13、go并发编程

目录
- 一、并发模型
- 二、MPG并发模型
- 三、Goroutine的使用
-
- 1 - 协程使用
- 2 - panic与defer
- 四、channel的同步与异步‘’
-
- 1 - 同步与异步channel
- 2 - 关闭channel
- 五、并发安全性
-
- 1 - 资源竞争
- 2 - 原子操作
- 3 - 读写锁
- 4 - 容器的并发安全
- 六、多路复用
-
- 1 - 阻塞I/O
- 2 - 非阻塞I/O
- 3 - 多路复用I/O
一、并发模型
- 进程与线程:无论开辟多少个线程,并发是由内核数量决定的
- 任何语言的并行,到操作系统层面,都是内核线程的并行
- 同一个进程内的多个线程共享系统资源,进程的创建、销毁、切换比线程大很多
- 从进程到线程再到协程, 其实是一个不断共享, 不断减少切换成本的过程
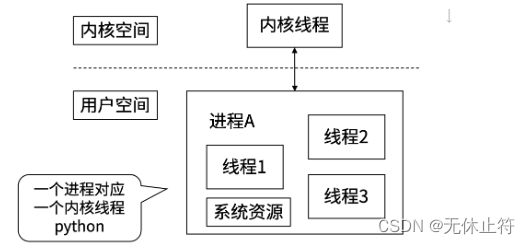
- python:内核线程与进程一一对应
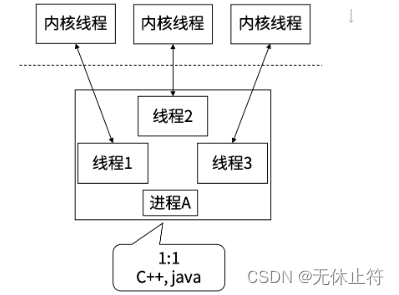
- C++、Java:内核线程与线程一一对应
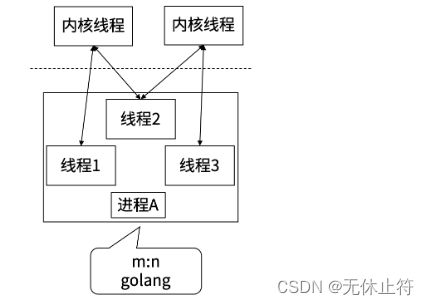
- golang:动态变换,没有对应关系
- 协程与线程
| 协程 | 线程 | |
|---|---|---|
| 创建数量 | 轻松创建上百万个协程而不会导致系统资源衰竭 | 通常最多不能超过1万个 |
| 内存占用 | 初始分配4k堆栈,随着程序的执行自动增长删除 | 创建线程时必须指定堆栈且是固定的,通常以M为单位 |
| 切换成本 | 协程切换只需保存三个寄存器,耗时约200纳秒 | 线程切换需要保存几十个寄存器,耗时约1000纳秒 |
| 调度方式 | 非抢占式,由Go runtime主动交出控制权(对于开发者而言是抢占式) | 在时间片用完后,由 CPU 中断任务强行将其调度走,这时必须保存很多信息 |
| 创建销毁 | goroutine因为是由Go runtime负责管理的,创建和销毁的消耗非常小,是用户级的 | 创建和销毁开销巨大,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池 |
- 查看逻辑核心数
func main() {fmt.Println(runtime.NumCPU()) //16
}
二、MPG并发模型
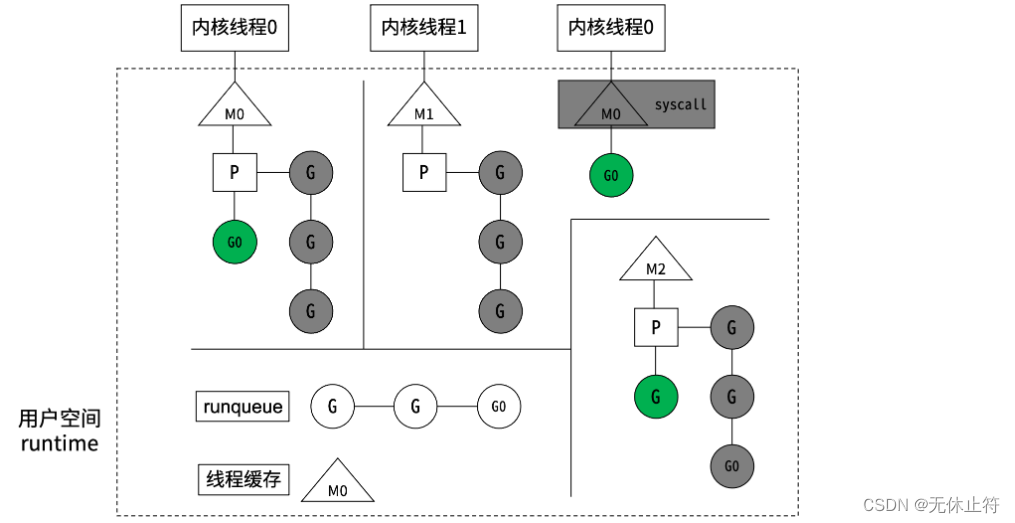
- MPG概念
- M(Machine)对应一个内核线程
- P(Processor)虚拟处理器,代表M所需的上下文环境,是处理用户级代码逻辑的处理器
- P的数量由环境变量中的GOMAXPROCS决定,默认情况下就是核数
- G(Goroutine)本质上是轻量级的线程,G0正在执行,其他G在等待
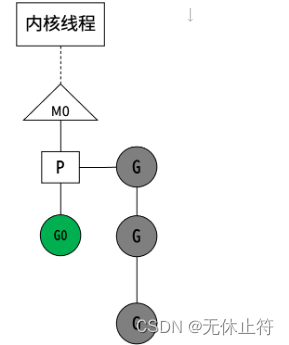
- MPG模型
- M和内核线程的对应关系是确定的
- G0阻塞(如系统调用)时,P与G0、M0解绑,P被挂到其他M上,然后继续执行G队列
- G0解除阻塞后,如果有空闲的P,就绑定M0并执行G0;否则G0进入全局可运行队列(runqueue),P会周期性扫描全局runqueue,使上面的G得到执行;如果全局runqueue为空,就从其他P的等待队列里偷一半G过来
三、Goroutine的使用
1 - 协程使用
