Flink系列-8、Flink DataStream的简介和API开发

版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
大数据系列文章目录
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/

目录
- 流处理的介绍
- Flink DataStream API 概览
-
- Flink DataStream API编程基本步骤
流处理的介绍
一般来说,由于需要支持无限数据集的处理,流处理系统一般采用一种数据驱动的处理方式。它会提前设置一些算子,然后等到数据到达后对数据进行处理。
为了表达复杂的计算逻辑,包括 Flink 在内的分布式流处理引擎一般采用 DAG 图来表示整个计算逻辑,其中 DAG 图中的每一个点就代表一个基本的逻辑单元,也就是算子。由于计算逻辑被组织成有向图,数据会按照边的方向,从一些特殊的 Source 节点流入系统,然后通过网络传输、本地传输等不同的数据传输方式在算子之间进行发送和处理,最后会通过 Sink 节点将计算结果发送到某个外部系统或数据库中。
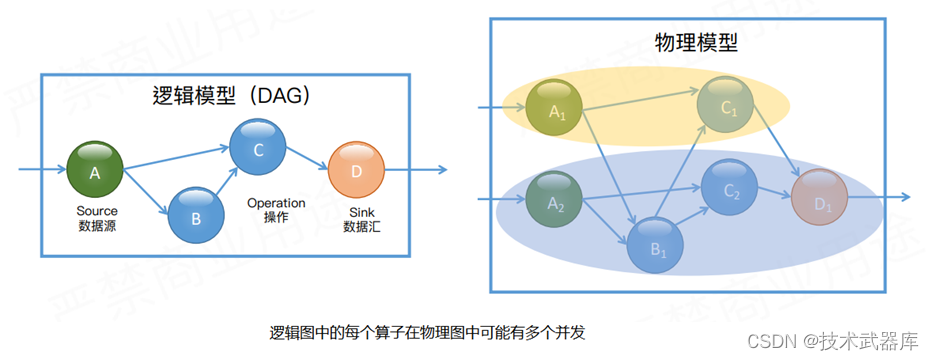
对于分布式流处理引擎,实际运行时物理模型可能比较复杂,由于每个算子都可能有多个实例。如图所示,作为 Source 的 A 算子有两个实例,中间算子 C 也有两个实例。在逻辑模型中,A 和 B 是 C 的上游节点,而在对应的物理逻辑中,C 的所有实例和 A、B 的所有实例之间可能都存在数据交换。在物理模型中,会根据计算逻辑,采用系统自动优化或人为指定的方式将计算工作分布到不同的实例中。只有当算子实例分布到不同进程上时,才需要通过网络进行数据传输,而同一进程中的多个实例之间的数据传输通常是不需要通过网络的。

