redis学习笔记

No circle泛指非关系型数据库not only circle,用于高并发和超大规模的操作,mysql把我们的数据都落到硬盘里了,这就意味着读数据,写数据就要涉及到IO这个东西,正因为这个原因mysql最大的瓶颈就卡在IO上,所以关系型数据库建议的级别是千万级别不上亿,Mysql的瓶颈在IO上处理sql的时候会慢很多,每秒钟处理是2千到4千条,遇到那种大规模的请求,会力不从心,那关系型数据库IO的读写慢了,有什么办法会更快呢?那内存操作就是更快的,io操作是毫秒级别,内存操作是纳秒级别,redis读1万写8万次每秒
非关系型数据,比如说mango db只要你硬盘够大,理论上是可以无限存储的,
redis的键值对形式典型应用场景就是内存缓存,主要用于处理大量数据,高访问负载也用于一些日志系统,优点是查找速度快,缺点是数据无结构化,通常只被当做字符串或二进制数据
优点:
对数据高并发读写(直接是内存中进行读写的)
对海量数据的高效率存储和访问
对数据的可拓展性和高可用性
单线程操作,每个操作都是原子操作,没有并发相关问题(redis6 之后是有两条队 )
缺点:
redis(ACID处理非常简单)
无法做太复杂的关系数据库模型
吃瓜群众来的时候用redis在内存里操作,热度散去再搬回mysql来保持数据的一致性
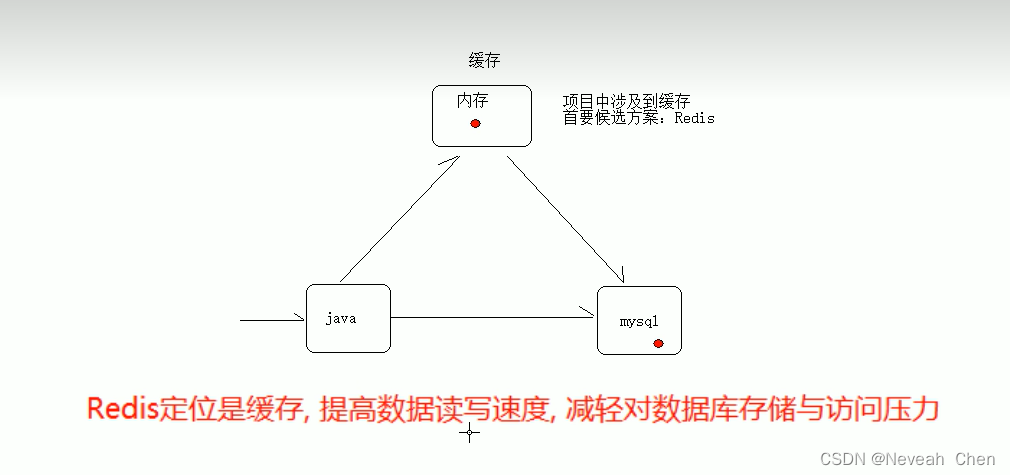
但是redis不建议存储敏感数据,因为可能丢失

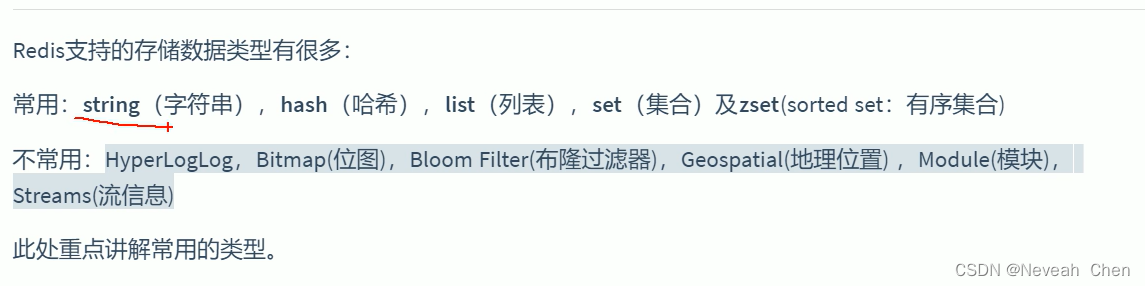


 高并发shu数据无法共享怎么办?
