SAM Segment Anything

https://arxiv.org/pdf/2304.02643v1.pdf
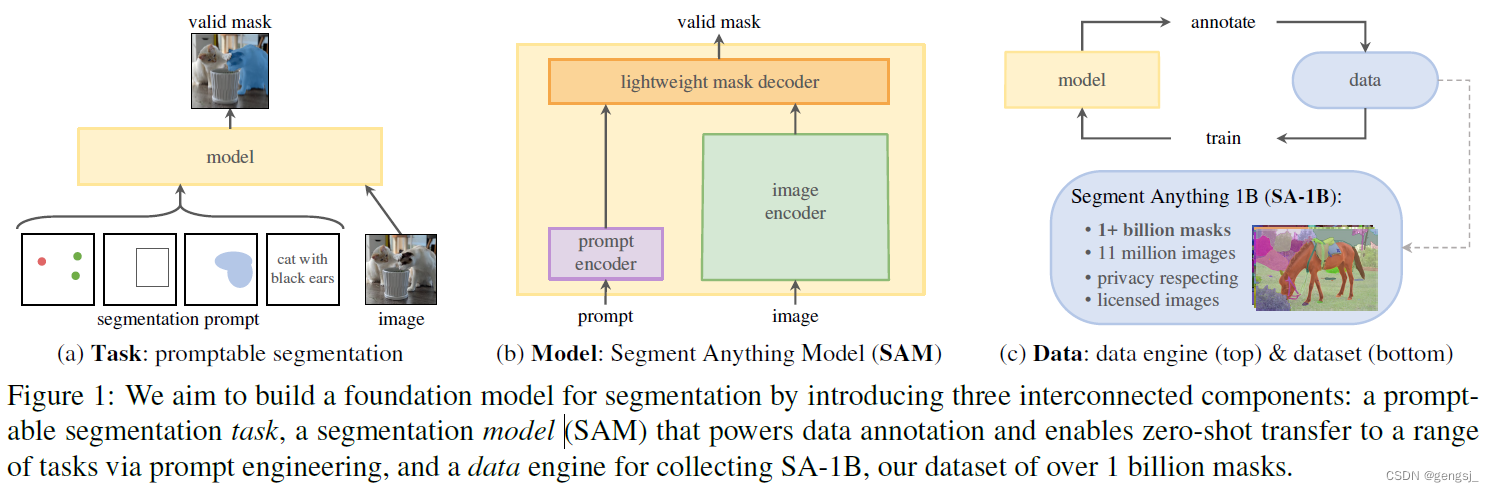
包含三个主题:Task、Model、Data
Task(任务):
需要定义一个 足够通用的图像分割任务,可以提供一个强大的预训练目标,并支持广泛的下游应用程序。
Model(模型):
模型一共包含三个部分:image encoder, prompt encoder, mask decoder
data(数据集):
SA-1B
上述三者之间的关系:先定义了图像分割任务之后,需要用模型来演绎,但是训练模型又需要数据集,然后没有现成的具有很多mask的数据集,就干脆用 data engine 来边生成数据边改进模型。
模型架构
image encoder为图像生成一次性的embedding,而 prompt encoder 将 prompt 实时的转换为 嵌入向量。然后将这两个信息源组合在一个预测分割mask的 轻量级mask解码器中。计算之后,SAM就可以在50ms内 根据浏览器中的任何提示生成一个 分割。


数据集
标注者使用 SAM 交互地注释图像,之后新注释的数据又反过来更新 SAM,可谓是相互促进。
使用该方法,交互式地注释一个掩码只需大约 14 秒。与之前的大规模分割数据收集工作相比,Meta 的方法比 COCO 完全手动基于多边形的掩码注释快 6.5 倍,比之前最大的数据注释工作快 2 倍,这是因为有了 SAM 模型辅助的结果。
最终的数据集超过 11 亿个分割掩码,在大约 1100 万张经过许可和隐私保护图像上收集而来。SA-1B 的掩码比任何现有的分割数据集多 400 倍,并且经人工评估研究证实,这些掩码具有高质量和多样性,在某些情况下甚至在质量上可与之前更小、完全手动注释的数据集的掩码相媲美 。
我认为这篇文章比较厉害的点:
Data Engine
可以边生成数据,边用这个数据改进模型,然后在用这个模型生成数据,迭代迭代迭代……