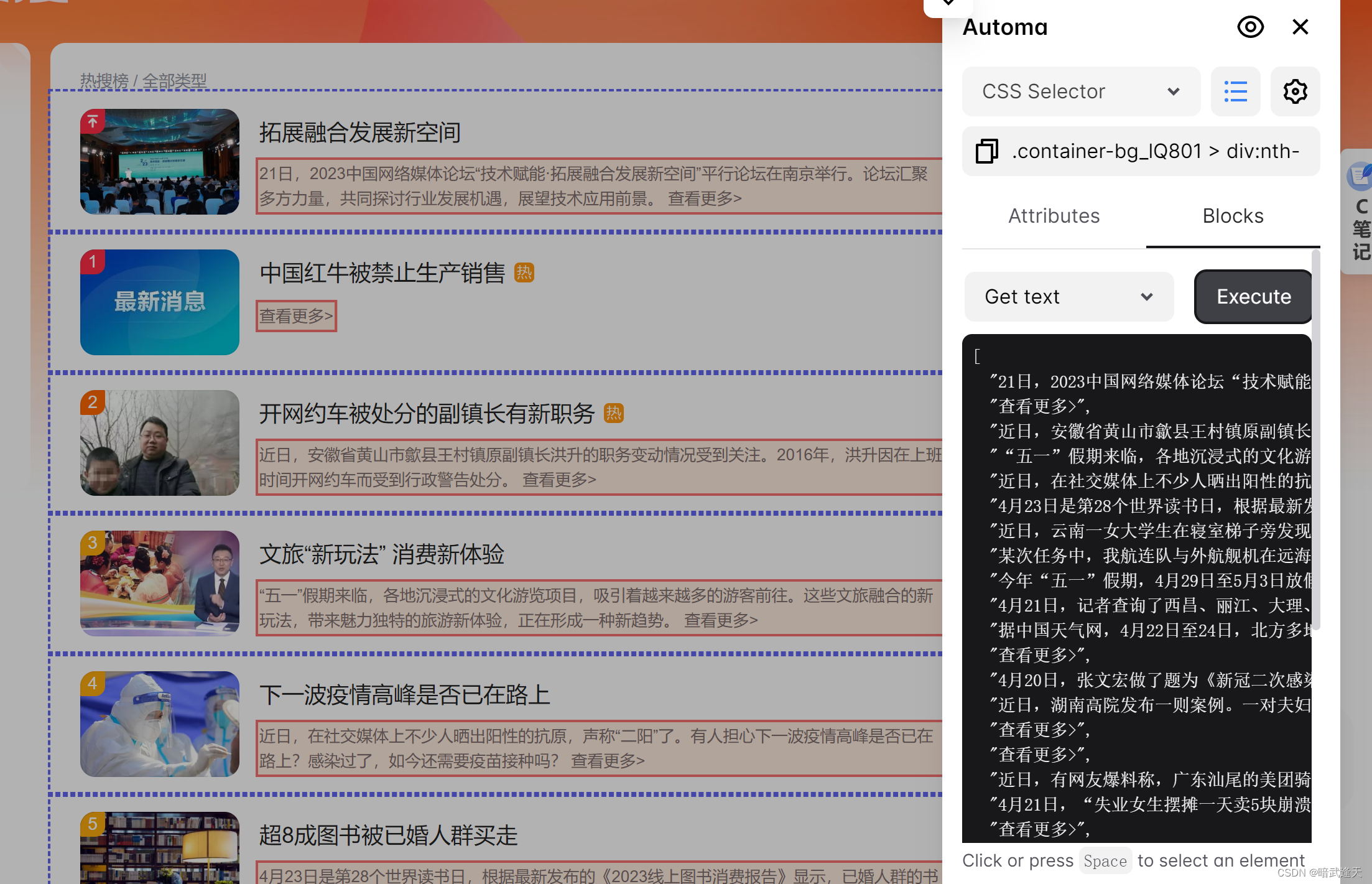
创建获取三个文本的标签
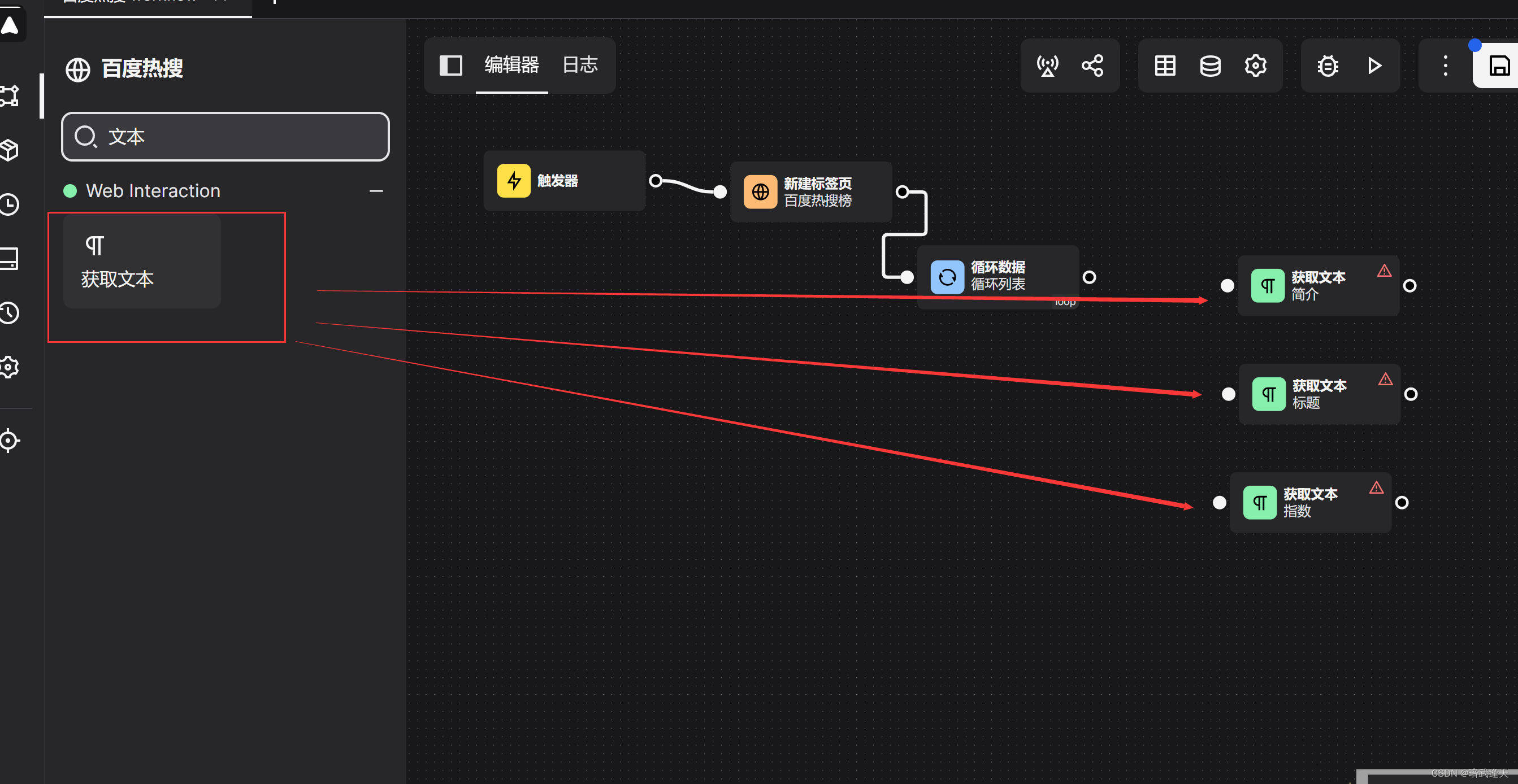
把刚才测试的标题的样式选择器,简介选择器,指数选择器等内容直接粘贴到相对应的标签里
简介和指数的以此类推
然后我们前面已经创建了loop循环标签,这里套用automa提供的循环参数
{{$increment([loopData.loop.$index],1)}}直接代替child()中的数字参数
注意格式 {{$increment([loopData.前面定义的loop循环唯一标识.$index],1)}}