- 两种启动协程的常见方式:
- 以下2份代码都无法打印出Add,因为main函数已经结束了
- 如果想要打印出Add,可以添加time.Sleep来让协程运行完,才结束主进程
func Add(a, b int) int {fmt.Println("Add")return a + b
}func main() {go Add(2, 4)
}
func main() {go func(a, b int) int {fmt.Println("Add")return a + b}(2, 4)
}
- 优雅地等子协程结束:虽然上述情况我们使用time.Sleep来让协程运行完,才结束主进程,但是实际情况中我们并不知道协程需要多久才能执行完,此时就可以使用sync.WaitGroup来优雅的等待子协程结束
var wg = sync.WaitGroup{}func Add() {defer wg.Done() //减1time.Sleep(100 * time.Millisecond)fmt.Println("Add")
}func main() {wg.Add(2) //加2go Add()go Add()wg.Wait() //等待为0
}
- 协程之间互不影响:除了main协程退出后,所有协程都会退出;其他的协程之间互不影响
var wg = sync.WaitGroup{}func Add() {defer wg.Done() //减1go Sub()fmt.Println("over Add")
}func Sub() {time.Sleep(2000 * time.Millisecond)fmt.Println("over Sub")
}func main() {wg.Add(2) //加2go Add()go Add()wg.Wait() //等待为0time.Sleep(5000 * time.Millisecond) //等待Sub协程// over Add// over Add// over Sub// over Sub
}
- ele使用的是全局的ele
- fmt.Printf使用的是IO操作
- for range中使用的协程是无延迟的
- 也就是说当第一个协程执行fmt.Printf的时候,for循环可能已经结束了,此时的ele已经变成了4
func main() {arr := []int{1, 2, 3, 4}for _, ele := range arr {go func() {fmt.Printf("%d ", ele) //用的是协程外面的全局变量ele。输出4 4 4 4}()}time.Sleep(1 * time.Second)
}
- 闭包:向协程内部传递变量来解决上述问题
func main() {arr := []int{1, 2, 3, 4}for _, ele := range arr {go func(value int) {fmt.Printf("%d ", value) //1 4 2 3,这里打印是乱序的没有问题}(ele)}time.Sleep(1 * time.Second)
}
- sync.Once:有时候需要确保在高并发的场景下有些事情只执行一次,比如加载配置文件、关闭管道等
var oc sync.Once
var a int = 5func main() {go func() {oc.Do(func() {a++})}()go func() {oc.Do(func() {a++})}()time.Sleep(time.Second)fmt.Println(a) //6