高并发shu数据无法共享怎么办?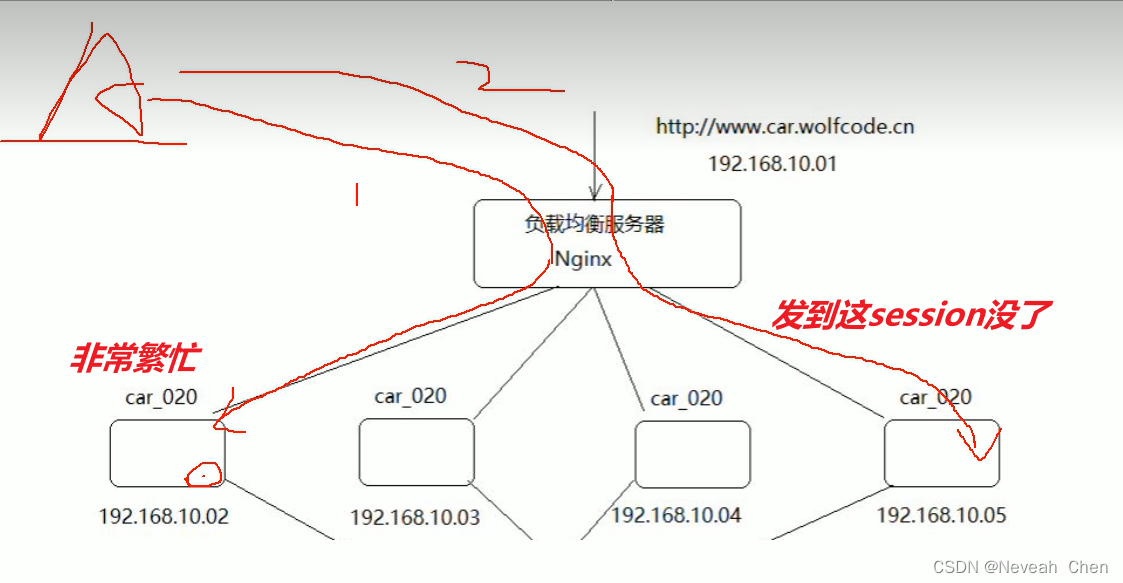
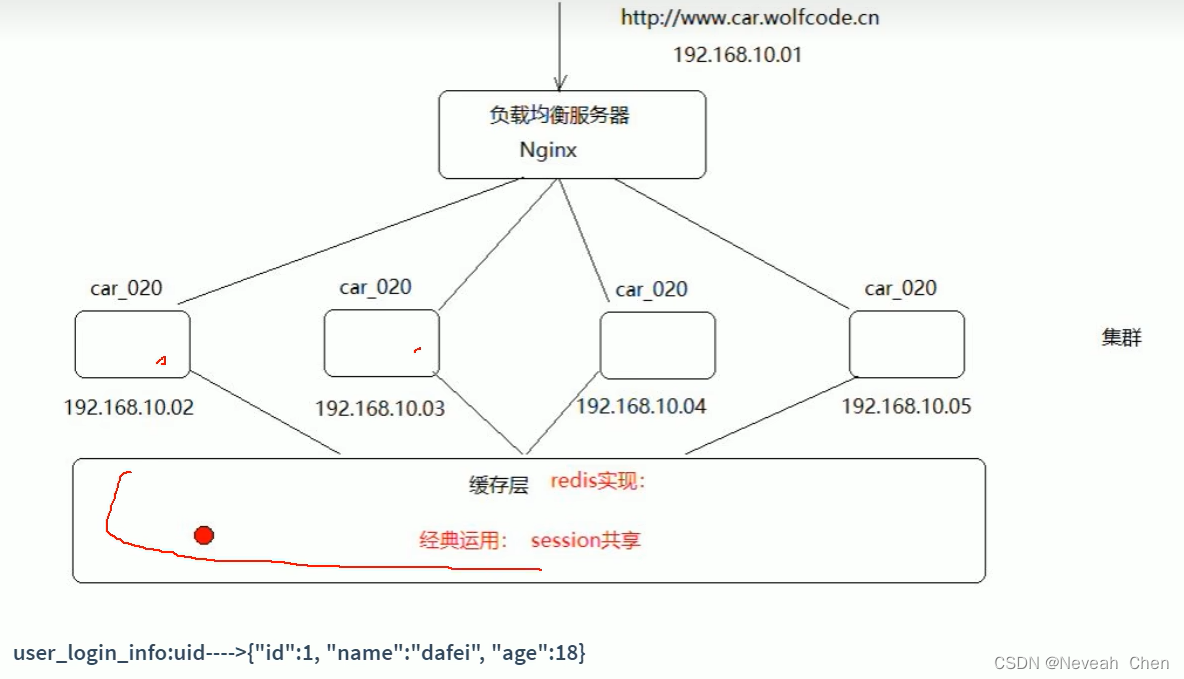
两种方案1.string2.hash,string方便