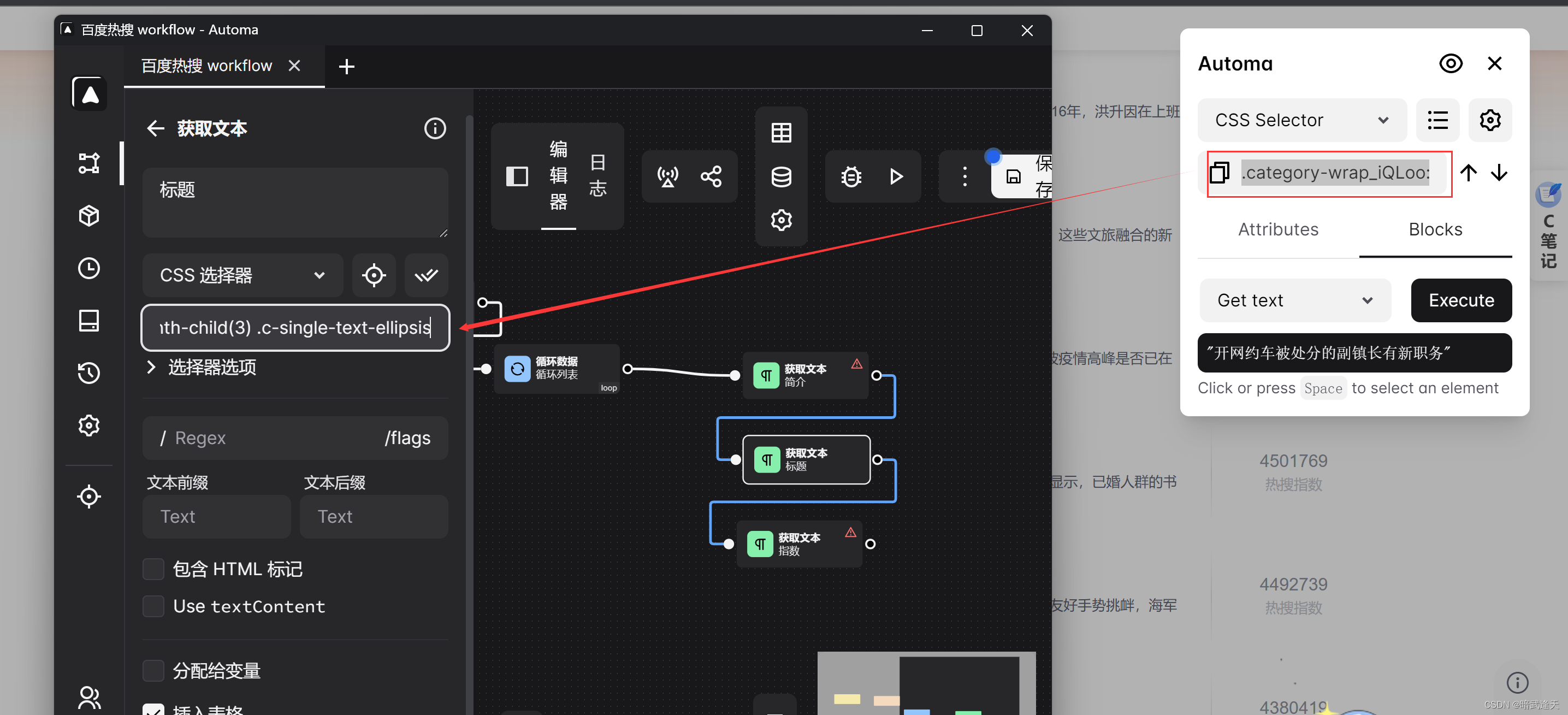
举例: 原样式选择器表达式 .category-wrap_iQLoo:nth-child(3) .c-single-text-ellipsis
替换后 .category-wrap_iQLoo:nth-child({{$increment([loopData.loop.$index],1)}}) .c-single-text-ellipsis
简介,标题,指数的样式选择器表达式都依次类推
最后定义循环结束
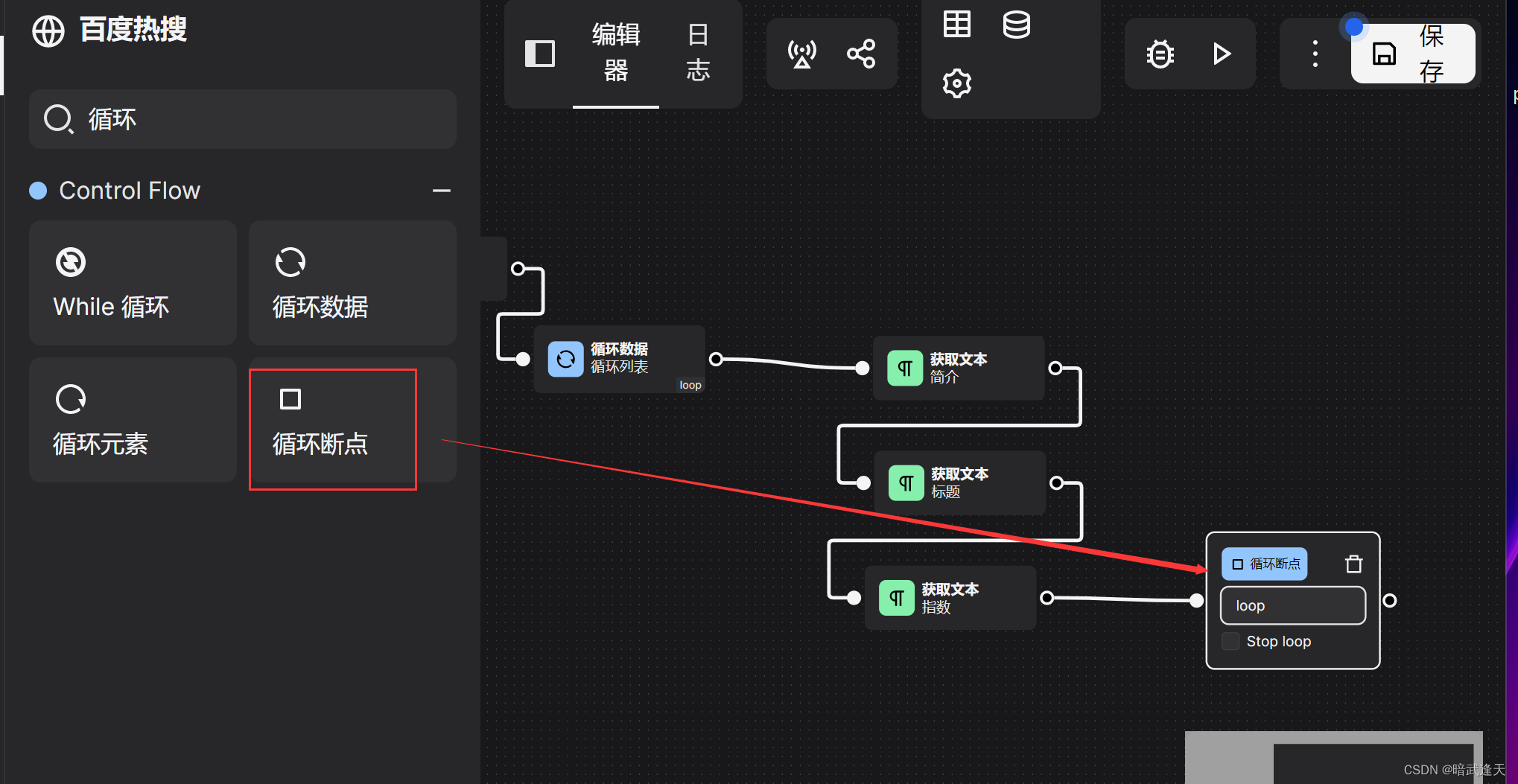
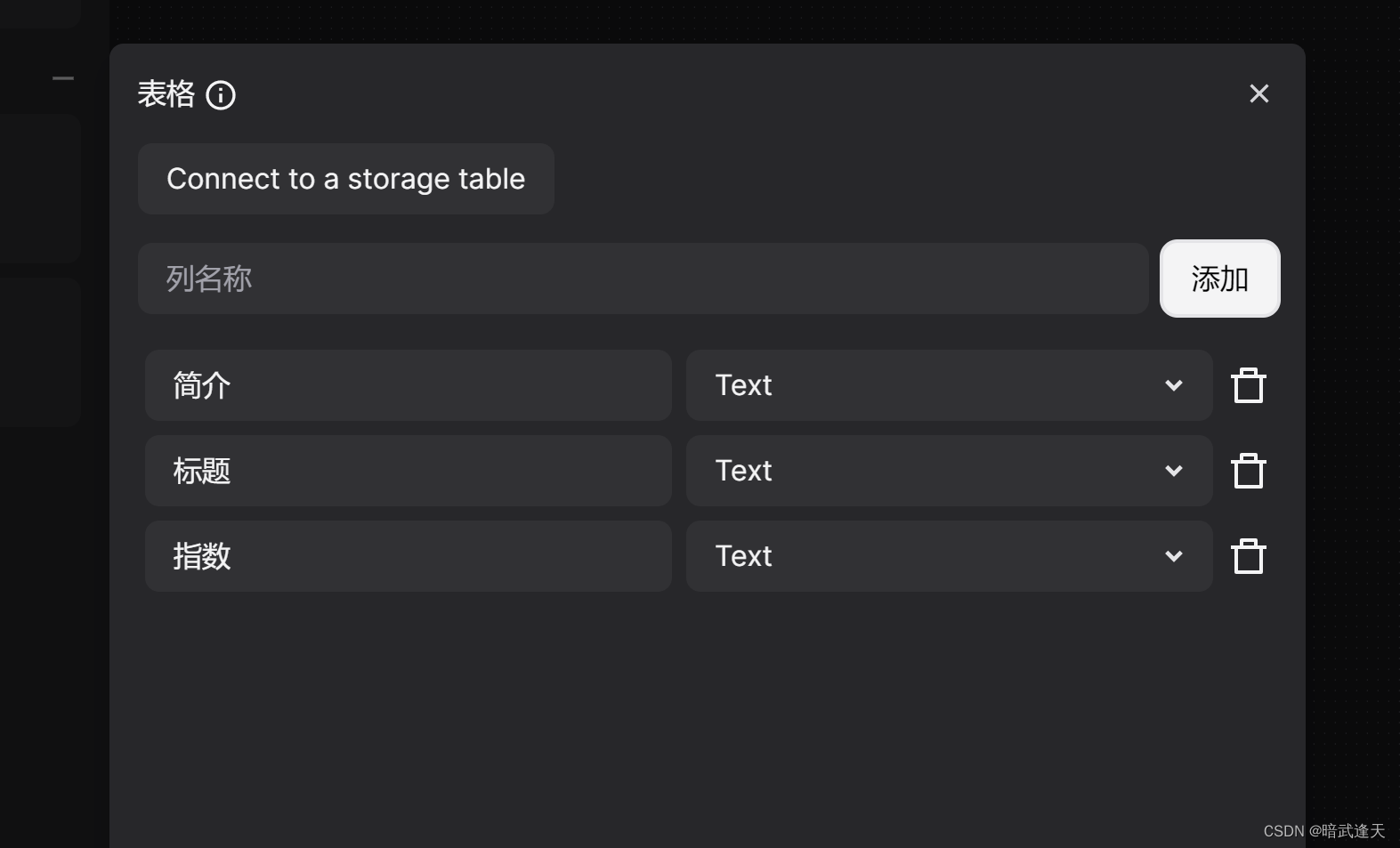
