探讨接口测试颗粒度


偶然间在论坛上看到一个帖子,帖子内容如下:
假设现在有一个新增商品的接口,返回的参数中有新增商品的 id(每次返回的 id 都不一样)、success(判断是否成功,0 失败 1 成功)
1. 接口测试,断言的时候是否需要断言 id,还是说只需要断言 success 等于 1 就行?
2. 如果需要断言 id,是断言 id 不为空即可,还是说从数据库中取新增商品的 id 和接口返回的 id 进行比较,断言是否相等,这种比较有必要吗
问题的核心点是接口测试断言颗粒度问题,大家的观点基本上属于两派:
1. 只需要断言接口响应即可,无需做DB落表数据断言
2. 断言尽可能详细,DB断言很重要。
单体架构测试颗粒度
本文的主题也由此展开,探讨一下微服务接口测试的颗粒度问题。
20年之前,当时负责的产品属于单体架构,产品功能也相对比较简单。第一家公司产品是一个用户营销平台(画像系统),核心功能就是用户标签管理、圈人管理以及客群管理;第二家公司所在部门做在线教育产品,产品是内容生产平台,该平台用于对 K12 教辅书籍进行流水线形式录入,功能涉及文件上传、目录录入、内容框选、题目录入、题目质检等。
当时的测试策略,测试重点在于功能测试,测试手段是手工端到端测试以及实现自动化的接口端到端测试用例。说白了只要覆盖核心的业务场景(核心链路),发布后就基本上没太大问题。
当然,单接口的自动化测试也有覆盖,包括对接口在处理业务前的前置处理逻辑测试,以及接口处理业务逻辑后的输出结果测试。
1.默认值测试
很多情况一些非必填的参数会有默认值,比如说一个查询的接口,参数count为返回查询的结果数量, 默认为10,那么就应该有一条case来测试,当然前置条件是数据库里面必须要存在这样的数据超过10条。
2.异常类型测试
比如上面的count参数,这个参数的类型一定是可以转换为int类型的,这时候我们需要测试如果传的一些不可以 转换为int类型值来测试代码是否加入判断
3.必传项测试
如果接口的参数有必传项,那么需要测试在不传这个参数的时候接口返回情况,测试是否会提示 相应的error code
4.非必传项测试
如果接口有非必填项,当我不传递这些参数的时候会不会正常的返回相应的结果
5.非空测试
无论是必传的和非必传的参数,传递的key是正确的,但是value=null,这时候返回结果是否正确
6.错误码测试
通用的错误码与业务错误码是否能够清晰的说明调用问题,错误码是否能够尽可能的全的覆盖所有的情况
7.接口返回值
主要是对接口返回结果进行断言。例如返回结果中某些字段是否缺失,类型是否正确等。
但我印象中,单接口测试用例发现的缺陷比例占比相对比较少,更多缺陷都是通过端到端测试发现的。
总结一下,可能是出于业务简单(链路复杂度低、业务模型简单)的缘故,测试手段为手工测试+自动化测试,测试场景覆盖核心业务流程即可,接口自动化测试断言返回数据就能满足质量要求,也很少断言DB数据。
微服务架构测试颗粒度
来到阿里,接触的产品业务复杂度、技术架构复杂度指数级增高,此外金融类业务对资损的把控极其严格,只要是资损至少是P级故障了,并且和绩效直接挂钩。所以金融类业务的质量保障工作压力颇大,对测试质量要求极高。因此对落库数据正确性、对下游调用的参数正确性都必须校验到。
通常情况下,开发的编码质量也比较高,常规的业务功能用例开发基本上联调过问题不大。对测试同学来说,测试的重点更多偏向于异常测试场景,例如缓存数据一致性、高并发、异步消息重发/漏发等这些情况下系统该如何正确处理。
