【论文笔记】VideoGPT: Video Generation using VQ-VAE and Transformers


论文标题:VideoGPT: Video Generation using VQ-VAE and Transformers
论文代码:https://wilson1yan. github.io/videogpt/index.html.
论文链接:https://arxiv.org/abs/2104.10157
发表时间: 2021年9月
Abstract
作者提出了VideoGPT:一种概念上简单的架构,用于将基于似然的生成建模扩展到自然视频。VideoGPT使用VQ-VAE,通过使用3D卷积和轴向自注意力学习原始视频的下采样离散潜在表示。然后使用类似于GPT的简单架构来自回归地建模离散潜在表示,使用时空位置编码。
尽管在公式和训练方面非常简单,但作者设计的架构能够生成与视频GAN模型相竞争的样本,用于BAIR机器人数据集的视频生成,并从UCF-101和Tumbler GIF数据集(TGIF)生成高保真度的自然视频。
样本和代码可在https://wilson1yan. github.io/videogpt/index.html.上获得
创新点
1. VideoGPT是一种基于似然的生成模型,它使用了VQ-VAE和Transformer两种技术来生成高质量自然视频。这种方法在视频生成领域是比较新颖的。
2. VideoGPT使用了VQ-VAE来学习原始视频的下采样离散潜在表示,这种表示可以被看作是对原始视频进行了压缩和抽象化。这种方法可以有效地降低模型的复杂度,并提高模型的泛化能力。
3. VideoGPT使用了轴向自注意力来处理3D卷积产生的长距离依赖关系,这种方法可以有效地捕捉视频中的时空信息,并提高模型的生成效果。
4. 在实验部分,VideoGPT在多个数据集上都表现出色,包括BAIR Robot Pushing Dataset、UCF-101和Tumbler GIF Dataset等。这表明VideoGPT具有很好的泛化能力和适应性。
Method

先介绍一下VQ-VAE:
VQ-VAE是一种用于生成模型的神经网络架构,它可以将高维数据点压缩到一个离散的潜在空间中,并从中重构原始数据。
VQ-VAE的全称是Vector Quantized Variational Autoencoder,它结合了自编码器和变分自编码器的思想,并使用了向量量化技术来实现离散化。
具体来说,VQ-VAE包含两个主要部分:编码器和解码器。编码器将输入数据映射到一个连续的潜在空间中,然后通过向量量化将这个连续空间转换为一个离散的潜在空间。解码器则将这个离散潜在空间映射回原始数据空间,并重构原始数据。
VQ-VAE使用了一种叫做“代码本”的技术来实现向量量化。代码本是由一组固定大小的向量组成的集合,每个向量都代表着潜在空间中的一个离散点。当输入数据被映射到连续潜在空间时,VQ-VAE会找到最接近该点的代码本向量,并用该向量来代替该点。
这样就可以将连续潜在空间转换为离散潜在空间。它使用了向量量化技术来实现离散化,并在图像、音频等地方取得了很好的效果。
说白了,VQ-VAE就是一种向量量化变分自编码器,通过使用最近邻查找将数据离散化为嵌入码本中的向量,以获得高效的数据压缩和图像重构。
最近邻查找就是“代码本”
---------------------------------------------------------------------------------------------------------------------------------
VideoGPT的运行:
首先,VideoGPT的输入是原始视频数据,它通过3D卷积进行下采样,并被转换为离散潜在表示。这些离散潜在表示被送入Transformer模型进行自回归建模。
其次,在VQ-VAE阶段,原始视频数据通过3D卷积进行下采样,并被转换为离散潜在表示。这些离散潜在表示被送入Transformer模型进行自回归建模。
然后,在Transformer模型中,每个时间步的输入是前一个时间步生成的离散潜在表示和位置编码。Transformer模型会根据这些输入预测下一个时间步的离散潜在表示。
最后,最终输出是由VQ-VAE解码器将离散潜在表示转换为连续像素值序列得到的自然视频。
整个过程可以看作是将离散潜在变量转换为连续像素值序列的过程。最终,VideoGPT可以生成高质量、多样化、连续时间的自然视频,并且在各种数据集上都表现出色。
Experiments
实验目标:VideoGPT在UCF-101数据集上使用FVD和IS两个指标进行评估
实验结果:VideoGPT可以在复杂视频数据集上生成高保真度样本,并且与最先进的GAN模型相比具有竞争力。
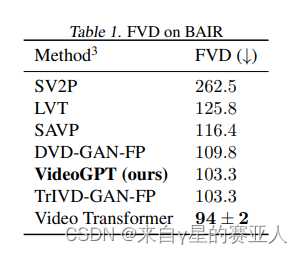
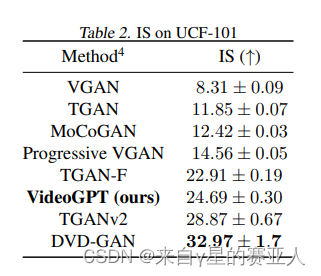
后续作者还做了一些实验,包括:
1、不同训练策略对性能的影响
2、模型结构对性能的影响