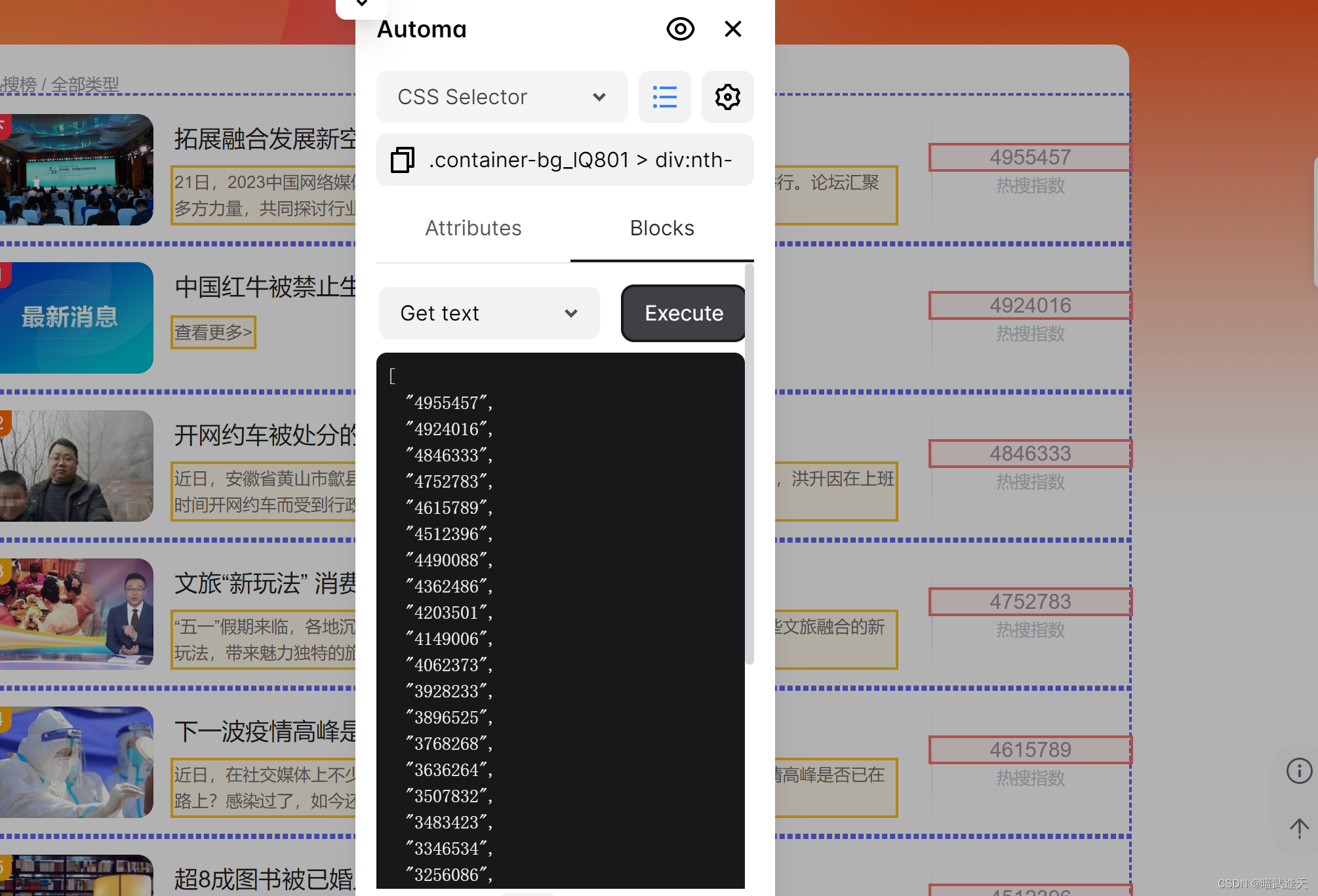
还需要定义爬取的内容添加到表格中
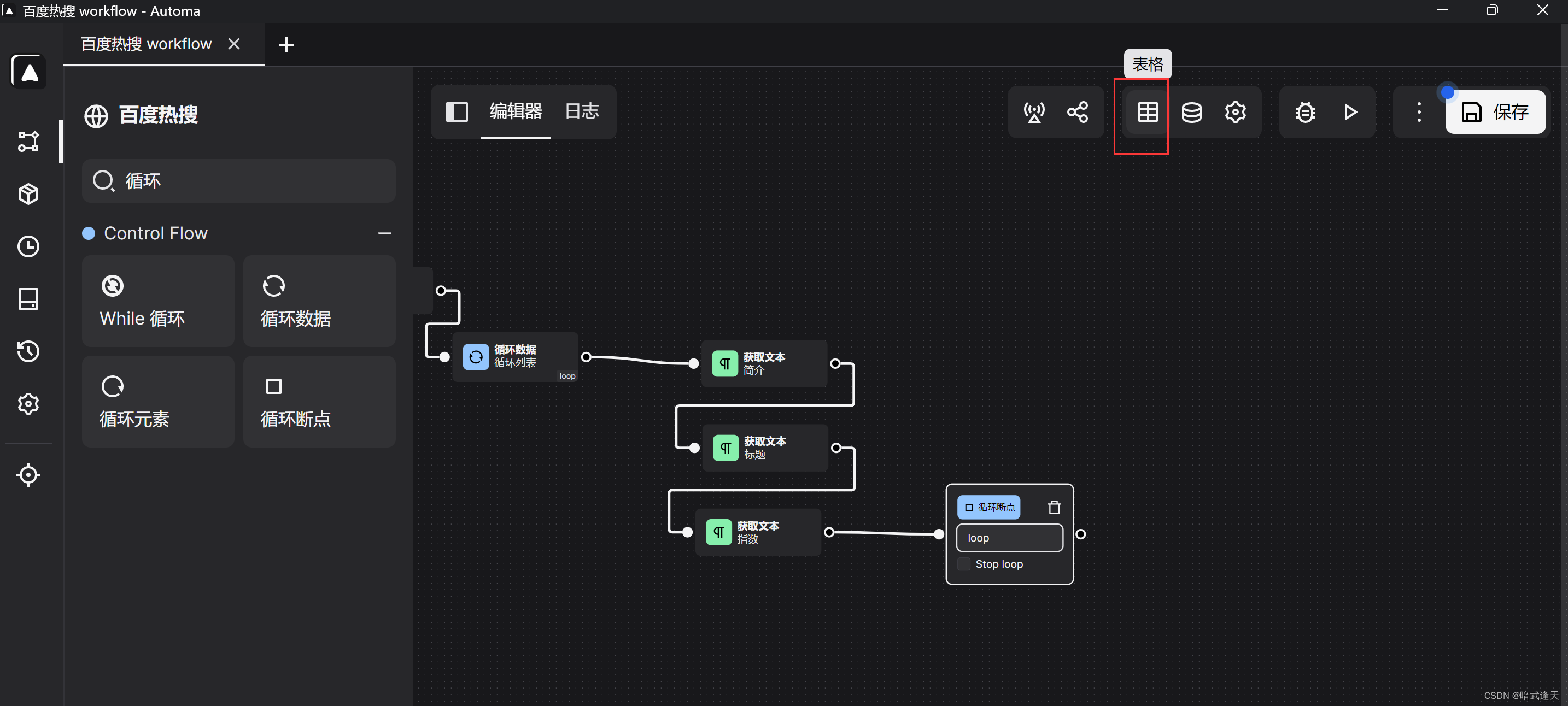
添加表格三列
然后区分映射爬取的字段到对应的表格列中
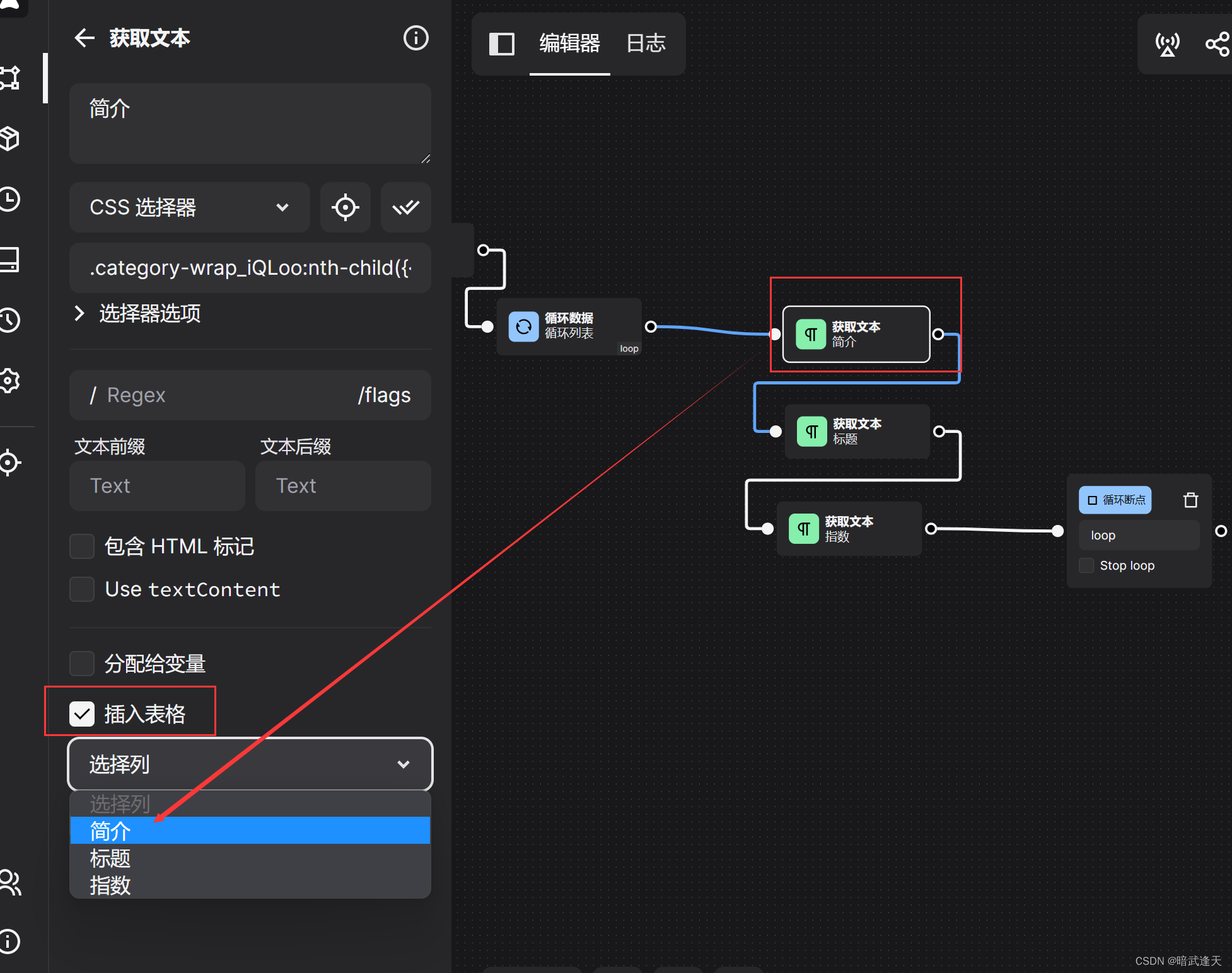
标题,简介依次类推
定义好之后点击保存
点击启动开始测试
点击日志查看爬取结果
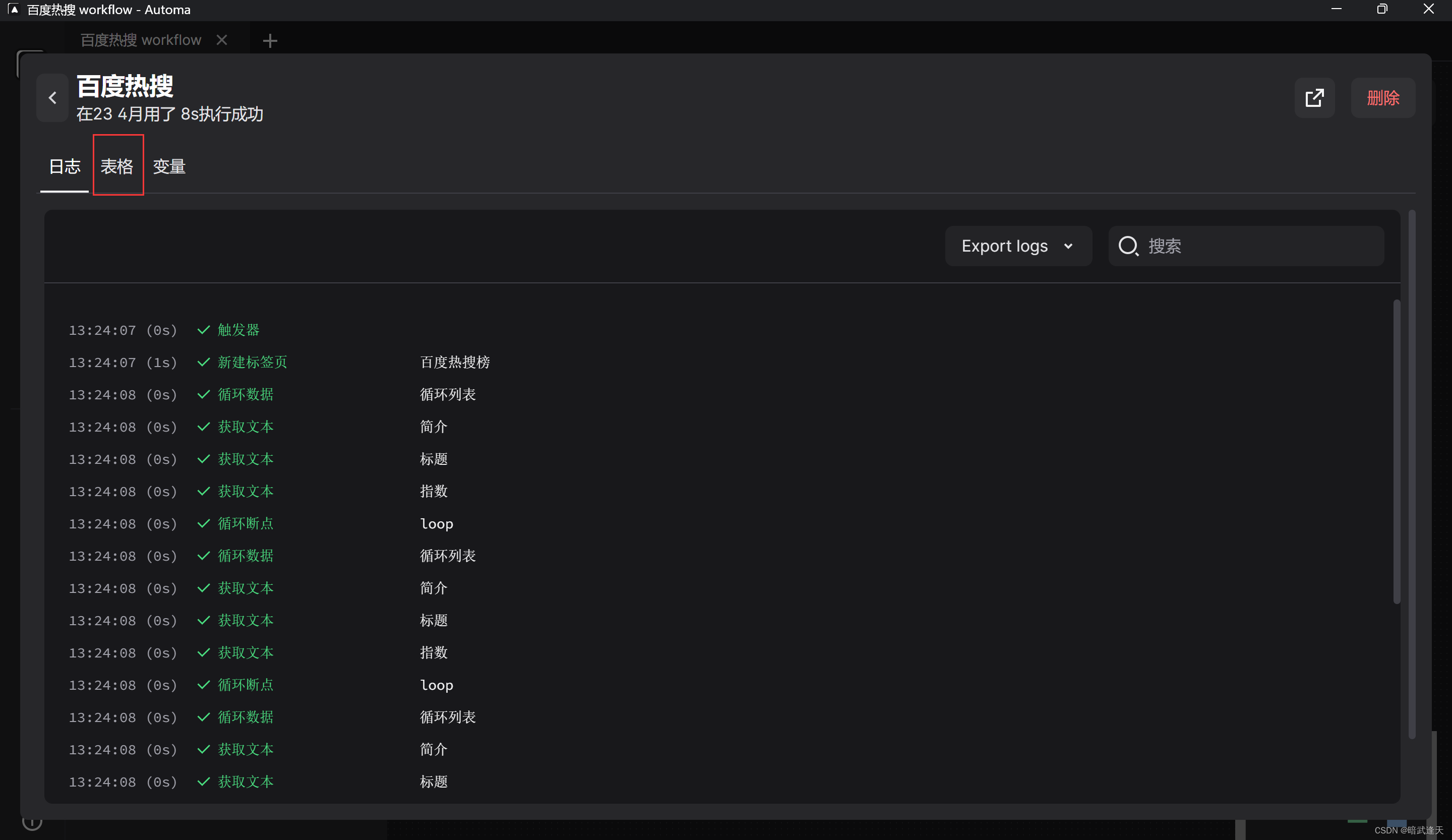

测试成功
循环数据数字小结:
