ElasticSearch - 分片内部原理之动态更新索引、近实时搜索、持久化变更、段合并
ElasticSearch的倒排索引机制,简直是搜索引擎界的“懒人福音”!它通过词项、词汇表和倒排列表,让全文搜索变得和刷微博一样简单。想象一下,你输入“谷歌”,ElasticSearch瞬间告诉你相关文档,还能告诉你“谷歌”在这些文档里出现了几次、在哪个位置。这就像你问朋友“今天吃什么”,他不但告诉你“火锅”,还告诉你“麻辣火锅”在菜单的第5页。
那么问题来了,倒排索引为啥是不可变的?这就好比你在朋友圈发了条动态,发了就不能改,省得你总是纠结要不要“撤回”。不变性让ElasticSearch免去了锁的烦恼,缓存也更高效。不过,它的缺点也很明显:如果你要更新文档,就得重建整个索引,就像你非得删了朋友圈重发一样,有点麻烦。
那么,ElasticSearch如何解决“动态更新”这个难题呢?答案是:临时索引!它就像你的备忘录,随时记录新文档,等到内存撑不住了,再把这些临时索引“存档”到磁盘。这样一来,虽然倒排索引本身不变,但通过临时索引和删除列表,ElasticSearch实现了“动态更新”的骚操作。这就像你虽然不能改朋友圈,但可以删了重发,或者发个新动态覆盖旧的。
当然,这背后还有段合并、持久化变更等复杂机制,确保数据不会丢。总之,ElasticSearch的设计思路就是:用更多的“临时文件”来绕过不变性的限制,既保留了性能优势,又实现了灵活性。这不禁让人思考:在其他领域,我们是否也能用类似的“迂回战术”来解决看似不可调和的问题呢?

文章目录
-
-
- 01. ElasticSearch 倒排索引是什么?
- 02. ElasticSearch 倒排索引为什么是不可变的?
- 03. ElasticSearch 索引文档原理?
- 04. ElasticSearch 如何动态更新索引?
- 05. ElasticSearch 文档的新增、删除、更新?
- 06. ElasticSearch 搜索为什么是近实时的?
- 07. ElasticSearch 在什么情况下使用 refresh api ?
- 08. Elasticsearch 是怎样保证更新被持久化在断电时也不丢失数据?
- 09. ElasticSearch 在什么情况下使用 flush api?
- 10. ElasticSearch 为什么需要段合并?
- 11. ElasticSearch 在什么情况下使用 optimize api?
- 12. 分片内部原理
-
- 1. 索引的不可变性
- 2. 动态更新索引
- 3. 近实时搜索
- 4. 持久化变更
- 5. 段合并
-
01. ElasticSearch 倒排索引是什么?
Elasticsearch的倒排索引是一种数据结构,它将每个单词与包含该单词的文档列表相关联。倒排索引的优势在于它可以快速地进行全文搜索和相关性评分。
倒排索引由3个主要部分组成:词项、词汇表、倒排列表。其中词项是索引中最小的存储和查询单元。词汇表是一个包含所有单词的列表,每个单词都有一个唯一的词项ID。倒排列表是一个包含每个单词的文档列表(一个单词出现在哪些文档中),每个文档都有一个唯一的文档ID。倒排列表还包含每个单词在每个文档中出现的位置和频率的信息。
当用户执行全文搜索时,Elasticsearch将查询中的每个单词与词汇表中的词项进行匹配,并检索包含这些单词的文档列表。然后,Elasticsearch使用倒排列表中的信息来计算每个文档的相关性得分,并将结果返回给用户。
ElasticSearch索引中索引了3个文档:
| 文档id | 文档内容 |
|---|---|
| 1 | 谷歌地图之父跳槽Facebook |
| 2 | 谷歌地图之父加盟Facebook |
| 3 | 谷歌地图创始人离开谷歌加盟Facebook |
倒排索引中需要记录的信息:
| 单词id | 单词 | 文档频率 | 倒排列表(文档id;单词频率;<单词在文档中的位置>) |
|---|---|---|---|
| 1 | 谷歌 | 3 | (1;1<1>),(2;1;<1>),(3;2;<5>) |
| 2 | 地图 | 3 | (1;1<2>),(2;1;<2>),(3;1;<2>) |
| 3 | 之父 | 2 | (1;1<3>),(2;1;<3>) |
| 4 | 跳槽 | 2 | (1;1<4>) |
| 5 | 3 | (1;1<5>),(2;1;<5>),(3;1;<7>) | |
| 6 | 加盟 | 2 | (2;1<4>),(3;1;<6>) |
| 7 | 创始人 | 1 | (3;1;<3>) |
| 8 | 离开 | 1 | (3;1;<4>) |
以单词谷歌为例,其单词编号为1,文档频率为3,代表有3个文档包含这个单词,对应的倒排列表为{(1;1;<1>), (2;1;<1>), (3;2;<1>)},其含义为在文档1、2、3都出现过这个单词,文档1和文档2中该单词出现的频率都为1,出现位置也都是1,即文档中第1个单词是谷歌。文档3中该单词出现的频率为2次,出现的位置为1和5,即文档3的第1个和第5个单词是谷歌。