改所以session一般用string
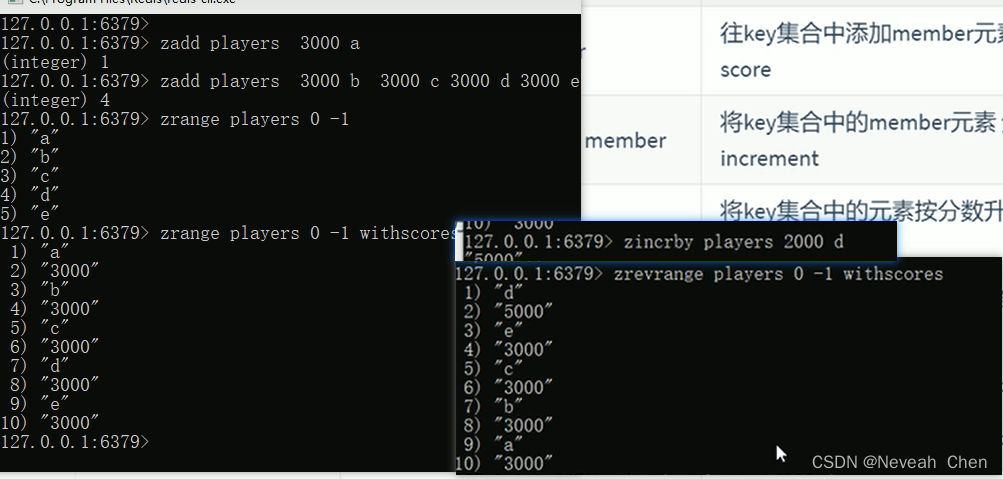
redis的list相当于双向的队列,可以头尾都进出,可以重复的数据
set不能存放重复的,Set集合是String类型的无序