}
2 - panic与defer
-
何时会发生panic
- 运行时错误会导致panic,比如数组越界、除0
- 程序主动调用panic(error)
-
panic会执行什么
- 逆序执行当前goroutine的defer链(recover从这里介入)
- 打印错误信息和调用堆栈
- 调用exit(2)结束整个进程
-
defer
- defer在函数退出前被调用,注意不是在代码的return语句之前执行,因为return语句不是原子操作
- 如果发生panic,则之后注册的defer不会执行
- defer服从先进后出原则,即一个函数里如果注册了多个defer,则按注册的逆序执行
- defer后面可以跟一个匿名函数
func F() {defer fmt.Printf("11111 ")defer fmt.Printf("22222 ")fmt.Printf("GGGGG ")defer fmt.Printf("33333 ")defer fmt.Printf("44444 ")panic("papapa")defer fmt.Printf("55555 ")fmt.Printf("FFFFF ")
}
func main() {go F()time.Sleep(time.Second)//无panic:GGGGG FFFFF 55555 44444 33333 22222 11111//panic:GGGGG 44444 33333 22222 11111
}
- recover
func F() {defer fmt.Printf("11111 ")defer fmt.Printf("22222 ")fmt.Printf("GGGGG ")defer fmt.Printf("33333 ")defer func() {//从panic发生的地方中途结束本协程//协程有中recover,即使panic也不会结束整个进程recover()}()defer fmt.Printf("44444 ")panic("papapa")defer fmt.Printf("55555 ")fmt.Printf("FFFFF ")
}
func main() {go F()time.Sleep(time.Second)fmt.Println("this is main")//无panic:GGGGG FFFFF 55555 44444 33333 22222 11111//panic:GGGGG 44444 33333 22222 11111//无recover有panic:GGGGG 44444 33333 22222 11111//有revocer有panic:GGGGG 44444 33333 22222 11111 this is main
}
四、channel的同步与异步‘’
1 - 同步与异步channel
- 共享内存:很多语言通过共享内存来实现线程间的通信,通过加锁来访问共享数据,如数组、map或结构体。go语言也实现了这种并发模型
- CSP:CSP(communicating sequential processes)讲究的是“以通信的方式来共享内存”,在go语言里channel是这种模式的具体实现
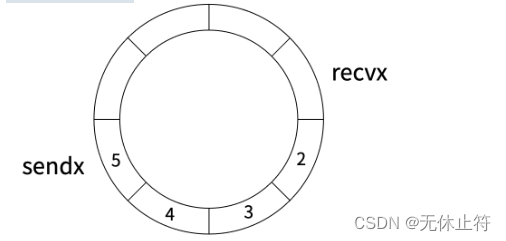
- 异步channel:
asynChann := make(chan int, 8)- channel底层维护一个环形队列(先进先出),make初始化时指定队列的长度