数字循环实际上就是通过拿取单个元素之后分析和其同样结构的元素,比如第一行标题与其他行标题样式选择器表达式的规律,发现其中只是child(number)中数字的递增,所以这种情况下可以直接使用循环数字来做
爬取百度热搜(循环元素)
我们不仅可以通过循环数字来进行数据元素的爬取,还可以通过循环元素来进行爬取
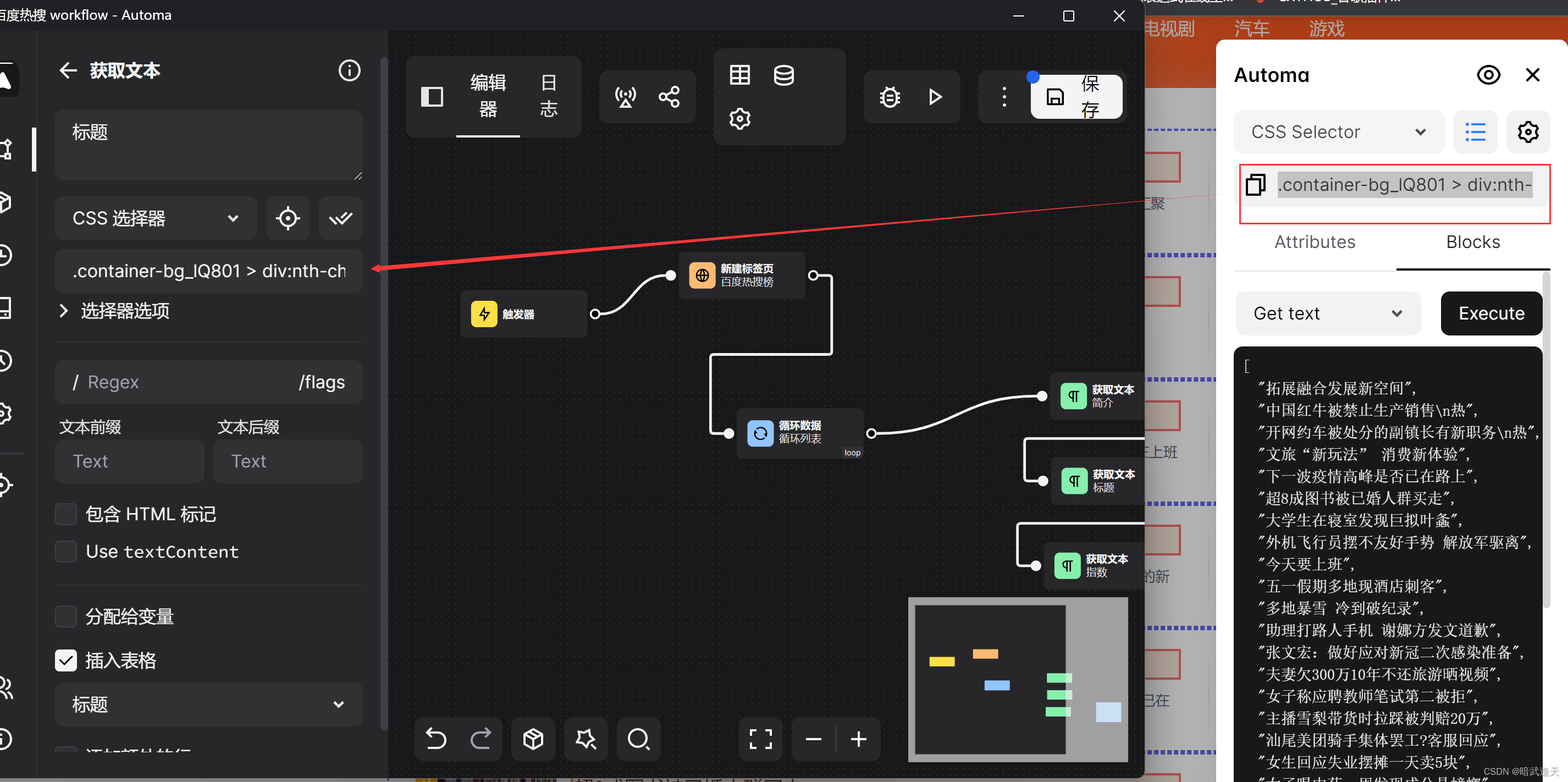
可以直接在前面的流程中进行改造
调整loop循环不再通过数字循环,而是通过元素循环
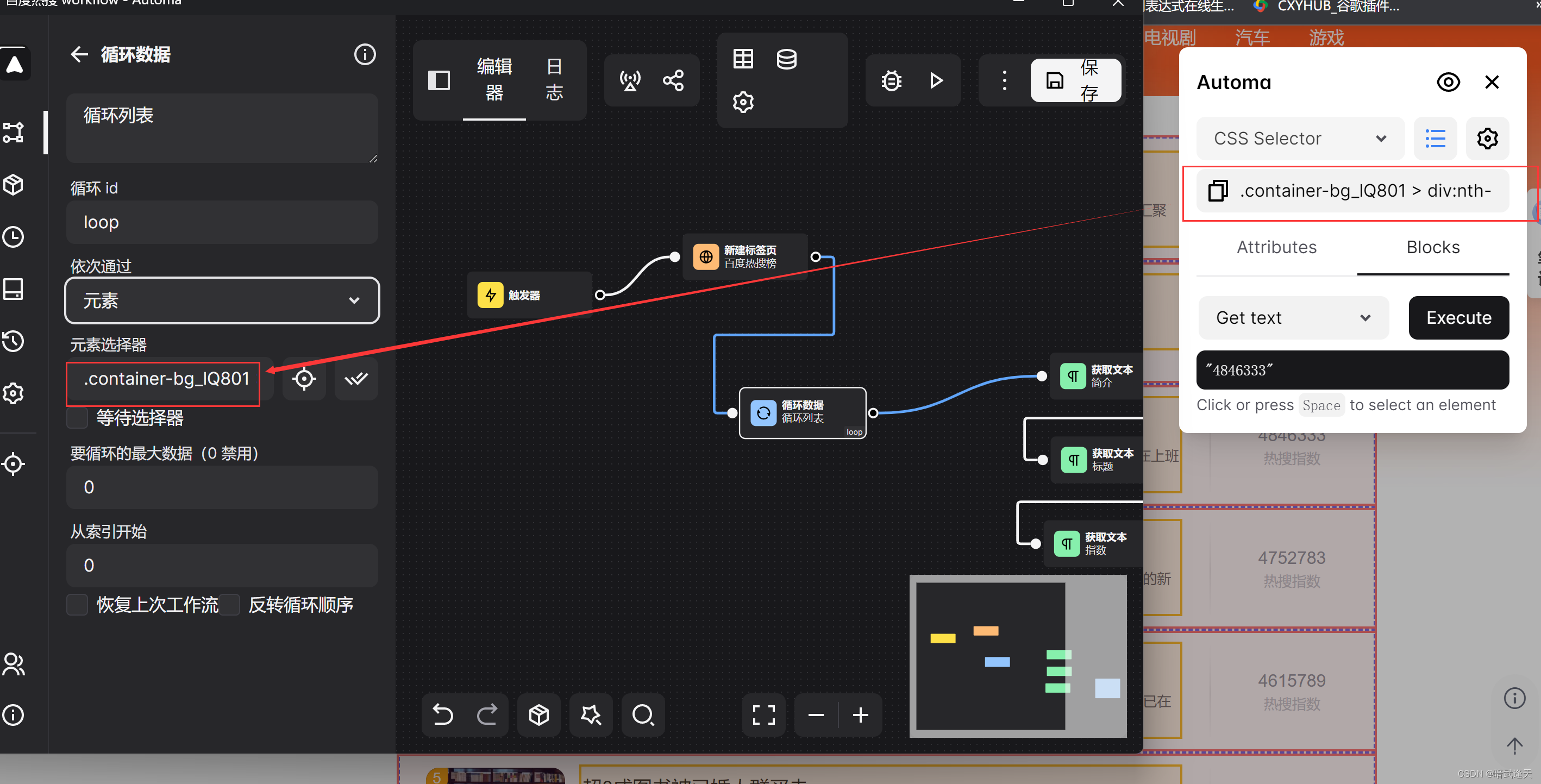
同理同样列表选择后替换原有的简介,标题,指数的样式选择器
将标题的列表样式选择表达式映射到对应的标题标签中