集合,set是通过HashTable?实现的,对集合我们可以取交集、并集、差集。找共同好友











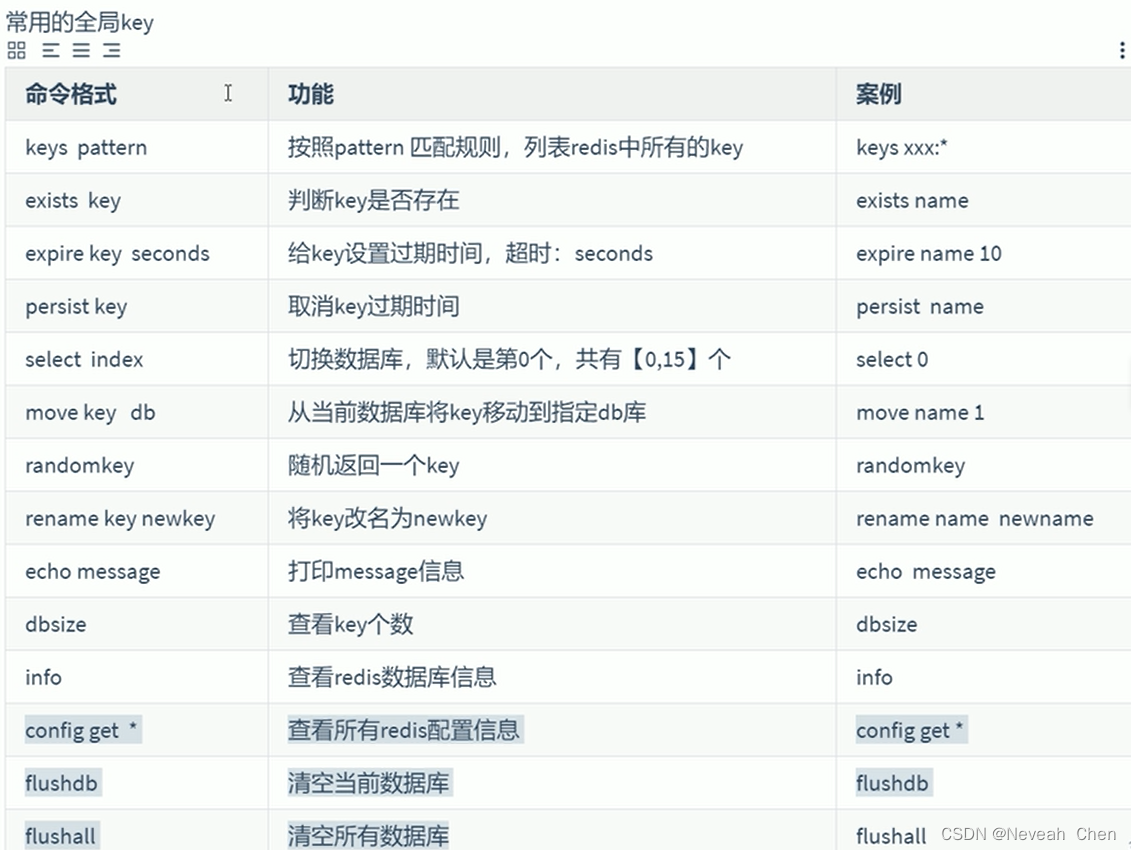
REDIS事务


在硬盘里开辟了空间备份了数据,为啥有些丢了有些没丢呢?