- 队列满时,写阻塞;队列空时,读阻塞
- sendx指向下一次写入的位置, recvx指向下一次读取的位置
- recvq(等待读的goroutine队列)维护因读管道而被阻塞的协程,sendq(等待写的goroutine队列)维护因写管道而被阻塞的协程
- 同步channel:同步管道可以认为队列容量为0,当读协程和写协程同时就绪时它们才会彼此帮对方解除阻塞
- 创建同步管道:
syncChann := make(chan int) - 往管理里放数据:
syncChann < -1-> 生产者 - 从管道取出数据:
v := <- syncChann-> 消费者
- 创建同步管道:
- 关于channel的死锁与阻塞
- Channel满了,就阻塞写;Channel空了,就阻塞读
- 阻塞之后会交出cpu,去执行其他协程,希望其他协程能帮自己解除阻塞
- 如果阻塞发生在main协程里,并且没有其他子协程可以执行,那就可以确定“希望永远等不来”,自已把自己杀掉,报一个fatal error:deadlock出来
- 如果阻塞发生在子协程里,就不会发生死锁,因为至少main协程是一个值得等待的“希望”,会一直等(阻塞)下去
func main() {//channel仅作为协程间同步的工具,不需要传递具体的数据,管道类型可以用struct{}//空结构体变量的内存占用为0,因此struct{}类型的管道比bool类型的管道还要省内存ch := make(chan struct{}, 1)ch <- struct{}{} //有1个缓冲可以用,无需阻塞,可以立即执行go func() { //子协程1time.Sleep(5 * time.Second) //sleep一个很长的时间<-ch //如果把本行代码注释掉,main协程5秒钟后会报fatal errorfmt.Println("sub routine 1 over")}()//由于子协程1已经启动,寄希望于子协程1帮自己解除阻塞,所以会一直等子协程1执行结束//如果子协程1执行结束后没帮自己解除阻塞,则希望完全破灭,报出deadlockch <- struct{}{}fmt.Println("send to channel in main routine")go func() { //子协程2time.Sleep(2 * time.Second)ch <- struct{}{} //channel已满,子协程2会一直阻塞在这一行fmt.Println("sub routine 2 over")}()time.Sleep(3 * time.Second)fmt.Println("main routine exit")// sub routine 1 over// send to channel in main routine// main routine exit
}
2 - 关闭channel
- 关闭channel的注意点
- 只有当管道关闭时,才能通过range遍历管道里的数据,否则会发生fatal error
- 管道关闭后读操作会立即返回,如果缓冲已空会返回“0值”
- ele, ok := <-ch ok==true代表ele是管道里的真实数据
- 向已关闭的管道里send数据会发生panic
- 不能重复关闭管道,不能关闭值为nil的管道,否则都会panic