简介和指数同理,不再一一列举
注意此时如果直接保存运行可能会产生爬取的内容全部一样的情况 比如:
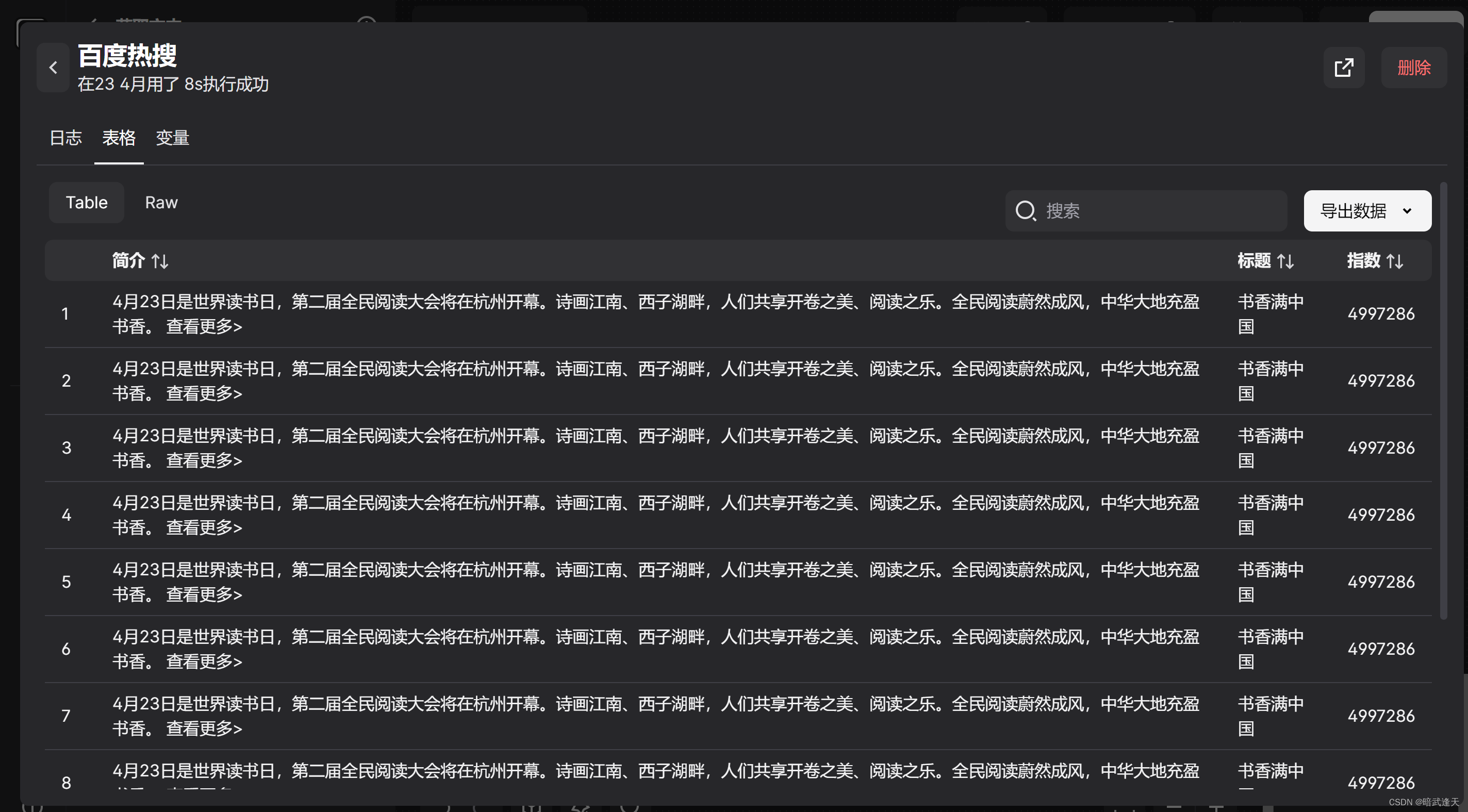
这是因为我们在选择标题,简介,指数的列表选择器时,只是把当前行的样式选中了,而并没有把整个列表的样式选择进行配置
这里将我拿到的标题,简介,指数,已经loop循环元素的样式选择表达式列举进行比较
loop循环元素: .container-bg_lQ801 > div:nth-child(2) > div
标题循环元素: .container-bg_lQ801 > div:nth-child(2) > div a.title_dIF3B