为什么与之前单体架构测试颗粒度差别如此之大?我从二者架构差异的以下几点说一下:
1.微服务架构部署和运维成本更高:微服务架构中的服务数量通常比单体架构更多,每个服务都需要独立部署、配置和监控,这会导致部署和运维成本变得更高。
2.微服务架构通常是分布式系统的:微服务架构中的服务分散在不同的服务器上,服务之间通过网络通信。服务实现时必须考虑分布式系统的问题,比如服务发现、负载均衡、容错等,显然这些都会增加系统的复杂性。
3.数据一致性问题:由于微服务架构中的服务是相互独立的,服务之间使用各自的数据库。这使得数据一致性变得更难以保证。
4.服务之间的依赖更加复杂:在微服务架构中,一个服务通常会依赖其他多个服务,这就需要管理服务之间的依赖关系(契约)。
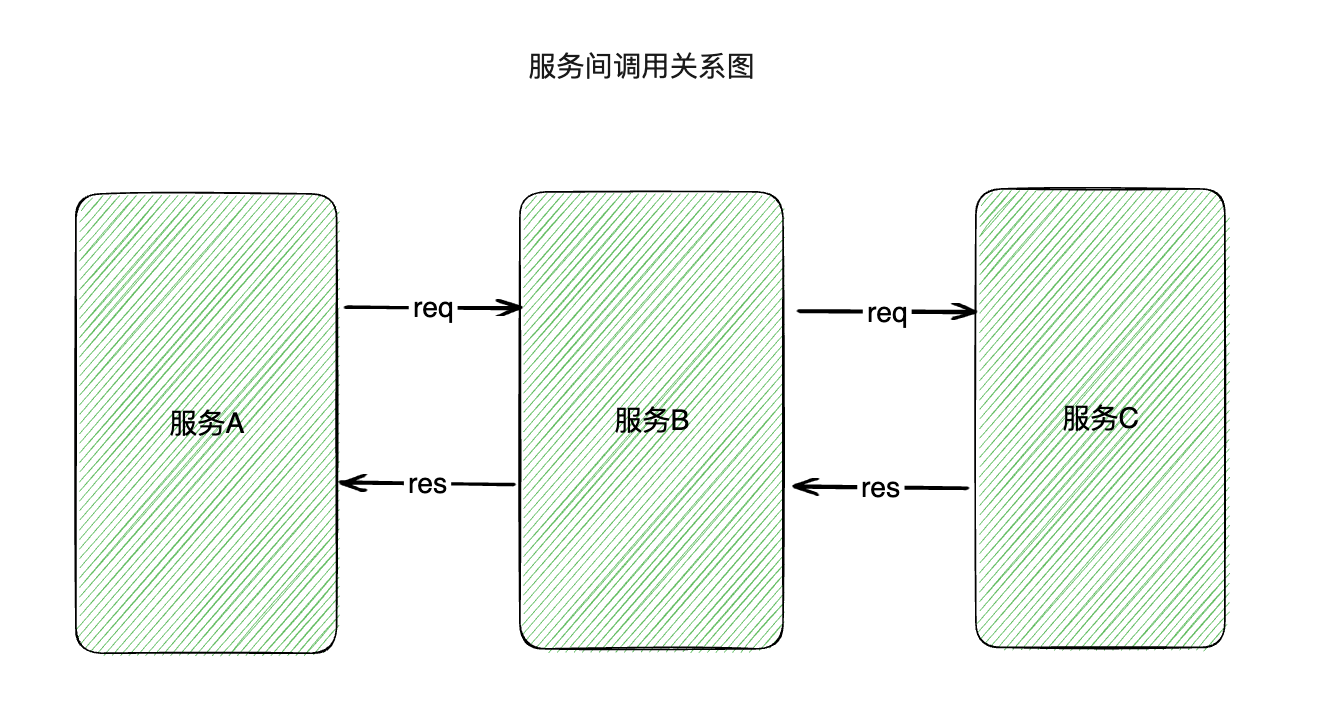
ok,说了这么多差异,下面介绍一下当前的接口测试颗粒度。
在测试策略上,不同于单体架构的端到端测试,如今测试重点是服务自身。如上图所示,如果以下单支付业务为例,服务A可以理解为网关的下单支付接口,服务B可以是X应用的下单支付接口,服务C可以是下游X域的支付接口,这样服务A、B、C分属不同的开发团队,则各个开发团队也只能保证各自应用服务的质量,所以测试重点就是服务自身,很少进行端到端测试。
基于此,如果你负责的服务是服务B,则你测试的颗粒度至少保证到:
1.服务A各种调用B的请求场景需要考虑到。正向的场景可以正确响应和异常的场景服务B则给予上游约定的错误码。
2.服务B内部的业务正常和异常处理落库的数据正确性。
3.服务B调用服务C,请求报文是否和契约一致。
此外,上文说到了数据一致性问题。整个也是比较重要的,一笔请求从A到C,则如何保证数据的金额、状态一致性也是需要测试同学关注的。当然如今对分布式系统数据一致性采取的都是最终一致性的实现方式。
1.采用分布式事务:分布式事务是指跨越多个节点的事务。当多个操作需要在不同的节点上执行时,为了确保所有节点上的操作都能正确地执行并且保持一致,可以使用分布式事务来协调这些操作。常见的实现方式包括两阶段提交和三阶段提交。
2.使用分布式锁:分布式锁是指在分布式系统中对共享资源进行加锁的一种机制。它可以防止多个节点同时对同一个资源进行修改,从而保证数据的一致性。常见的分布式锁实现包括基于数据库的分布式锁和基于缓存的分布式锁等。
3.采用分布式缓存:将数据存储在分布式缓存中,每个节点都可以从缓存中读取数据。如果缓存中没有所需的数据,则可以从数据库中读取。这种方法可以大大减少对数据库的访问次数,因此也能提高系统的性能。
如何测试数据一致性,测试同学只有先了解这些框架本身的原理,才能通过一定的测试手段构造这样的业务场景。
即使有些场景无法构造,也是可以使用被动手段来验证数据一致性,例如可以借助于核对的手段。对同一笔单据,服务A-服务B-服务C,落库数据的一致性核对;以及服务B落库数据各表数据一致性核对。
总结一下:微服务架构下业务复杂度高、技术架构服务高,对测试质量提出了更高的要求,单体架构下的测试策略已经不适用于微服务架构,微服务架构更偏重于接口测试。对接口测试的颗粒度要求尽可能细:
1.异常场景正确处理(这点和单体架构测试点几乎是一致的,如1-6)
2.契约测试保证契约符合预期
3.落库数据准确性
现在回头再看文章开头的那个问题,我认为他们说的都没错,凡事没有绝对性,不同的产品有不同的质量要求,最优解就是花最少的时间得到最优的质量回报。