func main() {c := make(chan int, 2)c <- 1c <- 2close(c) //如果不先close会报 -> fatal error: all goroutines are asleep - deadlock!// c <- 3 //关闭管道后继续向管道写入发生panic: send on closed channelfor ele := range c {fmt.Printf("%d ", ele) //1 2}//close channel之后,读操作总是立即返回//如果channel里没有元素,则返回对应类型的默认值v := <-cfmt.Println(v) //0
}
- channel的应用
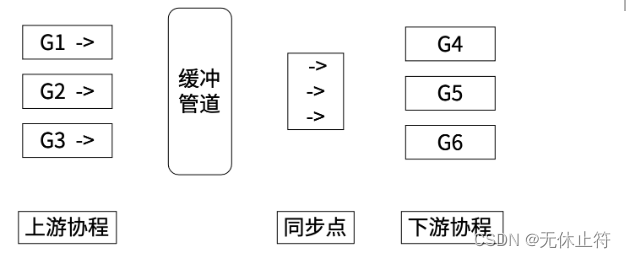
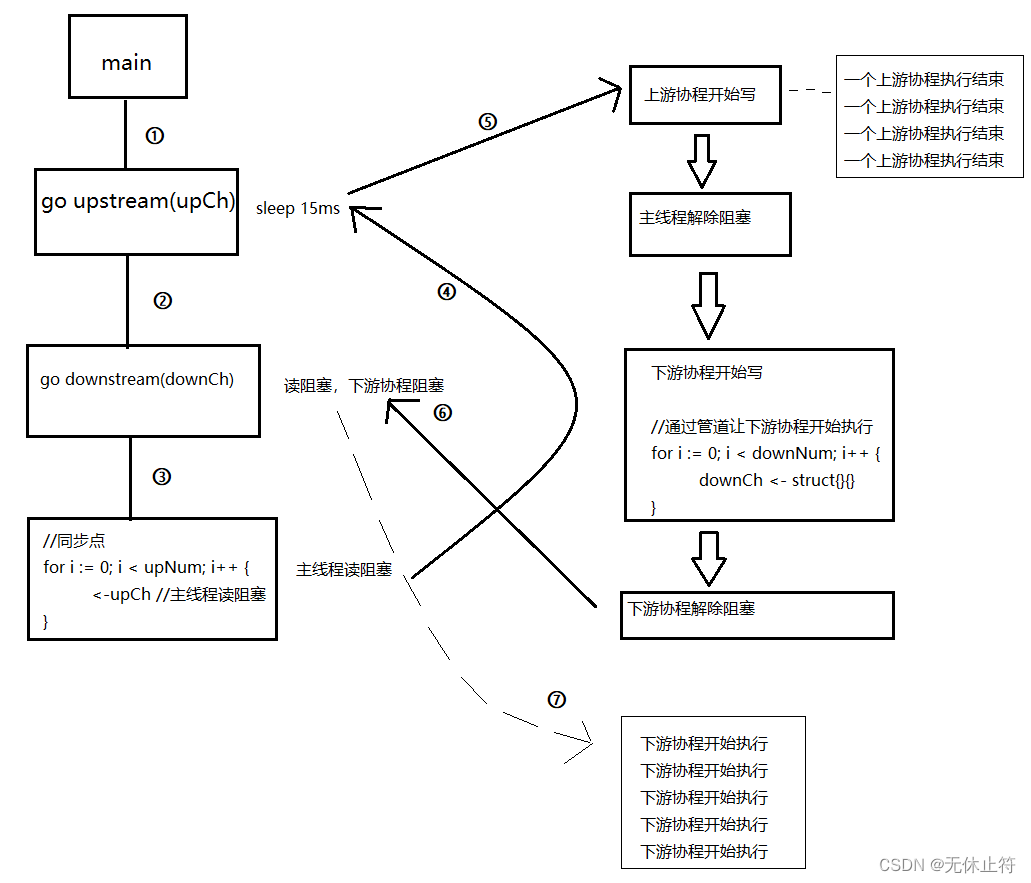
func upstream(ch chan struct{}) {time.Sleep(15 * time.Millisecond)fmt.Println("一个上游协程执行结束")ch <- struct{}{} //写
}func downstream(ch chan struct{}) {<-ch //读fmt.Println("下游协程开始执行")
}func main() {upNum := 4 //上游协程的数量downNum := 5 //下游协程的数量upCh := make(chan struct{}, upNum)downCh := make(chan struct{}, downNum)//启动上游协程和下游协程,实际下游协程会先阻塞for i := 0; i < upNum; i++ {go upstream(upCh) //time.Sleep(15 * time.Millisecond) 延迟执行}for i := 0; i < downNum; i++ {go downstream(downCh) //读阻塞}//同步点for i := 0; i < upNum; i++ {<-upCh //主线程读阻塞}//通过管道让下游协程开始执行for i := 0; i < downNum; i++ {downCh <- struct{}{}}time.Sleep(10 * time.Millisecond) //等下游协程执行结束
}
- 结果分析
一个上游协程执行结束
一个上游协程执行结束
一个上游协程执行结束
一个上游协程执行结束
下游协程开始执行
下游协程开始执行
下游协程开始执行
下游协程开始执行
下游协程开始执行
五、并发安全性
1 - 资源竞争
- 资源竞争:多协程并发修改同一块内存,产生资源竞争
- n++不是原子操作,并发执行时会存在脏写。n++分为3步:取出n,加1,结果赋给n。测试时需要开1000个并发协程才能观察到脏写
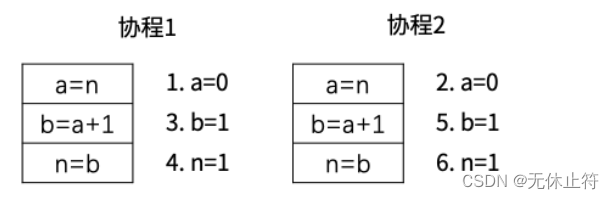
- n++不是原子操作,并发执行时会存在脏写。n++分为3步:取出n,加1,结果赋给n。测试时需要开1000个并发协程才能观察到脏写
var n intfunc main() {wg := sync.WaitGroup{}wg.Add(1000)for i := 0; i < 1000; i++ {go func() {defer wg.Done()n++}()}wg.Wait()fmt.Println(n) //无论运行多少次都不会到达1000
}
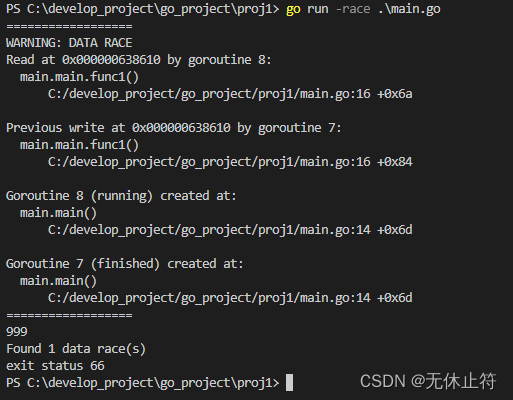