简介循环元素: .container-bg_lQ801 > div:nth-child(2) > div div.large_nSuFU
指数循环元素: .container-bg_lQ801 > div:nth-child(2) > div div.hot-index_1Bl1a
可以看到,标题,简介,指数的选择器前面的表达式和loop循环元素的一致,所以这里可以直接使用automa提供的样式选择元素替换前面一致的表达式{{loopData@设置的loop循环唯一标识}}以此来映射整个循环元素
替换后的:
标题循环元素: {{loopData@loop}} div a.title_dIF3B
简介循环元素: {{loopData@loop}} div div.large_nSuFU
指数循环元素: {{loopData@loop}} div div.hot-index_1Bl1a
点击保存进行测试

可以看到此时爬取的元素不再是同样的数据了,说明整个循环体元素映射绑定成功
爬取百度热搜(无循环)
前面介绍了两种爬取方式,我们还可以使用无循环进行爬取
还是建立相似的结构
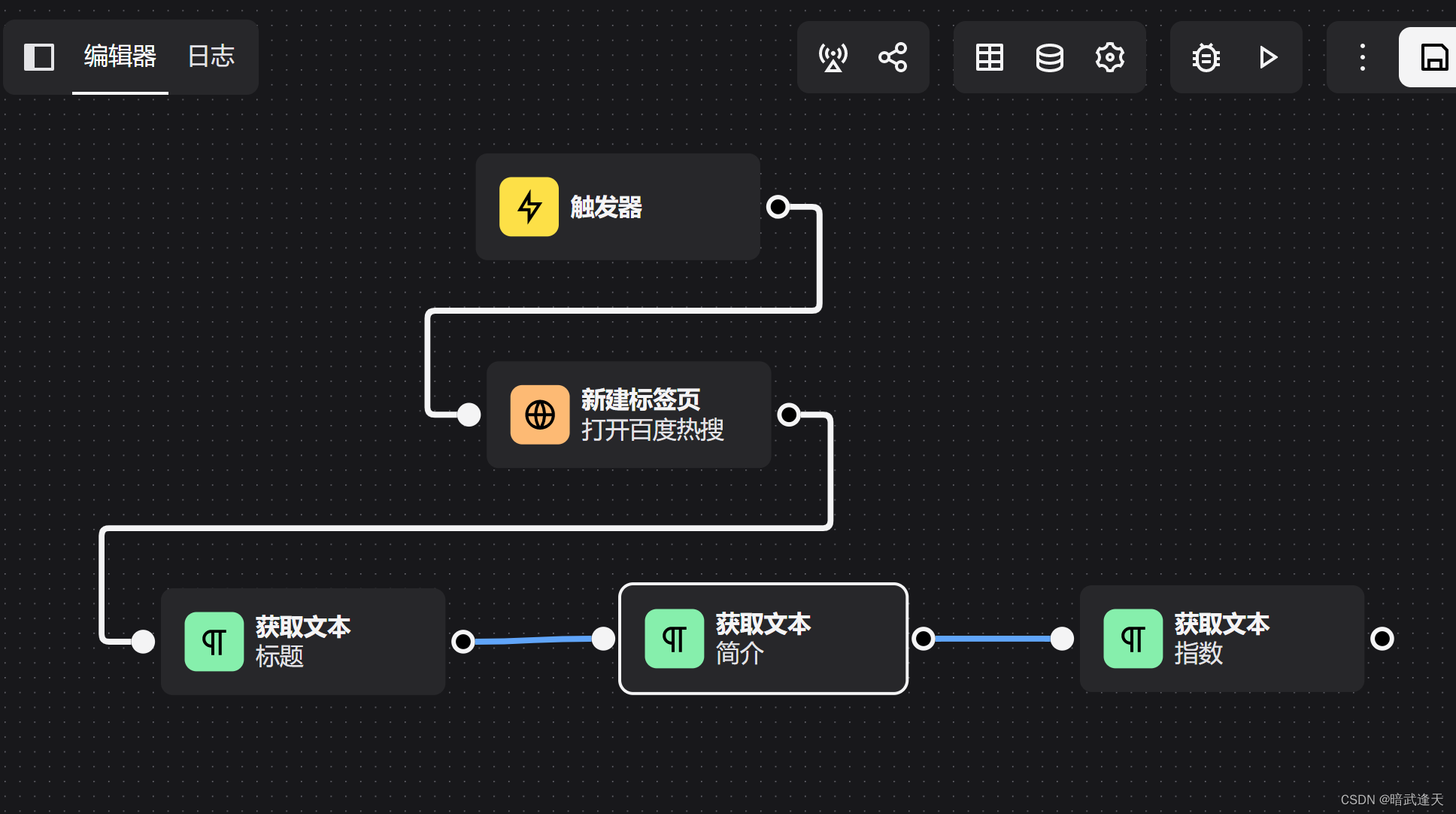
这里不同的就是没有循环体了
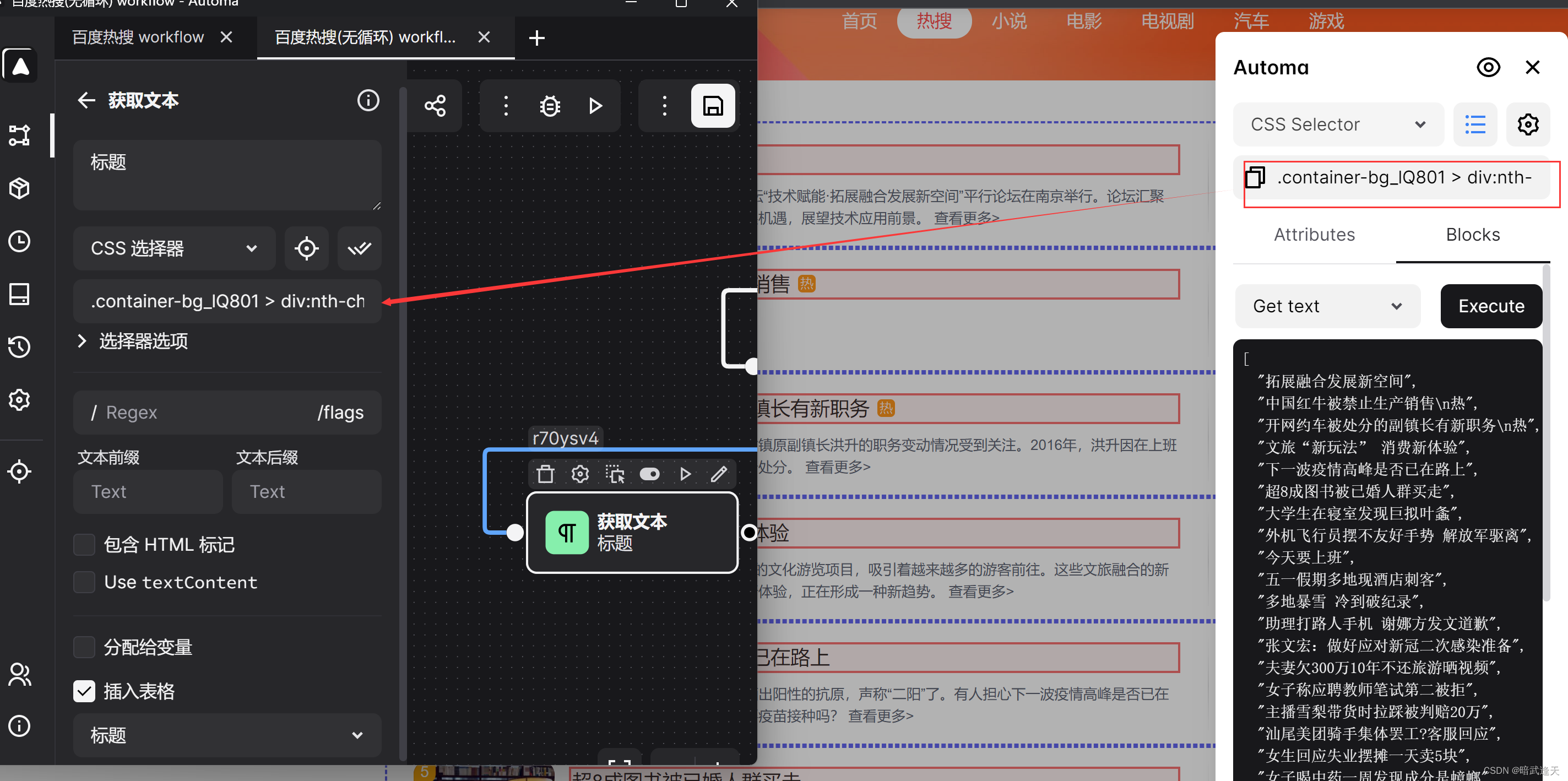
然后我们在标题,简介,指数的样式选择器赋值时也和前面的循环元素一样赋值即可,但是这里直接赋值,不再以循环体的来代替