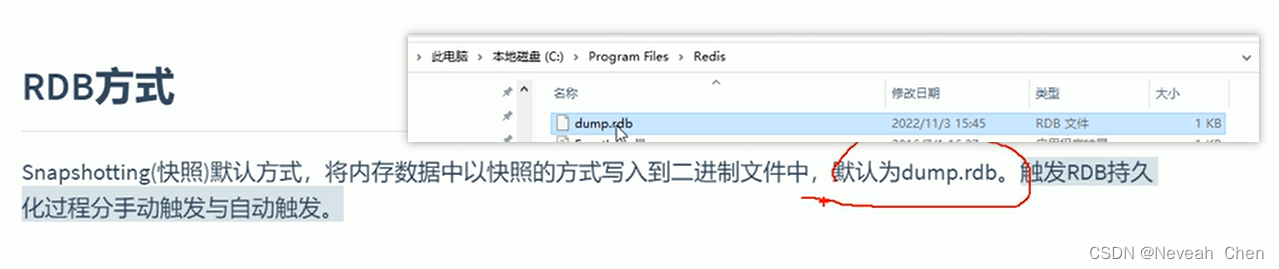

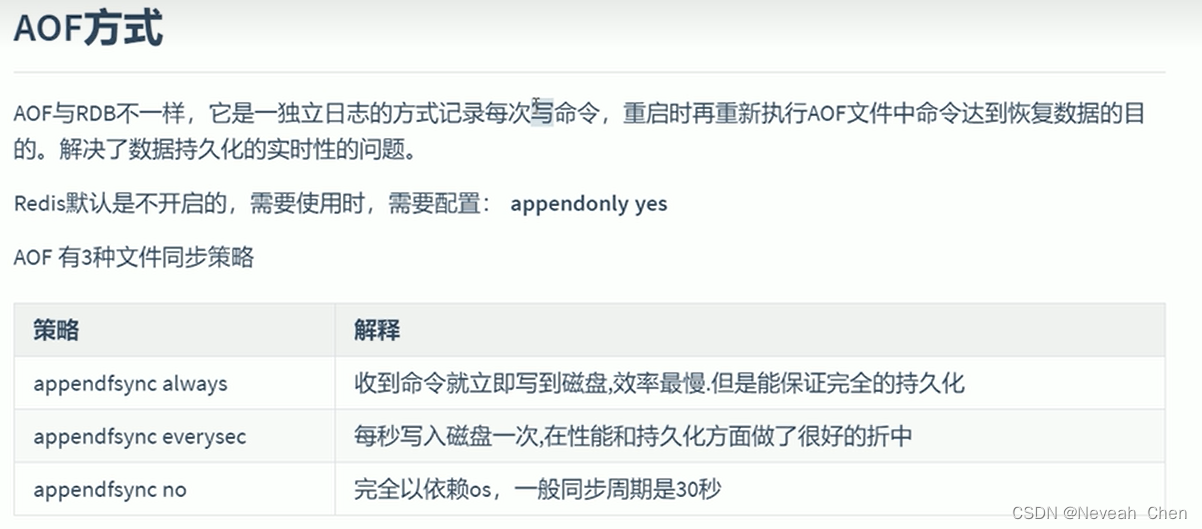



如果不是混合模式,而是普通的RDB与AOF一起启动时,Redis)加载数据执行流程