- -rece:go run或go build时添加-race参数检查资源竞争情况
go run -race .\\main.go
2 - 原子操作
- 原子操作
func atomic.AddInt32(addr *int32, delta int32) (new int32)func atomic.LoadInt32(addr *int32) (val int32)
var n int32func main() {wg := sync.WaitGroup{}wg.Add(1000)for i := 0; i < 1000; i++ {go func() {defer wg.Done()atomic.AddInt32(&n, 1)}()}wg.Wait()fmt.Println(n)
}

3 - 读写锁
- 读写锁:
var lock sync.RWMutex //声明读写锁,无需初始化lock.Lock() lock.Unlock() //加写锁和释放写锁lock.RLock() lock.RUnlock() //加读锁和释放读锁
var n int32
var lock sync.RWMutexfunc main() {wg := sync.WaitGroup{}wg.Add(1000)for i := 0; i < 1000; i++ {go func() {defer wg.Done()lock.Lock()n++lock.Unlock()}()}wg.Wait()fmt.Println(n)
}
- 写锁可以排斥其他写锁:任意时刻只可以加一把写锁,且不能加读锁
var lock sync.RWMutexfunc main() {go func() {lock.Lock()fmt.Println("A lock success")}()fmt.Println()go func() {lock.RLock() //阻塞,排斥读锁fmt.Println("B lock success")}()fmt.Println()go func() {lock.Lock() //阻塞,排斥写锁fmt.Println("C lock success")}()time.Sleep(time.Second)
}
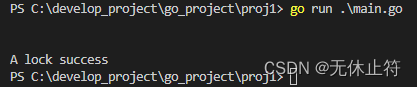
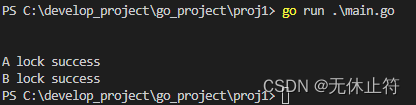
- 没加写锁时,可以同时加多把读锁,读锁加上之后不能再加写锁
var lock sync.RWMutexfunc main() {go func() {lock.RLock()fmt.Println("A lock success")}()fmt.Println()go func() {lock.RLock()fmt.Println("B lock success")}()fmt.Println()go func() {lock.Lock() //阻塞,排斥写锁fmt.Println("C lock success")}()time.Sleep(time.Second)
}
4 - 容器的并发安全
- 数组、slice、struct:允许并发修改(可能会脏写)
//切片和数组一样