由于流处理的计算逻辑是通过 DAG 图来表示的,因此它们的大部分 API 都是围绕构建这种计算逻辑图来设计的。例如,对于几年前非常流行的 Apache Storm,它的 Word Count 的示例如表 1 所示。基于 Apache Storm 用户需要在图中添加 Spout 或 Bolt 这种算子,并指定算子之前的连接方式。这样,在完成整个图的构建之后,就可以将图提交到远程或本地集群运行。
与之对比,Apache Flink 的接口虽然也是在构建计算逻辑图,但是 Flink 的 API 定义更加面向数据本身的处理逻辑,它把数据流抽象成为一个无限集,然后定义了一组集合上的操作,然后在底层自动构建相应的 DAG 图。可以看出,Flink 的 API 要更“上层”一些。
Flink DataStream API 概览
入门案例
//1、设置运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2、配置数据源读取数据
DataStream<String> text = env.readTextFile ("input");
//3、进行一系列转换
DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).keyBy(0).sum(1);
//4、配置数据汇写出数据
counts.writeAsText("output");
//5、提交执行
env.execute("Streaming WordCount");为了实现流式 Word Count:
- 要先获得一个 StreamExecutionEnvironment 对象。它是我们构建图过程中的上下文对象。
- 基于这个对象,我们可以添加一些算子
- 对于流处理程序,我们一般需要首先创建一个数据源去接入数据。在这个例子中,我们使用了 Environment 对象中内置的读取文件的数据源
- 上一步之后,我们拿到的是一个 DataStream 对象,它可以看作一个无限的数据集,可以在该集合上进行序列的操作
- 例如,在 Word Count 例子中,我们首先将每一条记录(即文件中的一行)分隔为单词,这是通过 FlatMap 操作来实现的。调用 FlatMap 将会在底层的 DAG 图中添加一个 FlatMap 算子。然后,我们得到了一个记录是单词的流
- 我们将流中的单词进行分组(keyBy),然后累积计算每一个单词的数据(sum(1))
- 计算出的单词的数据组成了一个新的流,我们将它写入到输出文件中
最后,调用 env.execute 方法来开始程序的执行。需要强调的是,前面我们调用的所有方法,都不是在实际处理数据,而是在构通表达计算逻辑的 DAG 图。只有当我们将整个图构建完成并显式的调用 Execute 方法后,框架才会把计算图提供到集群中,接入数据并执行实际的逻辑。
基于 Flink 的 DataStream API 来编写流处理程序一般需要三步:
- 通过 Source 接入数据
- 进行一系统列的处理以及将数据写出
- 不要忘记显式调用 Execute 方式,否则前面编写的逻辑并不会真正执行。
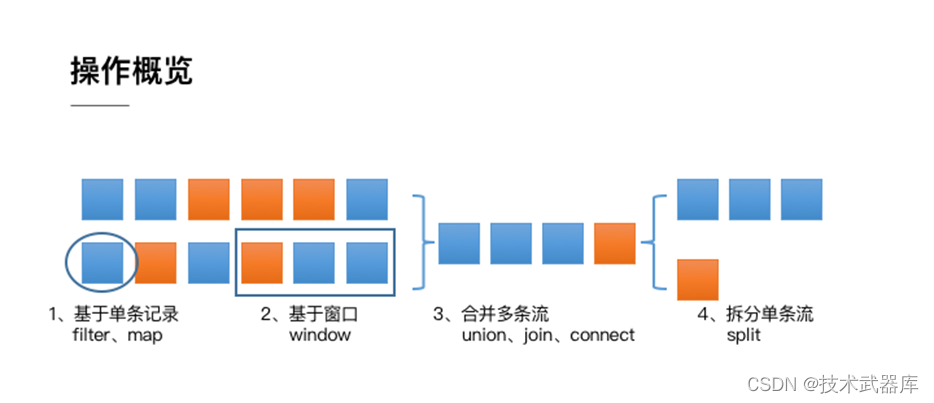
从上面的例子中还可以看出,Flink DataStream API 的核心,就是代表流数据的 DataStream 对象。整个计算逻辑图的构建就是围绕调用 DataStream 对象上的不同操作产生新的 DataStream 对象展开的。整体来说DataStream 上的操作可以分为四类。
- 第一类是对于单条记录的操作,比如筛除掉不符合要求的记录(Filter 操作),或者将每条记录都做一个转换(Map 操作)
- 第二类是对多条记录的操作。比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起。为了支持这种类型的操作,就得通过 Window 将需要的记录关联到一起进行处理
- 第三类是对多个流进行操作并转换为单个流。例如,多个流可以通过 Union、Join 或 Connect 等操作合到一起。这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作
- 最后, DataStream 还支持与合并对称的操作,即把一个流按一定规则拆分为多个流(Split 操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理。
Flink DataStream API编程基本步骤
- 获取执行环境(StreamExecutionEnvironment)
- 加载/创建初始数据集
- 对数据集进行各种转换操作(生成新的DataStream)
- 指定将计算的结果存储到哪个位置
- 触发APP执行(execute)