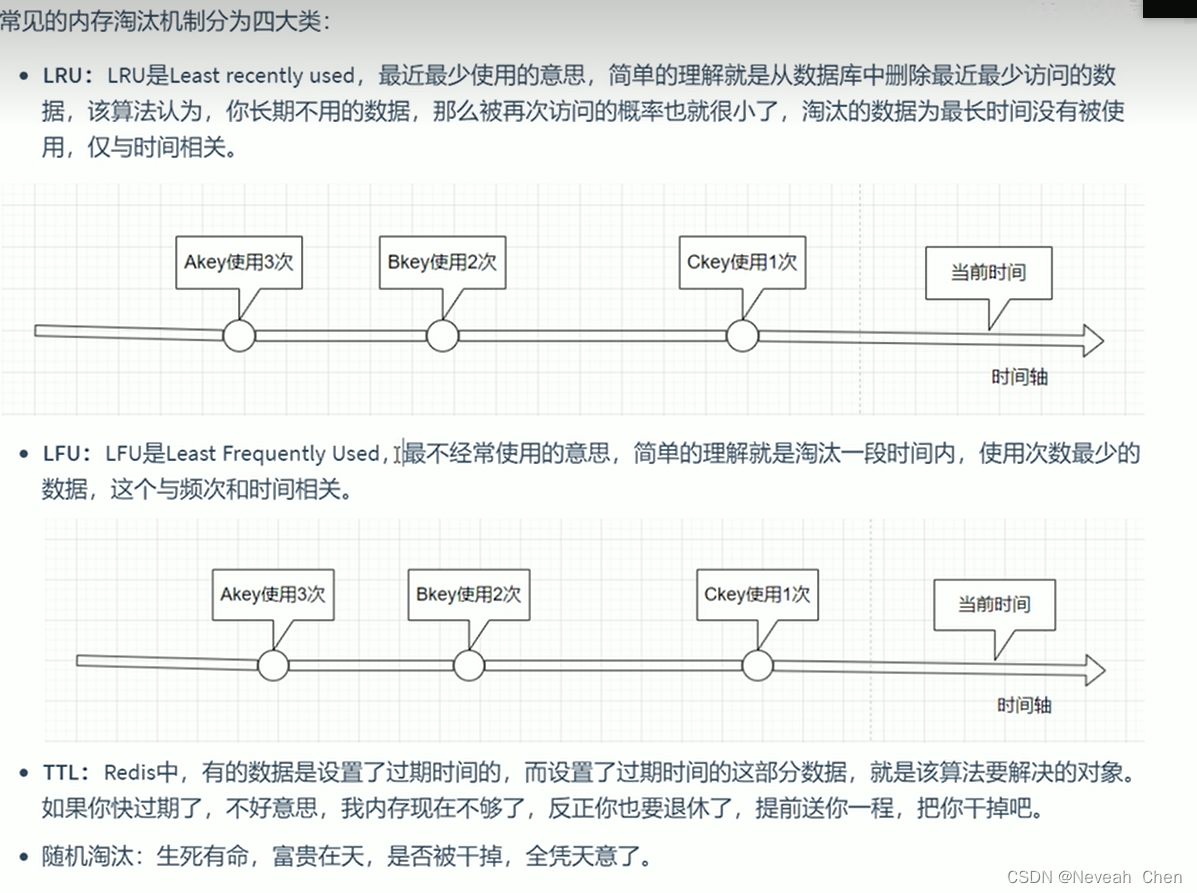



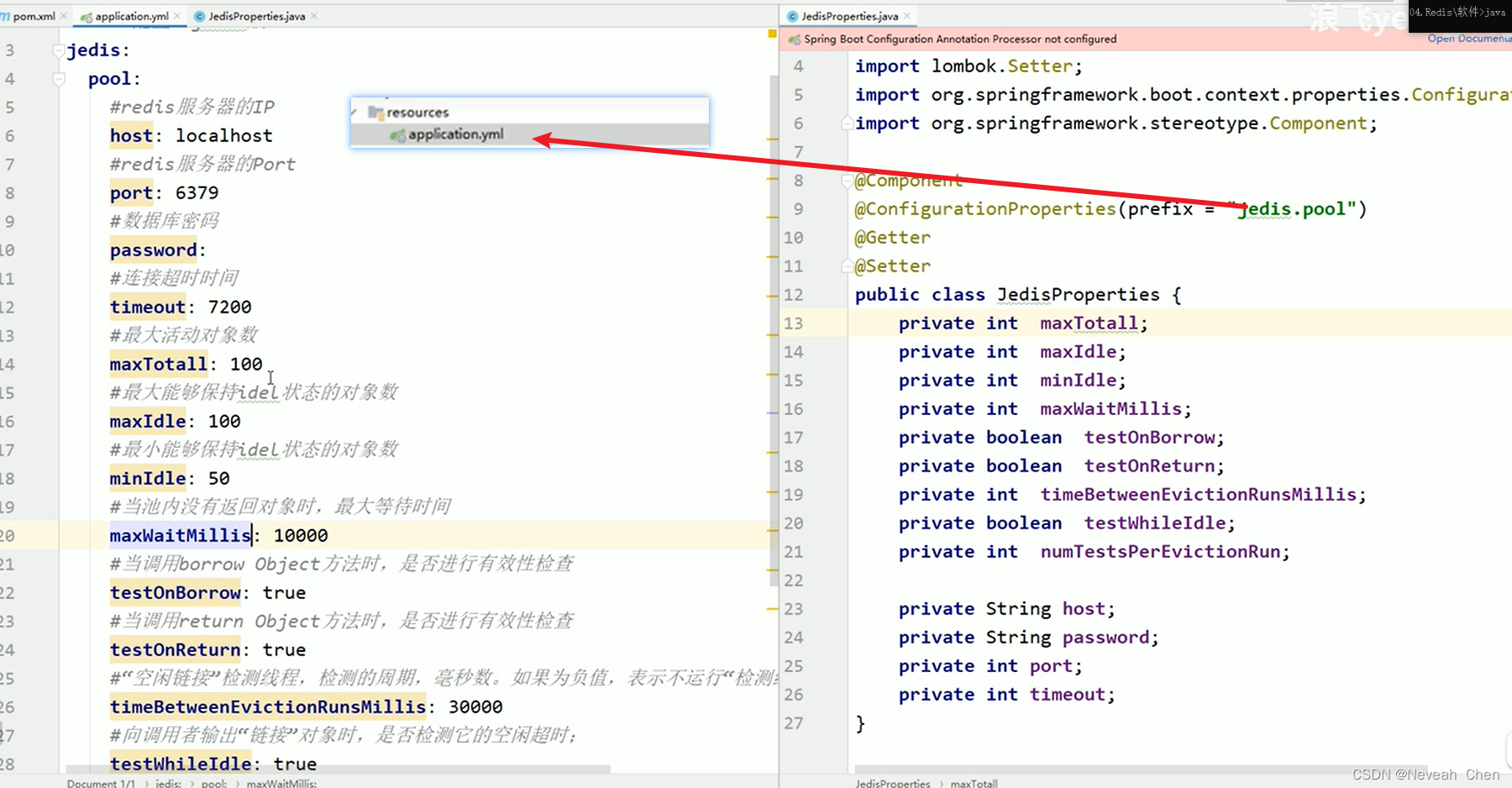
31.综合小案例_哔哩哔哩_bilibili