func main() {lst := make([]int, 5)go func() {for i := 0; i < len(lst); i += 1 {time.Sleep(10 * time.Millisecond)lst[i] = 888}}()go func() {for i := 0; i < len(lst); i += 1 {time.Sleep(10 * time.Millisecond)lst[i] = 555}}()time.Sleep(time.Second)fmt.Println(lst)
}// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// [888 888 888 888 888]
// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// [888 555 555 555 555]
// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// [555 555 555 555 555]
// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// [555 555 555 555 555]
// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// [888 555 555 555 555]
// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// [555 888 888 888 888]//struct
func main() {type Student struct {Age intName string}stu := new(Student)go func() {for i := 0; i < 10; i += 1 {time.Sleep(10 * time.Millisecond)stu.Age = 18time.Sleep(10 * time.Millisecond)stu.Name = "Jack"}}()go func() {for i := 0; i < 10; i += 1 {time.Sleep(10 * time.Millisecond)stu.Age = 11time.Sleep(10 * time.Millisecond)stu.Name = "Tom"}}()time.Sleep(time.Second)fmt.Println(stu)
}// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// &{18 Jack}
// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// &{11 Jack}
// PS C:\\develop_project\\go_project\\proj1> go run .\\main.go
// &{11 Tom}
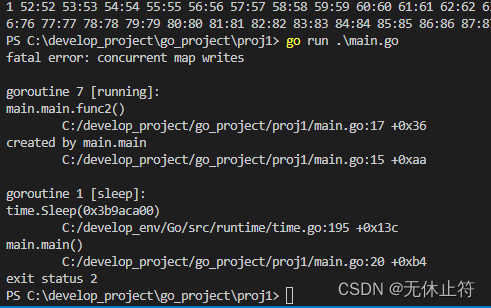
- map:并发修改map有时会发生panic
fatal error: concurrent map writes
func main() {mp := make(map[int]int, 10)go func() {for i := 0; i < 100; i += 1 {mp[i] = i}}()go func() {for i := 0; i < 100; i += 1 {mp[i] = i}}()time.Sleep(time.Second)fmt.Println(mp)