02. ElasticSearch 倒排索引为什么是不可变的?
倒排索引被写入磁盘后是不可改变的,它永远不会修改。不变性有重要的价值:
① 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
② 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
③ 其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
④ 写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量。
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
03. ElasticSearch 索引文档原理?
给定一个文档集合(第一次索引文档时),此时如何建立一个索引?首先在内存里维护一个倒排索引,当内存占满后,将内存数据写入磁盘的临时文件,第二阶段对临时文件进行合并形成最终索引。
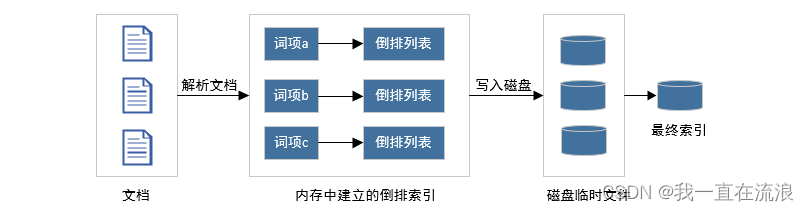
① 从磁盘读取文档,对文档内容进行解析,并在内存中建立一个倒排索引,相当于对目前处理的文档子集单独在内存中建立起了一整套倒排索引,和最终索引相比,其结构和形式是相同的,区别是这个索引只是部分文档的索引而非全部文档的索引。
② 当内存占满后,为了腾出内存空间,将整个内存中建立的倒排索引写入磁盘临时文件中,然后彻底清除所占内存,这样就空出内存来进行后续文档的处理。
③ 每一轮处理都会在磁盘产生一个对应的临时文件,当所有文档处理完成后,在磁盘中会有多个临时文件,为了产生最终的索引,需要将这些临时文件合并形成最终索引。
04. ElasticSearch 如何动态更新索引?
倒排索引一旦被写入磁盘就是不可更改的(没有写入磁盘前是可以更改的噢),如果搜索引擎需要处理的文档集合是静态集合,那么在索引建立好之后,就可以一直用建好的索引响应用户查询请求。但是,在真实环境中,搜索引擎需要处理的文档集合往往是动态集合,即在建好初始的索引后,后续不断有新文档进入系统,同时原先的文档集合内有些文档可能被删除或者内容被更改。问题是怎样在保留不变性的前提下实现倒排索引的更新呢?答案是: 用更多的索引,即增加临时索引。在动态更新索引中,有3个关键的索引结构:倒排索引、临时索引和已删除文档列表。
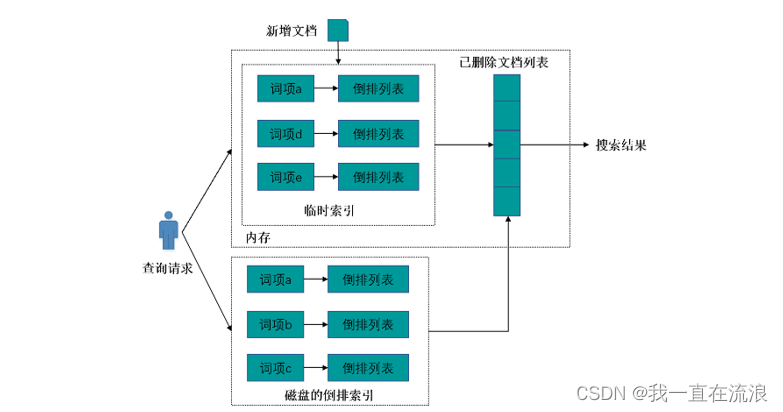
① 倒排索引就是对初始文档集合建立好的索引结构,该索引存在磁盘中,不可改变。
② 临时索引是在内存中实时建立的倒排索引,该索引存储在内存中,当新增文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排列表末尾追加倒排列表项,随着新加入系统的文档越来越多,临时索引消耗的内存也会随之增加,一旦临时索引将指定的内存消耗光,要考虑将临时索引的内容更新到磁盘索引中,以释放内存空间来容纳后续的新进文档。
③ 已删除文档列表则用来存储已被删除的文档的相应文档ID,形成一个文档ID列表。这里需要注意的是:当一篇文档内容被更改,可以认为是旧文档先被删除,之后向系统内增加一篇新的文档,通过这种间接方式实现对内容更改的支持。
当系统发现有新文档进入时,立即将其加入临时索引中。有文档被删除时,则将其加入删除文档队列。文档被更改时,则将原先文档放入删除队列,解析更改后的文档内容,并将其加入临时索引中。通过这种方式可以满足实时性的要求。
如果用户输入查询请求,则搜索引擎同时从倒排索引和临时索引中读取用户查询单词的倒排列表,找到包含用户查询的文档集合,并对两个结果进行合并,之后利用删除文档列表进行过滤,将搜索结果中那些已经被删除的文档从结果中过滤,形成最终的搜索结果,并返回给用户。这样就能够实现动态环境下的准实时搜索功能。
注意:在内存中的临时索引是不断变化的ÿ