然后我们在选择器选项中勾选多选和等待选择器 简介,指数同理,
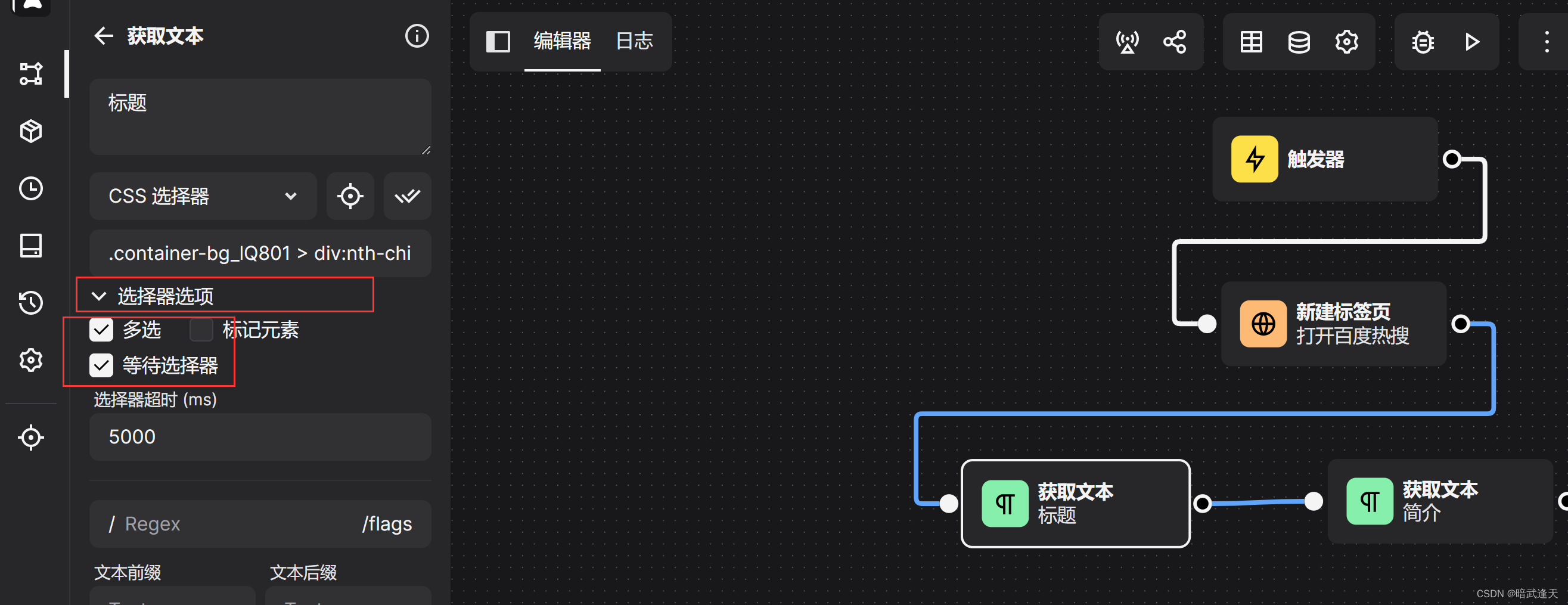
然后我们就可以点击保存进行测试

然后我们比较这三种方式
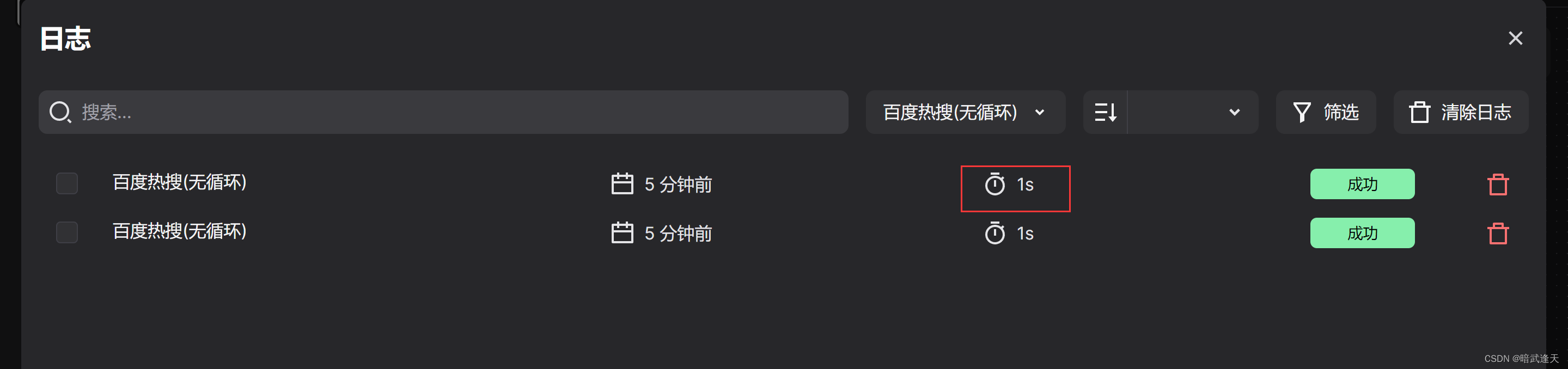
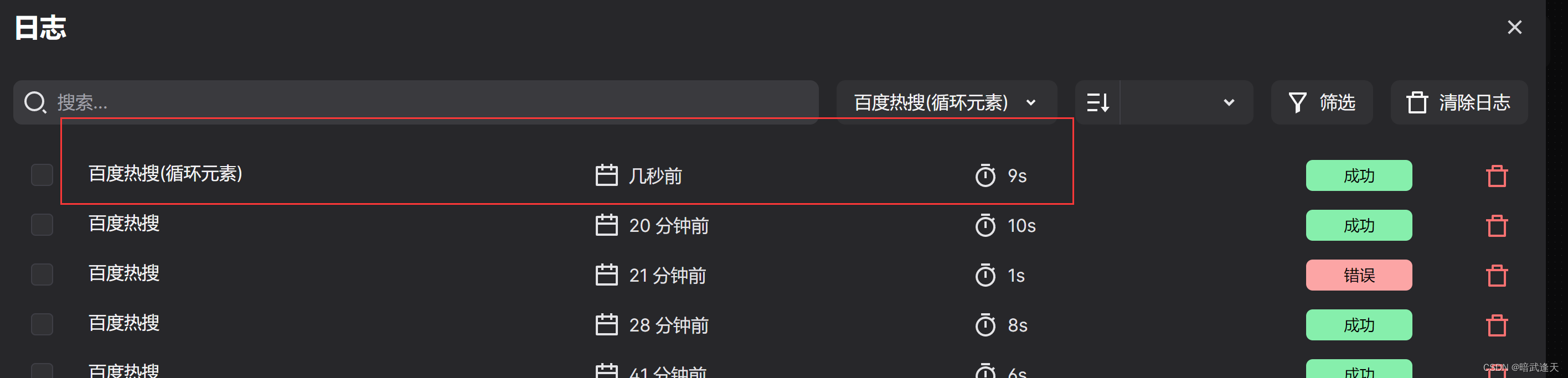
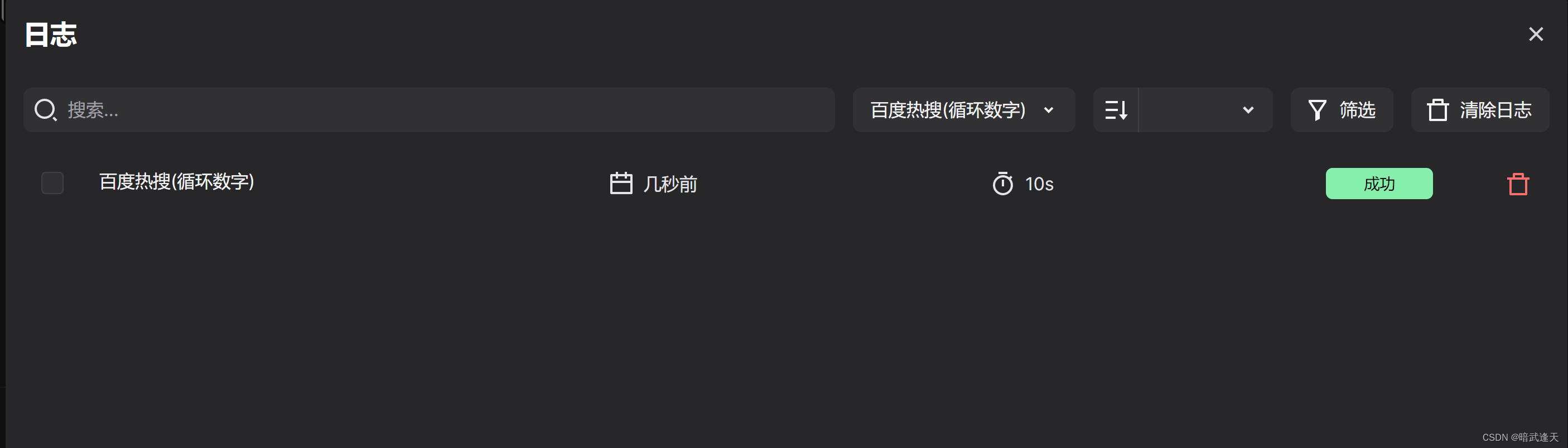
比较三者的速度,发现无循环方式是最快的,但并不是说无循环就是最好的方式,实际使用中还需要考虑到实际的场景来做选择