}
- sync.Map:如果需要并发修改map请使用sync.Map
func main() {var mp sync.Mapgo func() {for i := 0; i < 100; i += 1 {mp.Store(i, i)}}()go func() {for i := 0; i < 100; i += 1 {mp.Store(i, i)}}()time.Sleep(time.Second)fmt.Println(mp.Load(0))
}
六、多路复用
- 操作系统级的I/O模型有
- 阻塞I/O
- 非阻塞I/O
- 信号驱动I/O
- 异步I/O
- 多路复用I/O:
- Linux下,一切皆文件
- 包括普通文件、目录文件、字符设备文件(键盘、鼠标)、块设备文件(硬盘、光驱)、套接字socket等等
- 文件描述符(File descriptor,FD)是访问文件资源的抽象句柄,读写文件都要通过它
- 文件描述符就是个非负整数,每个进程默认都会打开3个文件描述符:0标准输入、1标准输出、2标准错误
- 由于内存限制,文件描述符是有上限的,可通过ulimit –n查看,文件描述符用完后应及时关闭
1 - 阻塞I/O
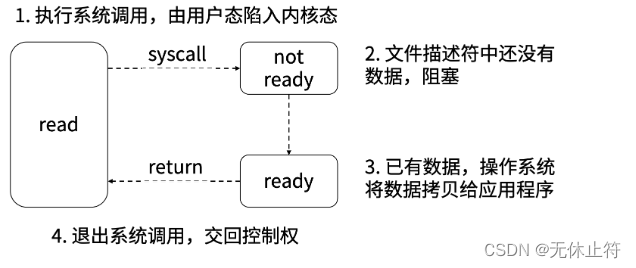
2 - 非阻塞I/O
- 阻塞I/O与非阻塞I/O的区别
- 阻塞I/O在阻塞的时候是不会处理其他事务一直阻塞等待
- 非阻塞I/O在阻塞的时候可以先处理其他事务,提高CPU的利用率
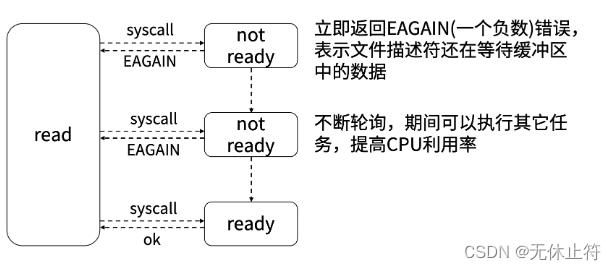
- read和write默认是阻塞模式
ssize_t read(int fd, void *buf, size_t count);ssize_t write(int fd, const void *buf, size_t nbytes);
- 通过系统调用fcntl可将文件描述符设置成非阻塞模式
int flags = fcntl(fd, F_GETFL, 0);fcntl(fd, F_SETFL, flags | O_NONBLOCK);
3 - 多路复用I/O
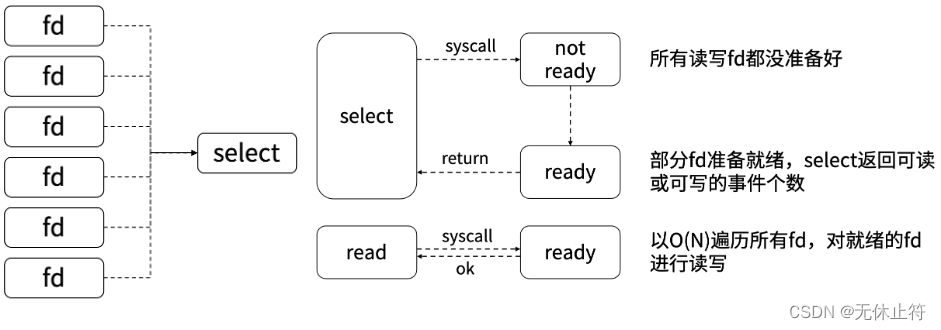
- 多路复用I/O
- select系统调用可同时监听1024个文件描述符的可读或可写状态
- poll用链表存储文件描述符,摆脱了1024的上限
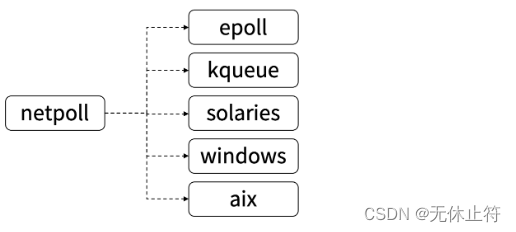
- 各操作系统实现了自己的I/O多路复用函数,如epoll、 evport 和kqueue等
- go的多路复用I/O:
- go多路复用函数以netpoll为前缀,针对不同的操作系统做了不同的封装,以达到最优的性能
- 在编译go语言时会根据目标平台选择特定的分支进行编译
LOOP:for {select { //同时监听多个channel,谁准备好就执行谁case n := <-countCh:fmt.Println(n)case <-finishCh:fmt.Println("finish")break LOOP //break LOOP 退出for循环,在使用for select的时,单独一个break无法退出case <-abortCh:fmt.Println("abort")break LOOP //break LOOP 退出for循环}}