跳表的实现
跳表这玩意儿,简直就是链表的「作弊器」!普通链表找数据像爬楼梯,一层层挪到腿软,跳表直接给每层装电梯——随机层数越高,电梯直达的楼层越远。比如Redis用它存有序集合,靠的就是跳表能O(logn)快速定位,还不像红黑树要拧巴着平衡节点,跳表直接摆烂:「层数随缘,爱咋咋地!」
问题来了:为啥不用平衡树?举个例子,你和朋友聚餐,平衡树像刀叉规矩的西餐,跳表像火锅——食材(数据)随便丢,筷子(指针)随机捞。Redis选跳表,本质是程序员懒得写旋转节点的代码,毕竟「随机概率」比「强制平衡」省心多了!
更骚的是,跳表的层数设计暗藏玄机。Redis设置p=1/4时,平均每个节点1.33个指针,空间比平衡树省一半。比如你存1亿数据,红黑树要1亿节点+左右指针,跳表只要1.33亿指针,内存瞬间瘦身成功!
所以下次遇到「快速查找还不想写复杂代码」的场景,跳表就像你的外卖小哥——随叫随到,还不用给小费(额外维护成本)!

目录
-
- 简介
- 跳表的实现
简介
skiplist本质也是一种查找结构,和搜索树、哈希表一样可以作为key或者key/value模型的查找结构,从命名可以看出它也是一个链表结构,链表的查找效率是O(n),作为在链表基础上优化的一种查找结构,跳表的查找的平均时间复杂度是O(logn),跳表是在有序链表的基础上发展起来的。优化的思路如下:
-
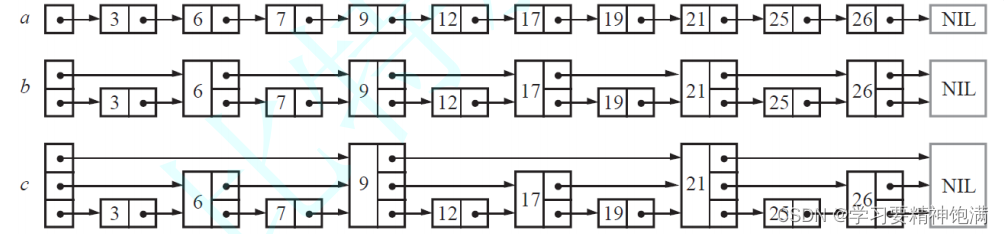
假如我们每相邻两个节点升高一层,增加一个指针,让指针指向下下个节点,如下图b所示。这 样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半。由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了,需要比较的节点数大概只有原来的一半。
-
以此类推,我们可以在第二层新产生的链表上,继续为每相邻的两个节点升高一层,增加一
个指针,从而产生第三层链表。如下图c,这样搜索效率就进一步提高了。 -
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方
式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似
二分查找,使得查找的时间复杂度可以降低到O(log n)。但是这个结构在插入删除数据的时
候有很大的问题,插入或者删除一个节点之后,就会打乱上下相邻两层链表上节点个数严格
的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也
包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。
- skiplist的设计为了避免这种问题,做了一个大胆的处理,不再严格要求对应比例关系,而是
插入一个节点的时候随机出一个层数。这样每次插入和删除都不需要考虑其他节点的层数,
这样就好处理多了。细节过程入下图:
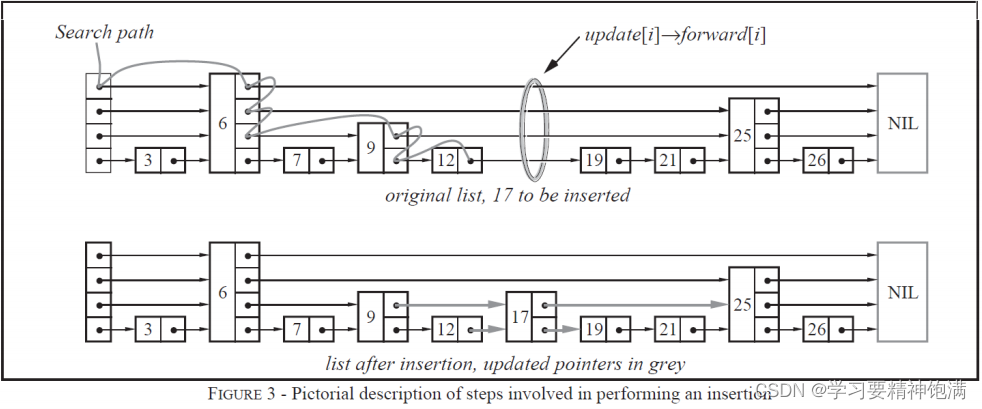
插入一个节点,这个节点随机一个层数的方式受两个参数的影响,p增加一层的概率,maxlenvel最大层数限制,伪代码如下

C++实现如下
int randomlevel(){int level = 1;while (rand() <= RAND_MAX * p && level < maxlevel) //RAND_MAX是能随机生成的最大值++level;return level;}
Redis的跳表实现中p是取1/4 maxlevel取32。
根据伪代码可以看出,产生越高的节点层数概率越低
节点层数等于1的概率为1-p
层数大于等于2的概率为p,恰好等于2的概率为p(1-p)
层数大于等于3的概率为p2,恰好等于3的概率为p2(1-p)
层数大于等于4的概率为p3, 恰好等于4的概率为p3(1-p)
…
一个节点的平均层数计算公式为
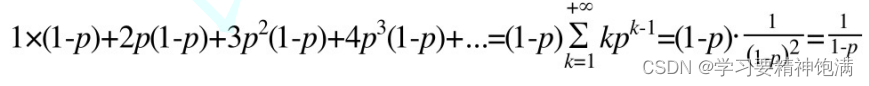
当p=1/2时,每个节点包含的平均指针数目为2
当p=1/4时,每个节点包含的平均指针数目为1.33
跳表的实现
struct skiplistnode
{int _val;vector<skiplistnode*>_nextV;skiplistnode(int val,int level):_val(val),_nextV(level,nullptr){}
};
class Skiplist
{typedef skiplistnode node;
public:Skiplist(){_head = new node(-1, 1);srand((unsigned int)time(0));}bool search(int target){node* cur = _head;int level = _head->_nextV.size()-1;while (level>=0){if (cur->_nextV[level] && cur->_nextV[level]->_val < target){cur = cur->_nextV[level];}else if (cur->_nextV[level] == nullptr || cur->_nextV[level]->_val